A Japanese Electronic Dictionary Project (Part 1: the Dictionary Files)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction to Kanbun: W4019x (Fall 2004) Mondays and Wednesdays 11-12:15, Kress Room, Starr Library (Entrance on 200 Level)
1 Introduction to Kanbun: W4019x (Fall 2004) Mondays and Wednesdays 11-12:15, Kress Room, Starr Library (entrance on 200 Level) David Lurie (212-854-5034, [email protected]) Office Hours: Tuesdays 2-4, 500A Kent Hall This class is intended to build proficiency in reading the variety of classical Japanese written styles subsumed under the broad term kanbun []. More specifically, it aims to foster familiarity with kundoku [], a collection of techniques for reading and writing classical Japanese in texts largely or entirely composed of Chinese characters. Because it is impossible to achieve fluent reading ability using these techniques in a mere semester, this class is intended as an introduction. Students will gain familiarity with a toolbox of reading strategies as they are exposed to a variety of premodern written styles and genres, laying groundwork for more thorough competency in specific areas relevant to their research. This is not a class in Classical Chinese: those who desire facility with Chinese classical texts are urged to study Classical Chinese itself. (On the other hand, some prior familiarity with Classical Chinese will make much of this class easier). The pre-requisite for this class is Introduction to Classical Japanese (W4007); because our focus is the use of Classical Japanese as a tool to understand character-based texts, it is assumed that students will already have control of basic Classical Japanese grammar. Students with concerns about their competence should discuss them with me immediately. Goals of the course: 1) Acquire basic familiarity with kundoku techniques of reading, with a focus on the classes of special characters (unread characters, twice-read characters, negations, etc.) that form the bulk of traditional Japanese kanbun pedagogy. -

Consonant Characters and Inherent Vowels
Global Design: Characters, Language, and More Richard Ishida W3C Internationalization Activity Lead Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 1 Getting more information W3C Internationalization Activity http://www.w3.org/International/ Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 2 Outline Character encoding: What's that all about? Characters: What do I need to do? Characters: Using escapes Language: Two types of declaration Language: The new language tag values Text size Navigating to localized pages Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 3 Character encoding Character encoding: What's that all about? Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 4 Character encoding The Enigma Photo by David Blaikie Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 5 Character encoding Berber 4,000 BC Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 6 Character encoding Tifinagh http://www.dailymotion.com/video/x1rh6m_tifinagh_creation Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 7 Character encoding Character set Character set ⴰ ⴱ ⴲ ⴳ ⴴ ⴵ ⴶ ⴷ ⴸ ⴹ ⴺ ⴻ ⴼ ⴽ ⴾ ⴿ ⵀ ⵁ ⵂ ⵃ ⵄ ⵅ ⵆ ⵇ ⵈ ⵉ ⵊ ⵋ ⵌ ⵍ ⵎ ⵏ ⵐ ⵑ ⵒ ⵓ ⵔ ⵕ ⵖ ⵗ ⵘ ⵙ ⵚ ⵛ ⵜ ⵝ ⵞ ⵟ ⵠ ⵢ ⵣ ⵤ ⵥ ⵯ Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 8 Character encoding Coded character set 0 1 2 3 0 1 Coded character set 2 3 4 5 6 7 8 9 33 (hexadecimal) A B 52 (decimal) C D E F Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 9 Character encoding Code pages ASCII Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 10 Character encoding Code pages ISO 8859-1 (Latin 1) Western Europe ç (E7) Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 11 Character encoding Code pages ISO 8859-7 Greek η (E7) Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 12 Character encoding Double-byte characters Standard Country No. -

Hiragana Chart
ひらがな Hiragana Chart W R Y M H N T S K VOWEL ん わ ら や ま は な た さ か あ A り み ひ に ち し き い I る ゆ む ふ ぬ つ す く う U れ め へ ね て せ け え E を ろ よ も ほ の と そ こ お O © 2010 Michael L. Kluemper et al. Beginning Japanese, Tuttle Publishing, an imprint of Periplus Editions (HK) Ltd. All rights reserved. www.TimeForJapanese.com. 1 Beginning Japanese 名前: ________________________ 1-1 Hiragana Activity Book 日付: ___月 ___日 一、 Practice: あいうえお かきくけこ がぎぐげご O E U I A お え う い あ あ お え う い あ お う あ え い あ お え う い お う い あ お え あ KO KE KU KI KA こ け く き か か こ け く き か こ け く く き か か こ き き か こ こ け か け く く き き こ け か © 2010 Michael L. Kluemper et al. Beginning Japanese, Tuttle Publishing, an imprint of Periplus Editions (HK) Ltd. All rights reserved. www.TimeForJapanese.com. 2 GO GE GU GI GA ご げ ぐ ぎ が が ご げ ぐ ぎ が ご ご げ ぐ ぐ ぎ ぎ が が ご げ ぎ が ご ご げ が げ ぐ ぐ ぎ ぎ ご げ が 二、 Fill in each blank with the correct HIRAGANA. SE N SE I KI A RA NA MA E 1. -

