Arxiv:Q-Bio.QM/0511042 V2 25 Nov 2005 Nomto Ae Lseig Upeetr Material Supplementary Clustering: Based Information .THE I
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Insights Into Anaerobic Degradation of Benzene and Naphthalene
TECHNISCHE UNIVERSITÄT MÜNCHEN Wissenschaftszentrum Weihenstephan für Ernährung, Landnutzung und Umwelt Lehrstuhl für Siedlungswasserwirtschaft Insights into anaerobic degradation of benzene and naphthalene Xiyang Dong Vollständiger Abdruck der von der Fakultät Wissenschaftszentrum Weihenstephan für Ernährung, Landnutzung und Umwelt der Technischen Universität München zur Erlangung des akademischen Grades eines Doktors der Naturwissenschaften genehmigten Dissertation. Vorsitzende(r): Prof. Dr. Wolfgang Liebl Prüfer der Dissertation: 1. Priv.-Doz. Dr. Tillmann Lueders 2. Prof. Dr. Siegfried Scherer 3. Prof. Dr. Rainer Meckenstock Die Dissertation wurde am 03.07.2017 bei der Technischen Universität München eingereicht und durch die Fakultät Wissenschaftszentrum Weihenstephan für Ernährung, Landnutzung und Umwelt am 18.08.2017 angenommen. 天道酬勤 God rewards those who work hard Abstract Aromatic hydrocarbons, e.g. benzene and naphthalene, have toxic, mutagenic and/or carcinogenic properties. Fortunately, these compounds can be degraded in environmental systems by indigenous microorganisms. Especially under anaerobic conditions, the physiology and ecology of the microbes involved are still poorly understood. In this thesis, important knowledge gaps are addressed in this field using microbiological approaches combined with “omics tools” (metagenomics and metaproteomics). A novel “reverse stable isotope labelling” approach is also introduced to investigate biodegradation activities. Firstly, the enrichment culture BPL was studied, which can degrade benzene coupled with sulfate reduction. It is dominated by an organism of the genus Pelotomaculum. Members of this genus are usually known to be fermenters, undergoing syntrophy with anaerobic respiring microorganisms or methanogens. It remains unclear if Pelotomaculum identified here (namely, Pelotomaculum candidate BPL) could perform both benzene degradation and sulfate reduction. By using a metagenomic approach, a high-quality genome was reconstructed for it. -
The Metabolic Building Blocks of a Minimal Cell Supplementary
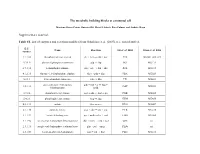
The metabolic building blocks of a minimal cell Mariana Reyes-Prieto, Rosario Gil, Mercè Llabrés, Pere Palmer and Andrés Moya Supplementary material. Table S1. List of enzymes and reactions modified from Gabaldon et. al. (2007). n.i.: non identified. E.C. Name Reaction Gil et. al. 2004 Glass et. al. 2006 number 2.7.1.69 phosphotransferase system glc + pep → g6p + pyr PTS MG041, 069, 429 5.3.1.9 glucose-6-phosphate isomerase g6p ↔ f6p PGI MG111 2.7.1.11 6-phosphofructokinase f6p + atp → fbp + adp PFK MG215 4.1.2.13 fructose-1,6-bisphosphate aldolase fbp ↔ gdp + dhp FBA MG023 5.3.1.1 triose-phosphate isomerase gdp ↔ dhp TPI MG431 glyceraldehyde-3-phosphate gdp + nad + p ↔ bpg + 1.2.1.12 GAP MG301 dehydrogenase nadh 2.7.2.3 phosphoglycerate kinase bpg + adp ↔ 3pg + atp PGK MG300 5.4.2.1 phosphoglycerate mutase 3pg ↔ 2pg GPM MG430 4.2.1.11 enolase 2pg ↔ pep ENO MG407 2.7.1.40 pyruvate kinase pep + adp → pyr + atp PYK MG216 1.1.1.27 lactate dehydrogenase pyr + nadh ↔ lac + nad LDH MG460 1.1.1.94 sn-glycerol-3-phosphate dehydrogenase dhp + nadh → g3p + nad GPS n.i. 2.3.1.15 sn-glycerol-3-phosphate acyltransferase g3p + pal → mag PLSb n.i. 2.3.1.51 1-acyl-sn-glycerol-3-phosphate mag + pal → dag PLSc MG212 acyltransferase 2.7.7.41 phosphatidate cytidyltransferase dag + ctp → cdp-dag + pp CDS MG437 cdp-dag + ser → pser + 2.7.8.8 phosphatidylserine synthase PSS n.i. cmp 4.1.1.65 phosphatidylserine decarboxylase pser → peta PSD n.i. -

