Una-Theses-0274.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Malayalam Noun and Verb Morphological Analyzer: a Simple Approach
Malayalam Noun and Verb Morphological Analyzer: A Simple Approach Nimal J Valath1, Narsheedha Beegum2 M.Tech Student1, M.Tech Student2 ABSTRACT Malayalam is a language of the Dravidian family and is one of This paper discusses the methods involved in the the four major languages of this family with a rich literary development of a Simple Malayalam Verb and Noun tradition. It is very close to Tamil, one of the major languages of Morphological Analyzer. Since in Malayalam, words can be the same family. This was due to the extensive cultural derived from a root word, a purely dictionary based approach synthesis that took place between the speakers of the two for Morphological analysis is not practical. Hence, a ‘Rule-cum- languages. The origin of Malayalam as a distinct language may Dictionary’ based approach is followed along with the Suffix be traced to the last quarter of 9th Century A.D. Throughout its Stripping concept. The grammatical behavior of the language, gradual evolution Malayalam has been influenced by the the formation of words with multiple suffixes and the various circumstances prevailed on different periods. preparation of the language are dealt with here, with examples of noun and verb forms in detail. Mainly Malayalam was influenced by Sanskrit and Prakrit brought into Kerala by Brahmins. After the 11th century a unique mixture of the native languages of Kerala and Sanskrit Keywords known as Manipravalam served as the medium of literary Morphological Analyzer, Malayalam, Suffix stripping, expression. Malayalam absorbed a lot from Sanskrit, not only in Transliteration, Retransliteration, Verb and Noun, Sandhi rules, the lexical level, but also in the phonemic, morphemic and Word Formation, Noun Cases, Algorithm. -

A Comparison Between Natural and Planned Languages
UvA-DARE (Digital Academic Repository) The Case of Correlatives: A Comparison between Natural and Planned Languages Gobbo, F. Publication date 2011 Document Version Final published version Published in Journal of Universal Language Link to publication Citation for published version (APA): Gobbo, F. (2011). The Case of Correlatives: A Comparison between Natural and Planned Languages. Journal of Universal Language, 12(2), 45-79. General rights It is not permitted to download or to forward/distribute the text or part of it without the consent of the author(s) and/or copyright holder(s), other than for strictly personal, individual use, unless the work is under an open content license (like Creative Commons). Disclaimer/Complaints regulations If you believe that digital publication of certain material infringes any of your rights or (privacy) interests, please let the Library know, stating your reasons. In case of a legitimate complaint, the Library will make the material inaccessible and/or remove it from the website. Please Ask the Library: https://uba.uva.nl/en/contact, or a letter to: Library of the University of Amsterdam, Secretariat, Singel 425, 1012 WP Amsterdam, The Netherlands. You will be contacted as soon as possible. UvA-DARE is a service provided by the library of the University of Amsterdam (https://dare.uva.nl) Download date:28 Sep 2021 Federico Gobbo 45 Journal of Universal Language 12-2 September 2011, 45-79 The Case of Correlatives: A Comparison between Natural and Planned Languages Federico Gobbo University of Insubria 1 Abstract Since the publication of Volapük, the most important functional and deictic words present in grammar—interrogative, relative and demonstrative pronouns, and adjectives among others—have been described in planned grammars in a series or a table, namely “correlatives,” showing a considerable level of regularity. -
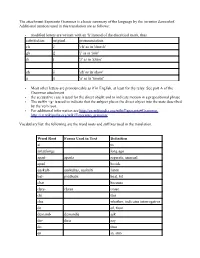
The Attachment Esperanto Grammar Is a Basic Summary of the Language by the Inventor Zamenhof
The attachment Esperanto Grammar is a basic summary of the language by the inventor Zamenhof. Additional nuances used in this translation are as follows: • modified letters are written with an 'h' instead of the diacritical mark, thus substitution original pronounciation ch ĉ 'ch' as in 'church' gh ĝ 'j' as in 'join' jh ĵ 'z' as in 'azure' sh ŝ 'sh' as in 'show' u ŭ 'u' as in 'mount' • Most other letters are pronouncable as if in English, at least for the relay. See part A of the Grammar attachment. • the accusative case is used for the direct objekt and to indicate motion in a prepositional phrase. • The suffix -ig- is used to indicate that the subject places the direct object into the state described by the verb root. • For additional information see http://en.wikipedia.org/wiki/Esperanto#Grammar http://en.wikipedia.org/wiki/Esperanto_grammar Vocabulary list: the following are the word roots and suffixes used in the translation. Word Root Forms Used in Text Definition al to antaulonge long ago apart- aparta separate, unusual apud beside auskult- auskultas, auskulti listen bat- piedbatis beat, hit char because ches- chesu cease chi this chu whether; indicates interrogative de of, from demand- demandis ask dir- diris say do thus en in, into Word Root Forms Used in Text Definition fakt- fakte fact, (fakte: in fact) far- fari to do ghen- ghenas bother ghi ghin it halt- haltu stop histori- historio stoty jhet- jhetis throw kaj and kiam when kiel how koler- kolerigis anger konsent- konsentas agree kvazau as if la the lag- lago, lagon lake -

