View About the Quality and the Already Existing Annotation of a Set of Cdnas
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The G Protein-Coupled Receptor Subset of the Dog Genome Is More Similar
BMC Genomics BioMed Central Research article Open Access The G protein-coupled receptor subset of the dog genome is more similar to that in humans than rodents Tatjana Haitina1, Robert Fredriksson1, Steven M Foord2, Helgi B Schiöth*1 and David E Gloriam*2 Address: 1Department of Neuroscience, Functional Pharmacology, Uppsala University, BMC, Box 593, 751 24, Uppsala, Sweden and 2GlaxoSmithKline Pharmaceuticals, New Frontiers Science Park, 3rd Avenue, Harlow CM19 5AW, UK Email: Tatjana Haitina - [email protected]; Robert Fredriksson - [email protected]; Steven M Foord - [email protected]; Helgi B Schiöth* - [email protected]; David E Gloriam* - [email protected] * Corresponding authors Published: 15 January 2009 Received: 20 August 2008 Accepted: 15 January 2009 BMC Genomics 2009, 10:24 doi:10.1186/1471-2164-10-24 This article is available from: http://www.biomedcentral.com/1471-2164/10/24 © 2009 Haitina et al; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Background: The dog is an important model organism and it is considered to be closer to humans than rodents regarding metabolism and responses to drugs. The close relationship between humans and dogs over many centuries has lead to the diversity of the canine species, important genetic discoveries and an appreciation of the effects of old age in another species. The superfamily of G protein-coupled receptors (GPCRs) is one of the largest gene families in most mammals and the most exploited in terms of drug discovery. -

An Evolutionary Based Strategy for Predicting Rational Mutations in G Protein-Coupled Receptors
Ecology and Evolutionary Biology 2021; 6(3): 53-77 http://www.sciencepublishinggroup.com/j/eeb doi: 10.11648/j.eeb.20210603.11 ISSN: 2575-3789 (Print); ISSN: 2575-3762 (Online) An Evolutionary Based Strategy for Predicting Rational Mutations in G Protein-Coupled Receptors Miguel Angel Fuertes*, Carlos Alonso Department of Microbiology, Centre for Molecular Biology “Severo Ochoa”, Spanish National Research Council and Autonomous University, Madrid, Spain Email address: *Corresponding author To cite this article: Miguel Angel Fuertes, Carlos Alonso. An Evolutionary Based Strategy for Predicting Rational Mutations in G Protein-Coupled Receptors. Ecology and Evolutionary Biology. Vol. 6, No. 3, 2021, pp. 53-77. doi: 10.11648/j.eeb.20210603.11 Received: April 24, 2021; Accepted: May 11, 2021; Published: July 13, 2021 Abstract: Capturing conserved patterns in genes and proteins is important for inferring phenotype prediction and evolutionary analysis. The study is focused on the conserved patterns of the G protein-coupled receptors, an important superfamily of receptors. Olfactory receptors represent more than 2% of our genome and constitute the largest family of G protein-coupled receptors, a key class of drug targets. As no crystallographic structures are available, mechanistic studies rely on the use of molecular dynamic modelling combined with site-directed mutagenesis data. In this paper, we hypothesized that human-mouse orthologs coding for G protein-coupled receptors maintain, at speciation events, shared compositional structures independent, to some extent, of their percent identity as reveals a method based in the categorization of nucleotide triplets by their gross composition. The data support the consistency of the hypothesis, showing in ortholog G protein-coupled receptors the presence of emergent shared compositional structures preserved at speciation events. -

