Performance Optimizations in Vmware Vsphere 7.0 U2 CPU Scheduler for AMD EPYC Processors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Effective Virtual CPU Configuration with QEMU and Libvirt
Effective Virtual CPU Configuration with QEMU and libvirt Kashyap Chamarthy <[email protected]> Open Source Summit Edinburgh, 2018 1 / 38 Timeline of recent CPU flaws, 2018 (a) Jan 03 • Spectre v1: Bounds Check Bypass Jan 03 • Spectre v2: Branch Target Injection Jan 03 • Meltdown: Rogue Data Cache Load May 21 • Spectre-NG: Speculative Store Bypass Jun 21 • TLBleed: Side-channel attack over shared TLBs 2 / 38 Timeline of recent CPU flaws, 2018 (b) Jun 29 • NetSpectre: Side-channel attack over local network Jul 10 • Spectre-NG: Bounds Check Bypass Store Aug 14 • L1TF: "L1 Terminal Fault" ... • ? 3 / 38 Related talks in the ‘References’ section Out of scope: Internals of various side-channel attacks How to exploit Meltdown & Spectre variants Details of performance implications What this talk is not about 4 / 38 Related talks in the ‘References’ section What this talk is not about Out of scope: Internals of various side-channel attacks How to exploit Meltdown & Spectre variants Details of performance implications 4 / 38 What this talk is not about Out of scope: Internals of various side-channel attacks How to exploit Meltdown & Spectre variants Details of performance implications Related talks in the ‘References’ section 4 / 38 OpenStack, et al. libguestfs Virt Driver (guestfish) libvirtd QMP QMP QEMU QEMU VM1 VM2 Custom Disk1 Disk2 Appliance ioctl() KVM-based virtualization components Linux with KVM 5 / 38 OpenStack, et al. libguestfs Virt Driver (guestfish) libvirtd QMP QMP Custom Appliance KVM-based virtualization components QEMU QEMU VM1 VM2 Disk1 Disk2 ioctl() Linux with KVM 5 / 38 OpenStack, et al. libguestfs Virt Driver (guestfish) Custom Appliance KVM-based virtualization components libvirtd QMP QMP QEMU QEMU VM1 VM2 Disk1 Disk2 ioctl() Linux with KVM 5 / 38 libguestfs (guestfish) Custom Appliance KVM-based virtualization components OpenStack, et al. -

AMD EPYC™ 7371 Processors Accelerating HPC Innovation
AMD EPYC™ 7371 Processors Solution Brief Accelerating HPC Innovation March, 2019 AMD EPYC 7371 processors (16 core, 3.1GHz): Exceptional Memory Bandwidth AMD EPYC server processors deliver 8 channels of memory with support for up The right choice for HPC to 2TB of memory per processor. Designed from the ground up for a new generation of solutions, AMD EPYC™ 7371 processors (16 core, 3.1GHz) implement a philosophy of Standards Based AMD is committed to industry standards, choice without compromise. The AMD EPYC 7371 processor delivers offering you a choice in x86 processors outstanding frequency for applications sensitive to per-core with design innovations that target the performance such as those licensed on a per-core basis. evolving needs of modern datacenters. No Compromise Product Line Compute requirements are increasing, datacenter space is not. AMD EPYC server processors offer up to 32 cores and a consistent feature set across all processor models. Power HPC Workloads Tackle HPC workloads with leading performance and expandability. AMD EPYC 7371 processors are an excellent option when license costs Accelerate your workloads with up to dominate the overall solution cost. In these scenarios the performance- 33% more PCI Express® Gen 3 lanes. per-dollar of the overall solution is usually best with a CPU that can Optimize Productivity provide excellent per-core performance. Increase productivity with tools, resources, and communities to help you “code faster, faster code.” Boost AMD EPYC processors’ innovative architecture translates to tremendous application performance with Software performance. More importantly, the performance you’re paying for can Optimization Guides and Performance be matched to the appropriate to the performance you need. -

