CRF Approaches to Kokborok Named Entity Recognition, a Low Resource Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Morphological Analyzer for Kokborok
Morphological Analyzer for Kokborok Khumbar Debbarma1 Braja Gopal Patra2 Dipankar Das3 Sivaji Bandyopadhyay2 (1) TRIPURA INSTITUTE OF TECHNOLOGY, Agartala, India (2) JADAVPUR UNIVERSITY, Kolkata, India (3) NATIONAL INSTITUTE_OF TECHNOLOGY, Meghalaya, India [email protected], [email protected], [email protected],[email protected] ABSTRACT Morphological analysis is concerned with retrieving the syntactic and morphological properties or the meaning of a morphologically complex word. Morphological analysis retrieves the grammatical features and properties of an inflected word. However, this paper introduces the design and implementation of a Morphological Analyzer for Kokborok, a resource constrained and less computerized Indian language. A database driven affix stripping algorithm has been used to design the Morphological Analyzer. It analyzes the Kokborok word forms and produces several grammatical information associated with the words. The Morphological Analyzer for Kokborok has been tested on 56732 Kokborok words; thereby an accuracy of 80% has been obtained on a manual check. KEYWORDS : Morphology Analyzer, Kokborok, Dictionary, Stemmer, Prefix, Suffix. Proceedings of the 3rd Workshop on South and Southeast Asian Natural Language Processing (SANLP), pages 41–52, COLING 2012, Mumbai, December 2012. 41 1 Introduction Kokborok is the native language of Tripura and is also spoken in the neighboring states like Assam, Manipur, Mizoram as well as the countries like Bangladesh, Myanmar etc., comprising of more than 2.5 millions1 of people. Kokborok belongs to the Tibeto-Burman (TB) language falling under the Sino language family of East Asia and South East Asia2. Kokborok shares the genetic features of TB languages that include phonemic tone, widespread stem homophony, subject- object-verb (SOV) word order, agglutinative verb morphology, verb derivational suffixes originating from the semantic bleaching of verbs, duplication or elaboration. -

Waromung an Ao Naga Village, Monograph Series, Part VI, Vol-I
@ MONOGRAPH CENSUS OF INDIA 1961 No. I VOLUME-I MONOGRAPH SERIES Part VI In vestigation Alemchiba Ao and Draft Research design, B. K. Roy Burman Supervision and Editing Foreword Asok Mitra Registrar General, InOla OFFICE OF THE REGISTRAR GENERAL, INDIA WAROMUNG MINISTRY OF HOME AFFAIRS (an Ao Naga Village) NEW DELHI-ll Photographs -N. Alemchiba Ao K. C. Sharma Technical advice in describing the illustrations -Ruth Reeves Technical advice in mapping -Po Lal Maps and drawings including cover page -T. Keshava Rao S. Krishna pillai . Typing -B. N. Kapoor Tabulation -C. G. Jadhav Ganesh Dass S. C. Saxena S. P. Thukral Sudesh Chander K. K. Chawla J. K. Mongia Index & Final Checking -Ram Gopal Assistance to editor in arranging materials -T. Kapoor (Helped by Ram Gopal) Proof Reading - R. L. Gupta (Final Scrutiny) P. K. Sharma Didar Singh Dharam Pal D. C. Verma CONTENTS Pages Acknow ledgement IX Foreword XI Preface XIII-XIV Prelude XV-XVII I Introduction ... 1-11 II The People .. 12-43 III Economic Life ... .. e • 44-82 IV Social and Cultural Life •• 83-101 V Conclusion •• 102-103 Appendices .. 105-201 Index .... ... 203-210 Bibliography 211 LIST OF MAPS After Page Notional map of Mokokchung district showing location of the village under survey and other places that occur in the Report XVI 2 Notional map of Waromung showing Land-use-1963 2 3 Notional map of Waromung showing nature of slope 2 4 (a) Notional map of Waromung showing area under vegetation 2 4 (b) Notional map of Waromung showing distribution of vegetation type 2 5 (a) Outline of the residential area SO years ago 4 5 (b) Important public places and the residential pattern of Waromung 6 6 A field (Jhurn) Showing the distribution of crops 58 liST OF PLATES After Page I The war drum 4 2 The main road inside the village 6 3 The village Church 8 4 The Lower Primary School building . -

