Automated Insect Identification Through Concatenated Histograms
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The 2014 Golden Gate National Parks Bioblitz - Data Management and the Event Species List Achieving a Quality Dataset from a Large Scale Event
National Park Service U.S. Department of the Interior Natural Resource Stewardship and Science The 2014 Golden Gate National Parks BioBlitz - Data Management and the Event Species List Achieving a Quality Dataset from a Large Scale Event Natural Resource Report NPS/GOGA/NRR—2016/1147 ON THIS PAGE Photograph of BioBlitz participants conducting data entry into iNaturalist. Photograph courtesy of the National Park Service. ON THE COVER Photograph of BioBlitz participants collecting aquatic species data in the Presidio of San Francisco. Photograph courtesy of National Park Service. The 2014 Golden Gate National Parks BioBlitz - Data Management and the Event Species List Achieving a Quality Dataset from a Large Scale Event Natural Resource Report NPS/GOGA/NRR—2016/1147 Elizabeth Edson1, Michelle O’Herron1, Alison Forrestel2, Daniel George3 1Golden Gate Parks Conservancy Building 201 Fort Mason San Francisco, CA 94129 2National Park Service. Golden Gate National Recreation Area Fort Cronkhite, Bldg. 1061 Sausalito, CA 94965 3National Park Service. San Francisco Bay Area Network Inventory & Monitoring Program Manager Fort Cronkhite, Bldg. 1063 Sausalito, CA 94965 March 2016 U.S. Department of the Interior National Park Service Natural Resource Stewardship and Science Fort Collins, Colorado The National Park Service, Natural Resource Stewardship and Science office in Fort Collins, Colorado, publishes a range of reports that address natural resource topics. These reports are of interest and applicability to a broad audience in the National Park Service and others in natural resource management, including scientists, conservation and environmental constituencies, and the public. The Natural Resource Report Series is used to disseminate comprehensive information and analysis about natural resources and related topics concerning lands managed by the National Park Service. -

Monte L. Bean Life Science Museum Brigham Young University Provo, Utah 84602 PBRIA a Newsletter for Plecopterologists
No. 10 1990/1991 Monte L. Bean Life Science Museum Brigham Young University Provo, Utah 84602 PBRIA A Newsletter for Plecopterologists EDITORS: Richard W, Baumann Monte L. Bean Life Science Museum Brigham Young University Provo, Utah 84602 Peter Zwick Limnologische Flußstation Max-Planck-Institut für Limnologie, Postfach 260, D-6407, Schlitz, West Germany EDITORIAL ASSISTANT: Bonnie Snow REPORT 3rd N orth A merican Stonefly S ymposium Boris Kondratieff hosted an enthusiastic group of plecopterologists in Fort Collins, Colorado during May 17-19, 1991. More than 30 papers and posters were presented and much fruitful discussion occurred. An enjoyable field trip to the Colorado Rockies took place on Sunday, May 19th, and the weather was excellent. Boris was such a good host that it was difficult to leave, but many participants traveled to Santa Fe, New Mexico to attend the annual meetings of the North American Benthological Society. Bill Stark gave us a way to remember this meeting by producing a T-shirt with a unique “Spirit Fly” design. ANNOUNCEMENT 11th International Stonefly Symposium Stan Szczytko has planned and organized an excellent symposium that will be held at the Tree Haven Biological Station, University of Wisconsin in Tomahawk, Wisconsin, USA. The registration cost of $300 includes lodging, meals, field trip and a T- Shirt. This is a real bargain so hopefully many colleagues and friends will come and participate in the symposium August 17-20, 1992. Stan has promised good weather and good friends even though he will not guarantee that stonefly adults will be collected during the field trip. Printed August 1992 1 OBITUARIES RODNEY L. -

