Cloud Computing Contents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Oracle Database User's Guide for Fujitsu Siemens BS2000/OSD
Oracle® Database User's Guide 10g Release 2 (10.2) for Fujitsu Siemens BS2000/OSD E10320-01 August 2007 Oracle Database User's Guide, 10g Release 2 (10.2) for Fujitsu Siemens BS2000/OSD E10320-01 Copyright © 2007, Oracle. All rights reserved. Primary Author: Brintha Bennet Contributing Author: Janelle Simmons The Programs (which include both the software and documentation) contain proprietary information; they are provided under a license agreement containing restrictions on use and disclosure and are also protected by copyright, patent, and other intellectual and industrial property laws. Reverse engineering, disassembly, or decompilation of the Programs, except to the extent required to obtain interoperability with other independently created software or as specified by law, is prohibited. The information contained in this document is subject to change without notice. If you find any problems in the documentation, please report them to us in writing. This document is not warranted to be error-free. Except as may be expressly permitted in your license agreement for these Programs, no part of these Programs may be reproduced or transmitted in any form or by any means, electronic or mechanical, for any purpose. If the Programs are delivered to the United States Government or anyone licensing or using the Programs on behalf of the United States Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the Programs, including documentation and technical data, shall be subject to the licensing restrictions set forth in the applicable Oracle license agreement, and, to the extent applicable, the additional rights set forth in FAR 52.227-19, Commercial Computer Software--Restricted Rights (June 1987). -
BS2000/OSD-BC ≥ V4.0, OSD-SVP V4.0 and OSD/XC V1.0 with SPOOL ≥ V4.4A – Openft for BS2000 As of V7.0 Und Openft-AC for BS2000 As of V7.0
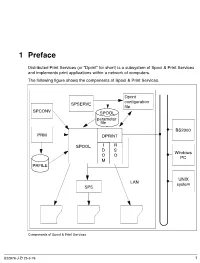
1Preface Distributed Print Services (or “Dprint” for short) is a subsystem of Spool & Print Services and implements print applications within a network of computers. The following figure shows the components of Spool & Print Services. Dprint configuration SPSERVE file SPCONV SPOOL parameter file BS2000 PRM DPRINT SPOOL I R D S Windows O O PC M PRFILE UNIX LAN system SPS Components of Spool & Print Services U22878-J-Z125-6-76 1 Brief product description Preface 1.1 Brief product description Distributed Print Services (known as “Dprint” for short) implements print applications in a network consisting of computers which use the BS20000/OSD, UNIX and Windows operating systems. Dprint utilizes TCP/IP, ISO or NEA (TRANSDATA) transport protocols. Dprint requires SPOOL as its execution unit and expands the print capabilities of SPOOL in respect of host-wide and network-wide utilization of the local BS2000 high-performance printers. Dprint supports network-wide access to BS2000 printers, printers attached to UNIX systems and Windows printers, i.e. interoperability between BS2000, Xprint and Wprint is possible. This means that data from a Windows PC can be output to a BS2000 printer. It is also possible to output data from BS2000 on a printer which is connected to a Windows PC. This then runs via a UNIX system. Dprint is designed as a client/server model and comprises the following components: – DPRINTCL (client component: print job generation) – DPRINTSV (server component: print job management) – DPRINTCM (implements management services, file transfer, communication, etc.) These components are installed as independent subsystems. DPRINTCL and DPRINTCM are combined to form the selectable unit DPRINT-CL, and DPRINTSV is supplied as the selectable unit DPRINT-SV. -