Occurrence of the Regulatory Nucleotides Ppgpp and Pppgpp Following Induction of the Stringent Response in Staphylococci
JOURNAL OF BACTERIOLOGY, Sept. 1995, p. 5161–5165 Vol. 177, No. 17 0021-9193/95/$04.0010 Copyright q 1995, American Society for Microbiology Occurrence of the Regulatory Nucleotides ppGpp and pppGpp following Induction of the Stringent Response in Staphylococci R. CASSELS,* B. OLIVA,† AND D. KNOWLES Department of Microbial Metabolism and Biochemistry, SmithKline Beecham Pharmaceuticals, Brockham Park, Betchworth, Surrey RH3 7AJ, United Kingdom Received 6 February 1995/Accepted 27 June 1995 The stringent response in Escherichia coli and many other organisms is regulated by the nucleotides ppGpp and pppGpp. We show here for the first time that at least six staphylococcal species also synthesize ppGpp and pppGpp upon induction of the stringent response by mupirocin. Spots corresponding to ppGpp and pppGpp on thin-layer chromatograms suggest that pppGpp is the principal regulatory nucleotide synthesized by staphylococci in response to mupirocin, rather than ppGpp as in E. coli. Bacteria adapt to amino acid or carbon source insufficiency and higher organisms after amino acid starvation or induction by a complex series of regulatory events known as the stringent by a variety of antibiotics (7, 18, 26). However, in halobacteria response (reviewed in reference 4). In Escherichia coli, for (25) and streptococci (21), stringency is not necessarily coupled example, amino acid starvation leads to an accumulation of with (p)ppGpp production. Thus, in Streptococcus pyogenes uncharged cognate tRNA. When the ratio of charged to un- and Streptococcus rattus, chloramphenicol reverses the inhibi- charged tRNA falls below a critical threshold (24), occupation tion of RNA synthesis caused by mupirocin, but there is no of the vacant mRNA codon at the ribosomal A site by un- generation of ppGpp in the presence of mupirocin alone. -

Toward the Discovery of Biological Functions Associated with the Mechanosensor Mtl1p of Saccharomyces Cerevisiae Via Integrative
www.nature.com/scientificreports OPEN Toward the discovery of biological functions associated with the mechanosensor Mtl1p of Saccharomyces cerevisiae via integrative multi‑OMICs analysis Nelson Martínez‑Matías1, Nataliya Chorna1*, Sahily González‑Crespo1, Lilliam Villanueva1, Ingrid Montes‑Rodríguez2, Loyda M. Melendez‑Aponte1, Abiel Roche‑Lima1, Kelvin Carrasquillo‑Carrión1, Ednalise Santiago‑Cartagena1, Brian C. Rymond3, Mohan Babu4, Igor Stagljar5,6 & José R. Rodríguez‑Medina1* Functional analysis of the Mtl1 protein in Saccharomyces cerevisiae has revealed that this transmembrane sensor endows yeast cells with resistance to oxidative stress through a signaling mechanism called the cell wall integrity pathway (CWI). We observed upregulation of multiple heat shock proteins (HSPs), proteins associated with the formation of stress granules, and the phosphatase subunit of trehalose 6‑phosphate synthase which suggests that mtl1Δ strains undergo intrinsic activation of a non‑lethal heat stress response. Furthermore, quantitative global proteomic analysis conducted on TMT‑labeled proteins combined with metabolome analysis revealed that mtl1Δ strains exhibit decreased levels of metabolites of carboxylic acid metabolism, decreased expression of anabolic enzymes and increased expression of catabolic enzymes involved in the metabolism of amino acids, with enhanced expression of mitochondrial respirasome proteins. These observations support the idea that Mtl1 protein controls the suppression of a non‑lethal heat stress response under normal conditions while it plays an important role in metabolic regulatory mechanisms linked to TORC1 signaling that are required to maintain cellular homeostasis and optimal mitochondrial function. Te fungal cell wall is a physical structure that evolved to shield cells from the changing conditions of the ecological niches in which they thrive, acting as a porous barrier that isolates the delicate plasma membrane (PM) and cytoplasm from the external environment 1,2. -