Download .PDF(1340
Stark, Bill P. and Stephen Green. 2011. Eggs of western Nearctic Acroneuriinae (Plecoptera: Perlidae). Illiesia, 7(17):157-166. Available online: http://www2.pms-lj.si/illiesia/Illiesia07-17.pdf EGGS OF WESTERN NEARCTIC ACRONEURIINAE (PLECOPTERA: PERLIDAE) Bill P. Stark1 and Stephen Green2 1,2 Box 4045, Department of Biology, Mississippi College, Clinton, Mississippi, U.S.A. 39058 1 E-mail: [email protected] 2 E-mail: [email protected] ABSTRACT Eggs for western Nearctic acroneuriine species of Calineuria Ricker, Doroneuria Needham & Claassen and Hesperoperla Banks are examined and redescribed based on scanning electron microscopy images taken from specimens collected from a substantial portion of each species range. Within genera, species differences in egg morphology are small and not always useful for species recognition, however eggs from one population of Calineuria are significantly different from those found in other populations and this population is given informal recognition as a possible new species. Keywords: Plecoptera, Calineuria, Doroneuria, Hesperoperla, Egg morphology, Western Nearctic INTRODUCTION occur in the region (Baumann & Olson 1984; Scanning electron microscopy (SEM) is often used Kondratieff & Baumann 2002; Stark 1989; Stark & to elucidate chorionic features for stoneflies (e.g. Gaufin 1976; Stark & Kondratieff 2004; Zuellig et al. Baumann 1973; Grubbs 2005; Isobe 1988; Kondratieff 2006). SEM images for eggs of the primary western 2004; Kondratieff & Kirchner 1996; Nelson 2000; acroneuriine genera, Calineuria Ricker, Doroneuria Sivec & Stark 2002; 2008; Stark & Nelson 1994; Stark Needham & Claassen and Hesperoperla Banks include & Szczytko 1982; 1988; Szczytko & Stewart 1979) and single images for each of these genera in Stark & Nearctic Perlidae were among the earliest stoneflies Gaufin (1976), three images of Hesperoperla hoguei to be studied with this technique (Stark & Gaufin Baumann & Stark (1980) and three images of H. -
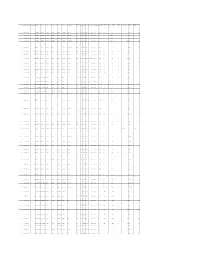
Appendix D: Summary of Accepted ECOTOX Papers
Effect Dur Dur Unit Dur Dur Unit Conc Conc Units Conc Value1 Purity CAS Number Chemical Name Species Number Phylum Class Order Family Genus Species Common Name Group Effect Meas Endpt1 Endpt2 Habitat Plant/Animal Media Orig Orig Preferred Preferred Type Conc Value1 Orig Orig Adjusted 1 298044 Disulfoton 4510 Chordata Mammalia Rodentia Muridae Rattus norvegicus Norway rat BEH AVO STIM NOAEL terrestrial Animal NONE 30 d 30 d F 2 mg/kg/d 1.96 2 298044 Disulfoton 351 Chordata Actinopterygii Perciformes Anabantidae Anabas testudineus Climbing perch BCM BCM LIPD LOAEL aquatic Animal FW 1 h 4.17E-02 d A 4 mg/L 4 3 298044 Disulfoton 351 Chordata Actinopterygii Perciformes Anabantidae Anabas testudineus Climbing perch BCM BCM PRCO LOAEL aquatic Animal FW 1 h 4.17E-02 d A 4 mg/L 4 4 298044 Disulfoton 351 Chordata Actinopterygii Perciformes Anabantidae Anabas testudineus Climbing perch BCM BCM LIPD LOAEL aquatic Animal FW 1 h 4.17E-02 d A 10.5 mg/L 10.5 5 298044 Disulfoton 4913 Chordata Mammalia Rodentia Muridae Mus musculus House mouse BCM BCM HXBT LOAEL terrestrial Animal NONE 3 d 3 d F 35.1 uM/kg 35.1 6 298044 Disulfoton 4510 Chordata Mammalia Rodentia Muridae Rattus norvegicus Norway rat BCM BCM GBCM LOAEL terrestrial Animal NONE 24 h 1 d F 0.26 mg/kg 0.234 7 298044 Disulfoton 4510 Chordata Mammalia Rodentia Muridae Rattus norvegicus Norway rat BCM BCM GBCM IC50 terrestrial Animal NONE 1 wk 7 d F 0.6 ppm 0.6 8 298044 Disulfoton 4510 Chordata Mammalia Rodentia Muridae Rattus norvegicus Norway rat BCM BCM GBCM NOAEL LOAEL terrestrial Animal NONE -

