Data Mining Algorithms
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Moving Average Filters
CHAPTER 15 Moving Average Filters The moving average is the most common filter in DSP, mainly because it is the easiest digital filter to understand and use. In spite of its simplicity, the moving average filter is optimal for a common task: reducing random noise while retaining a sharp step response. This makes it the premier filter for time domain encoded signals. However, the moving average is the worst filter for frequency domain encoded signals, with little ability to separate one band of frequencies from another. Relatives of the moving average filter include the Gaussian, Blackman, and multiple- pass moving average. These have slightly better performance in the frequency domain, at the expense of increased computation time. Implementation by Convolution As the name implies, the moving average filter operates by averaging a number of points from the input signal to produce each point in the output signal. In equation form, this is written: EQUATION 15-1 Equation of the moving average filter. In M &1 this equation, x[ ] is the input signal, y[ ] is ' 1 % y[i] j x [i j ] the output signal, and M is the number of M j'0 points used in the moving average. This equation only uses points on one side of the output sample being calculated. Where x[ ] is the input signal, y[ ] is the output signal, and M is the number of points in the average. For example, in a 5 point moving average filter, point 80 in the output signal is given by: x [80] % x [81] % x [82] % x [83] % x [84] y [80] ' 5 277 278 The Scientist and Engineer's Guide to Digital Signal Processing As an alternative, the group of points from the input signal can be chosen symmetrically around the output point: x[78] % x[79] % x[80] % x[81] % x[82] y[80] ' 5 This corresponds to changing the summation in Eq. -

On the Use of Discrete Fourier Transform for Solving Biperiodic Boundary Value Problem of Biharmonic Equation in the Unit Rectangle
On the Use of Discrete Fourier Transform for Solving Biperiodic Boundary Value Problem of Biharmonic Equation in the Unit Rectangle Agah D. Garnadi 31 December 2017 Department of Mathematics, Faculty of Mathematics and Natural Sciences, Bogor Agricultural University Jl. Meranti, Kampus IPB Darmaga, Bogor, 16680 Indonesia Abstract This note is addressed to solving biperiodic boundary value prob- lem of biharmonic equation in the unit rectangle. First, we describe the necessary tools, which is discrete Fourier transform for one di- mensional periodic sequence, and then extended the results to 2- dimensional biperiodic sequence. Next, we use the discrete Fourier transform 2-dimensional biperiodic sequence to solve discretization of the biperiodic boundary value problem of Biharmonic Equation. MSC: 15A09; 35K35; 41A15; 41A29; 94A12. Key words: Biharmonic equation, biperiodic boundary value problem, discrete Fourier transform, Partial differential equations, Interpola- tion. 1 Introduction This note is an extension of a work by Henrici [2] on fast solver for Poisson equation to biperiodic boundary value problem of biharmonic equation. This 1 note is organized as follows, in the first part we address the tools needed to solve the problem, i.e. introducing discrete Fourier transform (DFT) follows Henrici's work [2]. The second part, we apply the tools already described in the first part to solve discretization of biperiodic boundary value problem of biharmonic equation in the unit rectangle. The need to solve discretization of biharmonic equation is motivated by its occurence in some applications such as elasticity and fluid flows [1, 4], and recently in image inpainting [3]. Note that the work of Henrici [2] on fast solver for biperiodic Poisson equation can be seen as solving harmonic inpainting. -

