2017 PDL Fall Update
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Microsoft and Cray to Unveil $25,000 Windows-Based Supercomputer
AAll About Microsoft: l lCodeTracker A monthly look at Microsoft’s codenames and what they Areveal about the direction of the company. b o u t M i c r o s o f t : All About Microsoft CodeTracker Keeping track of Microsoft's myriad codenames is an (almost) full-time occupation. I know, as I spend a lot of my work hours tracking down the latest names in the hopes of being able to better keep tabs on what's coming next from the Redmondians. Each month, I'll be releasing an updated, downloadable version of the CodeTracker. I'll add new codenames -- arranged in alphabetical order by codename -- of forthcoming Microsoft products and technologies. I also will note timing changes (date slips, the release of a new test build, the disappearance of a planned deliverable) for entries that are already part of the Tracker. Once Microsoft releases the final version of a product or technology I've been tracking, I will remove it from the Tracker. In that way, the CodeTracker will remain focused on futures. (An aside about the Tracker: A question mark in place of an entry means I have insufficient information to hazard even an educated guess about a particular category.) If you have suggested new entries or corrections to existing ones, please drop me an e-mail at mjf at microsofttracker dot com. Thanks! Mary Jo Foley, Editor, ZDNet's "All About Microsoft" blog This Month's Theme: Big iron needs love, too If you went by nothing but blog and publication headlines, you might think mobile phones and slates are where all the innovation is these days. -

0321741331.Pdf
THE PHOTOSHOP ELEMENTS 9 BOOK FOR DIGITAL PHOTOGRAPHERS The Photoshop Elements Published by 9 Book for Digital New Riders Photographers Team Copyright ©2011 by Scott Kelby CREATIVE DIRECTOR Felix Nelson First edition: November 2010 TECHNICAL EDITORS All rights reserved. No part of this book may be reproduced or transmitted in any Cindy Snyder form, by any means, electronic or mechanical, including photocopying, recording, Kim Doty or by any information storage and retrieval system, without written permission from the publisher, except for inclusion of brief quotations in a review. TRAFFIC DIRECTOR Kim Gabriel Composed in Frutiger, Lucida, and Apple Garamond Light by Kelby Media Group, Inc. PRODUCTION MANAGER Dave Damstra Trademarks All terms mentioned in this book that are known to be trademarks or service marks ART DIRECTOR have been appropriately capitalized. New Riders cannot attest to the accuracy of Jessica Maldonado this information. Use of a term in the book should not be regarded as affecting the validity of any trademark or service mark. COVER PHOTOS COURTESY OF Photoshop Elements is a registered trademark of Adobe Systems, Inc. Scott Kelby Windows is a registered trademark of Microsoft Corporation. Matt Kloskowski Macintosh is a registered trademark of Apple Inc. iStockphoto.com Warning and Disclaimer This book is designed to provide information about Photoshop Elements for digital photographers. Every effort has been made to make this book as complete and as accurate as possible, but no warranty of fitness is implied. The information is provided on an as-is basis. The authors and New Riders shall have neither the liability nor responsibility to any person or entity with respect to any loss or damages arising from the information contained in this book or from the use of the discs or programs that may accompany it. -

The Fourth Paradigm
ABOUT THE FOURTH PARADIGM This book presents the first broad look at the rapidly emerging field of data- THE FOUR intensive science, with the goal of influencing the worldwide scientific and com- puting research communities and inspiring the next generation of scientists. Increasingly, scientific breakthroughs will be powered by advanced computing capabilities that help researchers manipulate and explore massive datasets. The speed at which any given scientific discipline advances will depend on how well its researchers collaborate with one another, and with technologists, in areas of eScience such as databases, workflow management, visualization, and cloud- computing technologies. This collection of essays expands on the vision of pio- T neering computer scientist Jim Gray for a new, fourth paradigm of discovery based H PARADIGM on data-intensive science and offers insights into how it can be fully realized. “The impact of Jim Gray’s thinking is continuing to get people to think in a new way about how data and software are redefining what it means to do science.” —Bill GaTES “I often tell people working in eScience that they aren’t in this field because they are visionaries or super-intelligent—it’s because they care about science The and they are alive now. It is about technology changing the world, and science taking advantage of it, to do more and do better.” —RhyS FRANCIS, AUSTRALIAN eRESEARCH INFRASTRUCTURE COUNCIL F OURTH “One of the greatest challenges for 21st-century science is how we respond to this new era of data-intensive -

