Architecture, Scheduling, and Machine Learning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Binary Counter
Systems I: Computer Organization and Architecture Lecture 8: Registers and Counters Registers • A register is a group of flip-flops. – Each flip-flop stores one bit of data; n flip-flops are required to store n bits of data. – There are several different types of registers available commercially. – The simplest design is a register consisting only of flip- flops, with no other gates in the circuit. • Loading the register – transfer of new data into the register. • The flip-flops share a common clock pulse (frequently using a buffer to reduce power requirements). • Output could be sampled at any time. • Clearing the flip-flop (placing zeroes in all its bit) can be done through a special terminal on the flip-flop. 1 4-bit Register I0 D Q A0 Clock C I1 D Q A1 C I D Q 2 A2 C D Q A I3 3 C Clear Registers With Parallel Load • The clock usually provides a steady stream of pulses which are applied to all flip-flops in the system. • A separate control system is needed to determine when to load a particular register. • The Register with Parallel Load has a separate load input. – When it is cleared, the register receives it output as input. – When it is set, it received the load input. 2 4-bit Register With Parallel Load Load D Q A0 I0 C D Q A1 C I1 D Q A2 I2 C D Q A3 I3 C Clock Shift Registers • A shift register is a register which can shift its data in one or both directions. -

Arithmetic and Logic Unit (ALU)
Computer Arithmetic: Arithmetic and Logic Unit (ALU) Arithmetic & Logic Unit (ALU) • Part of the computer that actually performs arithmetic and logical operations on data • All of the other elements of the computer system are there mainly to bring data into the ALU for it to process and then to take the results back out • Based on the use of simple digital logic devices that can store binary digits and perform simple Boolean logic operations ALU Inputs and Outputs Integer Representations • In the binary number system arbitrary numbers can be represented with: – The digits zero and one – The minus sign (for negative numbers) – The period, or radix point (for numbers with a fractional component) – For purposes of computer storage and processing we do not have the benefit of special symbols for the minus sign and radix point – Only binary digits (0,1) may be used to represent numbers Integer Representations • There are 4 commonly known (1 not common) integer representations. • All have been used at various times for various reasons. 1. Unsigned 2. Sign Magnitude 3. One’s Complement 4. Two’s Complement 5. Biased (not commonly known) 1. Unsigned • The standard binary encoding already given. • Only positive value. • Range: 0 to ((2 to the power of N bits) – 1) • Example: 4 bits; (2ˆ4)-1 = 16-1 = values 0 to 15 Semester II 2014/2015 8 1. Unsigned (Cont’d.) Semester II 2014/2015 9 2. Sign-Magnitude • All of these alternatives involve treating the There are several alternative most significant (leftmost) bit in the word as conventions used to -

FUNDAMENTALS of COMPUTING (2019-20) COURSE CODE: 5023 502800CH (Grade 7 for ½ High School Credit) 502900CH (Grade 8 for ½ High School Credit)
EXPLORING COMPUTER SCIENCE NEW NAME: FUNDAMENTALS OF COMPUTING (2019-20) COURSE CODE: 5023 502800CH (grade 7 for ½ high school credit) 502900CH (grade 8 for ½ high school credit) COURSE DESCRIPTION: Fundamentals of Computing is designed to introduce students to the field of computer science through an exploration of engaging and accessible topics. Through creativity and innovation, students will use critical thinking and problem solving skills to implement projects that are relevant to students’ lives. They will create a variety of computing artifacts while collaborating in teams. Students will gain a fundamental understanding of the history and operation of computers, programming, and web design. Students will also be introduced to computing careers and will examine societal and ethical issues of computing. OBJECTIVE: Given the necessary equipment, software, supplies, and facilities, the student will be able to successfully complete the following core standards for courses that grant one unit of credit. RECOMMENDED GRADE LEVELS: 9-12 (Preference 9-10) COURSE CREDIT: 1 unit (120 hours) COMPUTER REQUIREMENTS: One computer per student with Internet access RESOURCES: See attached Resource List A. SAFETY Effective professionals know the academic subject matter, including safety as required for proficiency within their area. They will use this knowledge as needed in their role. The following accountability criteria are considered essential for students in any program of study. 1. Review school safety policies and procedures. 2. Review classroom safety rules and procedures. 3. Review safety procedures for using equipment in the classroom. 4. Identify major causes of work-related accidents in office environments. 5. Demonstrate safety skills in an office/work environment. -