AO and PROTO-TIBETO-BURMAN – the RIMES* Daniel Bruhn University of California, Berkeley
Format adapted from the LTBA stylesheet UCB Linguistics Qualifying Paper #2 Revised: 27 October 2010 UNEARTHING THE ROOTS: AO AND PROTO-TIBETO-BURMAN – THE RIMES* Daniel Bruhn University of California, Berkeley Keywords: Tibeto-Burman, historical, linguistics, Naga, Mongsen, Chungli, Ao, reflexes, roots, cognate sets, sound correspondences, sound change Table of Contents 1. INTRODUCTION ......................................................................................................... 2 1.1. Purpose ................................................................................................................. 2 1.2. Background ........................................................................................................... 3 1.3. Phonology ............................................................................................................. 4 1.3.1. Chungli ........................................................................................................... 4 1.3.2. Mongsen ......................................................................................................... 7 1.4. Methodology ......................................................................................................... 9 2. RIMES ....................................................................................................................... 11 2.1. *-a- ..................................................................................................................... 11 2.1.1. *-a > Chungli -a/-u/-i, Mongsen -a ........................................................... -

THE LANGUAGES of MANIPUR: a CASE STUDY of the KUKI-CHIN LANGUAGES* Pauthang Haokip Department of Linguistics, Assam University, Silchar
Linguistics of the Tibeto-Burman Area Volume 34.1 — April 2011 THE LANGUAGES OF MANIPUR: A CASE STUDY OF THE KUKI-CHIN LANGUAGES* Pauthang Haokip Department of Linguistics, Assam University, Silchar Abstract: Manipur is primarily the home of various speakers of Tibeto-Burman languages. Aside from the Tibeto-Burman speakers, there are substantial numbers of Indo-Aryan and Dravidian speakers in different parts of the state who have come here either as traders or as workers. Keeping in view the lack of proper information on the languages of Manipur, this paper presents a brief outline of the languages spoken in the state of Manipur in general and Kuki-Chin languages in particular. The social relationships which different linguistic groups enter into with one another are often political in nature and are seldom based on genetic relationship. Thus, Manipur presents an intriguing area of research in that a researcher can end up making wrong conclusions about the relationships among the various linguistic groups, unless one thoroughly understands which groups of languages are genetically related and distinct from other social or political groupings. To dispel such misconstrued notions which can at times mislead researchers in the study of the languages, this paper provides an insight into the factors linguists must take into consideration before working in Manipur. The data on Kuki-Chin languages are primarily based on my own information as a resident of Churachandpur district, which is further supported by field work conducted in Churachandpur district during the period of 2003-2005 while I was working for the Central Institute of Indian Languages, Mysore, as a research investigator. -

Non-Structural Case Marking in Tibeto-Burman and Artificial Languages*
Non-structural Case Marking in Tibeto-Burman and Artificial Languages* Alexander R. Coupe Sander Lestrade Nanyang Technological University Radboud University This paper discusses the diachronic development of non-structural case marking in Tibeto- Burman and in computer simulations of language evolution. It is shown how case marking is initially motivated by the pragmatic need to disambiguate between two core arguments, but eventually may develop flagging functions that even extend into the intransitive domain. Also, it is shown how different types of case-marking may emerge from various underlying disambiguation strategies. 1. Introduction This paper was motivated by the authors’ serendipitous discovery that a computer simulation of the emergence of case marking produced results that are uncannily similar to attested grammaticalization pathways and patterns of core case marking observed in the grammars of many Tibeto-Burman (henceforth TB) languages with pragmatically-motivated case marking. When it manifests, core case marking in both the natural and artificial languages appears to be initially motivated by the same fundamental need to disambiguate semantic roles. In other words, whenever some meaning does not follow inherently from the semantics of the dependency relationship holding between a head and its arguments, it must be encoded explicitly in the grammars of both the simulated language and the natural languages. Disambiguating case marking is most likely to appear in clauses with two core arguments when either one may potentially fulfill the role of the agent. Under these circumstances, some grammatical means of distinguishing an A argument from an O argument may be required to clarify meaning. 1 Conversely, if semantic roles can be unambiguously assigned to core arguments because of the semantic nature of their referents, then there may be no overt marking, even in bivalent clauses, so the use of core case marking is observed to have a pragmatic basis. -