Plecoptera: Perlidae), with an Annotated Checklist of the Subfamily in the Realm
Opusc. Zool. Budapest, 2016, 47(2): 173–196 On the identity of some Oriental Acroneuriinae taxa (Plecoptera: Perlidae), with an annotated checklist of the subfamily in the realm D. MURÁNYI1 & W.H. LI2 1Dávid Murányi, Department of Civil and Environmental Engineering, Ehime University, Bunkyo-cho 3, Matsuyama, 790-8577 Japan, and Department of Zoology, Hungarian Natural History Museum, H-1088 Budapest, Baross u. 13, Hungary. E-mail: [email protected], [email protected] 2Weihai Li, Department of Plant Protection, Henan Institute of Science and Technology, Xinxiang, Henan, 453003 China. E-mail: [email protected] Abstract. The monotypic Taiwanese genus Mesoperla Klapálek, 1913 is redescribed on the basis of a male syntype specimen, and its affinities are re-evaluated. The single female type specimen of further two Oriental monotypic genera, Kalidasia Klapálek, 1914 and Nirvania Klapálek, 1914, are confirmed to be lost or destroyed respectively; both genera are considered as nomina dubia. The Sichuan endemic Acroneuria grahami Wu & Claassen, 1934 is redescribed on the basis of male holotype. Distinctive characters of the genus Brahmana Klapálek, 1914 consisting of five, inadequately known Oriental species are discussed. Flavoperla needhami (Klapálek, 1916) and Sinacroneuria sinica (Yang & Yang, 1998) comb. novae are suggested for an Indian species originally described in Gibosia Okamoto, 1912 and a Chinese species originally described in Acroneuria Pictet, 1841. At present, 62 species of Acroneuriinae, classified in 10 valid genera are reported from the Oriental Realm but 29 species are inadequately known. A key is presented to distinguish males of the Asian Acroneuriinae genera. Asian distribution of each genera are detailed and depicted on a map. -

The Effects of Electricity on Some Aquatic Invertebrates
The effects of electricity on some aquatic invertebrates Item Type text; Thesis-Reproduction (electronic) Authors Mesick, Carl Frederick Publisher The University of Arizona. Rights Copyright © is held by the author. Digital access to this material is made possible by the University Libraries, University of Arizona. Further transmission, reproduction or presentation (such as public display or performance) of protected items is prohibited except with permission of the author. Download date 26/09/2021 21:59:29 Link to Item http://hdl.handle.net/10150/558075 THE EFFECTS OF ELECTRICITY ON SOME AQUATIC INVERTEBRATES by Carl Frederick Mesick A Thesis Submitted to the Faculty of the SCHOOL OF RENEWABLE NATURAL RESOURCES In Partial Fulfillment of Requirements For the Degree of MASTER OF SCIENCE WITH A MAJOR IN FISHERIES SCIENCE In the Graduate College THE UNIVERSITY OF ARIZONA 1 9 7 9 STATEMENT BY AUTHOR This thesis has been submitted in partial fulfill ment of requirements for an advanced degree at The University of Arizona and is deposited in the University Library to be made available to borrowers under rules of the Libraryo Brief quotations from this thesis are allowable without special permission, provided that accurate acknowl edgment of source is made. Requests for permission for extended quotation from or reproduction of this manuscript in whole or in part may be granted by the head of the major department or the Dean of the Graduate College when in his judgment the proposed use of the material is in the inter ests of scholarship. In all other instances, however, permission must be obtained from the author, SIGNED i ' ^ V[ APPROVAL BY THESIS DIRECTOR This thesis has been approved on the date shown below: JERRY C . -

Aquatic Insect Ecophysiological Traits Reveal Phylogenetically Based Differences in Dissolved Cadmium Susceptibility
Aquatic insect ecophysiological traits reveal phylogenetically based differences in dissolved cadmium susceptibility David B. Buchwalter*†, Daniel J. Cain‡, Caitrin A. Martin*, Lingtian Xie*, Samuel N. Luoma‡, and Theodore Garland, Jr.§ *Department of Environmental and Molecular Toxicology, Campus Box 7633, North Carolina State University, Raleigh, NC 27604; ‡Water Resources Division, U.S. Geological Survey, 345 Middlefield Road, MS 465, Menlo Park, CA 94025; and §Department of Biology, University of California, Riverside, CA 92521 Edited by George N. Somero, Stanford University, Pacific Grove, CA, and approved April 28, 2008 (received for review February 20, 2008) We used a phylogenetically based comparative approach to evaluate ecosystems today (e.g., trace metals) (6). This variation in the potential for physiological studies to reveal patterns of diversity susceptibility has practical implications, because the ecological in traits related to susceptibility to an environmental stressor, the structure of aquatic insect communities is often used to indicate trace metal cadmium (Cd). Physiological traits related to Cd bioaccu- the ecological conditions in freshwater systems (7–9). Differ- mulation, compartmentalization, and ultimately susceptibility were ences among species’ responses to environmental stressors can measured in 21 aquatic insect species representing the orders be profound, but it is uncertain whether the cause is related to Ephemeroptera, Plecoptera, and Trichoptera. We mapped these ex- functional ecology [usually the assumption (10, 11)] or physio- perimentally derived physiological traits onto a phylogeny and quan- logical traits (5, 12–14), which have received considerably less tified the tendency for related species to be similar (phylogenetic attention. To the degree that either is involved, their link to signal). -

