Optimising the Smoothness and Accuracy of Moving Average for Stock Price Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Moving Average Filters
CHAPTER 15 Moving Average Filters The moving average is the most common filter in DSP, mainly because it is the easiest digital filter to understand and use. In spite of its simplicity, the moving average filter is optimal for a common task: reducing random noise while retaining a sharp step response. This makes it the premier filter for time domain encoded signals. However, the moving average is the worst filter for frequency domain encoded signals, with little ability to separate one band of frequencies from another. Relatives of the moving average filter include the Gaussian, Blackman, and multiple- pass moving average. These have slightly better performance in the frequency domain, at the expense of increased computation time. Implementation by Convolution As the name implies, the moving average filter operates by averaging a number of points from the input signal to produce each point in the output signal. In equation form, this is written: EQUATION 15-1 Equation of the moving average filter. In M &1 this equation, x[ ] is the input signal, y[ ] is ' 1 % y[i] j x [i j ] the output signal, and M is the number of M j'0 points used in the moving average. This equation only uses points on one side of the output sample being calculated. Where x[ ] is the input signal, y[ ] is the output signal, and M is the number of points in the average. For example, in a 5 point moving average filter, point 80 in the output signal is given by: x [80] % x [81] % x [82] % x [83] % x [84] y [80] ' 5 277 278 The Scientist and Engineer's Guide to Digital Signal Processing As an alternative, the group of points from the input signal can be chosen symmetrically around the output point: x[78] % x[79] % x[80] % x[81] % x[82] y[80] ' 5 This corresponds to changing the summation in Eq. -

Spatial Domain Low-Pass Filters
Low Pass Filtering Why use Low Pass filtering? • Remove random noise • Remove periodic noise • Reveal a background pattern 1 Effects on images • Remove banding effects on images • Smooth out Img-Img mis-registration • Blurring of image Types of Low Pass Filters • Moving average filter • Median filter • Adaptive filter 2 Moving Ave Filter Example • A single (very short) scan line of an image • {1,8,3,7,8} • Moving Ave using interval of 3 (must be odd) • First number (1+8+3)/3 =4 • Second number (8+3+7)/3=6 • Third number (3+7+8)/3=6 • First and last value set to 0 Two Dimensional Moving Ave 3 Moving Average of Scan Line 2D Moving Average Filter • Spatial domain filter • Places average in center • Edges are set to 0 usually to maintain size 4 Spatial Domain Filter Moving Average Filter Effects • Reduces overall variability of image • Lowers contrast • Noise components reduced • Blurs the overall appearance of image 5 Moving Average images Median Filter The median utilizes the median instead of the mean. The median is the middle positional value. 6 Median Example • Another very short scan line • Data set {2,8,4,6,27} interval of 5 • Ranked {2,4,6,8,27} • Median is 6, central value 4 -> 6 Median Filter • Usually better for filtering • - Less sensitive to errors or extremes • - Median is always a value of the set • - Preserves edges • - But requires more computation 7 Moving Ave vs. Median Filtering Adaptive Filters • Based on mean and variance • Good at Speckle suppression • Sigma filter best known • - Computes mean and std dev for window • - Values outside of +-2 std dev excluded • - If too few values, (<k) uses value to left • - Later versions use weighting 8 Adaptive Filters • Improvements to Sigma filtering - Chi-square testing - Weighting - Local order histogram statistics - Edge preserving smoothing Adaptive Filters 9 Final PowerPoint Numerical Slide Value (The End) 10. -

Review of Smoothing Methods for Enhancement of Noisy Data from Heavy-Duty LHD Mining Machines
E3S Web of Conferences 29, 00011 (2018) https://doi.org/10.1051/e3sconf/20182900011 XVIIth Conference of PhD Students and Young Scientists Review of smoothing methods for enhancement of noisy data from heavy-duty LHD mining machines Jacek Wodecki1, Anna Michalak2, and Paweł Stefaniak2 1Machinery Systems Division, Wroclaw University of Science and Technology, Wroclaw, Poland 2KGHM Cuprum R&D Ltd., Wroclaw, Poland Abstract. Appropriate analysis of data measured on heavy-duty mining machines is essential for processes monitoring, management and optimization. Some particular classes of machines, for example LHD (load-haul-dump) machines, hauling trucks, drilling/bolting machines etc. are characterized with cyclicity of operations. In those cases, identification of cycles and their segments or in other words – simply data segmen- tation is a key to evaluate their performance, which may be very useful from the man- agement point of view, for example leading to introducing optimization to the process. However, in many cases such raw signals are contaminated with various artifacts, and in general are expected to be very noisy, which makes the segmentation task very difficult or even impossible. To deal with that problem, there is a need for efficient smoothing meth- ods that will allow to retain informative trends in the signals while disregarding noises and other undesired non-deterministic components. In this paper authors present a review of various approaches to diagnostic data smoothing. Described methods can be used in a fast and efficient way, effectively cleaning the signals while preserving informative de- terministic behaviour, that is a crucial to precise segmentation and other approaches to industrial data analysis. -