Languages of Southeast Asia
Jiarong Horpa Zhaba Amdo Tibetan Guiqiong Queyu Horpa Wu Chinese Central Tibetan Khams Tibetan Muya Huizhou Chinese Eastern Xiangxi Miao Yidu LuobaLanguages of Southeast Asia Northern Tujia Bogaer Luoba Ersu Yidu Luoba Tibetan Mandarin Chinese Digaro-Mishmi Northern Pumi Yidu LuobaDarang Deng Namuyi Bogaer Luoba Geman Deng Shixing Hmong Njua Eastern Xiangxi Miao Tibetan Idu-Mishmi Idu-Mishmi Nuosu Tibetan Tshangla Hmong Njua Miju-Mishmi Drung Tawan Monba Wunai Bunu Adi Khamti Southern Pumi Large Flowery Miao Dzongkha Kurtokha Dzalakha Phake Wunai Bunu Ta w an g M o np a Gelao Wunai Bunu Gan Chinese Bumthangkha Lama Nung Wusa Nasu Wunai Bunu Norra Wusa Nasu Xiang Chinese Chug Nung Wunai Bunu Chocangacakha Dakpakha Khamti Min Bei Chinese Nupbikha Lish Kachari Ta se N a ga Naxi Hmong Njua Brokpake Nisi Khamti Nung Large Flowery Miao Nyenkha Chalikha Sartang Lisu Nung Lisu Southern Pumi Kalaktang Monpa Apatani Khamti Ta se N a ga Wusa Nasu Adap Tshangla Nocte Naga Ayi Nung Khengkha Rawang Gongduk Tshangla Sherdukpen Nocte Naga Lisu Large Flowery Miao Northern Dong Khamti Lipo Wusa NasuWhite Miao Nepali Nepali Lhao Vo Deori Luopohe Miao Ge Southern Pumi White Miao Nepali Konyak Naga Nusu Gelao GelaoNorthern Guiyang MiaoLuopohe Miao Bodo Kachari White Miao Khamti Lipo Lipo Northern Qiandong Miao White Miao Gelao Hmong Njua Eastern Qiandong Miao Phom Naga Khamti Zauzou Lipo Large Flowery Miao Ge Northern Rengma Naga Chang Naga Wusa Nasu Wunai Bunu Assamese Southern Guiyang Miao Southern Rengma Naga Khamti Ta i N u a Wusa Nasu Northern Huishui -

Download (4MB)
North East Indian Linguistics Volume 3 Edited by Gwendolyn Hyslop • Stephen Morey. Mark W. Post EOUNDATlON® S (j) ® Ie S Delhi· Bengaluru • Mumbai • Kolkata • Chennai • Hyderabad • Pune Published by Cambridge University Press India Pvt. Ltd. under the imprint of Foundation Books Cambridge House, 438114 Ansari Road, Daryaganj, New Delhi 110002 Cambridge University Press India Pvt. Ltd. C-22, C-Block, Brigade M.M., K.R. Road, Iayanagar, Bengaluru 560 070 Plot No. 80, Service Industries, Sbirvane, Sector-I, Neru!, Navi Mumbai 400 706 10 Raja Subodb Mullick Square, 2nd Floor, Kolkata 700 013 2111 (New No. 49), 1st Floor, Model School Road, Thousand Lights, Chcnnai 600 006 House No. 3-5-874/6/4, (Near Apollo Hospital), Hyderguda, Hyderabad 500 029 Agarwal Pride, 'A' Wing, 1308 Kasba Peth, Near Surya Hospital, :"Pune 411 011 © Cambridge Universiry Press India Pvt. Ltd. First Published 20 II ISBN 978-81-7596-793-9 All rights reserved. No reproduction of any part may take place without the written pennission of Cambridge University Press India Pvl. Ltd., subject to statutory exception and to the provision of relevant collective licensing agreements. Cambridge" Universiry Press India Pvl. Ltd. has no responsibility for the persistence or accuracy of URLs for external or third-parry internet websites referred to in this book, and does not guarantee that any content on such websites is, or will remain, accurate or appropriate. Typeset at SanchauLi Image Composers, New Deihi. Published by Manas Saikia for Cambridge University Press India Pvl. Ltd. and printed at Sanat Printers, Kundli. Haryana Contents About the Contributors v Foreword Chungkham Yashawanta Singh ix A Note from the Editors xvii The View from Manipur 1. -
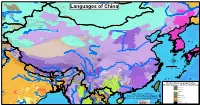
Map by Steve Huffman Data from World Language Mapping System 16
Mandarin Chinese Evenki Oroqen Tuva China Buriat Russian Southern Altai Oroqen Mongolia Buriat Oroqen Russian Evenki Russian Evenki Mongolia Buriat Kalmyk-Oirat Oroqen Kazakh China Buriat Kazakh Evenki Daur Oroqen Tuva Nanai Khakas Evenki Tuva Tuva Nanai Languages of China Mongolia Buriat Tuva Manchu Tuva Daur Nanai Russian Kazakh Kalmyk-Oirat Russian Kalmyk-Oirat Halh Mongolian Manchu Salar Korean Ta tar Kazakh Kalmyk-Oirat Northern UzbekTuva Russian Ta tar Uyghur SalarNorthern Uzbek Ta tar Northern Uzbek Northern Uzbek RussianTa tar Korean Manchu Xibe Northern Uzbek Uyghur Xibe Uyghur Uyghur Peripheral Mongolian Manchu Dungan Dungan Dungan Dungan Peripheral Mongolian Dungan Kalmyk-Oirat Manchu Russian Manchu Manchu Kyrgyz Manchu Manchu Manchu Northern Uzbek Manchu Manchu Manchu Manchu Manchu Korean Kyrgyz Northern Uzbek West Yugur Peripheral Mongolian Ainu Sarikoli West Yugur Manchu Ainu Jinyu Chinese East Yugur Ainu Kyrgyz Ta jik i Sarikoli East Yugur Sarikoli Sarikoli Northern Uzbek Wakhi Wakhi Kalmyk-Oirat Wakhi Kyrgyz Kalmyk-Oirat Wakhi Kyrgyz Ainu Tu Wakhi Wakhi Khowar Tu Wakhi Uyghur Korean Khowar Domaaki Khowar Tu Bonan Bonan Salar Dongxiang Shina Chilisso Kohistani Shina Balti Ladakhi Japanese Northern Pashto Shina Purik Shina Brokskat Amdo Tibetan Northern Hindko Kashmiri Purik Choni Ladakhi Changthang Gujari Kashmiri Pahari-Potwari Gujari Japanese Bhadrawahi Zangskari Kashmiri Baima Ladakhi Pangwali Mandarin Chinese Churahi Dogri Pattani Gahri Japanese Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Ladakhi Northern Qiang -

