Lepcha Romanization Table
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Problems with Unicode for Languages Unsupported by Computers
Problems with Unicode for Languages Unsupported by Computers Pat Hall, Language Technology Kendra, Patan, Nepal [email protected] Abstract If a language is to be used on the Internet it needs to be written and that writing encoded for the computer. The problems of achieving this for small languages is illustrated with respect to Nepal. Nepal has over 120 languages, with only the national language Nepali having any modern computer support. Nepali is relatively easy, since it is written in Devanagari which is also used for Hindi and other Indian languages, though with some local differences. I focus on the language of the Newar people, a language which has a mature written tradition spanning more than one thousand years, with several different styles of writing, and yet has no encoding of its writing within Unicode. Why has this happened? I explore this question, looking for answers in the view of technology of the people involved, in their different and possibly competing interests, and in the incentives for working on standards. I also explore what should be done about the many other unwritten and uncomputerised languages of Nepal. We are left with serious concerns about the standardisation process, but appreciate that encoding is critically important and we must work with the standardisation process as we find it.. Introduction If we are going to make knowledge written in our language available to everybody in their own languages, those languages must be written and that writing must be encoded in the computer. Those of us privileged to be native speakers of a world language such as English or Spanish may think this is straightforward, but it is not, as will be explained here. -
Lepcha Script Was Devised in the Early 18Th Century by Prince Chakdor Namgyal of Tibet
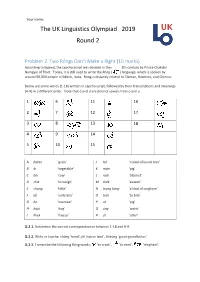
Your name: The UK Linguistics Olympiad 2019 Round 2 Problem 2. Two Róngs Don’t Make a Right (10 marks) According to legend, the Lepcha script was devised in the early 18th century by Prince Chakdor Namgyal of Tibet. Today, it is still used to write the Róng ( ) language, which is spoken by around 50,000 people in Sikkim, India. Róng is distantly related to Tibetan, Burmese, and Chinese. Below are some words (1-18) written in Lepcha script, followed by their transcriptions and meanings (A-R) in a different order. Note that ó and ú are distinct vowels from o and u. 1 6 11 16 2 7 12 17 3 8 13 18 4 9 14 5 10 15 A bakto 'grain' J lali 'a kind of laurel tree' B bi 'vegetable' K món 'pig' C bik 'cow' L radi 'blanket' D chik 'to weigh' M thúk 'season' E chung 'little' N tsung kóng 'a kind of sorghum' F dú 'umbrella' O tsúk 'to bite' G ka 'overseer' P ut 'pig' H kajú 'dog' Q úng 'water' I khek 'freeze' R út 'otter' Q.2.1. Determine the correct correspondences between 1-18 and A-R. Q.2.2. Write in Lepcha: chóng ‘hand’, jik ‘native land’, thikúng ‘great-grandfather’. Q.2.3. Transcribe the following Róng words: ‘to crack’, ‘to read’, ’elephant’. Your name: The UK Linguistics Olympiad 2019 Round 2 Solution and marking. Scoring (max 30) • Q.2.1: 1 point for each correct letter (max 18) • Q.2.2: 2 points for each correct Lepcha word; 1 point with one error (max 6) • Q.2.3: 2 points for each correct transliteration; 1 with one error (max 6) Q.2.1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 J F A Q C R D N H M G I B O K L E P Q.2.2 chóng ‘hand’ jik ‘native land’ thikúng ‘great-grandfather’ (thi-kung) or (thik-ung) Q.2.3 dan ‘to crack’ rok ‘to read’ ’elephant’ ranmo Your name: The UK Linguistics Olympiad 2019 Round 2 Commentary 1. -

Iso/Iec Jtc1/Sc2/Wg2 N2947r L2/05-158R