Data Mining Algorithms
Data Management and Exploration © for the original version: Prof. Dr. Thomas Seidl Jiawei Han and Micheline Kamber http://www.cs.sfu.ca/~han/dmbook Data Mining Algorithms Lecture Course with Tutorials Wintersemester 2003/04 Chapter 4: Data Preprocessing Chapter 3: Data Preprocessing Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary WS 2003/04 Data Mining Algorithms 4 – 2 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data noisy: containing errors or outliers inconsistent: containing discrepancies in codes or names No quality data, no quality mining results! Quality decisions must be based on quality data Data warehouse needs consistent integration of quality data WS 2003/04 Data Mining Algorithms 4 – 3 Multi-Dimensional Measure of Data Quality A well-accepted multidimensional view: Accuracy (range of tolerance) Completeness (fraction of missing values) Consistency (plausibility, presence of contradictions) Timeliness (data is available in time; data is up-to-date) Believability (user’s trust in the data; reliability) Value added (data brings some benefit) Interpretability (there is some explanation for the data) Accessibility (data is actually available) Broad categories: intrinsic, contextual, representational, and accessibility. WS 2003/04 Data Mining Algorithms 4 – 4 Major Tasks in Data Preprocessing -

Image Smoothening and Sharpening Using Frequency Domain Filtering Technique
International Journal of Emerging Technologies in Engineering Research (IJETER) Volume 5, Issue 4, April (2017) www.ijeter.everscience.org Image Smoothening and Sharpening using Frequency Domain Filtering Technique Swati Dewangan M.Tech. Scholar, Computer Networks, Bhilai Institute of Technology, Durg, India. Anup Kumar Sharma M.Tech. Scholar, Computer Networks, Bhilai Institute of Technology, Durg, India. Abstract – Images are used in various fields to help monitoring The content of this paper is organized as follows: Section I processes such as images in fingerprint evaluation, satellite gives introduction to the topic and projects fundamental monitoring, medical diagnostics, underwater areas, etc. Image background. Section II describes the types of image processing techniques is adopted as an optimized method to help enhancement techniques. Section III defines the operations the processing tasks efficiently. The development of image applied for image filtering. Section IV shows results and processing software helps the image editing process effectively. Image enhancement algorithms offer a wide variety of approaches discussions. Section V concludes the proposed approach and for modifying original captured images to achieve visually its outcome. acceptable images. In this paper, we apply frequency domain 1.1 Digital Image Processing filters to generate an enhanced image. Simulation outputs results in noise reduction, contrast enhancement, smoothening and Digital image processing is a part of signal processing which sharpening of the enhanced image. uses computer algorithms to perform image processing on Index Terms – Digital Image Processing, Fourier Transforms, digital images. It has numerous applications in different studies High-pass Filters, Low-pass Filters, Image Enhancement. and researches of science and technology. The fundamental steps in Digital Image processing are image acquisition, image 1. -

Application of Data Smoothing Method in Signal Processing for Vortex Flow Meters
ITM Web of Conferences 11, 01014 (2017) DOI: 10.1051/itmconf/20171101014 IST2017 Application of Data Smoothing Method in Signal Processing for Vortex Flow Meters Jun ZHANG1, Tian ZOU2 and Chun-Lai TIAN1,a 1School of Mechanical and Electronic Engineeing, Pingxiang University, 337055 Pingxiang, Jiangxi Province, China 2School of Law, Pingxiang University, 337055 Pingxiang, Jiangxi Province, China Abstract. Vortex flow meter is typical flow measure equipment. Its measurement output signals can easily be impaired by environmental conditions. In order to obtain an improved estimate of the time-averaged velocity from the vortex flow meter, a signal filter method is applied in this paper. The method is based on a simple Savitzky-Golay smoothing filter algorithm. According with the algorithm, a numerical program is developed in Python with the scientific library numerical Numpy. Two sample data sets are processed through the program. The results demonstrate that the processed data is available accepted compared with the original data. The improved data of the time-averaged velocity is obtained within smoothing curves. Finally the simple data smoothing program is useable and stable for this filter. 1 Introduction As types of flow measurement equipments, vortex flow meters are commonly used to measure the flow velocity. According with the advanced development of the flow measurement technology, they play a major role in flow measurement business. The vortex flow meters are extensively used in industries and academic research. It is being currently applied extensively in the measurement of liquids, gases and steam [1]. The vortex flow meter is a device that works with based on the principle of shedding of vortices behind a bluff body placed in the flow. -