Word Order in Biate
====================================================================== Language in India www.languageinindia.com ISSN 1930-2940 Vol. 19:6 June 2019 ===================================================================== Word Order in Biate M Hemminlal Haokip, Ph.D. Scholar Department of Linguistics Assam University, Silchar 788011 [email protected] Phone: 8402023162 ====================================================================== Abstract The paper aims to discuss the word order pattern in Biate (ISO639-3), an endangered and undocumented language spoken in Jaintia Hills of Meghalaya, Dima Hasao (North Cachar Hills) district of Assam and some parts of Mizoram and Manipur. Biate stands for both the people and the language. It is spoken by 19,000 speakers (Ethnologue 2019). Grierson-Konow (1904) and Graham Thurgood (2003) classified Biate to the Old-Kuki sub-group of Sino-Tibetan language family. The paper will discuss and examine the word order pattern, which is one of the primary ways in which languages differ from one another. Biate is a verb-final language, with SOV as its basic word order. It exhibits a large number of characteristics expected of it as an OV language. Biate employs postpositions (PP), which follow the noun phrase they combine with. Like other Kuki-Chin languages, the genitive is indicated by the possessor which precedes the possessed item. The Adjective follows the noun (NAdj) in Biate. Noun modifiers like numerals and classifiers follow the noun. Relative clause precedes the noun (RelN) in Biate. Keywords: Biate, Kuki-Chin, Word order, Tibeto-Burman Introduction Biate is one of the recognized tribes of Assam, Meghalaya, Mizoram, and Manipur under ‘Any Kuki Tribes’. The word Biate has varied meanings; the most common meaning that seems everybody accepts is worshippers, referring to a common worship of a particular deity or different worship of various deities by their ancestors from time immemorial, (Remsiama Ngamlai, 20141). -