Unsupervised Separation of Transliterable and Native Words For
Unsupervised Separation of Transliterable and Native Words for Malayalam Deepak P Queen’s University Belfast, UK [email protected] Abstract names that need to be transliterated than translated to correlate with English text. On a manual analy- Differentiating intrinsic language words sis of a news article dataset, we found that translit- from transliterable words is a key step erated words and proper nouns each form 10-12% aiding text processing tasks involving dif- of all distinct words. It is useful to transliterate ferent natural languages. We consider such words for scenarios that involve processing the problem of unsupervised separation of Malayalam text in the company of English text; transliterable words from native words for this will avoid them being treated as separate index text in Malayalam language. Outlining a terms (wrt their transliteration) in a multi-lingual key observation on the diversity of char- retrieval engine, and help a statistical translation acters beyond the word stem, we develop system to make use of the link to improve effec- an optimization method to score words tiveness. In this context, it ia notable that there has based on their nativeness. Our method re- been recent interest in devising specialized meth- lies on the usage of probability distribu- ods to translate words that fall outside the core vo- tions over character n-grams that are re- cabulary (Tsvetkov and Dyer, 2015). fined in step with the nativeness scorings In this paper, we consider the problem of sepa- in an iterative optimization formulation. rating out such transliterable words from the other Using an empirical evaluation, we illus- words within an unlabeled dataset; we refer to trate that our method, DTIM, provides sig- the latter as “native” words. -

A Complex Structure. a Linguistic Description of Esperanto in Functional Discourse Grammar
Interdisciplinary Description of Complex Systems 13(2), 275-287, 2015 GRAMMAR: A COMPLEX STRUCTURE. A LINGUISTIC DESCRIPTION OF ESPERANTO IN FUNCTIONAL DISCOURSE GRAMMAR Wim Jansen* Chair of Interlinguistics and Esperanto, University of Amsterdam Amsterdam, Netherlands DOI: 10.7906/indecs.13.2.11 Received: 1 February 2014. Regular article Accepted: 17 June 2014. ABSTRACT Functional Discourse-Grammar or FDG is the latest development in the functional grammar that was initiated by the Dutch linguist Simon Dik (1940-1995). In this paper, the FDG architecture proper is described, including the role of the extra-grammatical conceptual and contextual components. A simple interrogative clause in Esperanto is used to illustrate how a linguistic expression is built up from the formulation of its (pragmatic) intention to its articulation. Attention is paid to linguistic transparencies and opacities, defined here as the absence or presence of discontinuities between the descriptive levels in the grammar. Opacities are held accountable, among other factors, for making languages more or less easy to learn. The grammar of every human language is a complex system. This is clearly demonstrable precisely in Esperanto, in which the relatively few difficulties, identified by the opacities in the system, form such a sharp contrast to the general background of freedom, regularity and lack of exceptions. KEY WORDS Esperanto, functional grammar, linguistic transparency CLASSIFICATION JEL: O35 *Corresponding author, : [email protected]; ; *Emmaplein 17A, 2225 BK Katwijk, Netherlands * W. Jansen INTRODUCTION1 In the authoritative monolingual dictionary Plena Ilustrita Vortaro de Esperanto (PIV) 1, under the headword gramatiko (‘grammar’) we find several definitions. The first is ‘study of language rules’ (scienco pri la lingvaj reguloj); under this definition, ĝenerala gramatiko (‘general grammar’) is described as the ‘study of rules common to all languages’ (scienco pri la reguloj komunaj al ĉiuj lingvoj). -