The Importance of Data
The landscape of Parallel Programing Models Part 2: The importance of Data Michael Wong and Rod Burns Codeplay Software Ltd. Distiguished Engineer, Vice President of Ecosystem IXPUG 2020 2 © 2020 Codeplay Software Ltd. Distinguished Engineer Michael Wong ● Chair of SYCL Heterogeneous Programming Language ● C++ Directions Group ● ISOCPP.org Director, VP http://isocpp.org/wiki/faq/wg21#michael-wong ● [email protected] ● [email protected] Ported ● Head of Delegation for C++ Standard for Canada Build LLVM- TensorFlow to based ● Chair of Programming Languages for Standards open compilers for Council of Canada standards accelerators Chair of WG21 SG19 Machine Learning using SYCL Chair of WG21 SG14 Games Dev/Low Latency/Financial Trading/Embedded Implement Releasing open- ● Editor: C++ SG5 Transactional Memory Technical source, open- OpenCL and Specification standards based AI SYCL for acceleration tools: ● Editor: C++ SG1 Concurrency Technical Specification SYCL-BLAS, SYCL-ML, accelerator ● MISRA C++ and AUTOSAR VisionCpp processors ● Chair of Standards Council Canada TC22/SC32 Electrical and electronic components (SOTIF) ● Chair of UL4600 Object Tracking ● http://wongmichael.com/about We build GPU compilers for semiconductor companies ● C++11 book in Chinese: Now working to make AI/ML heterogeneous acceleration safe for https://www.amazon.cn/dp/B00ETOV2OQ autonomous vehicle 3 © 2020 Codeplay Software Ltd. Acknowledgement and Disclaimer Numerous people internal and external to the original C++/Khronos group, in industry and academia, have made contributions, influenced ideas, written part of this presentations, and offered feedbacks to form part of this talk. But I claim all credit for errors, and stupid mistakes. These are mine, all mine! You can’t have them. -

AMD Accelerated Parallel Processing Opencl Programming Guide
AMD Accelerated Parallel Processing OpenCL Programming Guide November 2013 rev2.7 © 2013 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, AMD Accelerated Parallel Processing, the AMD Accelerated Parallel Processing logo, ATI, the ATI logo, Radeon, FireStream, FirePro, Catalyst, and combinations thereof are trade- marks of Advanced Micro Devices, Inc. Microsoft, Visual Studio, Windows, and Windows Vista are registered trademarks of Microsoft Corporation in the U.S. and/or other jurisdic- tions. Other names are for informational purposes only and may be trademarks of their respective owners. OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. The information contained herein may be of a preliminary or advance nature and is subject to change without notice. No license, whether express, implied, arising by estoppel or other- wise, to any intellectual property rights is granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as compo- nents in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other application in which the failure of AMD’s product could create a situation where personal injury, death, or severe property or envi- ronmental damage may occur. -

Parallel Rendering on Hybrid Multi-GPU Clusters
Eurographics Symposium on Parallel Graphics and Visualization (2012) H. Childs and T. Kuhlen (Editors) Parallel Rendering on Hybrid Multi-GPU Clusters S. Eilemann†1, A. Bilgili1, M. Abdellah1, J. Hernando2, M. Makhinya3, R. Pajarola3, F. Schürmann1 1Blue Brain Project, EPFL; 2CeSViMa, UPM; 3Visualization and MultiMedia Lab, University of Zürich Abstract Achieving efficient scalable parallel rendering for interactive visualization applications on medium-sized graphics clusters remains a challenging problem. Framerates of up to 60hz require a carefully designed and fine-tuned parallel rendering implementation that fits all required operations into the 16ms time budget available for each rendered frame. Furthermore, modern commodity hardware embraces more and more a NUMA architecture, where multiple processor sockets each have their locally attached memory and where auxiliary devices such as GPUs and network interfaces are directly attached to one of the processors. Such so called fat NUMA processing and graphics nodes are increasingly used to build cost-effective hybrid shared/distributed memory visualization clusters. In this paper we present a thorough analysis of the asynchronous parallelization of the rendering stages and we derive and implement important optimizations to achieve highly interactive framerates on such hybrid multi-GPU clusters. We use both a benchmark program and a real-world scientific application used to visualize, navigate and interact with simulations of cortical neuron circuit models. Categories and Subject Descriptors (according to ACM CCS): I.3.2 [Computer Graphics]: Graphics Systems— Distributed Graphics; I.3.m [Computer Graphics]: Miscellaneous—Parallel Rendering 1. Introduction Hybrid GPU clusters are often build from so called fat render nodes using a NUMA architecture with multiple The decomposition of parallel rendering systems across mul- CPUs and GPUs per machine. -

