Peopletools 8.52: Global Technology
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

EN 300 468 V1.3.1 (1997-09) European Standard (Telecommunications Series)
Draft EN 300 468 V1.3.1 (1997-09) European Standard (Telecommunications series) Digital Video Broadcasting (DVB); Specification for Service Information (SI) in DVB systems European Broadcasting Union Union Européenne de Radio-Télévision EBU UER European Telecommunications Standards Institute 2 Draft EN 300 468 V1.3.1 (1997-09) Reference REN/JTC-00DVB-43 (4c000j0o.PDF) Keywords DVB, broadcasting, digital, video, MPEG, TV ETSI Secretariat Postal address F-06921 Sophia Antipolis Cedex - FRANCE Office address 650 Route des Lucioles - Sophia Antipolis Valbonne - FRANCE Tel.: +33 4 92 94 42 00 Fax: +33 4 93 65 47 16 Siret N° 348 623 562 00017 - NAF 742 C Association à but non lucratif enregistrée à la Sous-Préfecture de Grasse (06) N° 7803/88 X.400 c= fr; a=atlas; p=etsi; s=secretariat Internet [email protected] http://www.etsi.fr Copyright Notification No part may be reproduced except as authorized by written permission. The copyright and the foregoing restriction extend to reproduction in all media. © European Telecommunications Standards Institute 1997. © European Broadcasting Union 1997. All rights reserved. 3 Draft EN 300 468 V1.3.1 (1997-09) Contents Intellectual Property Rights................................................................................................................................5 Foreword ............................................................................................................................................................5 1 Scope........................................................................................................................................................6 -

Standardisation Action Plan for Clarin
Standardisation Action Plan for Clarin State: Proposal to CLARIN community Nuria Bel, Jonas Beskow, Lou Boves, Gerhard Budin, Nicoletta Calzolari, Khalid Choukri, Erhard Hinrichs, Steven Krauwer, Lothar Lemnitzer, Stelios Piperidis, Adam Przepiorkowski, Laurent Romary, Florian Schiel, Helmut Schmidt, Hans Uszkoreit, Peter Wittenburg August 2009 Summary This document describes a proposal for a Standardisation Action Plan (SAP) for the Clarin initiative in close synchronization with other relevant initiatives such as Flarenet, ELRA, ISO and TEI. While Flarenet is oriented towards a broader scope since it is also addressing standards that are typically used in industry, CLARIN wants to be more focussed in its statements to the research domain. Due to the overlap it is agreed that the Flarenet and CLARIN documents on standards need to be closely synchronized. This note covers standards that are generic (XML, UNICODE) as well as standards that are domain specific where naturally the LRT community has much more influence. This Standardization Action Plan wants to give an orientation for all practical work in CLARIN to achieve a harmonized domain of language resources and technology stepwise and therefore its core message is to overcome fragmentation. To meet these goals it wants to keep its message as simple as possible. A web-site will be established that will contain more information about examples, guidelines, explanations, tools, converters and training events such as summer schools. The organization of the document is as follows: • Chapter 1: Introduction to the topic. • Chapter 2: Recommended standards that CLARIN should endorse page 4 • Chapter 3: Standards that are emerging and relevant for CLARIN page 8 • Chapter 4: General guidelines that need to be followed page 12 • Chapter 5: Reference to community practices page 14 • Chapter 6: References This document tries to be short and will give comments, recommendations and discuss open issues for each of the standards. -