(12) Patent Application Publication (10) Pub. No.: US 2009/0186358 A1 Melville Et Al
US 200901 86.358A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2009/0186358 A1 Melville et al. (43) Pub. Date: Jul. 23, 2009 (54) PATHWAYANALYSIS OF CELL CULTURE Related U.S. Application Data PHENOTYPES AND USES THEREOF (60) Provisional application No. 61/016,390, filed on Dec. 21, 2007. (75) Inventors: Mark Melville, Melrose, MA (US); Publication Classification Niall Barron, Shankill (IE): Martin Clynes, Clontarf (IE): (51) Int. C. CI2O I/68 (2006.01) Padraig Doolan, Swords (IE): CI2P 2L/00 (2006.01) Patrick Gammell, Naas (IE): C07K I4/00 (2006.01) Paula Meleady, Ratoath (IE) CI2O 1/02 (2006.01) CI2N I/2 (2006.01) Correspondence Address: CI2N 5/06 (2006.01) CHOATE, HALL & STEWART LLP CI2N 5/04 (2006.01) TWO INTERNATIONAL PLACE (52) U.S. Cl. .............. 435/6; 435/69.1:530/300; 435/29: BOSTON, MA 02110 (US) 435/252.3; 435/325; 435/419:435/254.2 (57) ABSTRACT (73) Assignees: Wyeth, Madison, NJ (US); Dublin The present invention provides methods for systematically City University, Glasnevin (IE) identifying genes, proteins and/or related pathways that regu late or indicative of cell phenotypes. The present invention further provides methods for manipulating the identified (21) Appl. No.: 12/340,629 genes, proteins and/or pathways to engineer improved cell lines and/or to evaluate or select cell lines with desirable (22) Filed: Dec. 19, 2008 phenotypes. inhibition of Signalling Signalling Caspases Apoptosis Apoptosis Signalling Caspases ATM Integrin MAPK p38 Signalling Signalling Signalling Signalling Signalling MAPK in ATM p53 Integrin Signalling Signalling Apoptosis Growth and Caspases Signalling Different. -

Transcriptomic Analysis of Field-Droughted Sorghum From
Transcriptomic analysis of field-droughted sorghum from seedling to maturity reveals biotic and metabolic responses. Supplementary Appendix Contents 1 Methods and Materials 2 2 Supplementary Figures and Tables 10 3 Cluster Summaries 26 4 All GO Terms per cluster 99 1 www.pnas.org/cgi/doi/10.1073/pnas.1907500116 1 Methods and Materials 1.1 Experimental protocols . .2 1.2 Computational methods . .4 1.2.1 Processing of Reads . .4 1.2.2 Differential expression analysis . .5 1.2.3 Clustering . .6 1.2.4 Identification of motifs and transcription factors enriched in clusters . .7 1.2.5 Gene set enrichment analysis in clusters . .7 1.2.6 Identifying shared patterns of expressions . .7 1.2.7 Longitudinal analysis of time course water potential . .8 1.1 Experimental protocols Design experiment / Field set-up The field experiments were conducted in Parlier, CA (36.6008°N, 119.5109°W). The fields consist of sandy loam soils with a silky substratum and pH 7.37. We number the weeks according to the dates that plants were sampled. Week 0 was set to be June 1 to coincide with seedling emergence (June 1-3). All plots were pre-watered before planting. Three watering conditions were subsequently used on plots: I) Control, consisting of weekly watering five days before the sampling date, with the first irrigation starting before the sampling of Week 3 (June 18) and continuing until before the sampling of Week 17 (Sept 23) II) Pre-flowering drought, consisting of a complete lack of irrigation up through and including samples from Week 8, at which time regular watering resumed prior to the sampling of Week 9 (July 29), and III) Post-flowering drought, consisting of regular irrigation up through and including irrigation prior to Week 9 sampling (July 29) { at which point over 50% of the plants had reached flowering (anthesis) { and no irrigation after that date (Figure 1a). -

