PHRP March 2015
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
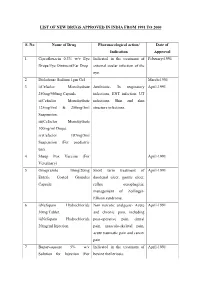
List of New Drugs Approved in India from 1991 to 2000
LIST OF NEW DRUGS APPROVED IN INDIA FROM 1991 TO 2000 S. No Name of Drug Pharmacological action/ Date of Indication Approval 1 Ciprofloxacin 0.3% w/v Eye Indicated in the treatment of February-1991 Drops/Eye Ointment/Ear Drop external ocular infection of the eye. 2 Diclofenac Sodium 1gm Gel March-1991 3 i)Cefaclor Monohydrate Antibiotic- In respiratory April-1991 250mg/500mg Capsule. infections, ENT infection, UT ii)Cefaclor Monohydrate infections, Skin and skin 125mg/5ml & 250mg/5ml structure infections. Suspension. iii)Cefaclor Monohydrate 100mg/ml Drops. iv)Cefaclor 187mg/5ml Suspension (For paediatric use). 4 Sheep Pox Vaccine (For April-1991 Veterinary) 5 Omeprazole 10mg/20mg Short term treatment of April-1991 Enteric Coated Granules duodenal ulcer, gastric ulcer, Capsule reflux oesophagitis, management of Zollinger- Ellison syndrome. 6 i)Nefopam Hydrochloride Non narcotic analgesic- Acute April-1991 30mg Tablet. and chronic pain, including ii)Nefopam Hydrochloride post-operative pain, dental 20mg/ml Injection. pain, musculo-skeletal pain, acute traumatic pain and cancer pain. 7 Buparvaquone 5% w/v Indicated in the treatment of April-1991 Solution for Injection (For bovine theileriosis. Veterinary) 8 i)Kitotifen Fumerate 1mg Anti asthmatic drug- Indicated May-1991 Tablet in prophylactic treatment of ii)Kitotifen Fumerate Syrup bronchial asthma, symptomatic iii)Ketotifen Fumerate Nasal improvement of allergic Drops conditions including rhinitis and conjunctivitis. 9 i)Pefloxacin Mesylate Antibacterial- In the treatment May-1991 Dihydrate 400mg Film Coated of severe infection in adults Tablet caused by sensitive ii)Pefloxacin Mesylate microorganism (gram -ve Dihydrate 400mg/5ml Injection pathogens and staphylococci). iii)Pefloxacin Mesylate Dihydrate 400mg I.V Bottles of 100ml/200ml 10 Ofloxacin 100mg/50ml & Indicated in RTI, UTI, May-1991 200mg/100ml vial Infusion gynaecological infection, skin/soft lesion infection. -

Dispensing of Vitamin Products by Retail Pharmacies in South Africa: Implications for Dietitians
South African Journal of Clinical Nutrition 2016; 29(4):133–138 http://dx.doi.org/10.1080/16070658.2016.1219468 SAJCN ISSN 1607-0658 EISSN 2221-1268 Open Access article distributed under the terms of the © 2016 The Author(s) Creative Commons License [CC BY-NC 3.0] http://creativecommons.org/licenses/by-nc/3.0 RESEARCH Dispensing of vitamin products by retail pharmacies in South Africa: Implications for dietitians Ilse Trutera* and Liana Steenkampb a Department of Pharmacy, Drug Utilisation Research Unit (DURU), Nelson Mandela Metropolitan University, Port Elizabeth, South Africa b HIV & AIDS Research Unit, Nelson Mandela Metropolitan University, Port Elizabeth, South Africa *Corresponding author, email: [email protected] Objective: The objective of this study was to analyse the dispensing patterns of vitamins (Anatomical Therapeutic Chemical (ATC) group A11) over a one-year period in a group of community pharmacies in South Africa. Design and setting: A retrospective drug utilisation study was conducted on community pharmacy electronic dispensing records in South Africa recorded in 2013. Outcome measures: All products for ATC subgroup A11 were extracted and analysed. Results: A total of 164 233 vitamin products were dispensed to 84 805 patients (62.64% female patients). Males received on average 2.09 (SD = 2.63) vitamin products per year, compared to 1.84 (SD = 2.13) products for females. Ergocalciferol (A11CC01) was the most often dispensed (37.48% of all vitamin products), followed by plain Vitamin B-complex products (A11EA00) accounting for 32.77%. Ergocalciferol (vitamin D2) is only available on prescription (50 000 IU tablets or 50 000 IU/ml oily drops) in South Africa. -