Standards for Language Coding: the ISO 639 Family
Standards for language coding: the ISO 639 family Rebecca Guenther Library of Congress Jan. 8, 2010 ISO Standards development !! ISO consists of Technical Committees (TC) with subcommittees (SC) !! ISO language coding standards are maintained by !! TC 37/SC2 (Terminology and other language and content resources ) !! TC 46/SC4 (Information and documentation) LSA Annual Meeting 2 ISO 639 standards !! ISO 639-1: 2-character codes (136 codes) !! ISO 639-2: 3-character codes (450+) !! ISO 639-3: 3-character codes (7700+) !! ISO 639-4: principles !! ISO 639-5: 3-character codes (114) !! ISO 639-6: 4-character codes (??) LSA Annual Meeting 3 ISO 639 Joint Advisory Committee !! Established to advise the RAs for ISO 639-1 and ISO 639-2 !! Rotating chairs: Infoterm (for TC37) and Library of Congress (for TC46) !! Committee consists of 3 members of each TC, representatives of each registration authority and up to 6 observers !! Coordinates development of different parts of ISO 639 LSA Annual Meeting 4 ISO 639 language coding principles !! Language codes are not changed for stability of standard !! If a language code is retired it is not reassigned to something else !! Programming languages are not in scope !! Only deals with languages; codes from other ISO standards may be added as needed for more granularity, e.g. country codes, script codes LSA Annual Meeting 5 ISO 639-1 !! First published 1967 !! Covers major languages of the world !! Alpha-2 codes; only 676 possible combinations !! Developed for use in terminology applications !! Consists of -

Technical Study Desktop Internationalization
Technical Study Desktop Internationalization NIC CH A E L T S T U D Y [This page intentionally left blank] X/Open Technical Study Desktop Internationalisation X/Open Company Ltd. December 1995, X/Open Company Limited All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior permission of the copyright owners. X/Open Technical Study Desktop Internationalisation X/Open Document Number: E501 Published by X/Open Company Ltd., U.K. Any comments relating to the material contained in this document may be submitted to X/Open at: X/Open Company Limited Apex Plaza Forbury Road Reading Berkshire, RG1 1AX United Kingdom or by Electronic Mail to: [email protected] ii X/Open Technical Study (1995) Contents Chapter 1 Internationalisation.............................................................................. 1 1.1 Introduction ................................................................................................. 1 1.2 Character Sets and Encodings.................................................................. 2 1.3 The C Programming Language................................................................ 5 1.4 Internationalisation Support in POSIX .................................................. 6 1.5 Internationalisation Support in the X/Open CAE............................... 7 1.5.1 XPG4 Facilities......................................................................................... -

API Dict 1 API Dict
API Dict 1 API Dict Get the list of available dictionaries Endpoint https:/ / api. pons. com/ v1/ dictionaries Building the request • We are expecting GET-Requests. • All other parameters have to be appended to the Endpoint-URL as request parameters. Name Type Description language Request-Parameter The language of the output (ISO 639-1 - two-letter codes). Supported languages are de,el,en,es,fr,it,pl,pt,ru,sl,tr,zh. Example using wget: wget -O - --no-check-certificate "https:/ / api. pons. com/ v1/ dictionaries?language=es" Response • The response is sent in JSON format (see below). • If an unsupported language was supplied, the response for the default language (english) will be delivered. Response content A list of available dictionaries: • key is the internal name of our dictionary. For two-language dictionaries, it should consist of the two languages ordered alphabetically. • simple_label is built this way: "[translated language1] «» [translated language2]" • directed_label should be used if there is a direction involved (for example when displaying search results). The direction is implied in the key (i.e. plde means pl » de). This applies only to some languages (see example - you could not use simple_label here) • languages is a list containing the languages of the dictionary. Please note that some dictionaries may have only one language (at the time of writing: dede, dedx). Example: [ { "key": "depl", "simple_label": "niemiecki «» polski", "directed_label": { "depl": "niemiecki » polski", "plde": "polski » niemiecki" }, "languages": [ "de", "pl" ] API Dict 2 }, [...] ] Query dictionary Endpoint https:/ / api. pons. com/ v1/ dictionary Building the request • We are expecting GET-Requests. • The request has to contain the credential (secret) in an HTTP-Header. -