The Central Processing Unit(CPU). the Brain of Any Computer System Is the CPU
Computer Fundamentals 1'stage Lec. (8 ) College of Computer Technology Dept.Information Networks The central processing unit(CPU). The brain of any computer system is the CPU. It controls the functioning of the other units and process the data. The CPU is sometimes called the processor, or in the personal computer field called “microprocessor”. It is a single integrated circuit that contains all the electronics needed to execute a program. The processor calculates (add, multiplies and so on), performs logical operations (compares numbers and make decisions), and controls the transfer of data among devices. The processor acts as the controller of all actions or services provided by the system. Processor actions are synchronized to its clock input. A clock signal consists of clock cycles. The time to complete a clock cycle is called the clock period. Normally, we use the clock frequency, which is the inverse of the clock period, to specify the clock. The clock frequency is measured in Hertz, which represents one cycle/second. Hertz is abbreviated as Hz. Usually, we use mega Hertz (MHz) and giga Hertz (GHz) as in 1.8 GHz Pentium. The processor can be thought of as executing the following cycle forever: 1. Fetch an instruction from the memory, 2. Decode the instruction (i.e., determine the instruction type), 3. Execute the instruction (i.e., perform the action specified by the instruction). Execution of an instruction involves fetching any required operands, performing the specified operation, and writing the results back. This process is often referred to as the fetch- execute cycle, or simply the execution cycle. -

Cross Architectural Power Modelling
Cross Architectural Power Modelling Kai Chen1, Peter Kilpatrick1, Dimitrios S. Nikolopoulos2, and Blesson Varghese1 1Queen’s University Belfast, UK; 2Virginia Tech, USA E-mail: [email protected]; [email protected]; [email protected]; [email protected] Abstract—Existing power modelling research focuses on the processor are extensively explored using a cumbersome trial model rather than the process for developing models. An auto- and error approach after which a suitable few are selected [7]. mated power modelling process that can be deployed on different Such an approach does not easily scale for various processor processors for developing power models with high accuracy is developed. For this, (i) an automated hardware performance architectures since a different set of hardware counters will be counter selection method that selects counters best correlated to required to model power for each processor. power on both ARM and Intel processors, (ii) a noise filter based Currently, there is little research that develops automated on clustering that can reduce the mean error in power models, and (iii) a two stage power model that surmounts challenges in methods for selecting hardware counters to capture proces- using existing power models across multiple architectures are sor power over multiple processor architectures. Automated proposed and developed. The key results are: (i) the automated methods are required for easily building power models for a hardware performance counter selection method achieves compa- collection of heterogeneous processors as seen in traditional rable selection to the manual method reported in the literature, data centers that host multiple generations of server proces- (ii) the noise filter reduces the mean error in power models by up to 55%, and (iii) the two stage power model can predict sors, or in emerging distributed computing environments like dynamic power with less than 8% error on both ARM and Intel fog/edge computing [8] and mobile cloud computing (in these processors, which is an improvement over classic models. -

Experiment No
1 LIST OF EXPERIMENTS 1. Study of logic gates. 2. Design and implementation of adders and subtractors using logic gates. 3. Design and implementation of code converters using logic gates. 4. Design and implementation of 4-bit binary adder/subtractor and BCD adder using IC 7483. 5. Design and implementation of 2-bit magnitude comparator using logic gates, 8- bit magnitude comparator using IC 7485. 6. Design and implementation of 16-bit odd/even parity checker/ generator using IC 74180. 7. Design and implementation of multiplexer and demultiplexer using logic gates and study of IC 74150 and IC 74154. 8. Design and implementation of encoder and decoder using logic gates and study of IC 7445 and IC 74147. 9. Construction and verification of 4-bit ripple counter and Mod-10/Mod-12 ripple counter. 10. Design and implementation of 3-bit synchronous up/down counter. 11. Implementation of SISO, SIPO, PISO and PIPO shift registers using flip-flops. KCTCET/2016-17/Odd/3rd/ETE/CSE/LM 2 EXPERIMENT NO. 01 STUDY OF LOGIC GATES AIM: To study about logic gates and verify their truth tables. APPARATUS REQUIRED: SL No. COMPONENT SPECIFICATION QTY 1. AND GATE IC 7408 1 2. OR GATE IC 7432 1 3. NOT GATE IC 7404 1 4. NAND GATE 2 I/P IC 7400 1 5. NOR GATE IC 7402 1 6. X-OR GATE IC 7486 1 7. NAND GATE 3 I/P IC 7410 1 8. IC TRAINER KIT - 1 9. PATCH CORD - 14 THEORY: Circuit that takes the logical decision and the process are called logic gates. -