Supplementary Table 1: Differentially Methylated Genes and Functions of the Genes Before/After Treatment with A) Doxorubicin and B) FUMI and in C) Responders Vs
Supplementary Table 1: Differentially methylated genes and functions of the genes before/after treatment with a) doxorubicin and b) FUMI and in c) responders vs. non- responders for doxorubicin and d) FUMI Differentially methylated genes before/after treatment a. Doxo GENE FUNCTION CCL5, CCL8, CCL15, CCL21, CCR1, CD33, IL5, immunoregulatory and inflammatory processes IL8, IL24, IL26, TNFSF11 CCNA1, CCND2, CDKN2A cell cycle regulators ESR1, FGF2, FGF14, FGF18 growth factors WT1, RASSF5, RASSF6 tumor suppressor b. FUMI GENE FUNCTION CCL7, CCL15, CD28, CD33, CD40, CD69, TNFSF18 immunoregulatory and inflammatory processes CCND2, CDKN2A cell cycle regulators IGF2BP1, IGFBP3 growth factors HOXB4, HOXB6, HOXC8 regulation of cell transcription WT1, RASSF6 tumor suppressor Differentially methylated genes in responders vs. non-responders c. Doxo GENE FUNCTION CBR1, CCL4, CCL8, CCR1, CCR7, CD1A, CD1B, immunoregulatory and inflammatory processes CD1D, CD1E, CD33, CD40, IL5, IL8, IL20, IL22, TLR4 CCNA1, CCND2, CDKN2A cell cycle regulators ESR2, ERBB3, FGF11, FGF12, FGF14, FGF17 growth factors WNT4, WNT16, WNT10A implicated in oncogenesis TNFSF12, TNFSF15 apoptosis FOXL1, FOXL2, FOSL1,HOXA2, HOXA7, HOXA11, HOXA13, HOXB4, HOXB6, HOXB8, HOXB9, HOXC8, regulation of cell transcription HOXD8, HOXD9, HOXD11 GSTP1, MGMT DNA repair APC, WT1 tumor suppressor d. FUMI GENE FUNCTION CCL1, CCL3, CCL5,CCL14, CD1B, CD33, CD40, CD69, immunoregulatory and inflammatory IL20, IL32 processes CCNA1, CCND2, CDKN2A cell cycle regulators IGF2BP1, IGFBP3, IGFBP7, EGFR, ESR2,RARB2 -

Supplementary Table 1
Supplementary Table 1. 492 genes are unique to 0 h post-heat timepoint. The name, p-value, fold change, location and family of each gene are indicated. Genes were filtered for an absolute value log2 ration 1.5 and a significance value of p ≤ 0.05. Symbol p-value Log Gene Name Location Family Ratio ABCA13 1.87E-02 3.292 ATP-binding cassette, sub-family unknown transporter A (ABC1), member 13 ABCB1 1.93E-02 −1.819 ATP-binding cassette, sub-family Plasma transporter B (MDR/TAP), member 1 Membrane ABCC3 2.83E-02 2.016 ATP-binding cassette, sub-family Plasma transporter C (CFTR/MRP), member 3 Membrane ABHD6 7.79E-03 −2.717 abhydrolase domain containing 6 Cytoplasm enzyme ACAT1 4.10E-02 3.009 acetyl-CoA acetyltransferase 1 Cytoplasm enzyme ACBD4 2.66E-03 1.722 acyl-CoA binding domain unknown other containing 4 ACSL5 1.86E-02 −2.876 acyl-CoA synthetase long-chain Cytoplasm enzyme family member 5 ADAM23 3.33E-02 −3.008 ADAM metallopeptidase domain Plasma peptidase 23 Membrane ADAM29 5.58E-03 3.463 ADAM metallopeptidase domain Plasma peptidase 29 Membrane ADAMTS17 2.67E-04 3.051 ADAM metallopeptidase with Extracellular other thrombospondin type 1 motif, 17 Space ADCYAP1R1 1.20E-02 1.848 adenylate cyclase activating Plasma G-protein polypeptide 1 (pituitary) receptor Membrane coupled type I receptor ADH6 (includes 4.02E-02 −1.845 alcohol dehydrogenase 6 (class Cytoplasm enzyme EG:130) V) AHSA2 1.54E-04 −1.6 AHA1, activator of heat shock unknown other 90kDa protein ATPase homolog 2 (yeast) AK5 3.32E-02 1.658 adenylate kinase 5 Cytoplasm kinase AK7 -

Supplementary Data