Evaluation of AMD EPYC
Evaluation of AMD EPYC Chris Hollowell <[email protected]> HEPiX Fall 2018, PIC Spain What is EPYC? EPYC is a new line of x86_64 server CPUs from AMD based on their Zen microarchitecture Same microarchitecture used in their Ryzen desktop processors Released June 2017 First new high performance series of server CPUs offered by AMD since 2012 Last were Piledriver-based Opterons Steamroller Opteron products cancelled AMD had focused on low power server CPUs instead x86_64 Jaguar APUs ARM-based Opteron A CPUs Many vendors are now offering EPYC-based servers, including Dell, HP and Supermicro 2 How Does EPYC Differ From Skylake-SP? Intel’s Skylake-SP Xeon x86_64 server CPU line also released in 2017 Both Skylake-SP and EPYC CPU dies manufactured using 14 nm process Skylake-SP introduced AVX512 vector instruction support in Xeon AVX512 not available in EPYC HS06 official GCC compilation options exclude autovectorization Stock SL6/7 GCC doesn’t support AVX512 Support added in GCC 4.9+ Not heavily used (yet) in HEP/NP offline computing Both have models supporting 2666 MHz DDR4 memory Skylake-SP 6 memory channels per processor 3 TB (2-socket system, extended memory models) EPYC 8 memory channels per processor 4 TB (2-socket system) 3 How Does EPYC Differ From Skylake (Cont)? Some Skylake-SP processors include built in Omnipath networking, or FPGA coprocessors Not available in EPYC Both Skylake-SP and EPYC have SMT (HT) support 2 logical cores per physical core (absent in some Xeon Bronze models) Maximum core count (per socket) Skylake-SP – 28 physical / 56 logical (Xeon Platinum 8180M) EPYC – 32 physical / 64 logical (EPYC 7601) Maximum socket count Skylake-SP – 8 (Xeon Platinum) EPYC – 2 Processor Inteconnect Skylake-SP – UltraPath Interconnect (UPI) EYPC – Infinity Fabric (IF) PCIe lanes (2-socket system) Skylake-SP – 96 EPYC – 128 (some used by SoC functionality) Same number available in single socket configuration 4 EPYC: MCM/SoC Design EPYC utilizes an SoC design Many functions normally found in motherboard chipset on the CPU SATA controllers USB controllers etc. -

AMD EPYC 7002 Architecture Extends Benefits for Storage-Centric
Micron Technical Brief AMD EPYC™ 7002 Architecture Extends Benefits for Storage-Centric Solutions Overview With the release of the second generation of AMD EPYC™ family of processors, Micron believes that AMD has extended the benefits of EPYC as a foundation for storage-centric, all-flash solutions beyond the previous generation. As more enterprises are evaluating and deploying commodity server-based software-defined storage (SDS) solutions, platforms built using AMD EPYC 7002 processors continue to provide massive storage flexibility and throughput using the latest generation of PCI Express® (PCIe™) and NVM Express® (NVMe™) SSDs. With this new offering, Micron revisits our previously released analysis of the advantages that AMD EPYC architecture-based servers provide storage-centric solutions. To best assess the AMD EPYC architecture, we discuss the EPYC 7002 for solid-state storage solutions, based on AMD EPYC product features, capabilities and server manufacturer recommendations. We have not included any specific testing performed by Micron. Each OEM/ODM will have differing server implementation and additional support components, which could ultimately affect solution performance. Architecture Overview The new EPYC 7002 series of enterprise-class server processors, AMD created a second generation of its “Zen” microarchitecture and a second- generation Infinity Fabric™ to interconnect up to eight processor core complex die (CCD) per socket. Each CCD can host up to eight cores together with a centralized I/O controller that handles all PCIe and memory traffic (Figure 1). AMD has doubled the performance of each system-on-a- chip (SoC) while reducing the overall power consumption per core through advanced 7nm process technology over the first generation’s 14nm process, doubling memory DIMM size support to 256GB LRDIMMs while also providing a 2x peripheral throughput increase with the introduction of PCIe Generation 4.0 I/O controllers. -

