History of Processor Performance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AMD Athlon™ Processor X86 Code Optimization Guide
AMD AthlonTM Processor x86 Code Optimization Guide © 2000 Advanced Micro Devices, Inc. All rights reserved. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. No license, whether express, implied, arising by estoppel or otherwise, to any intellectual property rights is granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as components in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other applica- tion in which the failure of AMD’s product could create a situation where per- sonal injury, death, or severe property or environmental damage may occur. AMD reserves the right to discontinue or make changes to its products at any time without notice. Trademarks AMD, the AMD logo, AMD Athlon, K6, 3DNow!, and combinations thereof, AMD-751, K86, and Super7 are trademarks, and AMD-K6 is a registered trademark of Advanced Micro Devices, Inc. Microsoft, Windows, and Windows NT are registered trademarks of Microsoft Corporation. -

Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance
White Paper Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance Ofri Wechsler Intel Fellow, Mobility Group Director, Mobility Microprocessor Architecture Intel Corporation White Paper Inside Intel®Core™ Microarchitecture Introduction Introduction 2 The Intel® Core™ microarchitecture is a new foundation for Intel®Core™ Microarchitecture Design Goals 3 Intel® architecture-based desktop, mobile, and mainstream server multi-core processors. This state-of-the-art multi-core optimized Delivering Energy-Efficient Performance 4 and power-efficient microarchitecture is designed to deliver Intel®Core™ Microarchitecture Innovations 5 increased performance and performance-per-watt—thus increasing Intel® Wide Dynamic Execution 6 overall energy efficiency. This new microarchitecture extends the energy efficient philosophy first delivered in Intel's mobile Intel® Intelligent Power Capability 8 microarchitecture found in the Intel® Pentium® M processor, and Intel® Advanced Smart Cache 8 greatly enhances it with many new and leading edge microar- Intel® Smart Memory Access 9 chitectural innovations as well as existing Intel NetBurst® microarchitecture features. What’s more, it incorporates many Intel® Advanced Digital Media Boost 10 new and significant innovations designed to optimize the Intel®Core™ Microarchitecture and Software 11 power, performance, and scalability of multi-core processors. Summary 12 The Intel Core microarchitecture shows Intel’s continued Learn More 12 innovation by delivering both greater energy efficiency Author Biographies 12 and compute capability required for the new workloads and usage models now making their way across computing. With its higher performance and low power, the new Intel Core microarchitecture will be the basis for many new solutions and form factors. In the home, these include higher performing, ultra-quiet, sleek and low-power computer designs, and new advances in more sophisticated, user-friendly entertainment systems. -

Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and Power
Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and power ITSC 3181 Introduction to Computer Architecture https://passlaB.githuB.io/ITSC3181/ Department of Computer Science Yonghong Yan [email protected] https://passlab.github.io/yanyh/ Lectures for Chapter 1 and C Basics Computer Abstractions and Technology • Lecture 01: Chapter 1 – 1.1 – 1.4: Introduction, great ideas, Moore’s law, aBstraction, computer components, and program execution • Lecture 02: C Basics; Memory and Binary Systems • Lecture 03: Number System, Compilation, Assembly, Linking and Program Execution ☛• Lecture 04: Chapter 1 – 1.6 – 1.7: Performance, power and technology trends • Lecture 05: – 1.8 - 1.9: Multiprocessing and Benchmarking 2 § 1.6 Performance 1.6 Defining Performance • Which airplane has the best performance? Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 100 200 300 400 500 0 2000 4000 6000 8000 10000 Passenger Capacity Cruising Range (miles) Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 500 1000 1500 0 100000 200000 300000 400000 Cruising Speed (mph) Passengers x mph 3 Response Time and Throughput • Response time çè Latency – How long it takes to do a task • Throughput çè Bandwidth – Total work done per unit time • e.g., tasks/transactions/… per hour • How are response time and throughput affected by – Replacing the processor with a faster version? – Adding more processors? • We’ll focus on response time for now… 4 Relative Performance • Define Performance = 1/Execution Time • “X is n time faster than Y”, i.e. -