Report on Effects of Beta-Carotene Supplementation in Combination with Tocopherol and Ascorbate in Clinical and Chemopreventive Trials (Adopted by the SCF on 19/3/98)
Report on Effects of Beta-carotene Supplementation in Combination with Tocopherol and Ascorbate in Clinical and Chemopreventive Trials (Adopted by the SCF on 19/3/98) Terms of Reference The committee was asked by the Commission to review on recent reports of the studies on health effects of high doses of beta-carotene, retinol and alpha-tocopherol as well as ascorbate in controlled studies. Introduction Epidemiological studies of the last ten years have indicated that beta-carotene is a potential agent for the chemical prevention against carcinogenesis. In contrast, the recent prospective study performed by Heinonen et al. (1) has strikingly suggested that supplementation with beta-carotene significantly increased the incidence of lung, prostate and stomach cancer. The rising question is the possible dose dependency of a preventive or harmful action of beta-carotene and possible synergistic effects with other antioxidants. To answer this question clinical trials for therapy and intervention studies in healthy populations dealing with beta- carotene supplementation in different dosages below the GRAS daily intake of 200 mg have to be regarded. Clinical trials Therapeutic dosages of beta-carotene applied varied in a relative wide range of 20 mg/d to 180 mg/d. The highest daily dosage of 180 mg beta-carotene in combination with 100.000 IU vitamin A ( 30 mg retinol equivalents) was applied 1988 by Stich et al. (2) in tobacco chewers who had already sustained premalignant leukoplakia. After 6 months the single treatment with beta-carotene induced a significant remission of leukoplakias compared to the placebo group, although the combination of beta-carotene and retinol was much more effective. -

NIH Public Access Author Manuscript Pharmacol Ther
NIH Public Access Author Manuscript Pharmacol Ther. Author manuscript; available in PMC 2010 August 1. NIH-PA Author ManuscriptPublished NIH-PA Author Manuscript in final edited NIH-PA Author Manuscript form as: Pharmacol Ther. 2009 August ; 123(2): 239±254. doi:10.1016/j.pharmthera.2009.04.002. Ethnobotany as a Pharmacological Research Tool and Recent Developments in CNS-active Natural Products from Ethnobotanical Sources Will C. McClatcheya,*, Gail B. Mahadyb, Bradley C. Bennettc, Laura Shielsa, and Valentina Savod a Department of Botany, University of Hawaìi at Manoa, Honolulu, HI 96822, U.S.A b Department of Pharmacy Practice, University of Illinois at Chicago, Chicago, IL 60612, U.S.A c Department of Biological Sciences, Florida International University, Miami, FL 33199, U.S.A d Dipartimento di Biologia dì Roma Trè, Viale Marconi, 446, 00146, Rome, Italy Abstract The science of ethnobotany is reviewed in light of its multidisciplinary contributions to natural product research for the development of pharmaceuticals and pharmacological tools. Some of the issues reviewed involve ethical and cultural perspectives of healthcare and medicinal plants. While these are not usually part of the discussion of pharmacology, cultural concerns potentially provide both challenges and insight for field and laboratory researchers. Plant evolutionary issues are also considered as they relate to development of plant chemistry and accessing this through ethnobotanical methods. The discussion includes presentation of a range of CNS-active medicinal plants that have been recently examined in the field, laboratory and/or clinic. Each of these plants is used to illustrate one or more aspects about the valuable roles of ethnobotany in pharmacological research. -