Die Meilensteine Der Computer-, Elek
Das Poster der digitalen Evolution – Die Meilensteine der Computer-, Elektronik- und Telekommunikations-Geschichte bis 1977 1977 1978 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 und ... Von den Anfängen bis zu den Geburtswehen des PCs PC-Geburt Evolution einer neuen Industrie Business-Start PC-Etablierungsphase Benutzerfreundlichkeit wird gross geschrieben Durchbruch in der Geschäftswelt Das Zeitalter der Fensterdarstellung Online-Zeitalter Internet-Hype Wireless-Zeitalter Web 2.0/Start Cloud Computing Start des Tablet-Zeitalters AI (CC, Deep- und Machine-Learning), Internet der Dinge (IoT) und Augmented Reality (AR) Zukunftsvisionen Phasen aber A. Bowyer Cloud Wichtig Zählhilfsmittel der Frühzeit Logarithmische Rechenhilfsmittel Einzelanfertigungen von Rechenmaschinen Start der EDV Die 2. Computergeneration setzte ab 1955 auf die revolutionäre Transistor-Technik Der PC kommt Jobs mel- All-in-One- NAS-Konzept OLPC-Projekt: Dass Computer und Bausteine immer kleiner, det sich Konzepte Start der entwickelt Computing für die AI- schneller, billiger und energieoptimierter werden, Hardware Hände und Finger sind die ersten Wichtige "PC-Vorläufer" finden wir mit dem werden Massenpro- den ersten Akzeptanz: ist bekannt. Bei diesen Visionen geht es um die Symbole für die Mengendarstel- schon sehr früh bei Lernsystemen. iMac und inter- duktion des Open Source Unterstüt- möglichen zukünftigen Anwendungen, die mit 3D-Drucker zung und lung. Ägyptische Illustration des Beispiele sind: Berkley Enterprice mit neuem essant: XO-1-Laptops: neuen Technologien und Konzepte ermöglicht Veriton RepRap nicht Ersatz werden. -

In the United States District Court for the District of Delaware
Case 1:19-cv-00368-UNA Document 1 Filed 02/21/19 Page 1 of 58 PageID #: 1 IN THE UNITED STATES DISTRICT COURT FOR THE DISTRICT OF DELAWARE MEDIATEK INC. and ) MEDIATEK USA INC., ) ) Plaintiffs, ) ) C.A. No. _____________________ v. ) ) JURY TRIAL DEMANDED ADVANCED MICRO DEVICES, INC., ) ) Defendant. ) COMPLAINT Plaintiffs MEDIATEK INC. and MEDIATEK USA INC. (together “MediaTek” or “Plaintiffs”), for its Complaint against ADVANCED MICRO DEVICES, INC. (“AMD” or “Defendant”), hereby alleges as follows: PARTIES 1. Plaintiff MEDIATEK INC. is a Taiwanese company incorporated under the laws of Taiwan with its principal place of business located at No. 1, Dusing Road 1, Hsinchu Science Park, Hsinchu City 30078, Taiwan. MediaTek Inc. is the assignee of all patents identified in this Complaint including all rights to sue for past and future damages for infringement of said patents. 2. Plaintiff MEDIATEK USA INC. is a corporation organized and existing under the law of the State of Delaware with its principal place of business located at 2840 Junction Avenue, San Jose, California, 95134 and other locations in Austin, Texas, Bellevue, Washington, Irvine, California, San Diego, California, San Jose, California, and Woburn, Massachusetts. MediaTek USA Inc. is a wholly-owned subsidiary of MediaTek Inc. and has a license under the patents asserted here. Case 1:19-cv-00368-UNA Document 1 Filed 02/21/19 Page 2 of 58 PageID #: 2 3. Upon information and belief, AMD is a corporation organized and existing under the law of the State of Delaware, and maintains its principal place of business at 2485 Augustine Dr., Santa Clara, CA 95054 and principal administrative facilities as well as Corporate Secretary at 7171 Southwest Parkway, M/S B100.2, Austin, Texas 78735. -