Spatial Domain Low-Pass Filters
Low Pass Filtering Why use Low Pass filtering? • Remove random noise • Remove periodic noise • Reveal a background pattern 1 Effects on images • Remove banding effects on images • Smooth out Img-Img mis-registration • Blurring of image Types of Low Pass Filters • Moving average filter • Median filter • Adaptive filter 2 Moving Ave Filter Example • A single (very short) scan line of an image • {1,8,3,7,8} • Moving Ave using interval of 3 (must be odd) • First number (1+8+3)/3 =4 • Second number (8+3+7)/3=6 • Third number (3+7+8)/3=6 • First and last value set to 0 Two Dimensional Moving Ave 3 Moving Average of Scan Line 2D Moving Average Filter • Spatial domain filter • Places average in center • Edges are set to 0 usually to maintain size 4 Spatial Domain Filter Moving Average Filter Effects • Reduces overall variability of image • Lowers contrast • Noise components reduced • Blurs the overall appearance of image 5 Moving Average images Median Filter The median utilizes the median instead of the mean. The median is the middle positional value. 6 Median Example • Another very short scan line • Data set {2,8,4,6,27} interval of 5 • Ranked {2,4,6,8,27} • Median is 6, central value 4 -> 6 Median Filter • Usually better for filtering • - Less sensitive to errors or extremes • - Median is always a value of the set • - Preserves edges • - But requires more computation 7 Moving Ave vs. Median Filtering Adaptive Filters • Based on mean and variance • Good at Speckle suppression • Sigma filter best known • - Computes mean and std dev for window • - Values outside of +-2 std dev excluded • - If too few values, (<k) uses value to left • - Later versions use weighting 8 Adaptive Filters • Improvements to Sigma filtering - Chi-square testing - Weighting - Local order histogram statistics - Edge preserving smoothing Adaptive Filters 9 Final PowerPoint Numerical Slide Value (The End) 10. -
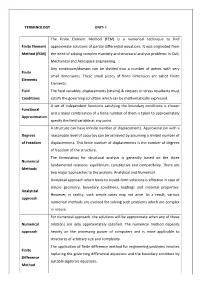
TERMINOLOGY UNIT- I Finite Element Method (FEM)
TERMINOLOGY UNIT- I The Finite Element Method (FEM) is a numerical technique to find Finite Element approximate solutions of partial differential equations. It was originated from Method (FEM) the need of solving complex elasticity and structural analysis problems in Civil, Mechanical and Aerospace engineering. Any continuum/domain can be divided into a number of pieces with very Finite small dimensions. These small pieces of finite dimension are called Finite Elements Elements. Field The field variables, displacements (strains) & stresses or stress resultants must Conditions satisfy the governing condition which can be mathematically expressed. A set of independent functions satisfying the boundary conditions is chosen Functional and a linear combination of a finite number of them is taken to approximately Approximation specify the field variable at any point. A structure can have infinite number of displacements. Approximation with a Degrees reasonable level of accuracy can be achieved by assuming a limited number of of Freedom displacements. This finite number of displacements is the number of degrees of freedom of the structure. The formulation for structural analysis is generally based on the three Numerical fundamental relations: equilibrium, constitutive and compatibility. There are Methods two major approaches to the analysis: Analytical and Numerical. Analytical approach which leads to closed-form solutions is effective in case of simple geometry, boundary conditions, loadings and material properties. Analytical However, in reality, such simple cases may not arise. As a result, various approach numerical methods are evolved for solving such problems which are complex in nature. For numerical approach, the solutions will be approximate when any of these Numerical relations are only approximately satisfied. -

Lecture 7: the Complex Fourier Transform and the Discrete Fourier Transform (DFT)
Lecture 7: The Complex Fourier Transform and the Discrete Fourier Transform (DFT) c Christopher S. Bretherton Winter 2014 7.1 Fourier analysis and filtering Many data analysis problems involve characterizing data sampled on a regular grid of points, e. g. a time series sampled at some rate, a 2D image made of regularly spaced pixels, or a 3D velocity field from a numerical simulation of fluid turbulence on a regular grid. Often, such problems involve characterizing, detecting, separating or ma- nipulating variability on different scales, e. g. finding a weak systematic signal amidst noise in a time series, edge sharpening in an image, or quantifying the energy of motion across the different sizes of turbulent eddies. Fourier analysis using the Discrete Fourier Transform (DFT) is a fun- damental tool for such problems. It transforms the gridded data into a linear combination of oscillations of different wavelengths. This partitions it into scales which can be separately analyzed and manipulated. The computational utility of Fourier methods rests on the Fast Fourier Transform (FFT) algorithm, developed in the 1960s by Cooley and Tukey, which allows efficient calculation of discrete Fourier coefficients of a periodic function sampled on a regular grid of 2p points (or 2p3q5r with slightly reduced efficiency). 7.2 Example of the FFT Using Matlab, take the FFT of the HW1 wave height time series (length 24 × 60=25325) and plot the result (Fig. 1): load hw1 dat; zhat = fft(z); plot(abs(zhat),’x’) A few elements (the second and last, and to a lesser extent the third and the second from last) have magnitudes that stand above the noise. -