45-Year CPU Evolution: One Law and Two Equations
45-year CPU evolution: one law and two equations Daniel Etiemble LRI-CNRS University Paris Sud Orsay, France [email protected] Abstract— Moore’s law and two equations allow to explain the a) IC is the instruction count. main trends of CPU evolution since MOS technologies have been b) CPI is the clock cycles per instruction and IPC = 1/CPI is the used to implement microprocessors. Instruction count per clock cycle. c) Tc is the clock cycle time and F=1/Tc is the clock frequency. Keywords—Moore’s law, execution time, CM0S power dissipation. The Power dissipation of CMOS circuits is the second I. INTRODUCTION equation (2). CMOS power dissipation is decomposed into static and dynamic powers. For dynamic power, Vdd is the power A new era started when MOS technologies were used to supply, F is the clock frequency, ΣCi is the sum of gate and build microprocessors. After pMOS (Intel 4004 in 1971) and interconnection capacitances and α is the average percentage of nMOS (Intel 8080 in 1974), CMOS became quickly the leading switching capacitances: α is the activity factor of the overall technology, used by Intel since 1985 with 80386 CPU. circuit MOS technologies obey an empirical law, stated in 1965 and 2 Pd = Pdstatic + α x ΣCi x Vdd x F (2) known as Moore’s law: the number of transistors integrated on a chip doubles every N months. Fig. 1 presents the evolution for II. CONSEQUENCES OF MOORE LAW DRAM memories, processors (MPU) and three types of read- only memories [1]. The growth rate decreases with years, from A. -

The Intel Microprocessors: Architecture, Programming and Interfacing Introduction to the Microprocessor and Computer
Microprocessors (0630371) Fall 2010/2011 – Lecture Notes # 1 The Intel Microprocessors: Architecture, Programming and Interfacing Introduction to the Microprocessor and computer Outline of the Lecture Evolution of programming languages. Microcomputer Architecture. Instruction Execution Cycle. Evolution of programming languages: Machine language - the programmer had to remember the machine codes for various operations, and had to remember the locations of the data in the main memory like: 0101 0011 0111… Assembly Language - an instruction is an easy –to- remember form called a mnemonic code . Example: Assembly Language Machine Language Load 100100 ADD 100101 SUB 100011 We need a program called an assembler that translates the assembly language instructions into machine language. High-level languages Fortran, Cobol, Pascal, C++, C# and java. We need a compiler to translate instructions written in high-level languages into machine code. Microprocessor-based system (Micro computer) Architecture Data Bus, I/O bus Memory Storage I/O I/O Registers Unit Device Device Central Processing Unit #1 #2 (CPU ) ALU CU Clock Control Unit Address Bus The figure shows the main components of a microprocessor-based system: CPU- Central Processing Unit , where calculations and logic operations are done. CPU contains registers , a high-frequency clock , a control unit ( CU ) and an arithmetic logic unit ( ALU ). o Clock : synchronizes the internal operations of the CPU with other system components using clock pulsing at a constant rate (the basic unit of time for machine instructions is a machine cycle or clock cycle) One cycle A machine instruction requires at least one clock cycle some instruction require 50 clocks. o Control Unit (CU) - generate the needed control signals to coordinate the sequencing of steps involved in executing machine instructions: (fetches data and instructions and decodes addresses for the ALU). -
Clock Rate Improves Roughly Proportional to Improvement in L • Number of Transistors Improves Proportional to L2 (Or Faster)
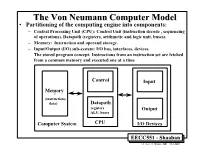
TheThe VonVon NeumannNeumann ComputerComputer ModelModel • Partitioning of the computing engine into components: – Central Processing Unit (CPU): Control Unit (instruction decode , sequencing of operations), Datapath (registers, arithmetic and logic unit, buses). – Memory: Instruction and operand storage. – Input/Output (I/O) sub-system: I/O bus, interfaces, devices. – The stored program concept: Instructions from an instruction set are fetched from a common memory and executed one at a time Control Input Memory - (instructions, data) Datapath registers Output ALU, buses Computer System CPU I/O Devices EECC551 - Shaaban #1 Lec # 1 Winter 2001 12-3-2001 Generic CPU Machine Instruction Execution Steps Instruction Obtain instruction from program storage Fetch Instruction Determine required actions and instruction size Decode Operand Locate and obtain operand data Fetch Execute Compute result value or status Result Deposit results in storage for later use Store Next Determine successor or next instruction Instruction EECC551 - Shaaban #2 Lec # 1 Winter 2001 12-3-2001 HardwareHardware ComponentsComponents ofof AnyAny ComputerComputer Five classic components of all computers: 1. Control Unit; 2. Datapath; 3. Memory; 4. Input; 5. Output } Processor Computer Keyboard, Mouse, etc. Processor Memory Devices (active) (passive) Control Input (where Unit programs, data Disk Datapath live when Output running) Display, Printer, etc. EECC551 - Shaaban #3 Lec # 1 Winter 2001 12-3-2001 CPUCPU OrganizationOrganization • Datapath Design: – Capabilities & performance characteristics of principal Functional Units (FUs): • (e.g., Registers, ALU, Shifters, Logic Units, ...) – Ways in which these components are interconnected (buses connections, multiplexors, etc.). – How information flows between components. • Control Unit Design: – Logic and means by which such information flow is controlled. – Control and coordination of FUs operation to realize the targeted Instruction Set Architecture to be implemented (can either be implemented using a finite state machine or a microprogram). -