Como Digitar Em Japonês 1
Como digitar em japonês 1 Passo 1: Mudar para o modo de digitação em japonês Abra o Office Word, Word Pad ou Bloco de notas para testar a digitação em japonês. Com o cursor colocado em um novo documento em algum lugar em sua tela você vai notar uma barra de idiomas. Clique no botão "PT Português" e selecione "JP Japonês (Japão)". Isso vai mudar a aparência da barra de idiomas. * Se uma barra longa aparecer, como na figura abaixo, clique com o botão direito na parte mais à esquerda e desmarque a opção "Legendas". ficará assim → Além disso, você pode clicar no "_" no canto superior direito da barra de idiomas, que a janela se fechará no canto inferior direito da tela (minimizar). ficará assim → © 2017 Fundação Japão em São Paulo Passo 2: Alterar a barra de idiomas para exibir em japonês Se você não consegue ler em japonês, pode mudar a exibição da barra de idioma para inglês. Clique em ツール e depois na opção プロパティ. Opção: Alterar a barra de idiomas para exibir em inglês Esta janela é toda em japonês, mas não se preocupe, pois da próxima vez que abrí-la estará em Inglês. Haverá um menu de seleção de idiomas no menu de "全般", escolha "英語 " e clique em "OK". © 2017 Fundação Japão em São Paulo Passo 3: Digitando em japonês Certifique-se de que tenha selecionado japonês na barra de idiomas. Após isso, selecione “hiragana”, como indica a seta. Passo 4: Digitando em japonês com letras romanas Uma vez que estiver no modo de entrada correto no documento, vamos digitar uma palavra prática. -

Handy Katakana Workbook.Pdf
First Edition HANDY KATAKANA WORKBOOK An Introduction to Japanese Writing: KANA THIS IS A SUPPLEMENT FOR BEGINNING LEVEL JAPANESE LANGUAGE INSTRUCTION. \ FrF!' '---~---- , - Y. M. Shimazu, Ed.D. -----~---- TABLE OF CONTENTS Page Introduction vi ACKNOWLEDGEMENlS vii STUDYSHEET#l 1 A,I,U,E, 0, KA,I<I, KU,KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #1 2 PRACTICE: A, I,U, E, 0, KA,KI, KU,KE, KO, GA,GI,GU, GE,GO, N WORKSHEET #2 3 MORE PRACTICE: A, I, U, E,0, KA,KI,KU, KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #~3 4 ADDmONAL PRACTICE: A,I,U, E,0, KA,KI, KU,KE, KO, GA,GI,GU,GE,GO, N STUDYSHEET #2 5 SA,SHI,SU,SE, SO, ZA,JI,ZU,ZE,ZO, TA, CHI, TSU, TE,TO, DA, DE,DO WORI<SHEEI' #4 6 PRACTICE: SA,SHI,SU,SE, SO, ZA,II, ZU,ZE,ZO, TA, CHI, 'lSU,TE,TO, OA, DE,DO WORI<SHEEI' #5 7 MORE PRACTICE: SA,SHI,SU,SE,SO, ZA,II, ZU,ZE, W, TA, CHI, TSU, TE,TO, DA, DE,DO WORKSHEET #6 8 ADDmONAL PRACI'ICE: SA,SHI,SU,SE, SO, ZA,JI, ZU,ZE,ZO, TA, CHI,TSU,TE,TO, DA, DE,DO STUDYSHEET #3 9 NA,NI, NU,NE,NO, HA, HI,FU,HE, HO, BA, BI,BU,BE,BO, PA, PI,PU,PE,PO WORKSHEET #7 10 PRACTICE: NA,NI, NU, NE,NO, HA, HI,FU,HE,HO, BA,BI, BU,BE, BO, PA, PI,PU,PE,PO WORKSHEET #8 11 MORE PRACTICE: NA,NI, NU,NE,NO, HA,HI, FU,HE, HO, BA,BI,BU,BE, BO, PA,PI,PU,PE,PO WORKSHEET #9 12 ADDmONAL PRACTICE: NA,NI, NU, NE,NO, HA, HI, FU,HE, HO, BA,BI,3U, BE, BO, PA, PI,PU,PE,PO STUDYSHEET #4 13 MA, MI,MU, ME, MO, YA, W, YO WORKSHEET#10 14 PRACTICE: MA,MI, MU,ME, MO, YA, W, YO WORKSHEET #11 15 MORE PRACTICE: MA, MI,MU,ME,MO, YA, W, YO WORKSHEET #12 16 ADDmONAL PRACTICE: MA,MI,MU, ME, MO, YA, W, YO STUDYSHEET #5 17 -