Supplementary Figure 1 Supplementary Figure 2 CCR-10-3244.R1 Supplementary Figure Legends Supplementary Figure 1. B-Myb is overexpressed in primary AML blasts and B-CLL cells. Baseline B-Myb mRNA levels were determined by quantitative RT-PCR, after normalization to the level of housekeeping gene, in primary B-CLL (n=10) and AML (n=5) patient samples, and in normal CD19+ (n=5) and CD34+ (n=4) cell preparations. Each sample was determined in triplicate. Horizontal bars are median, upper and lower edges of box are 75th and 25th percentiles, lines extending from box are 10th and 90th percentiles. Supplementary Figure 2. Cytotoxicity by Nutlin-3 and Chlorambucil used alone or in combination in leukemic cells. The p53wild-type EHEB and SKW6.4 cells lines, and the p53mutated BJAB cell line were exposed to Nutlin-3 or Chlorambucil used either alone or in combination. (Nutl.+Chlor.). In A, upon treatment with Nutlin-3 or Chlorambucil, used either alone (both at 10 μM) or in combination (Nutl.+Chlor.), induction of apoptosis was quantitatively evaluated by Annexin V/PI staining, while E2F1 and pRb protein levels were analyzed by Western blot. Tubulin staining is shown as loading control. The average combination index (CI) values (analyzed by the method of Chou and Talalay) for effects of Chlorambucil+Nutlin-3 on cell viability are shown. ED indicates effect dose. In B, levels of B-Myb and E2F1 mRNA were analyzed by quantitative RT- PCR. Results are expressed as fold of B-Myb and E2F1 modulation in cells treated for 24 hours as indicated, with respect to the control untreated cultures set to 1 (hatched line). -

Table S1 Changes in the Expression Levels of Genes Induced by Sevoflurane
Table S1 Changes in the expression levels of genes induced by sevoflurane * Gene ID Gene abbreviation log2 ratio Rtn4rl2 Reticulon 4 receptor-like 2 7.80 Mas1 MAS1 oncogene 7.76 Gpx6 Glutathione peroxidase 6 7.62 Ovol2 Ovo-like 2 (Drosophila) 7.19 Calcr Calcitonin receptor 6.81 Impg1 Interphotoreceptor matrix proteoglycan 1 6.72 Neurod6 Neurogenic differentiation 6 6.33 Neurod2 Neurogenic differentiation 2 6.30 Dio3 Deiodinase, iodothyronine type III 5.91 Cd6 CD6 antigen 5.80 Gucy2g Guanylate cyclase 2g 5.75 Jsrp1 Junctional sarcoplasmic reticulum protein 1 5.56 Slc38a4 Solute carrier family 38, member 4 5.51 Tmprss6 Transmembrane serine protease 6 5.47 Sh3rf2 SH3 domain containing ring finger 2 5.41 Ccbp2 Chemokine binding protein 2 5.33 Gprc5a G protein-coupled receptor, family C, group 5, member A 5.27 Clspn Claspin homolog (Xenopus laevis) 5.21 Robo3 Roundabout homolog 3 (Drosophila) 5.21 Figf C-fos induced growth factor 5.20 Trpc6 Transient receptor potential cation channel, subfamily C, member 6 5.19 Adora2a Adenosine A2a receptor 5.12 Tbx15 T-box 15 5.07 Cdsn Corneodesmosin 5.02 Cd4 CD4 antigen 5.02 Col19a1 Collagen, type XIX, alpha 1 4.98 Kcnh3 Potassium voltage-gated channel, subfamily H (eag-related), member 3 4.94 Gpr88 G-protein coupled receptor 88 4.90 C1qtnf7 C1q and tumor necrosis factor related protein 7 4.88 Serine (or cysteine) peptidase inhibitor, clade A (alpha-1 antiproteinase, Serpina9 antitrypsin), member 9 4.87 Il20ra Interleukin 20 receptor, alpha 4.79 Lrg1 Leucine-rich alpha-2-glycoprotein 1 4.78 Rpe65 Retinal -

Theoretical Study of the Interaction of Agonists with the 5-HT2A Receptor