ISO/IEC JTC1/SC2/WG2 N2947R L2/05-158R 2005-07-04 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Lepcha script in the BMP of the UCS Source: Michael Everson Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2005-07-04 Lepcha is a Sino-Tibetan language. The Lepchas call themselves Róngkup (‘children of the Róng’), and their language Róngríng (‘language of the Róng’), but the name Lepcha is very widespread now, and the Lepchas themselves also use it frequently. The Lepcha script is in current use by many people in Sikkim and West Bengal, especially in the Darjeeling district. The weekly government newspaper The Sikkim Herald is also published in Lepcha and Lepcha is taught in schools in Sikkim. In West Bengal, there are many evening classes in which the script is taught, as well as books and magazines which are published privately or through one of several Lepcha associations. The SIL Ethnologue indicates that there are 41,300 Lepchas. Structure The Lepcha script is of the Brahmic type, but indirectly, being derived directly from Tibetan; some of those innovations are reflected in the structure of Lepcha. If one turns a Lepcha syllable clockwise, the similarities to Tibetan syllables is often quite striking. Lepcha has also introduced some innovations of its own, such as the diacritical marks used for final consonants. Lepcha is thought to have been devised around 1720 CE by the Sikkim king Phyag-rdor rNam-rgyal (“Chakdor Namgyal”, born 1686), according to Jensen 1969. -

Rong Kit Introduction
ᰛᰀ Digital Lepcha for Windows, Mac OS X and Linux © Sikkim Bhutia Lepcha Apex Committee - 2016 Foreword Written language is incredibly important, as it is a fundamental way of communicating, and doing so indirectly and over time. It is a main way civilizations accrue and record their technology, educate their citizens, and keep a historical record. This “collective wisdom” for lack of a better term is a hallmark of many great civilizations. Writing is the physical manifestation of a spoken language. It is thought that human beings developed language c. 35,000 BCE as evidenced by cave paintings from the period of the Cro-Magnon Man (c. 50,000-30,000 BCE) which appear to express concepts concerning daily life. These images suggest a language because, in some instances, they seem to tell a story (say, of a hunting expedition in which specific events occurred) rather than being simply pictures of animals and people. Written language, however, does not emerge until its invention in Sumer, southern Mesopotamia, c. 3500 -3000 BCE. This early writing was called cuneiform and consisted of making specific marks in wet clay with a reed implement. The writing system of the Egyptians was already in use before the rise of the Early Dynastic Period (c. 3150 BCE) and is thought to have developed from Mesopotamian cuneiform (though this theory is disputed) and came to be known as hieroglyphics. The phonetic writing systems of the Greeks, and later the Romans, came from Phoenicia (hence the name). The Phoenician writing system, though quite different from that of Mesopotamia, still owes its development to the Sumerians and their advances in the written word. -

Papers in Southeast Asian Linguistics No. 14: Tibeto-Bvrman Languages of the Himalayas
PACIFIC LINGUISTICS Series A-86 PAPERS IN SOUTHEAST ASIAN LINGUISTICS NO. 14: TIBETO-BVRMAN LANGUAGES OF THE HIMALAYAS edited by David Bradley Department of Linguistics Research School of Pacific and Asian Studies THE AUSTRALIAN NATIONAL UNIVERSITY Bradley, D. editor. Papers in Southeast Asian Linguistics No. 14:. A-86, vi + 232 (incl. 4 maps) pages. Pacific Linguistics, The Australian National University, 1997. DOI:10.15144/PL-A86.cover ©1997 Pacific Linguistics and/or the author(s). Online edition licensed 2015 CC BY-SA 4.0, with permission of PL. A sealang.net/CRCL initiative. Pacific Linguistics specialises in publishing linguistic material relating to languages of East Asia, Southeast Asia and the Pacific. Linguistic and anthropological manuscripts related to other areas, and to general theoretical issues, are also considered on a case by case basis. Manuscripts are published in one of four series: SERIES A: Occasional Papers SERIES C: Books SERIES B: Monographs SERIES D: Special Publications FOUNDING EDITOR: S.A. Wurm EDITORIAL BOARD: M.D. Ross and D.T. Tryon (Managing Editors), T.E. Dutton, N.P. Himmelmann, A.K. Pawley EDITORIAL ADVISERS: B.W. Bender KA. McElhanon University of Hawaii Summer Institute of Linguistics David Bradley H.P. McKaughan La Trobe University University of Hawaii Michael G. Clyne P. Miihlhausler Monash University Universityof Adelaide S.H. Elbert G.N. O'Grady University of Hawaii University of Victoria, B.C. K.J. Franklin KL. Pike Summer Institute of Linguistics Summer Institute of Linguistics W.W.Glover E.C. Polome Summer Institute of Linguistics University of Texas G.W.Grace Gillian Sankoff University of Hawaii University of Pennsylvania M.A.K. -

