Learning Phonotactics Using ILP
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Syllabic Consonants and Phonotactics Syllabic Consonants
Syllabic consonants and phonotactics Syllabic consonants Consonants that stand as the peak of the syllable, and perform the functions of vowels, are called syllabic consonants. For example, in words like sudden and saddle, the consonant [d] is followed by either the consonant [n] or [l] without a vowel intervening. The [n] of sadden and the [l] of saddle constitute the centre of the second, unstressed, syllable and are considered to be syllabic peaks. They typically occur in an unstressed syllable immediately following the alveolar consonants, [t, s, z] as well as [d]. Examples of syllabic consonants Cattle [kæțɬ] wrestle [resɬ] Couple [kʌpɬ] knuckle [nʌkɬ] Panel[pæņɬ] petal [petɬ] Parcel [pa:șɬ] pedal [pedɬ] It is not unusual to find two syllabic consonants together. Examples are: national [næʃņɬ] literal [litrɬ] visionary [viʒņri] veteran [vetrņ] Phonotactics Phonotactic constraints determine what sounds can be put together to form the different parts of a syllable in a language. Examples: English onsets /kl/ is okay: “clean” “clamp” /pl/ is okay: “play” “plaque” */tl/ is not okay: *tlay *tlamp. We don’t often have words that begin with /tl/, /dm/, /rk/, etc. in English. However, these combinations can occur in the middle or final positions. So, what is phonotactics? Phonotactics is part of the phonology of a language. Phonotactics restricts the possible sound sequences and syllable structures in a language. Phonotactic constraint refers to any specific restriction To understand phonotactics, one must first understand syllable structure. Permissible language structures Languages differ in permissible syllable structures. Below are some simplified examples. Hawaiian: V, CV Japanese: V, CV, CVC Korean: V, CV, CVC, VCC, CVCC English: V CV CCV CCCV VC CVC CCVC CCCVC VCC CVCC CCVCC CCCVCC VCCC CVCCC CCVCCC CCCVCCC English consonant clusters sequences English allows CC and CCC clusters in onsets and codas, but they are highly restricted. -

Vowel Quality and Phonological Projection
i Vowel Quality and Phonological Pro jection Marc van Oostendorp PhD Thesis Tilburg University September Acknowledgements The following p eople have help ed me prepare and write this dissertation John Alderete Elena Anagnostop oulou Sjef Barbiers Outi BatEl Dorothee Beermann Clemens Bennink Adams Bo domo Geert Bo oij Hans Bro ekhuis Norb ert Corver Martine Dhondt Ruud and Henny Dhondt Jo e Emonds Dicky Gilb ers Janet Grijzenhout Carlos Gussenhoven Gert jan Hakkenb erg Marco Haverkort Lars Hellan Ben Hermans Bart Holle brandse Hannekevan Ho of Angeliek van Hout Ro eland van Hout Harry van der Hulst Riny Huybregts Rene Kager HansPeter Kolb Emiel Krah mer David Leblanc Winnie Lechner Klarien van der Linde John Mc Carthy Dominique Nouveau Rolf Noyer Jaap and Hannyvan Oosten dorp Paola Monachesi Krisztina Polgardi Alan Prince Curt Rice Henk van Riemsdijk Iggy Ro ca Sam Rosenthall Grazyna Rowicka Lisa Selkirk Chris Sijtsma Craig Thiersch MiekeTrommelen Rub en van der Vijver Janneke Visser Riet Vos Jero en van de Weijer Wim Zonneveld Iwant to thank them all They have made the past four years for what it was the most interesting and happiest p erio d in mylife until now ii Contents Intro duction The Headedness of Syllables The Headedness Hyp othesis HH Theoretical Background Syllable Structure Feature geometry Sp ecication and Undersp ecicati on Skeletal tier Mo del of the grammar Optimality Theory Data Organisation of the thesis Chapter Chapter -