Functional Studies of Escherichia Coli Stringent Response Factor Rela
Functional Studies of Escherichia coli Stringent Response Factor RelA Ievgen Dzhygyr Department of Molecular Biology, MIMS Umeå 2018 This work is protected by the Swedish Copyright Legislation (Act 1960:729) Dissertation for PhD Copyright © Ievgen Dzhygyr ISBN: 978-91-7601-934-4 ISSN: 0346-6612; New series No: 1970 Front cover design: Ievgen Dzhygyr Electronic version available at: http://umu.diva-portal.org/ Printed by: UmU Print Service, Umeå University Umeå, Sweden 2018 To my parents/Моїм батькам Table of Contents Abstract ........................................................................................... ii Abbreviations ................................................................................. iv Papers included in this thesis .......................................................... vi Introduction .................................................................................... 1 Background ....................................................................................................................... 1 Synthesis of (p)ppGpp ..................................................................................................... 2 Effects of (p)ppGpp on DNA replication ........................................................................ 4 (p)ppGpp mediated regulation of transcription .............................................................. 5 Effects of (p)ppGpp on GTPases ...................................................................................... 7 Effects of (p)ppGpp on Bacillus subtilis -

Biochemistry of Vitamins
MINISTRY OF HEALTH OF UKRAINE ZAPORIZHZHYA STATE MEDICAL UNIVERSITY Biological Chemistry Department BIOCHEMISTRY OF VITAMINS Textbook for students of international faculty Speciality: 7.120 10001 «General Medicine» Zaporizhzhya - 2016 1 Reviewers: Kaplaushenko A.G. Head of Physical and Colloidal Chemistry Department, doctor of pharmaceutical science, associate professor Voskoboynik O. Yu. Assoc. professor of Organic and Bioorganic Chemistry Department, Ph. D. Authors: Aleksandrova K.V. Rudko N.P. Aleksandrova K.V. Biochemistry of vitamins. Textbook for students of international faculty speciality: 7.120 10001 «General Medicine» / K.V. Aleksandrova, N.P. Rudko. – Zaporizhzhya : ZSMU, 2016.- 73 p. This textbook is recommended to use for students of international faculty (the second year of study) for independent work at home and in class. It is created as additional manual for study of Biochemistry for students of international faculty. Александрова К.В. Біохімія вітамінів. Начально-методичний посібник для студентів міжнародного факультету спеціальності 7.120 10001 «Лікувальна справа»/ К.В. Александрова, Н.П. Рудько,.- Запоріжжя : ЗДМУ, 2016. – 73 с. ©Aleksandrova K.V., Krisanova N.V., Ivanchenko D.G., Rudko N.P., , 2016 ©Zaporizhzhya State Medical University, 2016 2 INTRODUCTION Sometimes it is difficult for students to find out the main important notions for study of biochemistry in basic literature that is recommended. The educational process for students of medical department requires the use not only the basic literature but also that one which is discussed as additional literature sources. This is because each day we have new scientific researches in biochemistry, later which can improve our understanding of theoretical questions this subject. This manual is proposed by authors as additional one for study of water-soluble and fat-soluble vitamins: their structure, properties, functions and metabolism in human organism. -