AMD's Early Processor Lines, up to the Hammer Family (Families K8
AMD’s early processor lines, up to the Hammer Family (Families K8 - K10.5h) Dezső Sima October 2018 (Ver. 1.1) Sima Dezső, 2018 AMD’s early processor lines, up to the Hammer Family (Families K8 - K10.5h) • 1. Introduction to AMD’s processor families • 2. AMD’s 32-bit x86 families • 3. Migration of 32-bit ISAs and microarchitectures to 64-bit • 4. Overview of AMD’s K8 – K10.5 (Hammer-based) families • 5. The K8 (Hammer) family • 6. The K10 Barcelona family • 7. The K10.5 Shanghai family • 8. The K10.5 Istambul family • 9. The K10.5-based Magny-Course/Lisbon family • 10. References 1. Introduction to AMD’s processor families 1. Introduction to AMD’s processor families (1) 1. Introduction to AMD’s processor families AMD’s early x86 processor history [1] AMD’s own processors Second sourced processors 1. Introduction to AMD’s processor families (2) Evolution of AMD’s early processors [2] 1. Introduction to AMD’s processor families (3) Historical remarks 1) Beyond x86 processors AMD also designed and marketed two embedded processor families; • the 2900 family of bipolar, 4-bit slice microprocessors (1975-?) used in a number of processors, such as particular DEC 11 family models, and • the 29000 family (29K family) of CMOS, 32-bit embedded microcontrollers (1987-95). In late 1995 AMD cancelled their 29K family development and transferred the related design team to the firm’s K5 effort, in order to focus on x86 processors [3]. 2) Initially, AMD designed the Am386/486 processors that were clones of Intel’s processors. -

The Severest of Them All: Inference Attacks Against Secure Virtual Enclaves Jan Werner Joshua Mason Manos Antonakakis UNC Chapel Hill U
The SEVerESt Of Them All: Inference Attacks Against Secure Virtual Enclaves Jan Werner Joshua Mason Manos Antonakakis UNC Chapel Hill U. Illinois Georgia Tech [email protected] [email protected] [email protected] Michalis Polychronakis Fabian Monrose Stony Brook University UNC Chapel Hill [email protected] [email protected] ABSTRACT and Communications Security (AsiaCCS ’19), July 9–12, 2019, Auckland, The success of cloud computing has shown that the cost and con- New Zealand. ACM, New York, NY, USA, 13 pages. https://doi.org/10.1145/ venience benefits of outsourcing infrastructure, platform, and soft- 3321705.3329820 ware resources outweigh concerns about confidentiality. Still, many businesses resist moving private data to cloud providers due to in- 1 INTRODUCTION tellectual property and privacy reasons. A recent wave of hardware Of late, the need for a Trusted Execution Environment has risen virtualization technologies aims to alleviate these concerns by of- to the forefront as an important consideration for many parties in fering encrypted virtualization features that support data confiden- the cloud computing ecosystem. Cloud computing refers to the use tiality of guest virtual machines (e.g., by transparently encrypting of on-demand networked infrastructure software and capacity to memory) even when running on top untrusted hypervisors. provide resources to customers [52]. In today’s marketplace, con- We introduce two new attacks that can breach the confidentiality tent providers desire the ability to deliver copyrighted or sensitive of protected enclaves. First, we show how a cloud adversary can material to clients without the risk of data leaks. At the same time, judiciously inspect the general purpose registers to unmask the computer manufacturers must be able to verify that only trusted computation that passes through them. -