Unit 8 : Microprocessor Architecture
Unit 8 : Microprocessor Architecture Lesson 1 : Microcomputer Structure 1.1. Learning Objectives On completion of this lesson you will be able to : ♦ draw the block diagram of a simple computer ♦ understand the function of different units of a microcomputer ♦ learn the basic operation of microcomputer bus system. 1.2. Digital Computer A digital computer is a multipurpose, programmable machine that reads A digital computer is a binary instructions from its memory, accepts binary data as input and multipurpose, programmable processes data according to those instructions, and provides results as machine. output. 1.3. Basic Computer System Organization Every computer contains five essential parts or units. They are Basic computer system organization. i. the arithmetic logic unit (ALU) ii. the control unit iii. the memory unit iv. the input unit v. the output unit. 1.3.1. The Arithmetic and Logic Unit (ALU) The arithmetic and logic unit (ALU) is that part of the computer that The arithmetic and logic actually performs arithmetic and logical operations on data. All other unit (ALU) is that part of elements of the computer system - control unit, register, memory, I/O - the computer that actually are there mainly to bring data into the ALU to process and then to take performs arithmetic and the results back out. logical operations on data. An arithmetic and logic unit and, indeed, all electronic components in the computer are based on the use of simple digital logic devices that can store binary digits and perform simple Boolean logic operations. Data are presented to the ALU in registers. These registers are temporary storage locations within the CPU that are connected by signal paths of the ALU. -