Introduction: in Search of Esperanto
Interdisciplinary Description of Complex Systems 13(2), 182-192, 2015 INTRODUCTION: IN SEARCH OF ESPERANTO Humphrey Tonkin* University of Hartford West Hartford, USA DOI: 10.7906/indecs.13.2.12 Regular article ABSTRACT After almost one hundred years of continuous use, Esperanto has achieved the status and character of a fully-fledged language, functioning much as any other language does. Research on Esperanto is hampered because knowledge of the subject is often regarded, ipso facto, as evidence of a lack of objectivity, and also because Esperanto, as largely an L2, is elusive, and its speakers hard to quantify. The problem is compounded by the rapid shift in its community from membership-based organizations to decentralized, informal web-based communication. Also shifting are the community’s ideological underpinnings: it began as a response to lack of communication across languages but is now often perceived by its users as an alternative, more equitable means of communication than the increasingly ubiquitous English. Underlying these changes is a flourishing cultural base, including an extensive literature and periodical press. There is a need for more research – linguistic, sociolinguistic, and in the history of ideas. In intellectual history, Esperanto and related ideas have played a larger role than is generally recognized, intersecting with, and influencing, such movements as modernization in Japan, the development of international organizations, socialism in many parts of the world, and, in our own day, machine translation. KEY WORDS Esperanto, Esperanto community, interlinguistic research, language ideology CLASSIFICATION JEL: O20 *Corresponding author, : [email protected]; +1 860 768 4448; *Mortensen Library, University of Hartford, West Hartford, CT 06117, USA Introduction: in search of Esperanto INTRODUCTION In an influential essay some years ago, the late Richard Wood described Esperanto as “a voluntary, non-ethnic, non-territorial speech community” [1]. -

Download (.Pdf)
Fiat Lingua Title: From Elvish to Klingon: Exploring Invented Languages, A Review Author: Don Boozer MS Date: 11-16-2011 FL Date: 12-01-2011 FL Number: FL-000003-00 Citation: Boozer, Don. 2011. "From Elvish to Klingon: Exploring Invented Languages, A Review." FL-000003-00, Fiat Lingua, <http:// fiatlingua.org>. Web. 01 Dec. 2011. Copyright: © 2011 Don Boozer. This work is licensed under a Creative Commons Attribution- NonCommercial-NoDerivs 3.0 Unported License. ! http://creativecommons.org/licenses/by-nc-nd/3.0/ Fiat Lingua is produced and maintained by the Language Creation Society (LCS). For more information about the LCS, visit http://www.conlang.org/ From Elvish to Klingon: Exploring Invented Languages !!! A Review """ Don Boozer From Elvish to Klingon: Exploring Invented Languages. Michael Adams, ed. Oxford: Oxford University Press. Nov. 2011. c.294 p. index. ISBN13: 9780192807090. $19.95. From Elvish to Klingon: Exploring Invented Languages is a welcome addition to the small but growing corpus of works on the subject of invented languages. The collection of essays was edited by Michael Adams, Associate Professor and Director of Undergraduate Studies in the Department of English at Indiana University Bloomington and Vice-President of the Dictionary Society of North America. Not only does Adams serve as editor, he also writes complementary appendices to accompany each of the contributed essays to expand on a particular aspect or to introduce related material. Adams’ previous works include Slang: The People’s Poetry (Oxford University Press, 2009) and Slayer Slang: A Buffy the Vampire Slayer Lexicon (Oxford University Press, 2003). Although Oxford University Press is known for its scholarly publications, the title From Elvish to Klingon would suggest that the book is geared toward a popular audience. -