Theoretical study of the interaction of agonists with the 5-HT2A receptor Dissertation zur Erlangung des Doktorgrades der Naturwissenschaften (Dr. rer. nat) der Fakultät für Chemie und Pharmazie der Universität Regensburg vorgelegt von Maria Elena Silva aus Buccinasco Regensburg 2008 Die vorliegende Arbeit wurde in der Zeit von Oktober 2004 bis August 2008 an der Fakultät für Chemie und Pharmazie der Universität Regensburg in der Arbeitsgruppe von Prof. Dr. A. Buschauer unter der Leitung von Prof. Dr. S. Dove angefertigt Die Arbeit wurde angeleitet von: Prof. Dr. S. Dove Promotiongesucht eingereicht am: 28. Juli 2008 Promotionkolloquium am 26. August 2008 Prüfungsausschuß: Vorsitzender: Prof. Dr. A. Buschauer 1. Gutachter: Prof. Dr. S. Dove 2. Gutachter: Prof. Dr. S. Elz 3. Prüfer: Prof. Dr. H.-A. Wagenknecht I Contents 1 Introduction ......................................................................................................... 1 1.1 G protein coupled receptors .....................................................................................1 1.1.1 GPCR classification ............................................................................................2 1.1.2 Signal transduction mechanisms in GPCRs .......................................................4 1.2 Serotonin (5-hydroxytryptamine, 5-HT) ....................................................................7 1.2.1 Historical overview ..............................................................................................7 1.2.2 Biosynthesis and metabolism -
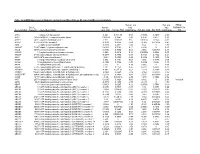
Mrna Expression in Human Leiomyoma and Eker Rats As Measured by Microarray Analysis
Table 3S: mRNA Expression in Human Leiomyoma and Eker Rats as Measured by Microarray Analysis Human_avg Rat_avg_ PENG_ Entrez. Human_ log2_ log2_ RAPAMYCIN Gene.Symbol Gene.ID Gene Description avg_tstat Human_FDR foldChange Rat_avg_tstat Rat_FDR foldChange _DN A1BG 1 alpha-1-B glycoprotein 4.982 9.52E-05 0.68 -0.8346 0.4639 -0.38 A1CF 29974 APOBEC1 complementation factor -0.08024 0.9541 -0.02 0.9141 0.421 0.10 A2BP1 54715 ataxin 2-binding protein 1 2.811 0.01093 0.65 0.07114 0.954 -0.01 A2LD1 87769 AIG2-like domain 1 -0.3033 0.8056 -0.09 -3.365 0.005704 -0.42 A2M 2 alpha-2-macroglobulin -0.8113 0.4691 -0.03 6.02 0 1.75 A4GALT 53947 alpha 1,4-galactosyltransferase 0.4383 0.7128 0.11 6.304 0 2.30 AACS 65985 acetoacetyl-CoA synthetase 0.3595 0.7664 0.03 3.534 0.00388 0.38 AADAC 13 arylacetamide deacetylase (esterase) 0.569 0.6216 0.16 0.005588 0.9968 0.00 AADAT 51166 aminoadipate aminotransferase -0.9577 0.3876 -0.11 0.8123 0.4752 0.24 AAK1 22848 AP2 associated kinase 1 -1.261 0.2505 -0.25 0.8232 0.4689 0.12 AAMP 14 angio-associated, migratory cell protein 0.873 0.4351 0.07 1.656 0.1476 0.06 AANAT 15 arylalkylamine N-acetyltransferase -0.3998 0.7394 -0.08 0.8486 0.456 0.18 AARS 16 alanyl-tRNA synthetase 5.517 0 0.34 8.616 0 0.69 AARS2 57505 alanyl-tRNA synthetase 2, mitochondrial (putative) 1.701 0.1158 0.35 0.5011 0.6622 0.07 AARSD1 80755 alanyl-tRNA synthetase domain containing 1 4.403 9.52E-05 0.52 1.279 0.2609 0.13 AASDH 132949 aminoadipate-semialdehyde dehydrogenase -0.8921 0.4247 -0.12 -2.564 0.02993 -0.32 AASDHPPT 60496 aminoadipate-semialdehyde -

An Update on the Tissue Renin Angiotensin System and Its Role in Physiology and Pathology
Journal of Cardiovascular Development and Disease Review An Update on the Tissue Renin Angiotensin System and Its Role in Physiology and Pathology Ali Nehme 1 , Fouad A. Zouein 2 , Zeinab Deris Zayeri 3 and Kazem Zibara 4,* 1 EA4173, Functional genomics of arterial hypertension, Univeristy Claude Bernard Lyon-1 (UCBL-1), 69008 Lyon, France; [email protected] 2 Department of Pharmacology and Toxicology, Heart Repair Division, Faculty of Medicine, American University of Beirut, Beirut 11-0236, Lebanon; [email protected] 3 Thalassemia & Hemoglobinopathy Research Center, Health Research Institute, Ahvaz