Datacite Metadata Kernel
DataCite ‐ International Data Citation DataCite Metadata Schema for the Publication and Citation of Research Data Version 2.1 March 2011 doi:10.5438/0003 Members of the Metadata Working Group Joan Starr, California Digital Library (head of working group) Jan Ashton, British Library Jan Brase, TIB / DataCite Paul Bracke, Purdue University Angela Gastl, ETH Zürich Jacqueline Gillet, Inist Alfred Heller, DTU Library Birthe Krog, DTU Library Lynne McAvoy, CISTI Karen Morgenroth, CISTI Elizabeth Newbold, British Library Madeleine de Smaele, TU Delft Anja Wilde, GESIS Scott Yeadon, ANDS Wolfgang Zenk‐Möltgen, GESIS Frauke Ziedorn, TIB (Metadata Supervisor) Table of Contents 1 Introduction..................................................................................................................................... 3 1.1 The DataCite Consortium....................................................................................................... 3 1.2 The Metadata Schema ........................................................................................................... 3 1.3 A Note about DataCite DOI registration ................................................................................ 4 1.4 Final Thoughts........................................................................................................................4 1.5 Version 2.1 Update ................................................................................................................ 4 2 DataCite Metadata Properties ....................................................................................................... -

ISO 639-3 Change Request 2010-020
ISO 639-3 Registration Authority Request for Change to ISO 639-3 Language Code Change Request Number: 2010-020 (completed by Registration authority) Date: 2010-3-12 Primary Person submitting request: Eric Johnson Affiliation: SIL International, East Asia Group E-mail address: eric_johnson at sil dot org Names, affiliations and email addresses of additional supporters of this request: Postal address for primary contact person for this request (in general, email correspondence will be used): P O Box 307, Chiang Mai, Thailand 50000 PLEASE NOTE: This completed form will become part of the public record of this change request and the history of the ISO 639-3 code set and will be posted on the ISO 639-3 website. Types of change requests This form is to be used in requesting changes (whether creation, modification, or deletion) to elements of the ISO 639 Codes for the representation of names of languages — Part 3: Alpha-3 code for comprehensive coverage of languages . The types of changes that are possible are to 1) modify the reference information for an existing code element, 2) propose a new macrolanguage or modify a macrolanguage group; 3) retire a code element from use, including merging its scope of denotation into that of another code element, 4) split an existing code element into two or more new language code elements, or 5) create a new code element for a previously unidentified language variety. Fill out section 1, 2, 3, 4, or 5 below as appropriate, and the final section documenting the sources of your information. The process by which a change is received, reviewed and adopted is summarized on the final page of this form. -
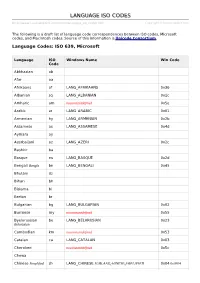
Language ISO Codes
LLAANNGGUUAAGGEE IISSOO CCOODDEESS http://www.tutorialspoint.com/html/language_iso_codes.htm Copyright © tutorialspoint.com The following is a draft list of language code correspondences between ISO codes, Microsoft codes, and Macintosh codes. Source of this information is Unicode Consortium. Language Codes: ISO 639, Microsoft Language ISO Windows Name Win Code Code Abkhazian ab Afar aa Afrikaans af LANG_AFRIKAANS 0x36 Albanian sq LANG_ALBANIAN 0x1c Amharic am noconstantdefined 0x5e Arabic ar LANG_ARABIC 0x01 Armenian hy LANG_ARMENIAN 0x2b Assamese as LANG_ASSAMESE 0x4d Aymara ay Azerbaijani az LANG_AZERI 0x2c Bashkir ba Basque eu LANG_BASQUE 0x2d Bengali Bangla bn LANG_BENGALI 0x45 Bhutani dz Bihari bh Bislama bi Breton br Bulgarian bg LANG_BULGARIAN 0x02 Burmese my noconstantdefined 0x55 Byelorussian be LANG_BELARUSIAN 0x23 Belarusian Cambodian km noconstantdefined 0x53 Catalan ca LANG_CATALAN 0x03 Cherokee noconstantdefined 0x5c Chewa Chinese Simplified zh LANG_CHINESE SUBLANGCHINESESIMPLIFIED 0x04 0x0804 Chinese zh LANG_CHINESE SUBLANGCHINESETRADITIONAL 0x04 0x0404 Traditional Corsican co Croatian hr LANG_CROATIAN 0x1a Czech cs LANG_CZECH 0x05 Danish da LANG_DANISH 0x06 Divehi LANG_DIVEHI 0x65 Dutch nl LANG_DUTCH 0x13 Edo noconstantdefined 0x66 English en LANG_ENGLISH 0x09 Esperanto eo Estonian et LANG_ESTONIAN 0x25 Faeroese fo LANG_FAEROESE 0x38 Farsi fa LANG_FARSI 0x29 Fiji fj Finnish fi LANG_FINNISH 0x0b Flemish LANG_DUTCH SUBLANGDUTCHBELGIAN 0x13 0x0813 French fr LANG_FRENCH 0x0c Frisian fy noconstantdefined 0x62 Fulfulde noconstantdefined -
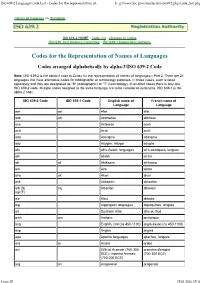
ISO 639-2 Language Code Lis
ISO 639-2 Language Code List - Codes for the representation of... h p://www.loc.gov/standards/iso639-2/php/code_list.php Library of Congress >> Standards IS0 639-2 HOME - Code List - Changes to Codes ISO 639 Joint Advisory Committee - ISO 639-1 Registration Authority Codes for the Representation of Names of Languages Codes arranged alphabetically by alpha-3/ISO 639-2 Code Note: ISO 639-2 is the alpha-3 code in Codes for the representation of names of languages-- Part 2. There are 21 languages that have alternative codes for bibliographic or terminology purposes. In those cases, each is listed separately and they are designated as "B" (bibliographic) or "T" (terminology). In all other cases there is only one ISO 639-2 code. Multiple codes assigned to the same language are to be considered synonyms. ISO 639-1 is the alpha-2 code. ISO 639-2 Code ISO 639-1 Code English name of French name of Language Language aar aa Afar afar abk ab Abkhazian abkhaze ace Achinese aceh ach Acoli acoli ada Adangme adangme ady Adyghe; Adygei adyghé afa Afro-Asiatic languages afro-asiatiques, langues afh Afrihili afrihili afr af Afrikaans afrikaans ain Ainu aïnou aka ak Akan akan akk Akkadian akkadien alb (B) sq Albanian albanais sqi (T) ale Aleut aléoute alg Algonquian languages algonquines, langues alt Southern Altai altai du Sud amh am Amharic amharique ang English, Old (ca.450-1100) anglo-saxon (ca.450-1100) anp Angika angika apa Apache languages apaches, langues ara ar Arabic arabe arc Official Aramaic (700-300 araméen d'empire BCE); Imperial Aramaic (700-300 BCE) (700-300 BCE) arg an Aragonese aragonais 1 von 15 15.01.2010 15:16 ISO 639-2 Language Code List - Codes for the representation of.. -