The Spirit of Innovation Why Innovation and Value in Japan? Why Now?
THE IAFOR GIVS-Tokyo2018 | Programme & Abstract Book | Programme & GIVS-Tokyo2018 GLOBAL INNOVATION & VALUE SUMMIT 2018 PROGRAMME & ABSTRACT BOOK THE SPIRIT OF INNOVATION Why Innovation and Value in Japan? Why Now? ISSN:2433-7544 (Online)ISSN: | 2433-7587 (Print) イノベーションの精神: 日本からのインスピレーション なぜ日本でのイノベーションと価値創造なのか?なぜ今なのか? Global Business Hub Tokyo, Japan | October 5, 2018 Toshi Center Hotel, Japan | October 6-7, 2018 Organised by IAFOR in association with the IAFOR Research Centre at Osaka University and IAFOR’s Global University Partners 開催場所・日時:グローバルビジネスハブ東京 | 2018年10月5日 開催場所・日時:都市センターホテル | 2018年10月6 〜7日 大阪大学大学院国際公共政策研究科 IAFOR 研究センター &IAFOR グローバル・ユニバーシティ・パートナーズ共同開催 Organised by IAFOR iafor MEDIA PARTNERS オフィシャル メディアパ ートナ ーズ CORPORATE STRATEGIC PARTNER 企業戦略パートナー SUPPORTING ORGANISATIONS 支援団体 SUMMIT GUIDE サ ミット・ガ イド Summit Theme サミットテーマ Symposium at a Glance シンポジウム・スケジュール Advisory Board 諮問委員会詳細 Organising Committee 組織委員会 Moderators モデレータ Letter of Welcome ウェルカム・レター A Few Thoughts on Innovation イノベーションとは? Directions & Access 会場アクセス SUMMIT THEME THE SPIRIT OF INNOVATION WHY INNOVATION AND VALUE IN JAPAN? WHY NOW? 「イノベーションの精神:日本からのインスピレーション」 なぜ日本でのイノベーションと価値創造なのか? なぜ今なのか? Japan has been hailed as one of the world’s most creative and innovative countries, while simultaneously being maligned as a stagnant and lost economy that has lost its lustre. Yet as the world confronts the limits of Western concepts of innovation and the value that these bring, unique, sustainable and inclusive models of innovation developed throughout Japan’s long history -

AI Chips: What They Are and Why They Matter
APRIL 2020 AI Chips: What They Are and Why They Matter An AI Chips Reference AUTHORS Saif M. Khan Alexander Mann Table of Contents Introduction and Summary 3 The Laws of Chip Innovation 7 Transistor Shrinkage: Moore’s Law 7 Efficiency and Speed Improvements 8 Increasing Transistor Density Unlocks Improved Designs for Efficiency and Speed 9 Transistor Design is Reaching Fundamental Size Limits 10 The Slowing of Moore’s Law and the Decline of General-Purpose Chips 10 The Economies of Scale of General-Purpose Chips 10 Costs are Increasing Faster than the Semiconductor Market 11 The Semiconductor Industry’s Growth Rate is Unlikely to Increase 14 Chip Improvements as Moore’s Law Slows 15 Transistor Improvements Continue, but are Slowing 16 Improved Transistor Density Enables Specialization 18 The AI Chip Zoo 19 AI Chip Types 20 AI Chip Benchmarks 22 The Value of State-of-the-Art AI Chips 23 The Efficiency of State-of-the-Art AI Chips Translates into Cost-Effectiveness 23 Compute-Intensive AI Algorithms are Bottlenecked by Chip Costs and Speed 26 U.S. and Chinese AI Chips and Implications for National Competitiveness 27 Appendix A: Basics of Semiconductors and Chips 31 Appendix B: How AI Chips Work 33 Parallel Computing 33 Low-Precision Computing 34 Memory Optimization 35 Domain-Specific Languages 36 Appendix C: AI Chip Benchmarking Studies 37 Appendix D: Chip Economics Model 39 Chip Transistor Density, Design Costs, and Energy Costs 40 Foundry, Assembly, Test and Packaging Costs 41 Acknowledgments 44 Center for Security and Emerging Technology | 2 Introduction and Summary Artificial intelligence will play an important role in national and international security in the years to come. -