Jundishapur University of Medical Sciences, Ahvaz, Iran; [email protected] 4 PRASE, Biology Department, Faculty of Sciences-I, Lebanese University, Beirut, Lebanon * Correspondence: [email protected] Received: 10 February 2019; Accepted: 26 March 2019; Published: 29 March 2019 Abstract: In its classical view, the renin angiotensin system (RAS) was defined as an endocrine system involved in blood pressure regulation and body electrolyte balance. However, the emerging concept of tissue RAS, along with the discovery of new RAS components, increased the physiological and clinical relevance of the system. Indeed, RAS has been shown to be expressed in various tissues where alterations in its expression were shown to be involved in multiple diseases including atherosclerosis, cardiac hypertrophy, type 2 diabetes (T2D) and renal fibrosis. In this chapter, we describe the new components of RAS, their tissue-specific expression, and their alterations under pathological conditions, which will help achieve more tissue- and condition-specific treatments. Keywords: renin-angiotensin-aldosterone system; tissue; expression; physiology 1. Introduction In its classical view, RAS was defined as an endocrine system involved in blood pressure regulation and body electrolyte balance. -

Mrna and Mirna Profiles in the Nucleus Accumbens Are Associated with Psychological Stress-Induced Susceptible and Resilient Mice
Pharmacology, Biochemistry and Behavior 199 (2020) 173062 Contents lists available at ScienceDirect Pharmacology, Biochemistry and Behavior journal homepage: www.elsevier.com/locate/pharmbiochembeh mRNA and miRNA profiles in the nucleus accumbens are associated with psychological stress-induced susceptible and resilient mice Yanjun Lu a, Jiuyong Yang a, Jinyan Sun a, Wei Lu a,*, Jin-Hui Wang a,b,c,** a Qingdao University, School of Pharmacy, Qingdao, Shandong 266021, China b University of Chinese Academy of Sciences, Beijing 100049, China c Institute of Biophysics, Chinese Academy of Sciences, Beijing 100101, China ARTICLE INFO ABSTRACT Keywords: Background: Stress may be one of the main causes of fear and anxiety. Previous studies have shown that the Psychological stress nucleus accumbens is involved in emotional responses. However, in the nucleus accumbens, the mRNA and Susceptibility miRNA profiles of stress susceptibility and resilience of psychological stress still need to be studied. Resilience Materials and methods: In this study, by observing the conspecific being attacked, the witness group experienced Anxiety psychological stress. After five days of psychological stress, the fear memory of mice was measured by social Nucleus accumbens interaction test, and the degree of anxiety was measured by elevated plus maze. mRNA and miRNA profilesin the nucleus accumbens tissue of control, susceptible and resilient mice were established by high-throughput sequencing. Results: In susceptible mice versus resilient mice, the Differentially expressed genes (DEGs) may be related to psychological stress-induced susceptibility. DEGs enriched in Cell adhesion molecules, Neuroactive ligand- receptor interaction, Gap junction, PI3K-Akt, VEGF, Jak-STAT, Ras, and Chemokine pathways were up- regulated. -

RT² Profiler PCR Array (384-Well Format) Mouse G Protein Coupled Receptors 384HT