Discretization of Integro-Differential Equations
Discretization of Integro-Differential Equations Modeling Dynamic Fractional Order Viscoelasticity K. Adolfsson1, M. Enelund1,S.Larsson2,andM.Racheva3 1 Dept. of Appl. Mech., Chalmers Univ. of Technology, SE–412 96 G¨oteborg, Sweden 2 Dept. of Mathematics, Chalmers Univ. of Technology, SE–412 96 G¨oteborg, Sweden 3 Dept. of Mathematics, Technical University of Gabrovo, 5300 Gabrovo, Bulgaria Abstract. We study a dynamic model for viscoelastic materials based on a constitutive equation of fractional order. This results in an integro- differential equation with a weakly singular convolution kernel. We dis- cretize in the spatial variable by a standard Galerkin finite element method. We prove stability and regularity estimates which show how the convolution term introduces dissipation into the equation of motion. These are then used to prove a priori error estimates. A numerical ex- periment is included. 1 Introduction Fractional order operators (integrals and derivatives) have proved to be very suit- able for modeling memory effects of various materials and systems of technical interest. In particular, they are very useful when modeling viscoelastic materials, see, e.g., [3]. Numerical methods for quasistatic viscoelasticity problems have been studied, e.g., in [2] and [8]. The drawback of the fractional order viscoelastic models is that the whole strain history must be saved and included in each time step. The most commonly used algorithms for this integration are based on the Lubich convolution quadrature [5] for fractional order operators. In [1, 2], we develop an efficient numerical algorithm based on sparse numerical quadrature earlier studied in [6]. While our earlier work focused on discretization in time for the quasistatic case, we now study space discretization for the fully dynamic equations of mo- tion, which take the form of an integro-differential equation with a weakly singu- lar convolution kernel. -

Review of Smoothing Methods for Enhancement of Noisy Data from Heavy-Duty LHD Mining Machines
E3S Web of Conferences 29, 00011 (2018) https://doi.org/10.1051/e3sconf/20182900011 XVIIth Conference of PhD Students and Young Scientists Review of smoothing methods for enhancement of noisy data from heavy-duty LHD mining machines Jacek Wodecki1, Anna Michalak2, and Paweł Stefaniak2 1Machinery Systems Division, Wroclaw University of Science and Technology, Wroclaw, Poland 2KGHM Cuprum R&D Ltd., Wroclaw, Poland Abstract. Appropriate analysis of data measured on heavy-duty mining machines is essential for processes monitoring, management and optimization. Some particular classes of machines, for example LHD (load-haul-dump) machines, hauling trucks, drilling/bolting machines etc. are characterized with cyclicity of operations. In those cases, identification of cycles and their segments or in other words – simply data segmen- tation is a key to evaluate their performance, which may be very useful from the man- agement point of view, for example leading to introducing optimization to the process. However, in many cases such raw signals are contaminated with various artifacts, and in general are expected to be very noisy, which makes the segmentation task very difficult or even impossible. To deal with that problem, there is a need for efficient smoothing meth- ods that will allow to retain informative trends in the signals while disregarding noises and other undesired non-deterministic components. In this paper authors present a review of various approaches to diagnostic data smoothing. Described methods can be used in a fast and efficient way, effectively cleaning the signals while preserving informative de- terministic behaviour, that is a crucial to precise segmentation and other approaches to industrial data analysis. -