In Search of Esperanto
Interdisciplinary Description of Complex Systems 13(2), 182-192, 2015 INTRODUCTION: IN SEARCH OF ESPERANTO Humphrey Tonkin* University of Hartford West Hartford, USA DOI: 10.7906/indecs.13.2.12 Regular article ABSTRACT After almost one hundred years of continuous use, Esperanto has achieved the status and character of a fully-fledged language, functioning much as any other language does. Research on Esperanto is hampered because knowledge of the subject is often regarded, ipso facto, as evidence of a lack of objectivity, and also because Esperanto, as largely an L2, is elusive, and its speakers hard to quantify. The problem is compounded by the rapid shift in its community from membership-based organizations to decentralized, informal web-based communication. Also shifting are the community’s ideological underpinnings: it began as a response to lack of communication across languages but is now often perceived by its users as an alternative, more equitable means of communication than the increasingly ubiquitous English. Underlying these changes is a flourishing cultural base, including an extensive literature and periodical press. There is a need for more research – linguistic, sociolinguistic, and in the history of ideas. In intellectual history, Esperanto and related ideas have played a larger role than is generally recognized, intersecting with, and influencing, such movements as modernization in Japan, the development of international organizations, socialism in many parts of the world, and, in our own day, machine translation. KEY WORDS Esperanto, Esperanto community, interlinguistic research, language ideology CLASSIFICATION JEL: O20 *Corresponding author, : [email protected]; +1 860 768 4448; *Mortensen Library, University of Hartford, West Hartford, CT 06117, USA Introduction: in search of Esperanto INTRODUCTION In an influential essay some years ago, the late Richard Wood described Esperanto as “a voluntary, non-ethnic, non-territorial speech community” [1]. -

Children's Possessive Structures
Ling 404 Lecture Notes No.4 Synchronic Clines in Morphology Productivity Clines: Japanese, Navajo, Mohawk, Eskimo, vs. Spanish, Italian, English One of the questions will be asking throughout is where do the above languages fall on the productivity cline and why (providing data and analyses.) One question to ask is to what degree is the lexicon ‘morpheme-based’ or ‘word-based’ (Chapters 3-4)? ‘Working Memory’ is implicated in the choice. For instance, are speakers all equally productive with their morpheme-units as tucked within word, a [-Fusion] language, or do some languages rather require morphemes within words to be memorized and incorporated as part of the lexical item, a [+Fusion] language? In addition to labeling languages as [+]Synthetic (as in Turkish, Hungarian, Spanish, English, Mohawk) or [-]Synthetic (as in Chinese, Vietnamese), the following data provide an additional exercise in teasing out what might be going on in languages which carry such a large number of embedded morphemes. Question leading to mid-term: How might such morphemes in Polysynthetic-type languages be stored and processed? The notion of [+/-Fusion] will be the central question here as we move to our mid-term material of this class. Typically, agglutinative morphemes are considered to be ‘loosely’ structured in that one morpheme has a one-to-one meaning. But the question might rather be how productive are the morphemes in isolation—viz., do they allow for movement? The question of movement, both at the word-level and at the morpheme-level will allow us to determine the nature of +/- productivity and +/- fusion. Regarding Movement. -

Latin Pronunciation Alphabet
Latin Pronunciation Alphabet The Roman alphabet was like the English alphabet except that it lacked the letters j and w, and the letter v originally represented both the vowel u and the sound of the English consonant w. The Roman names for the letters are generally similar to ours: A B C D E F G H I K L M N O P Q R S T V X Y Z ī ā bē kē dē ē ef gē hā ī kā el em en ō pē qū er es tē ū ex zēta Graeca NOTĀ BENE: The letter V originally stood for both the sounds of the vowel U and the consonant V. The rounded u-form appeared in the second century CE (or AD) to distinguish vowel from consonant. For convenience, both V and U are employed in the Latin texts of most modern editions and in this course as well. The letters y, z, and k are infrequent and usually found in words of Greek origin. The Roman alphabet lacks the letters j and w. The Roman letter i was both a vowel and a consonant. The letter j was added during the Middle Ages for consonantal i. Thus Iūlius came to be written Jūlius. This course adheres to the Roman usage of i. There are two important keys to pronouncing Latin: There are no silent letters. Even final e’s are pronounced. Latin is essentially WYSIWYG (What you see is what you get!). Unlike English, Latin is quite consistent in the sound a letter represents. -