2021-07-07 Report Date : Cost Centre(S)
Report Date : 2021-09-17 Cost Centre(s) : % LIST OF PUBLISHED STANDARDS Page No : 1 Of 3 Total Count: 44 Committee SANS Date Latest Reaffirmation Review/ Number Number Int Ed Ed Sansified Title Approved Amendment due Revision SABS/TC 037 SANS 427:2021/ISO 1087:2019 2 1 Y Terminology work and terminology science - 2021-02-26 2026-02-26 Vocabulary SANS 427-1:2006/ISO 1087-1:2000 1 1 Y Terminology work - Vocabulary Part 1: Theory 2006-02-16 2022-06-30 and application SANS 528-1:2007/ISO 639-1:2002 1 1 Y Codes for the representation of names of 2007-03-09 2024-01-25 languages Part 1: Alpha-2 code SANS 528-2:2007/ISO 639-2:1998 1 1 Y Codes for the representation of names of 2007-03-09 2024-01-25 languages Part 2: Alpha-3 code SANS 528-3:2008/ISO 639-3:2007 1 1 Y Codes for the representation of names of 2008-07-04 2024-10-11 languages Part 3: Alpha-3 code for comprehensive coverage of languages SANS 528-5:2008/ISO 639-5:2008 1 1 Y Codes for the representation of names of 2008-07-04 2024-10-11 languages Part 5: Alpha-3 code for language families and groups SANS 704:2018/ISO 704:2009 3 2 Y Terminology work - Principles and methods 2018-03-16 2023-03-16 SANS 860:2008/ISO 860:2007 3 1 Y Terminology work - Harmonization of 2008-11-21 2023-02-12 concepts and terms SANS 1723:2014/ISO 639-4:2010 1 Y Codes for the representation of names of 2014-10-10 2025-02-21 languages - Part 4: General principles of coding of the representation of names of languages and related entities, and application guidelines SANS 1951:2008/ISO 1951:2007 3 1 Y Presentation/representation -