Tuning Guide for AMD EPYC™ 7002 Series Processors
High Performance Computing: Tuning Guide for AMD EPYC™ 7002 Series Processors Publication # 56827 Revision: 1.0 Issue Date: January 2020 Authors: Anre Kashyap Advanced Micro Devices ©2020 Advanced Micro Devices, Inc. All rights reserved. The information contained herein is for informational purposes only and is subject to change without notice. While every precaution has been taken in the preparation of this document, it may contain technical inaccuracies, omissions and typographical errors, and AMD is under no obligation to update or otherwise correct this information. Advanced Micro Devices, Inc. makes no representations or warranties with respect to the accuracy or completeness of the contents of this document, and assumes no liability of any kind, including the implied warranties of noninfringement, merchantability or fitness for particular purposes, with respect to the operation or use of AMD hardware, software or other products described herein. No license, including implied or arising by estoppel, to any intellectual property rights is granted by this document. Terms and limitations applicable to the purchase or use of AMD’s products are as set forth in a signed agreement between the parties or in AMD's Standard Terms and Conditions of Sale. Trademarks AMD, the AMD Arrow logo, AMD EPYC, and combinations thereof are trademarks of Advanced Micro Devices, Inc. Other product names used in this publication are for identification purposes only and may be trademarks of their respective companies. 56827 Rev. 1.0 Anre Kashyap High Performance Computing: Tuning Guide for AMD EPYC™ 7002 Series Processors Contents Chapter 1 Introduction .............................................................................................................. 6 1.1 Prerequisites ....................................................................................................................... 6 1.2 History .............................................................................................................................. -

EPYC: Designed for Effective Performance
EPYC: Designed for Effective Performance By Linley Gwennap Principal Analyst June 2017 www.linleygroup.com EPYC: Designed for Effective Performance By Linley Gwennap, Principal Analyst, The Linley Group Measuring server-processor performance using clock speed (GHz) or even the traditional SPEC_int test can be misleading. AMD’s new EPYC processor is designed to deliver strong performance across a wide range of server applications, meeting the needs of modern data centers and enterprises. These design capabilities include advanced branch prediction, data prefetching, coherent interconnect, and integrated high-bandwidth DRAM and I/O interfaces. AMD sponsored the creation of this white paper, but the opinions and analysis are those of the author. Trademark names are used in an editorial fashion and are the property of their respective owners. Although many PC users can settle for “good enough” performance, data-center opera- tors are always seeking more. Web searches demand more performance as the Internet continues to expand. Newer applications such as voice recognition (for services such as Alexa and Siri) and analyzing big data also require tremendous performance. Neural networks are gaining in popularity for everything from image recognition to self-driving cars, but training these networks can tie up hundreds of servers for days at a time. Processor designers must meet these greater performance demands while staying within acceptable electrical-power ratings. Server processors are often characterized by core count and clock speed (GHz), but these characteristics provide only a rough approximation of application performance. As important as speed is, the amount of work that a processor can accomplish with each tick of the clock, a parameter known as instructions per cycle (IPC), is equally important. -