There Is Only One Fourier Transform Jens V
Preprints (www.preprints.org) | NOT PEER-REVIEWED | Posted: 25 December 2017 doi:10.20944/preprints201712.0173.v1 There is only one Fourier Transform Jens V. Fischer * Microwaves and Radar Institute, German Aerospace Center (DLR), Germany Abstract Four Fourier transforms are usually defined, the Integral Fourier transform, the Discrete-Time Fourier transform (DTFT), the Discrete Fourier transform (DFT) and the Integral Fourier transform for periodic functions. However, starting from their definitions, we show that all four Fourier transforms can be reduced to actually only one Fourier transform, the Fourier transform in the distributional sense. Keywords Integral Fourier Transform, Discrete-Time Fourier Transform (DTFT), Discrete Fourier Transform (DFT), Integral Fourier Transform for periodic functions, Fourier series, Poisson Summation Formula, periodization trick, interpolation trick Introduction Two Important Operations The fact that “there is only one Fourier transform” actually There are two operations which are being strongly related to needs no proof. It is commonly known and often discussed in four different variants of the Fourier transform, i.e., the literature, for example in [1-2]. discretization and periodization. For any real-valued T > 0 and δ(t) being the Dirac impulse, let However frequently asked questions are: (1) What is the difference between calculating the Fourier series and the (1) Fourier transform of a continuous function? (2) What is the difference between Discrete-Time Fourier Transform (DTFT) be the function that results from a discretization of f(t) and let and Discrete Fourier Transform (DFT)? (3) When do we need which Fourier transform? and many others. The default answer (2) today to all these questions is to invite the reader to have a look at the so-called Fourier-Poisson cube, e.g. -

Verification and Validation in Computational Fluid Dynamics1
SAND2002 - 0529 Unlimited Release Printed March 2002 Verification and Validation in Computational Fluid Dynamics1 William L. Oberkampf Validation and Uncertainty Estimation Department Timothy G. Trucano Optimization and Uncertainty Estimation Department Sandia National Laboratories P. O. Box 5800 Albuquerque, New Mexico 87185 Abstract Verification and validation (V&V) are the primary means to assess accuracy and reliability in computational simulations. This paper presents an extensive review of the literature in V&V in computational fluid dynamics (CFD), discusses methods and procedures for assessing V&V, and develops a number of extensions to existing ideas. The review of the development of V&V terminology and methodology points out the contributions from members of the operations research, statistics, and CFD communities. Fundamental issues in V&V are addressed, such as code verification versus solution verification, model validation versus solution validation, the distinction between error and uncertainty, conceptual sources of error and uncertainty, and the relationship between validation and prediction. The fundamental strategy of verification is the identification and quantification of errors in the computational model and its solution. In verification activities, the accuracy of a computational solution is primarily measured relative to two types of highly accurate solutions: analytical solutions and highly accurate numerical solutions. Methods for determining the accuracy of numerical solutions are presented and the importance of software testing during verification activities is emphasized. The fundamental strategy of 1Accepted for publication in the review journal Progress in Aerospace Sciences. 3 validation is to assess how accurately the computational results compare with the experimental data, with quantified error and uncertainty estimates for both. -