RT² Profiler PCR Array (384-Well Format) Mouse G Protein Coupled Receptors 384HT Cat. no. 330231 PAMM-3009ZE For pathway expression analysis Format For use with the following real-time cyclers RT² Profiler PCR Array, Applied Biosystems® models 7900HT (384-well block), Format E ViiA™ 7 (384-well block); Bio-Rad CFX384™ RT² Profiler PCR Array, Roche® LightCycler® 480 (384-well block) Format G Description The Mouse G Protein Coupled Receptors 384HT RT² Profiler™ PCR Array profiles the expression of a comprehensive panel of 370 genes encoding the most important G Protein Coupled Receptors (GPCR). GPCR regulate a number of normal biological processes and play roles in the pathophysiology of many diseases upon dysregulation of their downstream signal transduction activities. As a result, they represent 30 percent of the targets for all current drug development. Developing drug screening assays requires a survey of which GPCR the chosen cell-based model system expresses, to determine not only the expression of the target GPCR, but also related GPCR to assess off-target side effects. Expression of other unrelated GPCR (even orphan receptors whose ligand are unknown) may also correlate with off-target side effects. The ligands that bind and activate the receptors on this array include neurotransmitters and neuropeptides, hormones, chemokines and cytokines, lipid signaling molecules, light-sensitive compounds, and odorants and pheromones. The normal biological processes regulated by GPCR include, but are not limited to, behavioral and mood regulation (serotonin, dopamine, GABA, glutamate, and other neurotransmitter receptors), autonomic (sympathetic and parasympathetic) nervous system transmission (blood pressure, heart rate, and digestive processes via hormone receptors), inflammation and immune system regulation (chemokine receptors, histamine receptors), vision (opsins like rhodopsin), and smell (olfactory receptors for odorants and vomeronasal receptors for pheromones). -

The Emerging Mutational Landscape of G Proteins and G-Protein-Coupled
ANALYSIS The emerging mutational landscape of G proteins and G‑protein‑coupled receptors in cancer Morgan O’Hayre1, José Vázquez-Prado2, Irina Kufareva3, Eric W. Stawiski4,5, Tracy M. Handel3, Somasekar Seshagiri4 and J. Silvio Gutkind1 Abstract | Aberrant expression and activity of G proteins and G-protein-coupled receptors (GPCRs) are frequently associated with tumorigenesis. Deep sequencing studies show that 4.2% of tumours carry activating mutations in GNAS (encoding Gαs), and that oncogenic activating mutations in genes encoding Gαq family members (GNAQ or GNA11) are present in ~66% and ~6% of melanomas arising in the eye and skin, respectively. Furthermore, nearly 20% of human tumours harbour mutations in GPCRs. Many human cancer-associated viruses also express constitutively active viral GPCRs. These studies indicate that G proteins, GPCRs and their linked signalling circuitry represent novel therapeutic targets for cancer prevention and treatment. The G-protein-coupled receptor (GPCR) family of proteins G protein and GPCR signalling comprises approximately 4% of the encoded human genes: The widely accepted model for GPCR activation involves 1Oral and Pharyngeal Cancer Branch, Dental and with over 800 members, it is the largest family of cell- the binding of an agonist ligand at the extracellular side Craniofacial Research, surface receptors involved in signal transduction. These of the receptor, which induces a conformational change in National Institutes of Health, proteins are characterized by a seven-transmembrane the receptor and alters the position of its transmembrane Bethesda, Maryland 20892, domain structure with an extracellular amino terminus helices and intracellular loops. In this active conforma- USA. and an intracellular carboxyl terminus.