2017 CFHT Annual Report
2017 CFHT Annual Report Table of Contents Director’s Message……………………………………………………………………………………………... 3 Science Report ………………………………………………........................................................ 5 Hawaii Observatories Track an Interstellar Visitor…………………..…………………… 5 WIRCam and Herschel Observations of Interstellar Dust.…………………………………. 6 The Little Star That Survived a Supernova………………………....…….………………..……. 7 Rocky Planet Engulfment Explains Stellar Odd Couple......................................... 7 Capturing What Lies in the Space Between Galaxies………………………………….……. 8 Astronomers Define the Great Divide Between Stars and Brown Dwarfs………... 9 Blue Binaries Tell an Ancient Story……………………………………………………………….…. 10 Engineering Report ………..………………………………….……………………………………….……… 11 Primary Mirror Recoating – Shutdown August 2017..…………………………………..….. 11 SPIRou Development and Performance……………………………………………………………. 11 SITELLE Status………………………………………………………………………………………………….. 13 MegaCam Performance Improvements….…………………………….……………………….… 14 WIRCam Repairs….………………………….…………………………………………………………….… 17 ESPaDOnS/GRACES..………………………………………………………………….……………………. 18 Other Activity in the Engineering Group………………………….…………………………….… 20 MSE Report ……………………………………………………………………………………………………..…. 22 Summary and Overview…………………………………………………………………………………… 22 Partnership and Governance……………………………………………………………………………. 22 Science…………………………………………………………………………………………………………….. 23 Engineering………………………………………………………………………………………………………. 24 Overall Project Development and Priorities……………………………………………………… 26 Administration -

Managing Tail Latency in Large Scale Information Retrieval Systems
MANAGING TAIL LATENCY IN LARGE SCALE INFORMATION RETRIEVAL SYSTEMS A thesis submitted in fulfilment of the requirements for the degree of Doctor of Philosophy. Joel M. Mackenzie Bachelor of Computer Science, Honours – RMIT University Supervised by Associate Professor J. Shane Culpepper Associate Professor Falk Scholer School of Science College of Science, Engineering, and Health RMIT University Melbourne, Australia October, 2019 DECLARATION I certify that except where due acknowledgement has been made, the work is that of the author alone; the work has not been submitted previously, in whole or in part, to qualify for any other academic award; the content of the thesis is the result of work which has been carried out since the official commencement date of the approved research program; any editorial work, paid or unpaid, carried out by a third party is acknowledged; and, ethics procedures and guidelines have been followed. I acknowledge the support I have received for my research through the provision of an Australian Government Research Training Program Scholarship. Joel M. Mackenzie School of Science College of Science, Engineering, and Health RMIT University, Melbourne, Australia October 15, 2019 iii ABSTRACT As both the availability of internet access and the prominence of smart devices continue to increase, data is being generated at a rate faster than ever before. This massive increase in data production comes with many challenges, including efficiency concerns for the storage and retrieval of such large-scale data. However, users have grown to expect the sub-second response times that are common in most modern search engines, creating a problem — how can such large amounts of data continue to be served efficiently enough to satisfy end users? This dissertation investigates several issues regarding tail latency in large-scale information retrieval systems. -