Elevated Temperatures Cause Loss of Seed Set in Common Bean
Soltani et al. BMC Genomics (2019) 20:312 https://doi.org/10.1186/s12864-019-5669-2 RESEARCH ARTICLE Open Access Elevated temperatures cause loss of seed set in common bean (Phaseolus vulgaris L.) potentially through the disruption of source-sink relationships Ali Soltani1,2* , Sarathi M. Weraduwage3, Thomas D. Sharkey2,3,4 and David B. Lowry1,2 Abstract Background: Climate change models predict more frequent incidents of heat stress worldwide. This trend will contribute to food insecurity, particularly for some of the most vulnerable regions, by limiting the productivity of crops. Despite its great importance, there is a limited understanding of the underlying mechanisms of variation in heat tolerance within plant species. Common bean, Phaseolus vulgaris, is relatively susceptible to heat stress, which is of concern given its critical role in global food security. Here, we evaluated three genotypes of P. vulgaris belonging to kidney market class under heat and control conditions. The Sacramento and NY-105 genotypes were previously reported to be heat tolerant, while Redhawk is heat susceptible. Results: We quantified several morpho-physiological traits for leaves and found that photosynthetic rate, stomatal conductance, and leaf area all increased under elevated temperatures. Leaf area expansion under heat stress was greatest for the most susceptible genotype, Redhawk. To understand gene regulatory responses among the genotypes, total RNA was extracted from the fourth trifoliate leaves for RNA-sequencing. Several genes involved in the protection of PSII (HSP21, ABA4, and LHCB4.3) exhibited increased expression under heat stress, indicating the importance of photoprotection of PSII. Furthermore, expression of the gene SUT2 was reduced in heat. -

Expressed Sequence Tags: Characterization, Tissue-Specific Expression and Gene Markers
Marine Genomics 3 (2010) 179–191 Contents lists available at ScienceDirect Marine Genomics journal homepage: www.elsevier.com/locate/margen Gilthead sea bream (Sparus auratus) and European sea bass (Dicentrarchus labrax) expressed sequence tags: Characterization, tissue-specific expression and gene markers Bruno Louro a,j, Ana Lúcia S. Passos a, Erika L. Souche b,1, Costas Tsigenopoulos c, Alfred Beck d, Jacques Lagnel c, François Bonhomme e, Leonor Cancela a, Joan Cerdà f, Melody S. Clark g, Esther Lubzens h, Antonis Magoulas c, Josep V. Planas i, Filip A.M. Volckaert b, Richard Reinhardt d, Adelino V.M. Canario a,⁎ a Centre of Marine Sciences, University of Algarve, Building 7, Gambelas, 8000-139 Faro, Portugal b Laboratory of Animal Diversity and Systematics, Katholieke Universiteit Leuven, Charles Deberiotstraat 32, B-3000 Leuven, Belgium c Hellenic Centre for Marine Research, Institute of Marine Biology and Genetics, Thalassocosmos, Ex-US base at Gournes, P.O. Box 2214, Gournes Pediados, 715 00 Heraklion, Crete, Greece d MPI Molecular Genetics, Ihnestrasse 63-73, D-14195 Berlin-Dahlem, Germany e Département Biologie Intégrative, Institut des Sciences de l'Evolution, UMR 5554 Université de Montpellier 2, cc 63 — Pl. E Bataillon, F34095 Montpellier Cedex 5, France f Laboratory of Institut de Recerca i Tecnologia Agroalimentaries (IRTA)-Institut de Ciencies del Mar (Consejo Superior de Investigaciones Científicas, CSIC), Passeig Marítim 37-49, 08003-Barcelona, Spain g British Antarctic Survey, Natural Environment Research Council, High Cross, Madingley Road, Cambridge CB3 0ET, UK h National Institute of Oceanography, Israel Oceanographic & Limnological Research, P.O. Box 8030, Haifa 31080, Israel i Departament de Fisiologia, Facultat de Biologia, Universitat de Barcelona, Av. -