Using 'North Wind and the Sun' Texts to Sample Phoneme Inventories
Blowing in the wind: Using ‘North Wind and the Sun’ texts to sample phoneme inventories Louise Baird ARC Centre of Excellence for the Dynamics of Language, The Australian National University [email protected] Nicholas Evans ARC Centre of Excellence for the Dynamics of Language, The Australian National University [email protected] Simon J. Greenhill ARC Centre of Excellence for the Dynamics of Language, The Australian National University & Department of Linguistic and Cultural Evolution, Max Planck Institute for the Science of Human History [email protected] Language documentation faces a persistent and pervasive problem: How much material is enough to represent a language fully? How much text would we need to sample the full phoneme inventory of a language? In the phonetic/phonemic domain, what proportion of the phoneme inventory can we expect to sample in a text of a given length? Answering these questions in a quantifiable way is tricky, but asking them is necessary. The cumulative col- lection of Illustrative Texts published in the Illustration series in this journal over more than four decades (mostly renditions of the ‘North Wind and the Sun’) gives us an ideal dataset for pursuing these questions. Here we investigate a tractable subset of the above questions, namely: What proportion of a language’s phoneme inventory do these texts enable us to recover, in the minimal sense of having at least one allophone of each phoneme? We find that, even with this low bar, only three languages (Modern Greek, Shipibo and the Treger dialect of Breton) attest all phonemes in these texts. -

Abstract: Crossing Morpheme Boundaries in Dutch
Abstract: Crossing morpheme boundaries in Dutch On the basis of Dutch data, this article argues that many differences between types of affixes which are usually described by arbitrary morphological diacritics in the literature, can be made to follow from the phonological shape of affixes. Two cases are studied in some detail: the difference between prefixes and suffixes, and differences between 'cohering' and 'noncohering' suffixes. Prefixes in many languages of the world behave as prosodically more independent than suffixes with respect to syllabification: the former usually do not integrate with the stem, whereas the latter do. Dutch is an example of a language to which this applies. It is argued that this asymmetry does not have to be stipulated, but can be made to follow from the fact that the phonotactic reason for crossing a morpheme boundary usually involves the creation of an onset, which is on the left-hand side of a vowel and not on its right-hand side, plus some general (symmetric) conditions on the interface between phonology and morphology. The differences between 'cohering' and 'noncohering' suffixes with respect to syllable structure and stress in Dutch is argued to similarly follow from the phonological shape of these affixes. Once we have set up an appropriately sophisticated structure for every affix, there is no need any more to stipulate arbitrary morphological markings: differences in phonological behaviour follow from differences in phonological shape alone, given a sufficiently precise theory of universal constraint and their interactions. Keywords: Dutch phonology, phonology-morphology interface, prosody 1 Crossing Morpheme Boundaries in Dutch 1. Introduction Asymmetries in phonological behaviour between types of affixes are not uncommon in languages of the world.1 For instance, prefixes in a given language may behave quite differently from suffixes. -

CONSONANT CLUSTER PHONOTACTICS: a PERCEPTUAL APPROACH by MARIE-HÉLÈNE CÔTÉ B.Sc. Sciences Économiques, Université De Montr
CONSONANT CLUSTER PHONOTACTICS: A PERCEPTUAL APPROACH by MARIE-HÉLÈNE CÔTÉ B.Sc. Sciences économiques, Université de Montréal (1987) Diplôme Relations Internationales, Institut d’Études Politiques de Paris (1990) D.E.A. Démographie économique, Institut d’Études Politiques de Paris (1991) M.A. Linguistique, Université de Montréal (1995) Submitted to the department of Linguistics and Philosophy in partial fulfillment of the requirement for the degree of DOCTOR OF PHILOSOPHY À ma mère et à mon bébé, at the qui nous ont quittés À Marielle et Émile, MASSACHUSETTS INSTITUTE OF TECHNOLOGY qui nous sont arrivés À Jean-Pierre, qui est toujours là September 2000 © 2000 Marie-Hélène Côté. All rights reserved. The author hereby grants to M.I.T. the permission to reproduce and to distribute publicly paper and electronic copies of this thesis document in whole or in part. Signature of author_________________________________________________ Department of Linguistics and Philosophy August 25, 2000 Certified by_______________________________________________________ Professor Michael Kenstowicz Thesis supervisor Accepted by______________________________________________________ Alec Marantz Chairman, Department of Linguistics and Philosophy CONSONANT CLUSTER PHONOTACTICS: A PERCEPTUAL APPROACH NOTES ON THE PRESENT VERSION by The present version, finished in July 2001, differs slightly from the official one, deposited in September 2000. The acknowledgments were finally added. The MARIE-HÉLÈNE CÔTÉ formatting was changed and the presentation generally improved. Several typos were corrected, and the references were updated, when papers originally cited as manuscripts were subsequently published. A couple of references were also added, as Submitted to the Department of Linguistics and Philosophy well as short conclusions to chapters 3, 4, and 5, which for the most part summarize on September 5, 2000, in partial fulfillment of the requirements the chapter in question. -