CUDA Particle-Based Fluid Simulation
CUDA Particle-based Fluid Simulation Simon Green Overview Fluid Simulation Techniques CUDA particle simulation Spatial subdivision techniques Rendering methods Future © NVIDIA Corporation 2008 Fluid Simulation Techniques Various approaches: Grid based (Eulerian) Stable fluids Particle level set Particle based (Lagrangian) SPH (smoothed particle hydrodynamics) MPS (Moving-Particle Semi-Implicit) Height field FFT (Tessendorf) Wave propagation – e.g. Kass and Miller © NVIDIA Corporation 2008 CUDA N-Body Demo Computes gravitational attraction between n bodies Computes all n2 interactions Uses shared memory to reduce memory bandwidth 16K bodies @ 44 FPS x 20 FLOPS / interaction x 16K2 interactions / frame = 240 GFLOP/s GeForce 8800 GTX © NVIDIA Corporation 2008 Particle-based Fluid Simulation Advantages Conservation of mass is trivial Easy to track free surface Only performs computation where necessary Not necessarily constrained to a finite grid Easy to parallelize Disadvantages Hard to extract smooth surface from particles Requires large number of particles for realistic results © NVIDIA Corporation 2008 Particle Fluid Simulation Papers Particle-Based Fluid Simulation for Interactive Applications, M. Müller, 2003 3000 particles, 5fps Particle-based Viscoelastic Fluid Simulation, Clavet et al, 2005 1000 particles, 10fps 20,000 particles, 2 secs / frame © NVIDIA Corporation 2008 CUDA SDK Particles Demo Particles with simple collisions Uses uniform grid based on sorting Uses fast CUDA radix sort Current performance: >100 fps for 65K interacting -

Job Peer Group Controller Job Peer Group Host a PG for Each Job
Korea-Japan Grid Symposium, Seoul December 1-2, 2004 P3: Personal Power Plant Makes over your PCs into power generator on the Grid Kazuyuki Shudo <[email protected]>, Yoshio Tanaka, Satoshi Sekiguchi Grid Technology Research Center, AIST, Japan P3: Personal Power Plant Middleware for distributed computation utilizing JXTA. Traditional goals Cycle scavenging Harvest compute power of existing PCs in an organization. Conventional dist. computing Internet-wide distributed computing E.g. distributed.net, SETI@home Challenging goals Aggregate PCs and expose them as an integrated Grid resource. Integrate P3 with Grid middleware ? cf. Community Scheduler Framework Dealings and circulation of computational resources Transfer individual resources (C2C, C2B) and also aggregated resources (B2B). Transfer and aggregation of Other resources than processing power. individual resources Commercial dealings need a market and a system supporting it. P2P way of interaction between PCs P3 uses JXTA for all communications JXTA is a widely accepted P2P protocol, project and library, that provides common functions P2P software requires. P2P concepts supported by JXTA efficiently support P3: Ad-hoc self-organization PCs can discover and communicate with each other without pre-configuration. Discovery PCs dynamically discover each other and jobs without a central server. Peer Group PCs are grouped into job groups, in which PCs carry out code distribution, job control, and collective communication for parallel computation. Overlay Network Peer ID in JXTA is independent from physical IDs like IP addresses and MAC addresses. JXTA enables end-to-end bidirectional communication over NA(P)T and firewall (even if the FW allows only unidirectional HTTP). This function supports parallel processing in the message-passing model, not only master-worker model. -

Web Services and PC Grid
Web Services and PC Grid ONG Guan Sin <[email protected]> Grid Evangelist Singapore Computer Systems Ltd APBioNet/APAN 18 Jul 2006 Tera-scale Campus Grid @ NUS LATEST: CIO Award 2006 winner Harnessing existing computation capacity campus-wide, creating large-scale supercomputing capability Computers are aggregated through its gigabit network into a virtual supercomputing platform using United Devices Grid MP middleware Community grid by voluntary participation from depts Two-year collaboration project between NUS and SCS to develop applications and support community Number of Nodes Theoretical# Practical^ 1,042 (Sep 20, 2005) 4.5 TFlops 2.5 TFlops 3,000 (Planned - 2007) 13 TFlops 7.2 TFlops * Accumulated average CPU speed of 2.456GHz as at Sep 20, 2005 # Assuming 90% capacity effectively harnessed ^ Assuming 50% capacity effectively harnessed Copyright 2006 Singapore Computer Systems Limited 2 UD Grid MP Architecture Managed Grid Services Interface (MGSI) ± Web Services API 3 Command-line Interface Application Service 4 Simple Web Interface 5 Application Service Overview Application Service . Is a job submission and result retrieval program which provides users with a simple interface for performing work on the Grid . It is responsible for Splitting and Merging Application Data Features . Control the Grid MP Sever with SOAP or XML-RPC communications . SOAP and XML-RPC Communications are protected with SSL encryption . SOAP and XML-RPC are language and platform independent with many publicly available toolkits and libraries. User interface can be command-line, web-based, GUI, etc. Can be written to run on various operating systems MP Grid Services Interface (MGSI) . All Objects in the Grid MP platform can be controlled through the MGSI . -