Ribosome•Rela Structures Reveal the Mechanism of Stringent Response
Ribosome•RelA structures reveal the mechanism of stringent response activation Anna B. Loveland 1,2, Eugene Bah 1,4, Rohini Madireddy 1,Ying Zhang 1, 2,5 2,3,6 1,6 Axel F. Brilot , Nikolaus Grigorieff *, Andrei A. Korostelev * 1 RNA Therapeutics Institute, Department of Biochemistry and Molecular Pharmacology, University of Massachusetts Medical School, 368 Plantation St., Worcester, MA 01605, USA. 2 Department of Biochemistry, Rosenstiel Basic Medical Sciences Research Center, Brandeis University, Waltham, MA 02454, USA 3 Janelia Research Campus, Howard Hughes Medical Institute, 19700 Helix Drive, Ashburn, VA 20147, USA 4 Present address: Mayo Medical School, 200 First St. SW, Rochester, MN 55905, USA 5 Present address: Department of Biochemistry and Biophysics, School of Medicine, University of California, San Francisco, 600 16th Street, San Francisco CA 94158, USA 6 Co-senior author * Correspondence: [email protected] (N.G.), [email protected] (A.A.K.) 1 Summary Stringent response is a conserved bacterial stress response underlying virulence and antibiotic resistance. RelA/SpoT-homolog proteins synthesize transcriptional modulators (p)ppGpp, allowing bacteria to adapt to stresses. RelA is activated during amino-acid starvation, when cognate deacyl-tRNA binds to the ribosomal A (aminoacyl- tRNA) site. We report four cryo-EM structures of E. coli RelA bound to the 70S ribosome, in the absence and presence of deacyl-tRNA accommodating in the 30S A site. The boomerang-shaped RelA with a wingspan of more than 100 Å wraps around the A/R (30S A-site/RelA-bound) tRNA. The CCA end of the A/R tRNA pins the central TGS domain against the 30S subunit, presenting the (p)ppGpp-synthetase domain near the 30S spur. -

Beriberi in the ICU: Remarkable Shock Reversal with Thiamine
Netherlands Journal of Critical Care Submitted August 2018; Accepted December 2018 CASE REPORT Beriberi in the ICU: remarkable shock reversal with thiamine R.M. van Stigt1, G. van der Wal1, S. Kamphuis2, A. Braber1 1Department of Intensive Care Medicine, Gelre Hospital, Apeldoorn, the Netherlands 2Department of Clinical Chemistry, Gelre Hospital, Apeldoorn, the Netherlands Correspondence R.M. van Stigt - [email protected] Keywords - thiamine deficiency, shock, beriberi Abstract Table 1. Patient categories at risk for thiamine deficiency Wet and dry beriberi are two clinical manifestations of thiamine Causes of thiamine deficiency deficiency, and beriberi with fulminant cardiovascular collapse Malnourishment Alcohol abuse Other substance (e.g. opioid) abuse is called Shoshin beriberi. It can present as shock with high Excessive emesis levels of lactate and a need for high doses of vasopressor therapy, Eating disorders Institutionalisation (e.g. prison) in which thiamine infusion can effectuate rapid cardiovascular High-carbohydrate, low-nutrition diet and respiratory recovery. This is not often considered in the Increased loss Diuretic therapy differential diagnosis of profound shock but thiamine deficiency Renal failure treated with dialysis is more prevalent than oftentimes thought, and therefore we Decreased uptake Post gastro-enteric surgery present two cases of Shoshin beriberi in our intensive care Increased demand Pregnancy Lactation unit with thiamine-mediated shock reversal. Both patients Hyperthyroidism were malnourished, had demonstrably low thiamine levels, and Systemic infections/sepsis Critical illness showed marked recovery upon infusion of thiamine. Institutionalisation (e.g. prison) Elderly Introduction Thiamine is a water-soluble vitamin, which is able to cross the This makes attention to the thiamine status in these patients blood-brain barrier.