Nexium Control, Esomeprazole
27 June 2013 EMA/498929/2013 Committee for Medicinal Products for Human Use (CHMP) Assessment report Nexium Control International non-proprietary name: esomeprazole Procedure No. EMEA/H/C/002618 Note Assessment report as adopted by the CHMP with all information of a commercially confidential nature deleted. 7 Westferry Circus ● Canary Wharf ● London E14 4HB ● United Kingdom Telephone +44 (0)20 7418 8400 Facsimile +44 (0)20 7418 8613 E -mail [email protected] Website www.ema.europa.eu An agency of the European Union © European Medicines Agency, 2013. Reproduction is authorised provided the source is acknowledged. Product information Marketing authorisation application Name of the medicinal product: Nexium Control Applicant: AstraZeneca AB Building 411A, Floor 4 S - 151 85 Södertälje SWEDEN Active substance: esomeprazole (as magnesium trihydrate) International Nonproprietary Name/Common Name: esomeprazole Pharmaco-therapeutic group Proton pump inhibitors (ATC Code): (A02BC05) Therapeutic indication: Nexium Control is indicated for the short-term treatment of reflux symptoms (e.g. heartburn and acid regurgitation) in adults. Pharmaceutical form: Gastro-resistant tablet Strength: 20 mg Route of administration: Oral use Packaging: blister (PVC/PVDC) Package sizes: 7 tablets and 14 tablets Assessment report EMA/498929/2013 Page 2/70 Table of contents 1. Background information on the procedure .............................................. 6 1.1. Submission of the dossier ..................................................................................... -

Ijcep0048253.Pdf
Int J Clin Exp Pathol 2017;10(4):4089-4098 www.ijcep.com /ISSN:1936-2625/IJCEP0048253 Original Article Comparative effectiveness of different recommended doses of omeprazole and lansoprazole for gastroesophageal reflux disease: a meta-analysis of published data Feng Liu1, Jing Wang1, Hailong Wu1, Hui Wang2, Jianxiang Wang1, Rui Zhou1, Zhi Zhu3 Departments of 1Surgery, 2Gastroenterology, 3Epidemiology and Biostatistics, Puai Hospital, Tongji Medical College, Huazhong University of Science and Technology, Wuhan, China Received January 6, 2017; Accepted February 20, 2017; Epub April 1, 2017; Published April 15, 2017 Abstract: This meta-analysis aims to evaluate the effectiveness of different recommended doses of omeprazole and lansoprazole on gastroesophageal reflux diseases (GERD) in adults. The electronic databases of PubMed, EMBASE, Cochrane Library, and ClinicalTrials.gov were searched before September 13 2016. Fifteen eligible studies were identified involving 8752 patients in our meta-analysis. For the healing outcome of esophagitis, compared with 15 mg per day of lansoprazole, there were significant difference of both 30 mg per day of lansoprazole (RR=1.29, 95% CI [1.01, 1.66], I2=79.3%, P=0.028) and 60 mg per day of lansoprazole (RR=1.59, 95% CI [1.28, 1.99], I2=Not ap- plicable (NA), P=NA), and the other result were not significantly different between 60 mg per day and 30 mg per day. For relief of symptoms, our result indicated a significant difference between 20 mg per day and 10 mg per day of omeprazole (RR=1.21, 95% CI [1.06, 1.39], I2=53.9%, P=0.089); the overall result indicated a significant difference between lansoprazole and omeprazole (RR=0.93, 95% CI [0.86, 0.999], I2=60.7%, P=0.038). -