Om Babelstårnet Og Hvad Der Deraf Fulgte! - Kunstsprogsamlinger I Det Kongelige Bibliotek
3 Om Babelstårnet og hvad der deraf fulgte! - Kunstsprogsamlinger i Det kongelige Bibliotek - af forskningsbibliotekar, cand.mag. Ruth Bentzen Hele Menneskeheden havde et Tungemaal og samme Sprog — Derpaa sagde de: Kom, lad os bygge os et Taarn , hvis Top naar til Himmelen, og skabe os et Navn, for at vi ikke skal spredes ud over hele Jorden. Men Herren steg nedfor at se Byen og Taarnet, som Menneskebørnene byggede og sagde: Se, de er eet Folk og har alle eet Tungemaal; og naar de nu først er begyndt saaledes, er intet, som de sætter sig for umuligt for dem; lad os derfor stige ned og forvirre deres Tungemaal der, saa de ikke forstaar hver andres Tungemaal! Da spredte Herren dem fra det Sted ud over hele Jorden, og de opgav at bygge Byen. Derfor kaldte man den Babel, thi der forvirrede Herren al Jordens Tungemaal og derfra spredte Herren dem ud over Jorden. (1. Mosebog, kap. 11, vers 1-9) Bibelens fortælling om sprogenes oprindelse og Babelstårnet mindes de fleste sikkert fra deres barndomsskoles religionsundervisning. Udtrykket babelsk/ babylonisk for virring dukker op i de flestes bevidsthed, når man står i situationer med sprogligt vir var og dermed følgende forståelsesvanskeligheder eller som man vel snarere vil sige idag kommunikationsbrist. Gennem tiderne har folk stedse, når de i deres færden bevægede sig udenfor lo kalsamfundet været i situationer, hvor der var en forståelseskløft, de skulle over. Tan ken om eet fælles sprog, der kunne lette kommunikationen folkeslag imellem er fra tid til anden dukket op. Man har til forskellig tid hjulpet sig på forskellig vis. -

Vowel Category and Meanings of Size in Tolkien's Early Lexicons
Journal of Tolkien Research Volume 9 Issue 2 Article 5 2020 Vowel Category and Meanings of Size in Tolkien's Early Lexicons Lucas Annear none, [email protected] Follow this and additional works at: https://scholar.valpo.edu/journaloftolkienresearch Part of the Phonetics and Phonology Commons Recommended Citation Annear, Lucas (2020) "Vowel Category and Meanings of Size in Tolkien's Early Lexicons," Journal of Tolkien Research: Vol. 9 : Iss. 2 , Article 5. Available at: https://scholar.valpo.edu/journaloftolkienresearch/vol9/iss2/5 This Peer-Reviewed Article is brought to you for free and open access by the Christopher Center Library at ValpoScholar. It has been accepted for inclusion in Journal of Tolkien Research by an authorized administrator of ValpoScholar. For more information, please contact a ValpoScholar staff member at [email protected]. Vowel Category and Meanings of Size in Tolkien's Early Lexicons Cover Page Footnote My thanks to Nelson Goering for his comments and suggestions on an earlier draft of this essay. This peer-reviewed article is available in Journal of Tolkien Research: https://scholar.valpo.edu/ journaloftolkienresearch/vol9/iss2/5 Annear: Vowel Category and Meanings of Size in Tolkien's Early Lexicons 1. INTRODUCTION: TOLKIEN AND PHONETIC SYMBOLISM The grounds for studying phonetic symbolism1 in Tolkien's invented languages are at this point well established in the field of Tolkien studies. The recent stand-alone edition of "A Secret Vice" (Higgins & Fimi, 2016, hereafter SV), along with perennial interest and commentary on the appeal and effect of Tolkien's languages on the reader are evidence of this.