Computer Monitor and Television Recycling
Computer Monitor and Television Recycling What is the problem? Televisions and computer monitors can no longer be discarded in the normal household containers or commercial dumpsters, effective April 10, 2001. Televisions and computer monitors may contain picture tubes called cathode ray tubes (CRT’s). CRT’s can contain lead, cadmium and/or mercury. When disposed of in a landfill, these metals contaminate soil and groundwater. Some larger television sets may contain as much as 15 pounds of lead. A typical 15‐inch CRT computer monitor contains 1.5 pounds of lead. The State Department of Toxic Substances Control has determined that televisions and computer monitors can no longer be disposed with typical household trash, or recycled with typical household recyclables. They are considered universal waste that needs to be disposed of through alternate ways. CRTs should be stored in a safe manner that prevents the CRT from being broken and the subsequent release of hazardous waste into the environment. Locations that will accept televisions, computers, and other electronic waste (e‐waste): If the product still works, trying to find someone that can still use it (donating) is the best option before properly disposing of an electronic product. Non‐profit organizations, foster homes, schools, and places like St. Vincent de Paul may be possible examples of places that will accept usable products. Or view the E‐waste Recycling List at http://www.mercedrecycles.com/pdf's/EwasteRecycling.pdf Where can businesses take computer monitors, televisions, and other electronics? Businesses located within Merced County must register as a Conditionally Exempt Small Quantity Generator (CESQG) prior to the delivery of monitors and televisions to the Highway 59 Landfill. -
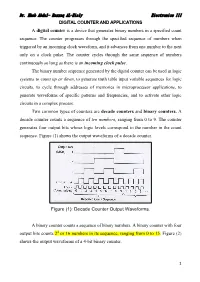
1 DIGITAL COUNTER and APPLICATIONS a Digital Counter Is
Dr. Ehab Abdul- Razzaq AL-Hialy Electronics III DIGITAL COUNTER AND APPLICATIONS A digital counter is a device that generates binary numbers in a specified count sequence. The counter progresses through the specified sequence of numbers when triggered by an incoming clock waveform, and it advances from one number to the next only on a clock pulse. The counter cycles through the same sequence of numbers continuously so long as there is an incoming clock pulse. The binary number sequence generated by the digital counter can be used in logic systems to count up or down, to generate truth table input variable sequences for logic circuits, to cycle through addresses of memories in microprocessor applications, to generate waveforms of specific patterns and frequencies, and to activate other logic circuits in a complex process. Two common types of counters are decade counters and binary counters. A decade counter counts a sequence of ten numbers, ranging from 0 to 9. The counter generates four output bits whose logic levels correspond to the number in the count sequence. Figure (1) shows the output waveforms of a decade counter. Figure (1): Decade Counter Output Waveforms. A binary counter counts a sequence of binary numbers. A binary counter with four output bits counts 24 or 16 numbers in its sequence, ranging from 0 to 15. Figure (2) shows-the output waveforms of a 4-bit binary counter. 1 Dr. Ehab Abdul- Razzaq AL-Hialy Electronics III Figure (2): Binary Counter Output Waveforms. EXAMPLE (1): Decade Counter. Problem: Determine the 4-bit decade counter output that corresponds to the waveforms shown in Figure (1). -

Console Games in the Age of Convergence
Console Games in the Age of Convergence Mark Finn Swinburne University of Technology John Street, Melbourne, Victoria, 3122 Australia +61 3 9214 5254 mfi [email protected] Abstract In this paper, I discuss the development of the games console as a converged form, focusing on the industrial and technical dimensions of convergence. Starting with the decline of hybrid devices like the Commodore 64, the paper traces the way in which notions of convergence and divergence have infl uenced the console gaming market. Special attention is given to the convergence strategies employed by key players such as Sega, Nintendo, Sony and Microsoft, and the success or failure of these strategies is evaluated. Keywords Convergence, Games histories, Nintendo, Sega, Sony, Microsoft INTRODUCTION Although largely ignored by the academic community for most of their existence, recent years have seen video games attain at least some degree of legitimacy as an object of scholarly inquiry. Much of this work has focused on what could be called the textual dimension of the game form, with works such as Finn [17], Ryan [42], and Juul [23] investigating aspects such as narrative and character construction in game texts. Another large body of work focuses on the cultural dimension of games, with issues such as gender representation and the always-controversial theme of violence being of central importance here. Examples of this approach include Jenkins [22], Cassell and Jenkins [10] and Schleiner [43]. 45 Proceedings of Computer Games and Digital Cultures Conference, ed. Frans Mäyrä. Tampere: Tampere University Press, 2002. Copyright: authors and Tampere University Press. Little attention, however, has been given to the industrial dimension of the games phenomenon. -