Computer Hardware
Computer Hardware MJ Rutter mjr19@cam Michaelmas 2014 Typeset by FoilTEX c 2014 MJ Rutter Contents History 4 The CPU 10 instructions ....................................... ............................................. 17 pipelines .......................................... ........................................... 18 vectorcomputers.................................... .............................................. 36 performancemeasures . ............................................... 38 Memory 42 DRAM .................................................. .................................... 43 caches............................................. .......................................... 54 Memory Access Patterns in Practice 82 matrixmultiplication. ................................................. 82 matrixtransposition . ................................................107 Memory Management 118 virtualaddressing .................................. ...............................................119 pagingtodisk ....................................... ............................................128 memorysegments ..................................... ............................................137 Compilers & Optimisation 158 optimisation....................................... .............................................159 thepitfallsofF90 ................................... ..............................................183 I/O, Libraries, Disks & Fileservers 196 librariesandkernels . ................................................197 -

Parallel Computer Architecture
Parallel Computer Architecture Introduction to Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 2 – Parallel Architecture Outline q Parallel architecture types q Instruction-level parallelism q Vector processing q SIMD q Shared memory ❍ Memory organization: UMA, NUMA ❍ Coherency: CC-UMA, CC-NUMA q Interconnection networks q Distributed memory q Clusters q Clusters of SMPs q Heterogeneous clusters of SMPs Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 2 Parallel Architecture Types • Uniprocessor • Shared Memory – Scalar processor Multiprocessor (SMP) processor – Shared memory address space – Bus-based memory system memory processor … processor – Vector processor bus processor vector memory memory – Interconnection network – Single Instruction Multiple processor … processor Data (SIMD) network processor … … memory memory Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 3 Parallel Architecture Types (2) • Distributed Memory • Cluster of SMPs Multiprocessor – Shared memory addressing – Message passing within SMP node between nodes – Message passing between SMP memory memory nodes … M M processor processor … … P … P P P interconnec2on network network interface interconnec2on network processor processor … P … P P … P memory memory … M M – Massively Parallel Processor (MPP) – Can also be regarded as MPP if • Many, many processors processor number is large Introduction to Parallel Computing, University of Oregon, -

Parallel Texture-Based Vector Field Visualization on Curved Surfaces Using GPU Cluster Computers
Eurographics Symposium on Parallel Graphics and Visualization (2006) Alan Heirich, Bruno Raffin, and Luis Paulo dos Santos (Editors) Parallel Texture-Based Vector Field Visualization on Curved Surfaces Using GPU Cluster Computers S. Bachthaler1, M. Strengert1, D. Weiskopf2, and T. Ertl1 1Institute of Visualization and Interactive Systems, University of Stuttgart, Germany 2School of Computing Science, Simon Fraser University, Canada Abstract We adopt a technique for texture-based visualization of flow fields on curved surfaces for parallel computation on a GPU cluster. The underlying LIC method relies on image-space calculations and allows the user to visualize a full 3D vector field on arbitrary and changing hypersurfaces. By using parallelization, both the visualization speed and the maximum data set size are scaled with the number of cluster nodes. A sort-first strategy with image-space decomposition is employed to distribute the workload for the LIC computation, while a sort-last approach with an object-space partitioning of the vector field is used to increase the total amount of available GPU memory. We specifically address issues for parallel GPU-based vector field visualization, such as reduced locality of memory accesses caused by particle tracing, dynamic load balancing for changing camera parameters, and the combination of image-space and object-space decomposition in a hybrid approach. Performance measurements document the behavior of our implementation on a GPU cluster with AMD Opteron CPUs, NVIDIA GeForce 6800 Ultra GPUs, and Infiniband network connection. Categories and Subject Descriptors (according to ACM CCS): I.3.3 [Computer Graphics]: Viewing algorithms I.3.3 [Three-Dimensional Graphics and Realism]: Color, shading, shadowing, and texture 1. -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References .............................................