On Syncope in Old English
In: Dieter Kastovsky and Aleksander Szwedek (eds) Linguistics across historical and geographical boundaries. In honour of Jacek Fisiak on the occasion of his fiftieth birthday. Berlin: Mouton-de Gruyter, 1986, 359-66. On syncope in Old English Raymond Hickey University of Bonn Abstract. Syncope in Old English is seen to be a rule which is determined by syllable structure but furthermore to be governed by a set of restricting conditions which refer to the world-class status of the forms which may act as input to the syncope rule, and also to the inflectional or derivational nature of the suffix which are added also to the precise phonological structure of those forms which undergo syncope. A phonological rule in a language which does not operate globally is always of particular interest as the conditions which restrict its application can frequently be recognized and formulized, at the same time throwing light on the nature of conditions which can in principle apply in a language’s phonology. In Old English a syncope rule existed which clearly related to the syllable structure of the forms it did not operate on but which was also subject to a set of restricting conditions which lie outside the domain of the syllable. The examination of this syncope rule and the conditions pertaining to it is the subject of this contribution. It is first of all necessary to distinguish syncope from another phonological process with which it might be confused. This is epenthesis, which appears to have been quite widespread in late West Saxon, as can be seen in the following forms. -

Phonotactics on the Web 487
PHONOTACTICS ON THE WEB 487 APPENDIX Table A1 International Phonetic Alphabet (IPA) and Computer-Readable “Klattese” Transcription Equivalents IPAKlattese IPA Klattese Stops Syllabic Consonants p p n N t t m M k k l L b b d d Glides and Semivowels g l l ɹ r Affricates w w tʃ C j y d J Vowels Sibilant Fricatives i i s s I ʃ S ε E z z e e Z @ Nonsibilant Fricatives ɑ a ɑu f f W θ a Y T v v ^ ð ɔ c D o h h O o o Nasals υ U n n u u m m R ŋ G ə x | X Klattese Transcription Conventions Repeated phonemes. The only situation in which a phoneme is repeated is in a compound word. For exam- ple, the word homemade is transcribed in Klattese as /hommed/. All other words with two successive phonemes that are the same just have a single segment. For example, shrilly would be transcribed in Klattese as /SrIli/. X/R alternation. /X/ appears only in unstressed syllables, and /R/ appears only in stressed syllables. Schwas. There are four schwas: /x/, /|/, /X/, and unstressed /U/. The /U/ in an unstressed syllable is taken as a rounded schwa. Syllabic consonants. The transcriptions are fairly liberal in the use of syllabic consonants. Words ending in -ism are transcribed /IzM/ even though a tiny schwa typically appears in the transition from the /z/ to the /M/. How- ever, /N/ does not appear unless it immediately follows a coronal. In general, /xl/ becomes /L/ unless it occurs be- fore a stressed vowel. -
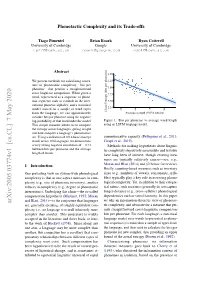
Phonotactic Complexity and Its Trade-Offs
Phonotactic Complexity and its Trade-offs Tiago Pimentel Brian Roark Ryan Cotterell University of Cambridge Google University of Cambridge [email protected] [email protected] [email protected] Abstract 3.50 We present methods for calculating a mea- 3.25 sure of phonotactic complexity—bits per phoneme—that permits a straightforward 3.00 cross-linguistic comparison. When given a 2.75 word, represented as a sequence of phone- mic segments such as symbols in the inter- 2.50 national phonetic alphabet, and a statistical 2.25 model trained on a sample of word types 5 6 7 8 from the language, we can approximately Cross Entropy (bits per phoneme) Average Length (# IPA tokens) measure bits per phoneme using the negative log-probability of that word under the model. Figure 1: Bits-per-phoneme vs average word length This simple measure allows us to compare using an LSTM language model. the entropy across languages, giving insight into how complex a language’s phonotactics are. Using a collection of 1016 basic concept communicative capacity (Pellegrino et al., 2011; words across 106 languages, we demonstrate Coupé et al., 2019). a very strong negative correlation of −0:74 Methods for making hypotheses about linguis- between bits per phoneme and the average tic complexity objectively measurable and testable length of words. have long been of interest, though existing mea- sures are typically relatively coarse—see, e.g., 1 Introduction Moran and Blasi(2014) and §2 below for reviews. Briefly, counting-based measures such as inventory One prevailing view on system-wide phonological sizes (e.g., numbers of vowels, consonants, sylla- complexity is that as one aspect increases in com- bles) typically play a key role in assessing phono- plexity (e.g., size of phonemic inventory), another logical complexity. -