Phenology and Diversity of Adult Stoneflies (Plecoptera) of a Small Coastal Stream, California
Bottorff, Richard L., Loren D. Bottorff, 2007. Phenology and diversity of adult stoneflies (Plecoptera) of a small coastal stream, California. Illiesia, 3(1):1‐9. Available online: http://www2.pms‐lj.si/illiesia/Illiesia03‐01.pdf PHENOLOGY AND DIVERSITY OF ADULT STONEFLIES (PLECOPTERA) OF A SMALL COASTAL STREAM, CALIFORNIA Richard L. Bottorff1 and Loren D. Bottorff 2 11963 Toppewetah Street, South Lake Tahoe, CA 96150, E‐mail: [email protected] 23265 Sandhurst Court, Cameron Park, CA 95682, E‐mail: [email protected] ABSTRACT Collections of adult stoneflies over a full year at Irish Gulch Creek, Mendocino Co., California, revealed 23 species. Adults were present at all times of the year. Species number varied from an autumnal low of 2 to a spring peak of 13. Adults of most species were present for less than 3 months, but Malenka depressa adults were present year‐round. Hesperoperla hoguei was the only strictly autumnal‐emerging species. The report of Suwallia dubia from Irish Gulch Creek represents a new California record. The stonefly faunas of Irish Gulch Creek (low coastal) and Sagehen Creek (high Sierra Nevada) were compared. Both creeks had similar numbers of species, but the species composition differed greatly, reflecting dissimilar environments (elevation, water temperature, thermal accumulation, and discharge). Irish Gulch Creek had uniform warmer temperatures; Sagehen Creek had variable colder temperatures. Peak emergence at Irish Gulch Creek occurred 2 months earlier than at Sagehen Creek. Keywords: Plecoptera, seasonal flight period, biodiversity, thermal stability, North Coast bioregion INTRODUCTION we studied these aspects for a small stream on the As might be expected from its varied topography, north coast of California. -

Ancient Rapid Radiations of Insects: Challenges for Phylogenetic Analysis
ANRV330-EN53-23 ARI 2 November 2007 18:40 Ancient Rapid Radiations of Insects: Challenges for Phylogenetic Analysis James B. Whitfield1 and Karl M. Kjer2 1Department of Entomology, University of Illinois, Urbana, Illinois 61821; email: jwhitfi[email protected] 2Department of Ecology, Evolution and Natural Resources, Rutgers University, New Brunswick, New Jersey 08901; email: [email protected] Annu. Rev. Entomol. 2008. 53:449–72 Key Words First published online as a Review in Advance on diversification, molecular evolution, Palaeoptera, Orthopteroidea, September 17, 2007 fossils The Annual Review of Entomology is online at ento.annualreviews.org Abstract by UNIVERSITY OF ILLINOIS on 12/18/07. For personal use only. This article’s doi: Phylogenies of major groups of insects based on both morphological 10.1146/annurev.ento.53.103106.093304 and molecular data have sometimes been contentious, often lacking Copyright c 2008 by Annual Reviews. the data to distinguish between alternative views of relationships. Annu. Rev. Entomol. 2008.53:449-472. Downloaded from arjournals.annualreviews.org All rights reserved This paucity of data is often due to real biological and historical 0066-4170/08/0107-0449$20.00 causes, such as shortness of time spans between divergences for evo- lution to occur and long time spans after divergences for subsequent evolutionary changes to obscure the earlier ones. Another reason for difficulty in resolving some of the relationships using molecu- lar data is the limited spectrum of genes so far developed for phy- logeny estimation. For this latter issue, there is cause for current optimism owing to rapid increases in our knowledge of comparative genomics. -