Protonix Protonix
NDA 22-020 Page 4 PROTONIX® (pantoprazole sodium) Delayed-Release Tablets PROTONIX® (pantoprazole sodium) For Delayed-Release Oral Suspension Rx only DESCRIPTION ® The active ingredient in PROTONIX (pantoprazole sodium) Delayed-Release Tablets and ® PROTONIX (pantoprazole sodium) For Delayed-Release Oral Suspension is a substituted benzimidazole, sodium 5-(difluoromethoxy)-2-[[(3,4-dimethoxy-2-pyridinyl)methyl] sulfinyl]- 1H-benzimidazole sesquihydrate, a compound that inhibits gastric acid secretion. Its empirical formula is C16H14F2N3NaO4S x 1.5 H2O, with a molecular weight of 432.4. The structural formula is: Pantoprazole sodium sesquihydrate is a white to off-white crystalline powder and is racemic. Pantoprazole has weakly basic and acidic properties. Pantoprazole sodium sesquihydrate is freely soluble in water, very slightly soluble in phosphate buffer at pH 7.4, and practically insoluble in n-hexane. The stability of the compound in aqueous solution is pH-dependent. The rate of degradation increases with decreasing pH. At ambient temperature, the degradation half-life is approximately 2.8 hours at pH 5.0 and approximately 220 hours at pH 7.8. PROTONIX (pantoprazole sodium) is supplied as a delayed-release tablet for oral administration, available in 2 strengths (40 mg and 20 mg); and as delayed-release granules for oral administration, available in the 40 mg strength. NDA 22-020 Page 5 Each PROTONIX (pantoprazole sodium) Delayed-Release tablet contains 45.1 mg or 22.6 mg of pantoprazole sodium sesquihydrate (equivalent to 40 mg or 20 mg pantoprazole, respectively) with the following inactive ingredients: calcium stearate, crospovidone, hypromellose, iron oxide, mannitol, methacrylic acid copolymer, polysorbate 80, povidone, propylene glycol, sodium carbonate, sodium lauryl sulfate, titanium dioxide, and triethyl citrate. -

Proton Pump Inhibitors (PPI) Preferred Step Therapy Program Annual Review Date: 01/18/2021
Policy: Proton Pump Inhibitors (PPI) Preferred Step Therapy Program Annual Review Date: 01/18/2021 Impacted Last Revised Date: Drugs: • Aciphex, Aciphex Sprinkle • Dexilant 06/17/2021 • Esomeprazole DR, esomeprazole strontium DR • Nexium • Omeprazole/sodium bicarbonate • Prevacid, Prevacid 24HR, Prevacid SoluTab • Prilosec • Protonix • Rabeprazole DR OVERVIEW Proton pump inhibitors (PPIs) [i.e., esomeprazole, dexlansoprazole, lansoprazole, omeprazole, pantoprazole, and rabeprazole] are commonly used antisecretory agents that are highly effective at suppressing gastric acid and subsequently treating associated conditions, including gastroesophageal reflux disease (GERD). Omeprazole is available generically and over-the-counter (OTC). Omeprazole OTC is prescription strength (20 mg). Lansoprazole is also available generically and OTC. Lansoprazole OTC is available as 15 mg capsules. Zegerid capsules are available generically and OTC; the OTC product contains omeprazole 20 mg and sodium bicarbonate 1100 mg. Nexium® 24HR (esomeprazole magnesium 22.3 mg delayed-release capsules) is available OTC and is equivalent to 20 mg of esomeprazole base. The OTC products are indicated for the short-term (14 days) treatment of heartburn. Patients should not take the OTC products for more than 14 days or more often than every 4 months unless under the supervision of a physician. Although the PPIs vary in their specific Food and Drug Administration (FDA)-approved indications, all of the PPIs have demonstrated the ability to control GERD symptoms and to heal esophagitis when used at prescription doses. Most comparative studies between PPIs to date have demonstrated comparable efficacies for acid-related diseases, including duodenal and gastric ulcerations, GERD, Zollinger-Ellison syndrome, and H. pylori eradication therapies. Though the available clinical data are not entirely complete for the comparison of these agents, many clinical trials have shown the PPIs to be similar in safety and efficacy. -