AMD Zen Rohin, Vijay, Brandon Outline
AMD Zen Rohin, Vijay, Brandon Outline 1. History and Overview 2. Datapath Structure 3. Memory Hierarchy 4. Zen 2 Improvements History and Overview AMD History ● IBM production too large, forced Intel to license their designs to 3rd parties ● AMD fills the gap, produces clones for 15ish years - legal battles ensued ● K5 first in-house x86 chip in 1996 ● Added more features like out of order, L2 caches, etc ● Current CPUs are Zen* tomshardware.com/picturestory/71 3-amd-cpu-history.html Zen Brand ● Performance desktop and mobile computing ○ Athlon ○ Ryzen 3, Ryzen 5, Ryzen 7, Ryzen 9 ○ Ryzen Threadripper ● Server ○ EPYC https://en.wikichip.org/wiki/amd/microarchitectures/zen Zen History ● Aimed to replace two of AMD’s older chips ○ Excavator: high performance architecture ○ Puma: low power architecture https://en.wikichip.org/wiki/amd/microarchitectures/zen#Block_Diagram Zen Architecture ● Quad-core ● Fetch 4 instructions/cycle ● Op cache 2k instructions ● 168 physical integer registers ● 72 out of order loads ● Large shared L3 cache ● 2 threads per core https://www.slideshare.net/AMD/amd-epyc-microp rocessor-architecture Datapath Structure Fetch ● Decoupled branch predictor ○ Runs ahead of fetches ○ Successful predictions help latency and memory parallelism ○ Mispredictions incur power penalty ● 3 layer TLB ○ L0: 8 entries ○ L1: 64 entries ○ L2: 512 entries https://www.anandtech.com/show/10591/amd-zen-microarchiture-p art-2-extracting-instructionlevel-parallelism/3 Branch Predictor ● Perceptron: simple neural network ● Table of perceptrons, each a vector of weights ● Branch address used to access perceptron table ● Dot product between weight vector and branch history vector Perceptron Branch Predictor ● ~10% improve prediction rates over gshare predictor - (2, 2) correlating predictor ● Can utilize longer branch histories ○ Hardware requirements scale linearly whereas they scale exponentially for other predictors D. -
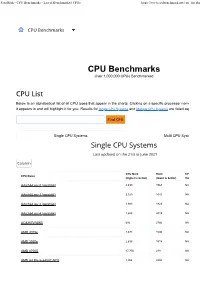
CPU Benchmarks - List of Benchmarked Cpus
PassMark - CPU Benchmarks - List of Benchmarked CPUs https://www.cpubenchmark.net/cpu_list.php CPU Benchmarks Over 1,000,000 CPUs Benchmarked Below is an alphabetical list of all CPU types that appear in the charts. Clicking on a specific processor name will take you to the ch it appears in and will highlight it for you. Results for Single CPU Systems and Multiple CPU Systems are listed separately. Single CPU Systems Multi CPU Systems CPU Mark Rank CPU Value CPU Name (higher is better) (lower is better) (higher is better) AArch64 rev 0 (aarch64) 2,499 1567 NA AArch64 rev 1 (aarch64) 2,320 1642 NA AArch64 rev 2 (aarch64) 1,983 1823 NA AArch64 rev 4 (aarch64) 1,653 2019 NA AC8257V/WAB 693 2766 NA AMD 3015e 2,678 1506 NA AMD 3020e 2,635 1518 NA AMD 4700S 17,756 238 NA AMD A4 Micro-6400T APU 1,004 2480 NA PassMark - CPU Benchmarks - List of Benchmarked CPUs https://www.cpubenchmark.net/cpu_list.php CPU Mark Rank CPU Value CPU Name (higher is better) (lower is better) (higher is better) AMD A4 PRO-7300B APU 1,481 2133 NA AMD A4 PRO-7350B 1,024 2465 NA AMD A4-1200 APU 445 3009 NA AMD A4-1250 APU 428 3028 NA AMD A4-3300 APU 961 2528 9.09 AMD A4-3300M APU 686 2778 22.86 AMD A4-3305M APU 815 2649 39.16 AMD A4-3310MX APU 785 2680 NA AMD A4-3320M APU 640 2821 16.42 AMD A4-3330MX APU 681 2781 NA AMD A4-3400 APU 1,031 2458 9.51 AMD A4-3420 APU 1,052 2443 7.74 AMD A4-4000 APU 1,158 2353 38.60 AMD A4-4020 APU 1,214 2310 13.34 AMD A4-4300M APU 997 2486 33.40 AMD A4-4355M APU 816 2648 NA AMD A4-5000 APU 1,282 2257 NA AMD A4-5050 APU 1,328 2219 NA AMD A4-5100