Galio Uma, Maƙerin Azurfa Maƙeri (M): Ni Ina Da Shekara Yanzu…
LANGUAGE PROGRAM, 232 BAY STATE ROAD, BOSTON, MA 02215 [email protected] www.bu.edu/Africa/alp 617.353.3673 Interview 2: Galio Uma, Maƙerin Azurfa Maƙeri (M): Ni ina da shekara yanzu…, ina da vers …alal misali vers mille neuf cent quatre vingt et quatre (1984) gare mu parce que wajenmu babu hopital lokacin da anka haihe ni ban san shekaruna ba, gaskiya. Ihehehe! Makaranta, ban yi makaranta ba sabo da an sa ni makaranta sai daga baya wajenmu babana bai da hali, mammana bai da hali sai mun biya. Akwai nisa tsakaninmu da inda muna karatu. Kilometir kama sha biyar kullum ina tahiya da ƙahwa. To, ha na gaji wani lokaci mu hau jaki, wani lokaci mu hau raƙumi, to wani lokaci ma babu hali, babu karatu. Amman na yi shekara shidda ina karatu ko biyat. Amman ban ji daɗi ba da ban yi karatu ba. Sabo da shi ne daɗin duniya. Mm. To mu Buzaye ne muna yin buzanci. Ana ce muna Tuareg. Mais Tuareg ɗin ma ba guda ba ne. Mu artisans ne zan ce miki. Can ainahinmu ma ba mu da wani aiki sai ƙira. Duka mutanena suna can Abala. Nan ga ni dai na nan ga. Ka gani ina da mata, ina da yaro. Akwai babana, akwai mammana. Ina da ƙanne huɗu, macce biyu da namiji biyu. Suna duka cikin gida. Duka kuma kama ni ne chef de famille. Duka ni ne ina aider ɗinsu. Sabo da babana yana da shekara saba’in da biyar. Vers. Mammana yana da shekara shi ma hamsin da biyar. -
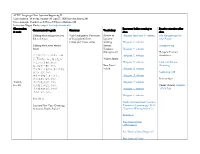
ALTEC Language Class: Japanese Beginning II
ALTEC Language Class: Japanese Beginning II Class duration: 10 weeks, January 28–April 7, 2020 (no class March 24) Class meetings: Tuesdays at 5:30pm–7:30pm in Hellems 145 Instructor: Megan Husby, [email protected] Class session Resources before coming to Practice exercises after Communicative goals Grammar Vocabulary & topic class class Talking about things that you Verb Conjugation: Past tense Review of Hiragana Intro and あ column Fun Hiragana app for did in the past of long (polite) forms Japanese your Phone (~desu and ~masu verbs) Writing Hiragana か column Talking about your winter System: Hiragana song break Hiragana Hiragana さ column (Recognition) Hiragana Practice クリスマス・ハヌカー・お Hiragana た column Worksheet しょうがつ 正月はなにをしましたか。 Winter Sports どこにいきましたか。 Hiragana な column Grammar Review なにをたべましたか。 New Year’s (Listening) プレゼントをかいましたか/ Vocab Hiragana は column もらいましたか。 Genki I pg. 110 スポーツをしましたか。 Hiragana ま column だれにあいましたか。 Practice Quiz Week 1, えいがをみましたか。 Hiragana や column Jan. 28 ほんをよみましたか。 Omake (bonus): Kasajizō: うたをききましたか/ Hiragana ら column A Folk Tale うたいましたか。 Hiragana わ column Particle と Genki: An Integrated Course in Japanese New Year (Greetings, Elementary Japanese pgs. 24-31 Activities, Foods, Zodiac) (“Japanese Writing System”) Particle と Past Tense of desu (Affirmative) Past Tense of desu (Negative) Past Tense of Verbs Discussing family, pets, objects, Verbs for being (aru and iru) Review of Katakana Intro and ア column Katakana Practice possessions, etc. Japanese Worksheet Counters for people, animals, Writing Katakana カ column etc. System: Genki I pgs. 107-108 Katakana Katakana サ column (Recognition) Practice Quiz Katakana タ column Counters Katakana ナ column Furniture and common Katakana ハ column household items Katakana マ column Katakana ヤ column Katakana ラ column Week 2, Feb. -
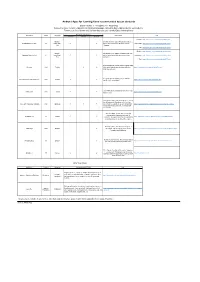
Android Apps for Learning Kana Recommended by Our Students
Android Apps for learning Kana recommended by our students [Kana column: H = Hiragana, K = Katakana] Below are some recommendations for Kana learning apps, ranked in descending order by our students. Please try a few of these and find one that suits your needs. Enjoy learning Kana! Recommended Points App Name Kana Language Description Link Listening Writing Quizzes English: https://nihongo-e-na.com/android/jpn/id739.html English, Developed by the Japan Foundation and uses Hiragana Memory Hint H Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id746.html Thai Hiragana. Thai: https://nihongo-e-na.com/android/eng/id773.html English: https://nihongo-e-na.com/android/eng/id743.html English, Developed by the Japan Foundation and uses Katakana Memory Hint K Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id747.html Thai Katakana. Thai: https://nihongo-e-na.com/android/eng/id775.html A holistic app that can be used to master Kana Obenkyo H&K English 〇 〇 fully, and eventually also for other skills like https://nihongo-e-na.com/android/eng/id602.html Kanji and grammar. A very integrated quizzing system with five Kana (Hiragana and Katakana) H&K English 〇 〇 https://nihongo-e-na.com/android/jpn/id626.html varieties of tests available. Uses SRS (Spatial Repetition System) to help Kana Town H&K English 〇 〇 https://nihongo-e-na.com/android/eng/id845.html build memory. Although the app is entirely in Japanese, it only has Hiragana and Katakana so the interface Free Learn Japanese Hiragana H&K Japanese 〇 〇 〇 does not pose a problem as such. -