Atmega165p Datasheet
Features • High Performance, Low Power Atmel® AVR® 8-Bit Microcontroller • Advanced RISC Architecture – 130 Powerful Instructions – Most Single Clock Cycle Execution – 32 × 8 General Purpose Working Registers – Fully Static Operation – Up to 16 MIPS Throughput at 16 MHz – On-Chip 2-cycle Multiplier • High Endurance Non-volatile Memory segments – 16 Kbytes of In-System Self-programmable Flash program memory – 512 Bytes EEPROM – 1 Kbytes Internal SRAM 8-bit – Write/Erase cyles: 10,000 Flash/100,000 EEPROM(1)(3) – Data retention: 20 years at 85°C/100 years at 25°C(2)(3) Microcontroller – Optional Boot Code Section with Independent Lock Bits In-System Programming by On-chip Boot Program with 16K Bytes True Read-While-Write Operation – Programming Lock for Software Security In-System • JTAG (IEEE std. 1149.1 compliant) Interface – Boundary-scan Capabilities According to the JTAG Standard Programmable – Extensive On-chip Debug Support – Programming of Flash, EEPROM, Fuses, and Lock Bits through the JTAG Interface Flash • Peripheral Features – Two 8-bit Timer/Counters with Separate Prescaler and Compare Mode – One 16-bit Timer/Counter with Separate Prescaler, Compare Mode, and Capture Mode – Real Time Counter with Separate Oscillator –Four PWM Channels ATmega165P – 8-channel, 10-bit ADC – Programmable Serial USART ATmega165PV – Master/Slave SPI Serial Interface – Universal Serial Interface with Start Condition Detector – Programmable Watchdog Timer with Separate On-chip Oscillator – On-chip Analog Comparator Preliminary – Interrupt and Wake-up -
HOW FAST? the Current Intel® Core™ Processor Has 43,000,000% More Transistors Than the 4004 Processor
40yrs of Intel® microprocessor innovation Following Moore’s Law the whole way Intel co-founder Gordon Moore once made a famous prediction that transistor The world’s first microprocessor count for computer chips would —the Intel® 4004—was “born” in 1971, double every two years. 10 years before the first PC came along. Using Moore’s Law as a guiding principle, Intel has provided ever-increasing functionality, performance and energy efficiency to its products. Just think: What if the world had followed this golden rule the last 40 years? HOW FAST? The current Intel® Core™ processor has 43,000,000% more transistors than the 4004 processor. If a village with a 1971 population of 100 had grown as quickly, it would now be by far the largest city in the world. War and Peace? Wait a second. The 4004 processor executed 92,000 instructions per second, while today’s Intel® Core™ i7 processor can run 92 billion. If your typing had accelerated at that rate, you’d be able to type Tolstoy’s classic in just over 1 second. 0101010101010101… You would need 25,000 years to turn a light switch on and off 1.5 trillion times, but today’s processors can do that in less than a second. A PENNY SAVED… When released in 1981, the first well- equipped IBM PC cost about $11,250 in inflation-adjusted 2011 dollars. Today, much more powerful PCs are available in the $500 range (or even less). Fly me to the moon If space travel had come down in price as much as transistors have since 1971, the Apollo 11 mission, which cost around $355 million in 1969, would cost about as much as a latte. -

Comparing the Power and Performance of Intel's SCC to State
Comparing the Power and Performance of Intel’s SCC to State-of-the-Art CPUs and GPUs Ehsan Totoni, Babak Behzad, Swapnil Ghike, Josep Torrellas Department of Computer Science, University of Illinois at Urbana-Champaign, Urbana, IL 61801, USA E-mail: ftotoni2, bbehza2, ghike2, [email protected] Abstract—Power dissipation and energy consumption are be- A key architectural challenge now is how to support in- coming increasingly important architectural design constraints in creasing parallelism and scale performance, while being power different types of computers, from embedded systems to large- and energy efficient. There are multiple options on the table, scale supercomputers. To continue the scaling of performance, it is essential that we build parallel processor chips that make the namely “heavy-weight” multi-cores (such as general purpose best use of exponentially increasing numbers of transistors within processors), “light-weight” many-cores (such as Intel’s Single- the power and energy budgets. Intel SCC is an appealing option Chip Cloud Computer (SCC) [1]), low-power processors (such for future many-core architectures. In this paper, we use various as embedded processors), and SIMD-like highly-parallel archi- scalable applications to quantitatively compare and analyze tectures (such as General-Purpose Graphics Processing Units the performance, power consumption and energy efficiency of different cutting-edge platforms that differ in architectural build. (GPGPUs)). These platforms include the Intel Single-Chip Cloud Computer The Intel SCC [1] is a research chip made by Intel Labs (SCC) many-core, the Intel Core i7 general-purpose multi-core, to explore future many-core architectures. It has 48 Pentium the Intel Atom low-power processor, and the Nvidia ION2 (P54C) cores in 24 tiles of two cores each. -