Physical Data and Biological Data for Algae, Aquatic Invertebrates, and Fish from Selected Reaches on the Carson and Truckee Rivers, Nevada and California, 1993–97
U.S. Department of the Interior U.S. Geological Survey Physical Data and Biological Data for Algae, Aquatic Invertebrates, and Fish from Selected Reaches on the Carson and Truckee Rivers, Nevada and California, 1993–97 Open-File Report 02–012 Prepared as part of the NATIONAL WATER-QUALITY ASSESSMENT PROGRAM U.S. Department of the Interior U.S. Geological Survey Physical Data and Biological Data for Algae, Aquatic Invertebrates, and Fish from Selected Reaches on the Carson and Truckee Rivers, Nevada and California, 1993–97 By Stephen J. Lawrence and Ralph L. Seiler Open-File Report 02–012 Prepared as part of the NATIONAL WATER QUALITY ASSESSMENT PROGRAM Carson City, Nevada 2002 U.S. DEPARTMENT OF THE INTERIOR GALE A. NORTON, Secretary U.S. GEOLOGICAL SURVEY CHARLES G. GROAT, Director Any use of trade, product, or firm names in this publication is for descriptive purposes only and does not imply endorsement by the U.S. Government For additional information contact: District Chief U.S. Geological Survey U.S. Geological Survey Information Services 333 West Nye Lane, Room 203 Building 810 Carson City, NV 89706–0866 Box 25286, Federal Center Denver, CO 80225–0286 email: [email protected] http://nevada.usgs.gov CONTENTS Abstract.................................................................................................................................................................................. 1 Introduction........................................................................................................................................................................... -

Annual Newsletter and Bibliography of the International Society of Plecopterologists
PERLA Annual Newsletter and Bibliography of The International Society of Plecopterologists Capnia valhalla Nelson & Baumann (Capniidae), ♂. California: San Diego Co. Palomar Mountain, Fry Creek. Photograph by C. R. Nelson PERLA NO. 30, 2012 Department of Bioagricultural Sciences and Pest Management Colorado State University Fort Collins, Colorado 80523 USA PERLA Annual Newsletter and Bibliography of the International Society of Plecopterologists Available on Request to the Managing Editor MANAGING EDITOR: Boris C. Kondratieff Department of Bioagricultural Sciences And Pest Management Colorado State University Fort Collins, Colorado 80523 USA E-mail: [email protected] EDITORIAL BOARD: Richard W. Baumann Department of Biology and Monte L. Bean Life Science Museum Brigham Young University Provo, Utah 84602 USA E-mail: [email protected] J. Manuel Tierno de Figueroa Dpto. de Biología Animal Facultad de Ciencias Universidad de Granada 18071 Granada, SPAIN E-mail: [email protected] Kenneth W. Stewart Department of Biological Sciences University of North Texas Denton, Texas 76203, USA E-mail: [email protected] Shigekazu Uchida Aichi Institute of Technology 1247 Yagusa Toyota 470-0392, JAPAN E-mail: [email protected] Peter Zwick Schwarzer Stock 9 D-36110 Schlitz, GERMANY E-mail: [email protected] 2 TABLE OF CONTENTS Subscription policy………………………………………………………..…………….4 2012 XIIIth International Conference on Ephemeroptera, XVIIth International Symposium on Plecoptera in JAPAN…………………………………………………………………………………...5 How to host -

Stark Et Al Stonefliy Common Names 1998.Pmd
Ohio Biological Survey Notes 1: 1-18, 1998. © Ohio Biological Survey Common Names of Stoneflies (Plecoptera) from the United States and Canada BILL P. S TARK1, KENNETH W. STEWART2, STANLEY W. SZCZYTKO3, AND RICHARD W. BAUMANN4 1 Dept. of Biology, Mississippi College, Clinton, MS 39058. 2 Dept. of Biological Sciences, Univ. of North Texas, Denton, TX 76203. 3 College of Natural Resources, Univ. of Wisconsin, Stevens Point, WI 54481. 4 Dept. of Zoology, Brigham Young Univ., Provo, UT 84602 Introduction Stoneflies are one of the important and often dominant orders of insects in North American stream ecosystems. They have remained generally poorly known to nonspecialists because of their cryptic habits, and often nocturnal activity. Larger species, or those that are colorful or important to flyfishers, have acquired regional or local names that vary from place to place. Names such as blacks, browns, greens, yellows, rollwings, needleflies, broadbacks, sallies, olives, stones, willowflies, or the generic names Acroneuria, Isoperla, Pteronarcys and others have become firmly established in fly fishing literature, and are used by flyfishers. The following list of recommended common names of Plecoptera species from the United States and Canada was originally formulated by us, acting as a subcommittee of the North American Benthological Society Scientific and Common Names Committee. This committee was charged with producing comprehensive species checklists of North American aquatic invertebrates, including insects with assigned common names. The first of the intended series of special publications by the American Fisheries Society of scientific and common names of U.S. aquatic invertebrates was of mollusks (Turgeon et al., 1988); the volumes on Insecta never followed.