Applied Time-Series Analysis
Estimation of spectral densities References Applied Time-Series Analysis Arun K. Tangirala Department of Chemical Engineering, IIT Madras Estimation of spectral densities for stochastic signals Arun K. Tangirala (IIT Madras) Applied Time-Series Analysis 1 Estimation of spectral densities References Learning Goals In this lecture, we focus on the estimation of spectral densities for stochastic signals. We shall learn the following: I Blackman-Tukey and Daniell’s method I Welch’s averaged periodogram I Parametric methods Arun K. Tangirala (IIT Madras) Applied Time-Series Analysis 2 Estimation of spectral densities References Recap. The lack of consistency in periodogram estimator can be explained from three viewpoints: i. The infinitely-long ACVF is approximated by a finite-length estimated ACVF and the error in ACVF estimates increases with the lag (leads to Blackman-Tukey estimators). ii. The true p.s.d. is a smooth function of frequency, whereas the estimated one is erratically fluctuating (leads to smoothers). iii. The true p.s.d. is an average property, whereas the estimated one is from a single realization (leads to Welch’s average periodogram estimators). Arun K. Tangirala (IIT Madras) Applied Time-Series Analysis 3 Estimation of spectral densities References Recap: Methods for improvement Method Summary Reference Blackman-Tukey Fourier transformation of smoothed, truncated autoco- Chatfield, 1975 variance function Smoothed peri- Estimate periodogram by DFT of time series; Smooth Bloomfield, 2000 odogram periodogram with modified Daniell -

Concurrent Filtering and Smoothing
Concurrent Filtering and Smoothing Michael Kaess∗, Stephen Williamsy, Vadim Indelmany, Richard Robertsy, John J. Leonard∗, and Frank Dellaerty ∗Computer Science and Artificial Intelligence Laboratory, MIT, Cambridge, MA 02139, USA yCollege of Computing, Georgia Institute of Technology, Atlanta, GA 30332, USA Abstract—This paper presents a novel algorithm for integrat- ing real-time filtering of navigation data with full map/trajectory smoothing. Unlike conventional mapping strategies, the result of loop closures within the smoother serve to correct the real-time navigation solution in addition to the map. This solution views filtering and smoothing as different operations applied within a single graphical model known as a Bayes tree. By maintaining all information within a single graph, the optimal linear estimate is guaranteed, while still allowing the filter and smoother to operate asynchronously. This approach has been applied to simulated aerial vehicle sensors consisting of a high-speed IMU and stereo camera. Loop closures are extracted from the vision system in an external process and incorporated into the smoother when discovered. The performance of the proposed method is shown to approach that of full batch optimization while maintaining real-time operation. Figure 1. Smoother and filter combined in a single optimization problem and Index Terms—Navigation, smoothing, filtering, loop closing, represented as a Bayes tree. A separator is selected so as to enable parallel Bayes tree, factor graph computations. I. INTRODUCTION Simultaneous localization and mapping (SLAM) algorithms High frequency navigation solutions are essential for a in robotics perform a similar state estimation task, but addi- wide variety of applications ranging from autonomous robot tionally can include loop closure constraints at higher latency. -

Weight Smoothing for Generalized Linear Models Using a Laplace Prior
Weight Smoothing for Generalized Linear Models Using a Laplace Prior Xi Xia PhD Candidate, Department of Biostatistics School of Public Health, University of Michigan 1415 Washington Heights, Ann Arbor, MI, 48109 Michael R. Elliot Professor, Department of Biostatistics School of Public Health, University of Michigan 1415 Washington Heights, Ann Arbor, MI, 48109 Research Professor, Institute for Social Research 426 Thompson St, Ann Arbor, MI, 48106 Abstract When analyzing data sampled with unequal inclusion probabilities, correlations between the prob ability of selection and the sampled data can induce bias. Weights equal to the inverse of the probability of selection are commonly used to correct this possible bias. When weights are uncor related with the sampled data, or more specifically the descriptive or model estimators of interest, highly disproportional sample design resulting in large weights can introduce unnecessary vari ability, leading to an overall larger root mean square error (RMSE) compared to the unweighted or Winsorized methods. We describe an approach we term weight smoothing that models the interactions between the weights and the estimators of interest as random effects, reducing the overall RMSE by shrink ing interactions toward zero when such shrinkage is supported by data. This manuscript adapts a more flexible Laplace prior distribution for the hierarchical Bayesian model in order to gain more robustness against model misspecification and considers this approach in the context of a general ized linear model. Both simulation and application suggest that under linear model setting, weight smoothing models with Laplace prior yield robust results when weighting is not necessary, and could reduce the RMSE by more than 25% if strong patterns exist in the data. -