Handbook on Industrial Property Information and Documentation
HANDBOOK ON INDUSTRIAL PROPERTY INFORMATION AND DOCUMENTATION Ref.: Standards – ST.40 page: 3.40.1 STANDARD ST.40 RECOMMENDATION CONCERNING MAKING FACSIMILE IMAGES OF PATENT DOCUMENTS AVAILABLE ON CD-ROM INTRODUCTION 1. This Recommendation provides for making patent documents available as facsimile images on a Compact Disc Read-Only Memory (CD-ROM), particularly for exchange purposes between patent offices to assist the future use of CD-ROM discs in place of paper. It is intended that discs published in compliance with this Recommendation will function, without modification, under a variety of operating systems. 2. For the purposes of this Recommendation, the expression “patent documents” includes patents for invention, plant patents, inventors’ certificates, design patents, utility certificates, utility models, documents of addition thereto and published applications therefor. 3. This Recommendation gives guidance to offices in their production of facsimile CD-ROM discs. The current or proposed practices of offices in their production of facsimile CD-ROM discs are analyzed in respect of that guidance. REFERENCES 4. The following references are of importance to this Recommendation: – CCITT Group IV:1984 T.6, Facsimile Coding Schemes and Control Functions for Group 4 Facsimile Apparatus. – ISO 639:1988, Code for the Representation of Names of Languages. – ISO 646:1991, Information Technology – ISO 7-bit Coded Character Sets for Information Exchange. – ISO 2022:1986, Information Processing – ISO 7-bit and 8-bit-Coded Character Sets – Coded Extension Techniques. – ISO 2375:1985, Data processing – Procedure for Registration of Escape Sequences. – ISO 8601:1988, Data Elements and Interchange Formats – Information Interchange – Representation of Dates and Times. – ISO 8879:1986, Information processing – Text and Office Systems – Standard Generalized Markup Language (SGML). -

Language Codes Standards
Language Codes Standards Lee Gillam University of Surrey Overview • Language Codes Standards are growing in number and complexity – From 2 to 6 – From 400 identifiers to upwards of 30000 – From lists to databases – From tables to metadata registries – From published text documents to “published” databases – From IETF RFC to RFCs to RFCs – From a closed membership committee to an open Community initiative (OmegaWiki) – …. with accompanying (web) services and products Overview • Language Codes Standards are growing in number and complexity – From 2 to 6 – eventually back to 1? – From 400 identifiers to upwards of 30000 – plus supporting metadata – From lists to databases – multiple metadata registers – From tables to metadata registries – registers + policies + “auditors” – From published text documents to “published” databases – “SAD” – From IETF RFC to RFCs to RFCs – consume, consume, consume – From a closed membership committee to an open Community initiative (OmegaWiki) – supporting infrastructure, expert review of community contributions (e-Voting?) – …. with accompanying (web) services and products – Open Source and bespoke, and secured funding as necessary Overview ISO 12620 ISO 11179 “standards as databases” ISO 639-4 ISO 639-X standard ISO 639-6 standard “Auditors” ISO 639-X data ISO 639-6 data Co-ordination Expert review Community review Language Codes & Language Resources Applications in e-Science, video annotation and document quality….. The Language Documentation and Interchange Format (LDIF) • Language Documentation Description