Receptor Antagonist (H RA) Shortages | May 25, 2020 2 2 2 GERD4,5 • Take This Opportunity to Determine If Continued Treatment Is Necessary
H2-receptor antagonist (H2RA) Shortages Background . 2 H2RA Alternatives . 2 Therapeutic Alternatives . 2 Adults . 2 GERD . 3 PUD . 3 Pediatrics . 3 GERD . 3 PUD . 4 Tables Table 1: Health Canada–Approved Indications of H2RAs . 2 Table 2: Oral Adult Doses of H2RAs and PPIs for GERD . 4 Table 3: Oral Adult Doses of H2RAs and PPIs for PUD . 5 Table 4: Oral Pediatric Doses of H2RAs and PPIs for GERD . 6 Table 5: Oral Pediatric Doses of H2RAs and PPIs for PUD . 7 References . 8 H2-receptor antagonist (H2RA) Shortages | May 25, 2020 1 H2-receptor antagonist (H2RA) Shortages BACKGROUND Health Canada recalls1 and manufacturer supply disruptions may be causing shortages of commonly used acid-reducing medications called histamine H2-receptor antagonists (H2RAs) . H2RAs include cimetidine, famotidine, nizatidine and ranitidine . 2 There are several Health Canada–approved indications of H2RAs (see Table 1); this document addresses the most common: gastroesophageal reflux disease (GERD) and peptic ulcer disease (PUD) . 2 TABLE 1: HEALTH CANADA–APPROVED INDICATIONS OF H2RAs H -Receptor Antagonists (H RAs) Health Canada–Approved Indications 2 2 Cimetidine Famotidine Nizatidine Ranitidine Duodenal ulcer, treatment ü ü ü ü Duodenal ulcer, prophylaxis — ü ü ü Benign gastric ulcer, treatment ü ü ü ü Gastric ulcer, prophylaxis — — — ü GERD, treatment ü ü ü ü GERD, maintenance of remission — ü — — Gastric hypersecretion,* treatment ü ü — ü Self-medication of acid indigestion, treatment and prophylaxis — ü† — ü† Acid aspiration syndrome, prophylaxis — — — ü Hemorrhage from stress ulceration or recurrent bleeding, — — — ü prophylaxis ü = Health Canada–approved indication; GERD = gastroesophageal reflux disease *For example, Zollinger-Ellison syndrome . -

Fluid Ophthalmic Composition Based on Lipid Microparticles Containing at Least One Active Principle
Europaisches Patentamt J European Patent Office Office europden des brevets (11) Publication number : 0 437 368 A1 EUROPEAN PATENT APPLICATION (21) Application number: 91300181.4 ® int. ci.5 : A61K 9/06, A61K 9/16 @ Date of filing : 10.01.91 © Priority : 12.01.90 FR 9000340 (72) Inventor : Rozier, Annouk 23 Bd Lafayette F-63000 Clermont-Ferrand (FR) @ Date of publication of application : 17.07.91 Bulletin 91/29 74) Representative : Hesketh, Alan, Dr. et al European Patent Department Merck & Co., @ Designated Contracting States : Inc. Tertings Park Eastwick Road CH DE FR GB IT LI NL Harlow Essex, CM20 2QR (GB) © Applicant : LABORATOIRES MERCK, SHARP & DOHME-CHIBRET 3, Avenue Hoche F-75008 Paris (FR) (S) Fluid ophthalmic composition based on lipid microparticles containing at least one active principle. (57) There is described a fluid ophthalmic composition which comprises a suspension in a fluid dispersant medium of lipid microparticles containing at least one active principle. The composition enables improved availability of the active principle to be obtained as a result of high intraocular levels. 00 <0 CO Q. UJ Jouve, 18, rue Saint-Denis, 75001 PARIS EP 0 437 368 A1 FLUID OPHTHALMIC COMPOSITION BASED ON LIPID MICROPARTICLES CONTAINING AT LEAST ONE ACTIVE PRINCIPLE The present invention relates to a fluid ophthalmic composition. Many ophthalmic compositions are currently available in liquid or solid form, but none of them is, in fact, completely satisfactory. In effect, liquid ophthalmic compositions, although easy to use, have some drawbacks ; in particular, it is 5 difficult to obtain a sustained or delayed action of the active principle which they contain. -