Amendment for .Mls
Amendment No. 1 to Registry Agreement The Internet Corporation for Assigned Names and Numbers and The Canadian Real Estate Association agree, effective as of _______________________________ (“Amendment No. 1 Effective Date”), that the modification set forth in this amendment No. 1 (the “Amendment”) is made to the 23 April 2015 .MLS Registry Agreement between the parties, as amended (the “Agreement”). The parties hereby agree to amend Exhibit A of the Agreement by deleting section 4 in its entirety: [OLD TEXT] “4. Internationalized Domain Names (IDNs) Registry Operator may offer registration of IDNs at the second and lower levels provided that Registry Operator complies with the following requirements: 4.1. Registry Operator must offer Registrars support for handling IDN registrations in EPP. 4.2. Registry Operator must handle variant IDNs as follows: 4.2.1. Variant IDNs (as defined in the Registry Operator’s IDN tables and IDN Registration Rules) will be blocked from registration. 4.3. Registry Operator may offer registration of IDNs in the following languages/scripts (IDN Tables and IDN Registration Rules will be published by the Registry Operator as specified in the ICANN IDN Implementation Guidelines): 4.3.1. Arabic script 4.3.2. Armenian script 4.3.3. Avestan script 4.3.4. Azerbaijani language 4.3.5. Balinese script 4.3.6. Bamum script 4.3.7. Batak script 4.3.8. Belarusian language 4.3.9. Bengali script 4.3.10. Bopomofo script 4.311. Brahmi script 4.3.12. Buginese script 4.3.13. Buhid script 4.3.14. Bulgarian language 4.3.15. -

Prosodic Analysis and Asian Linguistics: to Honour R.K
PACIFIC LINGIDSTICS Series C - No.l04 PROSODIC ANALYSIS AND ASIAN LINGUISTICS: TO HONOUR R.K. SPRIGG David Bradley, Eugenie 1.A. Henderson and Martine Mazaudon eds Department of Linguistics Research School of Pacific Studies THE AUSTRALIAN NATIONAL UNIVERSITY PACIFIC LIN GUISTICS is issued through the Linguistic Circle of Canberra and consists of four series: SERIES A: Occasional Papers SERIES C: Books SERIESB: Monographs SERIES D: Special Publications FOUNDING EDITOR: S.A. Wurm EDITORIAL BOARD: D.T. Tryon, T.E. Dutton, M.D. Ross EDITORIAL ADVISERS: B.W. Bender H. P. McKaughan University of Hawaii University of Hawaii David Bradley_ P. Miihlhl1usler LaTrobe University Bond University Michael G. Clyne G.N. O' Grady Monash University University of Victoria, B.C. S.H. Elbert A.K. Pawley University of Hawaii University of Auckland K.J. Franklin KL. Pike Summer Institute of Linguistics Summer Instituteof Linguistics W.W. Glover E.C. Polome Summer Institute of Linguistics University of Texas G.W. Grace GillianSan koff Universi� of Hawaii University of Pennsylvania M.A.K. Halliday W.A.L. Stokhof University of Sydney University of Leiden E. Haugen B.K. T'sou HarvardUniversity CityPolytechnic of Hong Kong A. Healey E.M. Uhlenbeck Summer Institute of Linguistics University of Leiden L.A. Hercus J .W.M. Verhaar AustralianNational University Divine Word Institute, Madang John Lynch CL. Voorhoeve Umversity of PapuaNew Guinea University of Leiden K.A. McElhanon Summer Institute of Linguistics All correspondence concerningPACIFIC LIN GUISTICS, including orders and subscriptions, should be addressed to: PACIFIC LIN GUISTICS Department of Linguistics Research School of Pacific Studies The AustralianNational University Canberra, A.C.T. -
Peter T. DANIELS – William BRIGHT (Eds.), the World's Writing Systems, New York/Oxford: Oxford University Press, 1996. Pp. X