The Computer Games Journal Ltd Registered Company No
ISSN 2052-773X The Computer Games Journal Ltd Registered company no. SC 441838 Registered address: 5 Golf Course Rd, Skelmorlie, North Ayrshire, UK (post code PA17 5BH) journal website: www.computergamesjournal.com journal enquiries: [email protected] The Computer Games Journal Volume 1, Edition 1 (Whitsun 2012) Reproduction rights owned by The Computer Games Journal Ltd ©2012-13 The Computer Games Journal 1(1) Whitsun 2012 The Computer Games Journal Editor-in-Chief Dr John N Sutherland BSc, MSc, EdD, CEng, CISE, CISP, MBCS Deputy Editors-in-Chief Dr Tony Maude BSc (Hons), PhD, BD (Hons) Dr Malcolm Sutherland BSc (Hons), PhD Editorial Board Prof. Alonzo Addison, University of California Dr Kenny MacAlpine, University of Abertay Dundee Aaron Allport, Blitz Games Studios Dr Hannah Marston, Deutsche Sporthochschule, Koln Jennifer Ash, IBM Alex McGivern, Reality Council Brian Baglow, Revolver PR Stephen McGlinchey, Eurocom Developments Ltd Dawn Beasley, Mission Resourcing Ltd Simon Meek, Tern Digital Pauline Belford, Edinburgh Telford College Andy Miah, Creative Futures Research Council Matt Black, Blitz Games Studios John Nash, Blitz Games Studios Kim Blake, Blitz Games Studios Walter Patterson, e3Net Peter Bloomfield; Software Engineer, Vertual Ltd Gary Penn, Denki Ltd Prof. Paul Bourke, University of Western Australia Eve Penford-Dennis (freelance game developer) Dr Fiona Cameron, University of Western Sydney Dr Mike Reddy, Newport University Phil Carlisle, Namaste Prof. Skip Rizzo, University of Southern California Dr Prathap -

Methods for Answer Extraction in Textual Question Answering
\aunimo_phd" | 2007/5/25 | 3:45 | page i | #1 View metadata, citation and similar papers at core.ac.uk brought to you by CORE Department of Computer Science provided by Helsingin yliopiston digitaalinen arkisto Series of Publications A Report A-2007-3 Methods for Answer Extraction in Textual Question Answering Lili Aunimo To be presented, with the permission of the Faculty of Science of the University of Helsinki, for public criticism in Auditorium XIV, University Main Building, on June 12th, 2007, at noon. University of Helsinki Finland \aunimo_phd" | 2007/5/25 | 3:45 | page ii | #2 Contact information Postal address: Department of Computer Science P.O. Box 68 (Gustaf H¨allstr¨omin katu 2b) FI-00014 University of Helsinki Finland Email address: [email protected] (Internet) URL: http://www.cs.Helsinki.FI/ Telephone: +358 9 1911 Telefax: +358 9 191 51120 Copyright c 2007 Lili Aunimo ISSN 1238-8645 ISBN 978-952-10-3992-8 (paperback) ISBN 978-952-10-3993-5 (PDF) Computing Reviews (1998) Classification: H.3.3, H.3.4, I.2.1, I.5.4 Helsinki 2007 Helsinki University Printing House \aunimo_phd" | 2007/5/25 | 3:45 | page iii | #3 Methods for Answer Extraction in Textual Question Answering Lili Aunimo Department of Computer Science P.O. Box 68, FI-00014 University of Helsinki, Finland lili.aunimo@iki.fi PhD Thesis, Series of Publications A, Report A-2007-3 Helsinki, June 2007, 127 + 19 pages ISSN 1238-8645 ISBN 978-952-10-3992-8 (paperback) ISBN 978-952-10-3993-5 (PDF) Abstract In this thesis we present and evaluate two pattern matching based meth- ods for answer extraction in textual question answering systems. -