Quality Use of Medicines in Residential Aged Care
RESEARCH Quality use of medicines in Michael Somers residential aged care Ella Rose Dasha Simmonds Claire Whitelaw Janine Calver Christopher Beer Background Approximately 190 000 people in high risk of ADEs in frail older people. For example, Older people are more likely to be Australia were estimated to have anticholinergic drugs commonly produce adverse exposed to polypharmacy. People dementia in 2006, with the prevalence effects in elderly people and are more likely to be with dementia, especially those living expected to increase to 465 000 by 2031.1 prescribed to people with dementia than those in residential aged care facilities The prevalence of dementia increases without.7 (RACFs), are at particularly high risk of with age, from 6.5% of Australians aged Antipsychotic medications are commonly used medication harm. We sought to describe medications prescribed for a sample of 65 years and over to 22% of Australians to manage the behavioural and psychological 2 people with dementia living in RACFs. aged 85 years and over. Dementia is symptoms of dementia (BPSD), such as associated with a large burden of disease psychosis, depression, agitation, aggression Methods in Australia’s aging population, costing and disinhibition.1,8 There is concern that A total of 351 residents with dementia Australia $1.4 billion in 2003.2 Most of this antipsychotics are used too frequently as a aged over 65 years were recruited from 36 RACFs in Western Australia. burden was associated with residential first line treatment for BPSD, with the risks of 2 Data on all medications prescribed aged care facilities (RACFs). Dementia antipsychotic use outweighing the benefits at their were collected, including conventional is the medical problem most frequently likely level of use.8 For example, risperidone, an medications, herbal medications, managed by general practitioners atypical antipsychotic prescribed frequently for the vitamins and minerals. -

Health and Social Outcomes Associated with High-Risk Alcohol Use
Manitoba Centre for Health Policy Health and Social Outcomes Associated with High-Risk Alcohol Use Summer 2018 Nathan C Nickel, MPH, PhD Jeff Valdivia, MNRM, CAPM Deepa Singal, PhD James Bolton, MD Christine Leong, PharmD Susan Burchill, BMus Leonard MacWilliam, MSc, MNRM Geoffrey Konrad, MD Randy Walld, BSc, BComm (Hons) Okechukwu Ekuma, MSc Greg Finlayson, PhD Leanne Rajotte, BComm (Hons) Heather Prior, MSc Josh Nepon, MD Michael Paille, BHSc This report is produced and published by the Manitoba Centre for Health Policy (MCHP). It is also available in PDF format on our website at: http://mchp-appserv.cpe.umanitoba.ca/deliverablesList.html Information concerning this report or any other report produced by MCHP can be obtained by contacting: Manitoba Centre for Health Policy Rady Faculty of Health Sciences Max Rady College of Medicine, University of Manitoba 4th Floor, Room 408 727 McDermot Avenue Winnipeg, Manitoba, Canada R3E 3P5 Email: [email protected] Phone: (204) 789-3819 Fax: (204) 789-3910 How to cite this report: Nathan C Nickel, James Bolton, Leonard MacWilliam, Okechukwu Ekuma, Heather Prior, Jeff Valdivia, Christine Leong, Geoffrey Konrad, Greg Finlayson, Josh Nepon, Deepa Singal, Susan Burchill, Randy Walld, Leanne Rajotte, Michael Paille. Health and Social Outcomes Associated with High-Risk Alcohol Use. Winnipeg, MB. Manitoba Centre for Health Policy, Summer 2018. Legal Deposit: Manitoba Legislative Library National Library of Canada ISBN 978-1-896489-90-2 ©Manitoba Health This report may be reproduced, in whole or in part, provided the source is cited. 1st printing (Summer 2018) This report was prepared at the request of Manitoba Health, Seniors and Active Living (MHSAL), a department within the Government of Manitoba, as part of the contract between the University of Manitoba and MHSAL.