Alternatives to the Syllabic Interpretation Of
ALTERNATIVES TO SYLLABLE-BASED ACCOUNTS OF CONSONANTAL PHONOTACTICS Donca Steriade, UCLA Abstract Phonotactic statements characterize contextual restrictions on the occurrence of segments or feature values. This study argues that consonantal phonotactics are best understood as syllable-independent, string-based conditions reflecting positional differences in the perceptibility of contrasts. The analyses proposed here have better empirical coverage compared to syllable-based analyses that link a consonant's feature realization to its syllabic position. Syllable-based analyses require identification of word-medial syllabic divisions; the account proposed here does not and this may be a significant advantage. Word-medial syllable- edges are, under specific conditions, not uniformly identified by speakers; but comparable variability does not exist for phonotactic knowledge. The paper suggests that syllable- independent conditions define segmental phonotactics, and that word-edge phonotactics, in turn, are among the guidelines used by speakers to infer word-internal syllable divisions. 1. Introduction. The issue addressed here is the link between consonantal phonotactics and syllable structure conditions. Consider a paradigm case of the role attributed to syllables in current accounts of consonant distributions, based on Kahn (1976). Kahn suggests a syllable- based explanation of the fact that tpt, dbd, tkt, dgd strings - two coronal stops surrounding a non-coronal - are impossible in English. Kahn explains this gap by combining three hypotheses, two of which are specific to English, and a third with potential as a universal: (i) English onsets cannot contain stop-stop sequences; (ii) alveolar stops cannot precede non-coronals in English codas; and (iii) each segment/feature must belong to some syllable. -

1 Phonotactics As Phonology: Knowledge of a Complex Constraint in Dutch René Kager (Utrecht University) and Joe Pater (Universi
Phonotactics as phonology: Knowledge of a complex constraint in Dutch René Kager (Utrecht University) and Joe Pater (University of Massachusetts, Amherst) Abstract : The Dutch lexicon contains very few sequences of a long vowel followed by a consonant cluster, where the second member of the cluster is a non-coronal. We provide experimental evidence that Dutch speakers have implicit knowledge of this gap, which cannot be reduced to the probability of segmental sequences or to word-likeness as measured by neighborhood density. The experiment also shows that the ill-formedness of this sequence is mediated by syllable structure: it has a weaker effect on judgments when the last consonant begins a new syllable. We provide an account in terms of Hayes and Wilson’s Maximum Entropy model of phonotactics, using constraints that go beyond the complexity permitted by their model of constraint induction. 1. Introduction Phonological analysis and theorizing typically takes phonotactics as part of the data to be accounted for in terms of a phonological grammar. Ohala (1986) challenges this assumption, raising the possibility that knowledge of the shape of a language’s words could be reduced to “knowledge of the lexicon plus the possession of very general cognitive abilities”. 1 As an example of the requisite general cognitive abilities, he points to Greenberg and Jenkins’ (1964) similarity metric, which measures the closeness of a nonce word to the existing lexicon as proportional to the number of real words obtained by substituting any set of the nonce word’s segments with other segments. Like many other models of word-likeness or probability, Greenberg and Jenkins’ model of phonotactic knowledge is quite different from those constructed in phonological theory. -