COMPTES RENDUS 331 Peter T. DANIELS – William BRIGHT (eds.), The World’s Writing Systems, New York/Oxford: Oxford University Press, 1996. Pp. xlv-922. £ 97.50. This book fills a major gap in the list of standard works in linguistics. As a matter of fact, although there are a number of valuable (and a much larger number of popularizing) works on writing systems, there was no work offering a comprehensive survey of the nature, status and func- tioning, the history, the diffusion and adaptation of the writing systems of the world. The book edited by DANIELS and BRIGHT provides all this information, and in addition to that it contains chapters on the decipher- ment of scripts, on the sociolinguistic embedding of writing systems, on secondary notation systems, and finally on imprinting and printing. All sections are followed by a bibliography, which constitutes a reference checklist for interested readers. The status of the work as a major refer- ence tool is enhanced by the inclusion of hundreds of tables and figures, and samples of the scripts, illustrated with a brief text (given in the par- ticular script, with transcription/transliteration, and translation). Some 80 specialists of writing systems and their history have con- tributed to this huge work, which is divided into 74 sections, with sev- eral sections being subdivided into small chapters (as noted above, bib- liographical references are grouped together at the end of sections). The overall organization of the book is into thirteen parts, following the dis- tinction into writing system (or scriptural type) and its respective chronology. -
Where the Gods Are Mountains: Three Years Among the People of The
ere are (Mx>unt4\m& THREE YEARS AMONG THE PEOPLE Of'THE HIMALAYAS ,-** RENE WN NEBESKY-WOJK- $4.75 WL ere tUe yie>i>s <avc lM by RENE VON NEBESKY-WOJKOWITZ dis Rene von Nebesky-Wojkowitz, the tinguished Austrian anthropologist, went mountain to Tibet and the neighboring countries to study the legends, customs and religious traditions of the Himalayan peoples. His three-year visit coincided with the turbulent period when revolu tion broke out in Nepal and Tibet was conquered by Red China. In this account of his travels he describes his own experi ences and gives much new and fascinating information about the people he was liv ing among. tie met lamas and explorers, princes and adventurers, saints and ministers. He visited Bhutan, which has been pene trated by only a dozen Europeans in the twelve centuries of its history; Kalim- pong, the terminus of the great caravan route which leads from Lhasa to India; the home of the Sherpas, whose customs have long been ignored by Europeans who concentrate on their abilities as climbers; and Tibet itself, where he was initiated into the mysteries of its religion, and studied the exquisite Tibetan paint ing and literature. He witnessed the ex traordinary trance of an "oracle-priest"; the mystical marathon run by the Yogis every twelve years; and a royal Sikkimese wedding, at which the weather-makers produced torrents of rain by mistake. He also discusses the complicated marital re lationships in Tibet, where women hold an exalted position and polyandry is common. Where the Gods are Mountains WTiere the Gods are Mountains THREE YEARS AMONG THE PEOPLE OF THE HIMALAYAS Rene von Nebesky-Wbjkowitz TRANSLATED FROM THE GERMAN BY Michael Bullock REYNAL AND COMPANY NEW YORK First published in Germany under the title Wo Berge Goetter Sind Published in the United States by Reynal and Company, Inc. -

2953 Date: 2006-02-16
ISO/IEC JTC 1/SC 2/WG 2 N2953 DATE: 2006-02-16 ISO/IEC JTC 1/SC 2/WG 2 Universal Multiple-Octet Coded Character Set (UCS) - ISO/IEC 10646 Secretariat: ANSI DOC TYPE: Meeting Minutes TITLE: Unconfirmed minutes of WG 2 meeting 47 ETSI Campus, Sophia Antipolis, France; 2005-09-12/15 SOURCE: V.S. Umamaheswaran, Recording Secretary, and Mike Ksar, Convener PROJECT: JTC 1.02.18 – ISO/IEC 10646 STATUS: SC 2/WG 2 participants are requested to review the attached unconfirmed minutes, act on appropriate noted action items, and to send any comments or corrections to the convener as soon as possible but no later than 2006-04-10. ACTION ID: ACT DUE DATE: 2006-04-10 DISTRIBUTION: SC 2/WG 2 members and Liaison organizations MEDIUM: Acrobat PDF file NO. OF PAGES: 57 (including cover sheet) Mike Ksar Convener – ISO/IEC/JTC 1/SC 2/WG 2 Microsoft Corporation Phone: +1 425 707-6973 One Microsoft Way Fax: +1 425 936-7329 Bldg 24/2217 email: [email protected] Redmond, WA 98052-6399 or [email protected] ISO International Organization for Standardization Organisation Internationale de Normalisation ISO/IEC JTC 1/SC 2/WG 2 Universal Multiple-Octet Coded Character Set (UCS) ISO/IEC JTC 1/SC 2/WG 2 N2953 Date: 2006-02-16 Title: Unconfirmed minutes of WG 2 meeting 47 ETSI Campus, Sophia Antipolis, France; 2005-09-12/15 Source: V.S. Umamaheswaran ([email protected]), Recording Secretary Mike Ksar ([email protected]), Convener Action: WG 2 members and Liaison organizations Distribution: ISO/IEC JTC 1/SC 2/WG 2 members and liaison organizations 1 Opening and roll call The convener opened the meeting at 10:05h. -

Nippon Life Insurance Company Request 25 April 2016
ICANN Registry Request Service Ticket ID: Z7Y2L-9F5Z2 Registry Name: Nippon Life Insurance Company gTLD: .nissay Status: ICANN Review Status Date: 2016-04-25 18:44:14 Print Date: 2016-04-25 18:44:29 Proposed Service Name of Proposed Service: Technical description of Proposed Service: .NISSAY registry operator, Nippon Life Insurance Company is applying to add IDN domain registration services. .NISSAY IDN domain name registration services will be fully compliant with IDNA 2008, as well as ICANN's Guidelines for implementation of IDNs. The language tables are submitted separately via the GDD portal together with IDN policies. .NISSAY is a brand TLD, as defined by the Specification 13, and as such only the registry and its affiliates are eligible to register .NISSAY domain names. The full list of languages/scripts is: Azerbaijani language Belarusian language Bulgarian language Chinese language Croatian language French language Greek, Modern language Japanese language Korean language Kurdish language Macedonian language Moldavian language Polish language Russian language Serbian language Spanish language Swedish language Ukrainian language Arabic script Armenian script Avestan script Balinese script Bamum script Batak script Page 1 ICANN Registry Request Service Ticket ID: Z7Y2L-9F5Z2 Registry Name: Nippon Life Insurance Company gTLD: .nissay Status: ICANN Review Status Date: 2016-04-25 18:44:14 Print Date: 2016-04-25 18:44:29 Bengali script Bopomofo script Brahmi script Buginese script Buhid script Canadian Aboriginal script Carian script -

Unidings.Pdf
Unidings Glyphs and Icons for Blocks of The Unicode Standard O Unidings, version 13.00, March 2020 free strictly for personal, non-commercial use available under the general ufas licence Unicode Fonts for Ancient Scripts George Douros C0 Controls � � 0000..001F Basic Latin � � 0020..007F C1 Controls � � 0080..009F Latin-1 Supplement � � 00A0..00FF Latin Extended-A � � 0100..017F Latin Extended-B � � 0180..024F IPA Extensions � � 0250..02AF Spacing Modifier Leters � � 02B0..02FF Combining Diacritical Marks � � 0300..036F Greek and Coptic � � 0370..03FF Cyrillic � � 0400..04FF Cyrillic Supplement � � 0500..052F Armenian � � 0530..058F Hebrew � � 0590..05FF Arabic � � 0600..06FF Syriac � � 0700..074F Arabic Supplement � � 0750..077F Thaana � � 0780..07BF NKo � � 07C0..07FF Samaritan � � 0800..083F Mandaic � � 0840..085F Syriac Supplement � � 0860..086F � � Arabic Extended-B Arabic Extended-A � � 08A0..08FF Devanagari � � 0900..097F Bengali � � 0980..09FF Gurmukhi � � 0A00..0A7F Gujarati � � 0A80..0AFF Oriya � � 0B00..0B7F Tamil � � 0B80..0BFF Telugu � � 0C00..0C7F Kannada � � 0C80..0CFF Malayalam � � 0D00..0D7F Sinhala � � 0D80..0DFF Thai � � 0E00..0E7F Lao � � 0E80..0EFF Tibetan � � 0F00..0FFF Myanmar � � 1000..109F Georgian � � 10A0..10FF Hangul Jamo � � 1100..11FF Ethiopic � � 1200..137F Ethiopic Supplement � � 1380..139F Cherokee � � 13A0..13FF Unified Canadian Aboriginal Syllabics � � 1400..167F Ogham � � 1680..169F Runic � � 16A0..16FF Tagalog � � 1700..171F Hanunoo � � 1720..173F Buhid � � 1740..175F Tagbanwa � � 1760..177F Khmer