Image Smoothening and Sharpening Using Frequency Domain Filtering Technique
International Journal of Emerging Technologies in Engineering Research (IJETER) Volume 5, Issue 4, April (2017) www.ijeter.everscience.org Image Smoothening and Sharpening using Frequency Domain Filtering Technique Swati Dewangan M.Tech. Scholar, Computer Networks, Bhilai Institute of Technology, Durg, India. Anup Kumar Sharma M.Tech. Scholar, Computer Networks, Bhilai Institute of Technology, Durg, India. Abstract – Images are used in various fields to help monitoring The content of this paper is organized as follows: Section I processes such as images in fingerprint evaluation, satellite gives introduction to the topic and projects fundamental monitoring, medical diagnostics, underwater areas, etc. Image background. Section II describes the types of image processing techniques is adopted as an optimized method to help enhancement techniques. Section III defines the operations the processing tasks efficiently. The development of image applied for image filtering. Section IV shows results and processing software helps the image editing process effectively. Image enhancement algorithms offer a wide variety of approaches discussions. Section V concludes the proposed approach and for modifying original captured images to achieve visually its outcome. acceptable images. In this paper, we apply frequency domain 1.1 Digital Image Processing filters to generate an enhanced image. Simulation outputs results in noise reduction, contrast enhancement, smoothening and Digital image processing is a part of signal processing which sharpening of the enhanced image. uses computer algorithms to perform image processing on Index Terms – Digital Image Processing, Fourier Transforms, digital images. It has numerous applications in different studies High-pass Filters, Low-pass Filters, Image Enhancement. and researches of science and technology. The fundamental steps in Digital Image processing are image acquisition, image 1. -

High Order Regularization of Dirac-Delta Sources in Two Space Dimensions
INTERNSHIP REPORT High order regularization of Dirac-delta sources in two space dimensions. Author: Supervisors: Wouter DE VRIES Prof. Guustaaf JACOBS s1010239 Jean-Piero SUAREZ HOST INSTITUTION: San Diego State University, San Diego (CA), USA Department of Aerospace Engineering and Engineering Mechanics Computational Fluid Dynamics laboratory Prof. G.B. JACOBS HOME INSTITUTION University of Twente, Enschede, Netherlands Faculty of Engineering Technology Group of Engineering Fluid Dynamics Prof. H.W.M. HOEIJMAKERS March 4, 2015 Abstract In this report the regularization of singular sources appearing in hyperbolic conservation laws is studied. Dirac-delta sources represent small particles which appear as source-terms in for example Particle-laden flow. The Dirac-delta sources are regularized with a high order accurate polynomial based regularization technique. Instead of regularizing a single isolated particle, the aim is to employ the regularization technique for a cloud of particles distributed on a non- uniform grid. By assuming that the resulting force exerted by a cloud of particles can be represented by a continuous function, the influence of the source term can be approximated by the convolution of the continuous function and the regularized Dirac-delta function. It is shown that in one dimension the distribution of the singular sources, represented by the convolution of the contin- uous function and Dirac-delta function, can be approximated with high accuracy using the regularization technique. The method is extended to two dimensions and high order approximations of the source-term are obtained as well. The resulting approximation of the singular sources are interpolated using a polynomial interpolation in order to regain a continuous distribution representing the force exerted by the cloud of particles. -

On Convergence of the Immersed Boundary Method for Elliptic Interface Problems
On convergence of the immersed boundary method for elliptic interface problems Zhilin Li∗ January 26, 2012 Abstract Peskin's Immersed Boundary (IB) method is one of the most popular numerical methods for many years and has been applied to problems in mathematical biology, fluid mechanics, material sciences, and many other areas. Peskin's IB method is associated with discrete delta functions. It is believed that the IB method is first order accurate in the L1 norm. But almost no rigorous proof could be found in the literature until recently [14] in which the author showed that the velocity is indeed first order accurate for the Stokes equations with a periodic boundary condition. In this paper, we show first order convergence with a log h factor of the IB method for elliptic interface problems essentially without the boundary condition restrictions. The results should be applicable to the IB method for many different situations involving elliptic solvers for Stokes and Navier-Stokes equations. keywords: Immersed Boundary (IB) method, Dirac delta function, convergence of IB method, discrete Green function, discrete Green's formula. AMS Subject Classification 2000 65M12, 65M20. 1 Introduction Since its invention in 1970's, the Immersed Boundary (IB) method [15] has been applied almost everywhere in mathematics, engineering, biology, fluid mechanics, and many many more areas, see for example, [16] for a review and references therein. The IB method is not only a mathematical modeling tool in which a complicated boundary condition can be treated as a source distribution but also a numerical method in which a discrete delta function is used.