Finding Phonological Features in Perception
UvA-DARE (Digital Academic Repository) Finding phonological features in perception Chládková, K. Publication date 2014 Link to publication Citation for published version (APA): Chládková, K. (2014). Finding phonological features in perception. General rights It is not permitted to download or to forward/distribute the text or part of it without the consent of the author(s) and/or copyright holder(s), other than for strictly personal, individual use, unless the work is under an open content license (like Creative Commons). Disclaimer/Complaints regulations If you believe that digital publication of certain material infringes any of your rights or (privacy) interests, please let the Library know, stating your reasons. In case of a legitimate complaint, the Library will make the material inaccessible and/or remove it from the website. Please Ask the Library: https://uba.uva.nl/en/contact, or a letter to: Library of the University of Amsterdam, Secretariat, Singel 425, 1012 WP Amsterdam, The Netherlands. You will be contacted as soon as possible. UvA-DARE is a service provided by the library of the University of Amsterdam (https://dare.uva.nl) Download date:01 Oct 2021 4 PERCEPTUALSENSITIVITYTOCHANGESINVOWEL DURATIONREVEALSTHESTATUSOFTHE PHONOLOGICALLENGTHFEATURE 4.1 pre-attentive sensitivity to vowel duration reveals native phonology and predicts learning of second- language sounds This section has been published as: KateˇrinaChládková, Paola Escudero, & Silvia Lipski (2013). Pre-attentive sensitivity to vowel duration reveals native phonology and predicts learning of second-language sounds. Brain and Language, 126 (3): 243-252. Abstract In some languages (e.g. Czech), changes in vowel duration affect word meaning, while in others (e.g. -

Chapter on Phonology
13 The (American) English Sound System 13.1a IPA Chart Consonants: Place & Manner of Articulation bilabial labiodental interdental alveolar palatal velar / glottal Plosives: [+voiced] b d g [voiced] p t k Fricatives: [+voiced] v ð z ž [voiced] f θ s š h Affricates: [+voiced] ǰ [voiced] č *Nasals: [+voiced] m n ŋ *Liquids: l r *Glides: w y *Syllabic Nasals and Liquids. When nasals /m/, /n/ and liquids /l/, /r/ take on vowellike properties, they are said to become syllabic: e.g., /ļ/ and /ŗ/ (denoted by a small line diacritic underneath the grapheme). Note how token examples (teacher) /tičŗ/, (little) /lIt ļ/, (table) /tebļ/ (vision) /vIžņ/, despite their creating syllable structures [CVCC] ([CVCC] = consonantvowel consonantconsonant), nonetheless generate a bisyllabic [CVCV] structure whereby we can ‘clapout’ by hand two syllables—e.g., [ [/ ti /] [/ čŗ /] ] and 312 Chapter Thirteen [ [/ lI /] [/ tļ /] ], each showing a [CVCC v] with final consonant [C v] denoting a vocalic /ŗ/ and /ļ/ (respectively). For this reason, ‘fluid’ [Consonantal] (vowellike) nasals, liquids (as well as glides) fall at the bottom half of the IPA chart in opposition to [+Consonantal] stops. 13.1b IPA American Vowels Diphthongs front: back: high: i u ay I ә U oy au e ^ o ε * ] low: æ a 13.1c Examples of IPA: Consonants / b / ball, rob, rabbit / d / dig, sad, sudden / g / got, jogger / p / pan, tip, rapper / t / tip, fit, punter / k / can, keep / v / vase, love / z / zip, buzz, cars / ž / measure, pleasure / f / fun, leaf / s / sip, cent, books / š / shoe, ocean, pressure / ð / the, further / l / lip, table, dollar / č / chair, cello / θ / with, theory / r / red, fear / ǰ / joke, lodge / w / with, water / y / you, year / h / house / m / make, ham / n / near, fan / ŋ / sing, pink The American English Sound System 313 *Note: Many varieties of American English cannot distinguish between the ‘open‘O’ vowel /]/ e.g., as is sounded in caught /k]t/ vs.