Design and Implementation of High Speed Counters Using “MUX Based Full Adder (MFA)”
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-ISSN: 2278-2834,p- ISSN: 2278-8735.Volume 14, Issue 4, Ser. I (Jul.-Aug. 2019), PP 57-64 www.iosrjournals.org Design and Implementation of High speed counters using “MUX based Full Adder (MFA)” K.V.Jyothi1, G.P.S. Prashanti2, 1Student, 2Assistant Professor 1,2,(Department of Electronics and Communication Engineering, Gayatri Vidya Parishad College of Engineering For Women,Visakhapatnam, Andhra Pradesh, India) Corresponding Author: K.V.Jyothi Abstract: In this brief, a new binary counter design is proposed. Counters are used to determine how many number of inputs are active (in the logic ONE state) for multi input circuits. In the existing systems 6:3 and 7:3 Counters are designed with full and half adders, parallel counters, stacking circuits. It uses 3-bit stacking and 6-bit stacking circuits which group all the “1” bits together and then stacks are converted into binary counts. This leads to increase in delay and area. To overcome this problem “MUX based Full adder (MFA)” 6:3 and 7:3 counters are proposed. The backend counter simulations are achieved by using MENTOR GRAPHICS in 130nm technology and frontend simulations are done by using XILINX. This MFA counter is faster than existing stacking counters and also consumesless area. Additionally, using this counters in Wallace tree multiplier architectures reduces latency for 64 and 128-bit multipliers. Keywords: stacking circuits, parallel counters,High speed counters, MUX based full adder (MFA) counter,Mentor graphics,Xilinx,SPARTAN-6 FPGA. ----------------------------------------------------------------------------------------------------------------------------- ---------- Date of Submission: 28-07-2019 Date of acceptance: 13-08-2019 ----------------------------------------------------------------------------------------------------------------------------- ---------- I. -

What Is a Microprocessor?
Behavior Research Methods & Instrumentation 1978, Vol. 10 (2),238-240 SESSION VII MICROPROCESSORS IN PSYCHOLOGY: A SYMPOSIUM MISRA PAVEL, New York University, Presider What is a microprocessor? MISRA PAVEL New York University, New York, New York 10003 A general introduction to microcomputer terminology and concepts is provided. The purpose of this introduction is to provide an overview of this session and to introduce the termi MICROPROCESSOR SYSTEM nology and some of the concepts that will be discussed in greater detail by the rest of the session papers. PERIPNERILS EIPERI MENT II A block diagram of a typical small computer system USS PRINIER KErBOARD INIERfICE is shown in Figure 1. Four distinct blocks can be STDRIGE distinguished: (1) the central processing unit (CPU); (2) external memory; (3) peripherals-mass storage, CONTROL standard input/output, and man-machine interface; 0111 BUS (4) special purpose (experimental) interface. IODiISS The different functional units in the system shown here are connected, more or less in parallel, by a number CENTKll ElIEBUL of lines commonly referred to as a bus. The bus mediates PROCESSING ME MOil transfer of information among the units by carrying UN IT address information, data, and control signals. For example, when the CPU transfers data to memory, it activates appropriate control lines, asserts the desired Figure 1. Block diagram of a smaIl computer system. destination memory address, and then outputs data on the bus. Traditionally, the entire system was built from a CU multitude of relatively simple components mounted on interconnected printed circuit cards. With the advances of integrated circuit technology, large amounts of circuitry were squeezed into a single chip. -
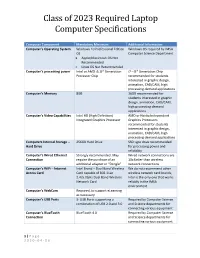
Class of 2023 Required Laptop Computer Specifications
Class of 2023 Required Laptop Computer Specifications Computer Component Mandatory Minimum Additional Information Computer’s Operating System Windows 10 Professional Edition Windows OS required by IMSA OS Computer Science Department Apple/Macintosh OS Not Recommended Linux OS Not Recommended Computer’s processing power Intel or AMD i5, 8th Generation i7 – 8th Generation Chip Processor Chip recommended for students interested in graphic design, animation, CAD/CAM, high processing demand applications Computer’s Memory 8GB 16GB recommended for students interested in graphic design, animation, CAD/CAM, high processing demand applications Computer’s Video Capabilities Intel HD (High Definition) AMD or Nvidia Independent Integrated Graphics Processor Graphics Processors recommended for students interested in graphic design, animation, CAD/CAM, high processing demand applications Computers Internal Storage – 256GB Hard Drive SSD type drive recommended Hard Drive for processing power and reliability Computer’s Wired Ethernet Strongly recommended. May Wired network connections are Connection require the purchase of an 10x faster than wireless additional adapter or “Dongle” network connections Computer’s WiFi – Internet Intel Brand – Dual Band Wireless We do not recommend other Access Card Card capable of 802.11ac wireless network card brands, 2.4/5.0GHz Dual Band Wireless Intel is the only one that works Network Card reliably in the IMSA environment Computer’s WebCam Required, to support eLearning as necessary Computer’s USB Ports 3- USB Ports