Performance of a Computer (Chapter 4) Vishwani D
ELEC 5200-001/6200-001 Computer Architecture and Design Fall 2013 Performance of a Computer (Chapter 4) Vishwani D. Agrawal & Victor P. Nelson epartment of Electrical and Computer Engineering Auburn University, Auburn, AL 36849 ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 1 What is Performance? Response time: the time between the start and completion of a task. Throughput: the total amount of work done in a given time. Some performance measures: MIPS (million instructions per second). MFLOPS (million floating point operations per second), also GFLOPS, TFLOPS (1012), etc. SPEC (System Performance Evaluation Corporation) benchmarks. LINPACK benchmarks, floating point computing, used for supercomputers. Synthetic benchmarks. ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 2 Small and Large Numbers Small Large 10-3 milli m 103 kilo k 10-6 micro μ 106 mega M 10-9 nano n 109 giga G 10-12 pico p 1012 tera T 10-15 femto f 1015 peta P 10-18 atto 1018 exa 10-21 zepto 1021 zetta 10-24 yocto 1024 yotta ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 3 Computer Memory Size Number bits bytes 210 1,024 K Kb KB 220 1,048,576 M Mb MB 230 1,073,741,824 G Gb GB 240 1,099,511,627,776 T Tb TB ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 4 Units for Measuring Performance Time in seconds (s), microseconds (μs), nanoseconds (ns), or picoseconds (ps). Clock cycle Period of the hardware clock Example: one clock cycle means 1 nanosecond for a 1GHz clock frequency (or 1GHz clock rate) CPU time = (CPU clock cycles)/(clock rate) Cycles per instruction (CPI): average number of clock cycles used to execute a computer instruction. -

Technology & Energy
This Unit: Technology & Energy • Technology basis • Fabrication (manufacturing) & cost • Transistors & wires CIS 501: Computer Architecture • Implications of transistor scaling (Moore’s Law) • Energy & power Unit 3: Technology & Energy Slides'developed'by'Milo'Mar0n'&'Amir'Roth'at'the'University'of'Pennsylvania'' with'sources'that'included'University'of'Wisconsin'slides' by'Mark'Hill,'Guri'Sohi,'Jim'Smith,'and'David'Wood' CIS 501: Comp. Arch. | Prof. Milo Martin | Technology & Energy 1 CIS 501: Comp. Arch. | Prof. Milo Martin | Technology & Energy 2 Readings Review: Simple Datapath • MA:FSPTCM • Section 1.1 (technology) + 4 • Section 9.1 (power & energy) Register Data Insn File PC s1 s2 d Mem • Paper Mem • G. Moore, “Cramming More Components onto Integrated Circuits” • How are instruction executed? • Fetch instruction (Program counter into instruction memory) • Read registers • Calculate values (adds, subtracts, address generation, etc.) • Access memory (optional) • Calculate next program counter (PC) • Repeat • Clock period = longest delay through datapath CIS 501: Comp. Arch. | Prof. Milo Martin | Technology & Energy 3 CIS 501: Comp. Arch. | Prof. Milo Martin | Technology & Energy 4 Recall: Processor Performance • Programs consist of simple operations (instructions) • Add two numbers, fetch data value from memory, etc. • Program runtime = “seconds per program” = (instructions/program) * (cycles/instruction) * (seconds/cycle) • Instructions per program: “dynamic instruction count” • Runtime count of instructions executed by the program • Determined by program, compiler, instruction set architecture (ISA) • Cycles per instruction: “CPI” (typical range: 2 to 0.5) • On average, how many cycles does an instruction take to execute? • Determined by program, compiler, ISA, micro-architecture Technology & Fabrication • Seconds per cycle: clock period, length of each cycle • Inverse metric: cycles per second (Hertz) or cycles per ns (Ghz) • Determined by micro-architecture, technology parameters • This unit: transistors & semiconductor technology CIS 501: Comp.