Tentative Program Schedule HLS23
TENTATIVE PROGRAM 23RD HIMALAYAN LANGUAGES SYMPOSIUM CENTRE FOR ENDANGERED LANGUAGES, TEZPUR UNIVERSITY 5 – 7 JULY 2017 DAY I WEDNESDAY 5 JULY VENUE: COUNCIL HALL, TEZPUR UNIVERSITY 09.00 - 10.00 Registration 10.00 - 11.00 INAUGURAL SESSION 10.00-10.15 Welcome Address by the Coordinator, 23rd HLS Organizing Committee 10.15-10.30 Introducing the theme of the Symposium 10.30-10.45 Inaugural Address by the Honourable Vice Chancellor, Tezpur University 10.45-10.50 Address by Dean, School of Humanities and Social Sciences, Tezpur University 10.50-11.05 Address by Prof. Van Driem 11.05-11.10 Vote of Thanks 11.10-11.30 Tea break 11.30-12.30 Keynote Address: Prof. George van Driem 12.30-01.30 SESSION- I Language and Linguistics Chair: K.V. Subbarao Venue: Council Hall 12.30-12.50 The Development and Implementation of a Writing System: Koĩc (Kiranti, Tibeto-Burman): Dorte Borcher 12.50-01.10 The Consequence of Code-Mixing the Adjective in NPs in Meiteilon-English: Tanmoy Bhattacharya 01.10-01.30 Raji: A Tibeto-Burman or Austro - Asiatic Language?: Kavita Rastogi 01.30-02.30 Lunch Break 02.30-03.30 Session II Venue: Department of EFL, HSS Building Acoustic Phonetics Syntax Ethnolinguistics Applied Linguistics Room No (to be announced) Room No (to be announced) Room No (to be announced) Room No (to be Chair: Temsunungsang T. Chair: Tanmoy Bhattacharya Chair: Hari Madhab Ray announced) Chair: Deepa Boruah 02.30-02.50 Acoustic analysis of the Nepali Tracing Burushaski through Tribal Development Boards and Influence of Assamese L2 plosives Case-marking -

An Unsupervised Word Level Language Identification of English and Kokborok Code
© 2020 JETIR August 2020, Volume 7, Issue 8 www.jetir.org (ISSN-2349-5162) An Unsupervised Word Level Language Identification of English and Kokborok Code- Mixed and Code-Switched Sentences 1Enjula Uchoi, 2Lenin Laitonjam 1Lecturer, 2Supervisor, 1Department of Computer Science and Engineering, 1Dhalai District Polytechnic, Agartala, India. Abstract: Considering the increasing uses of multilingual text, the need for an automatic word level language identification model is raised. In this regard, we present an unsupervised model for word level language identification of English and Kokborok code-mixed and code-switched sentences. Several works have already been reported for various languages, including various Indian languages. But, to the best of our knowledge, ours is the first language identification work dedicated to low resource English-Kokborok language pairs. The proposed model combines a frequency lexicon based, character n-gram language model and a language dependent morphological dictionary-based model for correctly classifying each word. The model which is suitable for low resource languages that do not have a large number of annotated dataset is able to achieve a good performance with word accuracy level of 84%. IndexTerms - Word level language identification, code-mixing, code-switching, dictionaries, affixes, kokborok, English. I. INTRODUCTION Automatic language identification based on code-mixing and code-switching in Social media is gaining more and more attention for those researchers who are basically working and doing research work in the field of Natural Language Processing. In this generation multilingual speakers are much higher in number than the monolingual speakers, we can see in Social media many of the speakers are multilingual speakers using more than two languages in their conversation in Facebook, tweeter and in many others sources. -

Languages of Manipur in the Fast Changing Globalized World
================================================================== Language in India www.languageinindia.com ISSN 1930-2940 Vol. 15:10 October 2015 =================================================================== Languages of Manipur in the Fast Changing Globalized World Naorem Brindebala Devi, Research Scholar Prof. Ch. Yashawanta Singh ================================================================= Abstract There are many languages in the world. But it is not confirmed yet the exact number of the languages. In Manipur itself, there are three language families: Indo-Aryan, Dravidian and Tibeto-Burman. Manipuri, the lingua-franca of Manipur, is included in the Tibeto-Burman language family, besides the 33 claimed tribal languages. It is an Eighth Schedule language which is used as a medium of instruction in schools and colleges. Some tribal language are in the status of using as a medium of instruction from standard 1 to graduate level where they are taught as an elective subject. However, social development and globalization have made a great impact on these languages. Various loan words related to computer, mobile phones, internet, cable TV and readymade phrases and sentences etc. are used with native languages with their respective verbs as an impact/effect of IT and various network developments which are the agents of globalization. It let the cultures exchanged throughout the world, translation, being the means. Globalization gives an opportunity of changing the languages but it needs care to develop the mother tongue as well as nativize it side by side. Key words: language, tribal language, endangered language, globalization, translation, technology. Introduction Till today there is no exact number of languages recorded in the world: it is estimated generally and reported as more than 6000 languages in the world.