Microsoft Corp. BUY Company Update : Enterprise Software
May 16, 2019 Microsoft Corp. BUY Company Update : Enterprise Software Labor-atory #18 - review of job openings new data This report is our eighteenth in a series of reviews of Microsoft’s Jay Vleeschhouwer open positions. We compile and compare the positions shown in [email protected] the “careers” website by job functions, e.g., engineering, sales, 646-442-4251 services; by region & country, and by products, brands, and other selected keywords. In addition, in the “special assignments” section, we show a selection of interesting or indicative positions, Stock Symbol NASDAQ: MSFT and in the “related companies” section we show positions at Current Price $128.93 Microsoft pertaining to our other coverage companies that sell to 12 mos. Target Price $145.00 and/or partner with Microsoft. For a comparable review of the jobs Market Cap $825,406.9 mln data at those companies, e.g., Adobe, Autodesk, PTC, et al, see Shares O/S 7,744.0 mln too our May 9th, 2019 industry report, “ Labor-atory #17.4: nice Avg Daily Vol. (3 mos.) 25,424,792 shs. work if you can get it”. 52-Week Price Low/High $71.70 - $111.15 The current compilation shows combined positions for software P/B 12.0x engineering, hardware engineering, sales, and services (i.e., Price/ FCF 0.0x consulting services, customer service & support) of about 2,635, Fiscal Year End Jun as compared with about 3,400 six months ago and about 4,150 a year ago; the highest total to date, since we began these ROE 37% reviews in 2012, was in late 2015 (about 4,950), driven at the Dividend / Yield $1.68 / 1.3% time by large increases in sales and services. -

Research Statement Deepak Narayanan
Research Statement Deepak Narayanan The end of Moore’s Law has led to the rapid adoption of a number of parallel architectures, such as multicore CPUs (with SIMD), GPUs, FPGAs, and domain-specific accelerators like the TPU, each with different programming models and performance characteristics (e.g., number of cores, SIMD lane width, cache sizes). Achieving high performance on these architectures is challenging for non-expert programmers like Machine Learning engineers and data analysts, who are increasingly using computer systems to perform expensive computations (e.g., a modern ML model has trillions of floating point operations). These computations will only become more expensive going forward as ML models become larger and the amount of available data to perform analyses over increases at unprecedented rates. My research makes it easier for programmers to achieve high performance on parallel hardware for emerging work- loads such as deep neural network model training and data analytics. My main research focus has involved building systems to execute deep learning computations in a more resource-efficient and scalable way. I have examined this problem in two main contexts: a) At a microscale granularity, how should operators in a deep neural network (DNN) model be partitioned among multiple workers to maximize throughput? I built a distributed deep learning engine called PipeDream that adapts pipelining, an optimization used in conventional compilers and runtime systems, to accelerate DNN training performance with no reduction in the final accuracy of the model. PipeDream introduced pipeline-parallel training, a principled combination of pipelining with data and inter-layer model parallel training. Pipeline-parallel training is now used at Microsoft, Facebook, and Nvidia. -
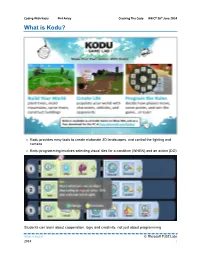
What Is Kodu?
Coding With Kodu Phil Anley Cracking The Code WEICT 26th June 2014 What is Kodu? Kodu is a visual programming language made specifically for creating games. It is designed to be accessible for children and enjoyable for everyone Kodu provides easy tools to create elaborate 3D landscapes, and control the lighting and camera Kodu programming involves selecting visual tiles for a condition (WHEN) and an action (DO) Students can learn about cooperation, logic and creativity, not just about programming What is Kodu? © Microsoft FUSE Labs 2014 1 Coding With Kodu Phil Anley Cracking The Code WEICT 26th June 2014 Kodu is a rich tool for narrative creation and storytelling – pulling users into creating stories Kodu demonstrates that programming is a creative medium What Can Kodu Teach? Kodu introduces the logic and problem solving of programming without complex syntax - Kodu introduces conditions and sequence, and is object-oriented Kodu builds real world, 21st century skills by challenging users to analyze a problem deeply and structure their solution – an approach applicable to all academic subjects, business and personal relationships Who Can Use Kodu? Anyone! - It can be taught by any teacher, no previous programming expertise required - Ages 8 and up typically have the most success How Do I Get Started? Download Kodu for free from fuse.microsoft.com/kodu You can start by playing the games that come with Kodu – Xevon 07 is one of our favorites. You can either use your mouse and keyboard or an Xbox Controller to play Kodu. For background and context, check out the postings on our blog: http://community.research.microsoft.com/blogs/kodu/default.aspx How do I view the Code? To view code, press the escape button on the keyboard or the back button on the controller to enter edit mode.