Smoothing and Analyzing 1D Signals
CS5112: Algorithms and Data Structures for Applications Lecture 14: Exponential decay; convolution Ramin Zabih Some content from: Piotr Indyk; Wikipedia/Google image search; J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org Administrivia • Q7 delayed due to Columbus day holiday • HW3 out but short, can do HW in groups of 3 from now on • Class 10/23 will be prelim review for 10/25 – Greg lectures on dynamic programming next week • Anonymous survey out, please respond! • Automatic grading apology Survey feedback Automatic grading apology • In general students should not have a grade revised downward – Main exception is regrade requests • Automatic grading means that this sometimes happened • At the end, we decided that the priority was to assign HW grades based on how correct the code was • Going forward, please treat HW grades as tentative grades – We will announce when those grades are finalized – After, they will only be changed under exceptional circumstances Today • Two streaming algorithms • Convolution Some natural histogram queries Top-k most frequent elements 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Find all elements with frequency > 0.1% What is the frequency of element 3? What is the total frequency of elements between 8 and 14? How many elements have non-zero frequency? Streaming algorithms (recap) 1. Boyer-Moore majority algorithm 2. Misra-Gries frequent items 3. Find popular recent items (box filter) 4. Find popular recent items (exponential window) 5. Flajolet-Martin number of -
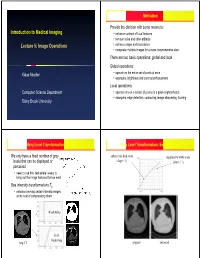
Introduction to Medical Imaging Lecture 5: Image Operations
Motivation Provide the clinician with some means to: Introduction to Medical Imaging • enhance contrast of local features • remove noise and other artifacts Lecture 5: Image Operations • enhance edges and boundaries • composite multiple images for a more comprehensive view There are two basic operations: global and local Global operations: Klaus Mueller • operate on the entire set of pixels at once • examples: brightness and contrast enhancement Local operations: Computer Science Department • operate only on a subset of pixels (in a pixel neighborhood) • examples: edge detection, contouring, image sharpening, blurring Stony Brook University Grey Level Transformation: Basics Grey Level Transformation: Enhancements We only have a fixed number of grey enhance the dark areas suppress the white areas levels that can be displayed or (slope > 1) (slope < 1) perceived • need to use this ‘real estate’ wisely to bring out the image features that we want Use intensity transformations Tp • enhance (remap) certain intensity ranges at the cost of compressing others thresholding level windowing lung CT original enhanced Grey Level Transformation: Windowing Multi-Image Operations: Noise Averaging Dedicate full contrast Assume a pixel value p is given by: p = signal + noise to either bone or lungs • E(signal) = signal • E(noise) = 0, when noise is random original lung Thus, averaging (adding) multiple images of a steady noisy CT image bi-modal object will eliminate, or at least reduce, the noise histogram bone window lung window original after averaging -
Savitzky-Golay Smoothing and Differentiation Filter Neal B
196 Hyacinth Road Manson, WA 98831 Research, Training, and Software www.Eigenvector.com Savitzky-Golay Smoothing and Differentiation Filter Neal B. Gallagher Key words: Smoothing, differentiation, end-effects Introduction: One of the most commonly used and A restriction for the filter is that w ³ (o + 1) i.e., the frequently cited filters in chemometrics is the Savitzky- number of measurements must be ³ the number of Golay smoothing and differentiation filter.[1] The parameters to be estimated. If w > (o + 1) the filter “savgol” filter is often used as a preprocessing in smooths the signal and if w = (o + 1) no smoothing is spectroscopy and signal processing. The filter can be provided. Figure 2 shows an example savgol smoothing used to reduce high frequency noise in a signal due to for a Raman spectrum (RamanDustParticles data in its smoothing properties and reduce low frequency PLS_Toolbox [2], and script savgoldemob.m for the signal (e.g., due to offsets and slopes) using examples shown in this white paper). This shows that differentiation. After a brief description of the filter, the as the filter width, w, increases the smoothing increases first example in this white paper will focus on the and the peaks appear more suppressed. At higher smoothing aspects of the filter and the second example smoothing, the peaks also acquire an artifact seen as on differentiation filtering. minima on either side of the main peak (see the subplot in Figure 2). Note that the Whittaker smoother can also The Savitzky-Golay (savgol) Filter: For a given signal be used for smoothing.[3,4] measured at N points and a filter of width, w, savgol calculates a polynomial fit of order o in each filter window as the filter is moved across the signal.