Na Kana Magiti Kei Na Lotu
1 NA KANA MAGITI KEI NA LOTU (Vola Tabu : Maciu 22:1-10; Luke 14:12-24) Vola ko Rev. Dr. Ilaitia S. Tuwere. Sa inaki ni vunau oqo me taroga ka sauma talega na taro : A cava na Lotu? Ni da tekivu edaidai ena noda solevu vakalotu, sa na yaga meda taroga ka tovolea talega me sauma na taro oqori. Ia, ena levu na kena isau eda na solia, me vaka na: gumatuataki ni masu kei na vulici ni Vola Tabu, bula vakayalo, muria na ivakarau se lawa ni lotu ka vuqa tale. Na veika oqori era ka dina ka tu kina eso na isau ni taro : A Cava na Lotu. Na i Vola Tabu e sega ni tuvalaka vakavosa vei keda na ibalebale ni lotu. E vakavuqa me boroya vei keda na iyaloyalo me vakadewataka kina na veika eso e vinakata me tukuna. E sega talega ni solia e duabulu ga na iyaloyalo me baleta na lotu. E vuqa sara e solia vei keda. Oqori me vaka na Qele ni Sipi kei na i Vakatawa Vinaka; na Vuni Vaini kei na Tabana; na i Vakavuvuli kei iratou na nona Gonevuli se Tisaipeli, na Masima se Rarama kei Vuravura, na Ulu kei na Vo ni Yago taucoko, ka vuqa tale. Ena mataka edaidai, meda raica vata yani na iyaloyalo ni kana magiti. E rua na kena ivakamacala eda rogoca, mai na Kosipeli i Maciu kei na nei Luke. Na kana magiti se na solevu edua na ivakarau vakaitaukei. Eda soqoni vata kina vakaveiwekani ena noda veikidavaki kei na marau, kena veitalanoa, kena sere kei na meke, kena salusalu kei na kumuni iyau. -

Writing As Aesthetic in Modern and Contemporary Japanese-Language Literature
At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2021 Reading Committee: Edward Mack, Chair Davinder Bhowmik Zev Handel Jeffrey Todd Knight Program Authorized to Offer Degree: Asian Languages and Literature ©Copyright 2021 Christopher J Lowy University of Washington Abstract At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy Chair of the Supervisory Committee: Edward Mack Department of Asian Languages and Literature This dissertation examines the dynamic relationship between written language and literary fiction in modern and contemporary Japanese-language literature. I analyze how script and narration come together to function as a site of expression, and how they connect to questions of visuality, textuality, and materiality. Informed by work from the field of textual humanities, my project brings together new philological approaches to visual aspects of text in literature written in the Japanese script. Because research in English on the visual textuality of Japanese-language literature is scant, my work serves as a fundamental first-step in creating a new area of critical interest by establishing key terms and a general theoretical framework from which to approach the topic. Chapter One establishes the scope of my project and the vocabulary necessary for an analysis of script relative to narrative content; Chapter Two looks at one author’s relationship with written language; and Chapters Three and Four apply the concepts explored in Chapter One to a variety of modern and contemporary literary texts where script plays a central role. -

'Positional Effect' on Consonant Gemination in Japanese Haruo
日本語促音の「位置効果」について On the ‘positional effect’ on consonant gemination in Japanese Haruo KUBOZONO*, Hajime TAKEYASU** and Mikio GIRIKO* *National Institute for Japanese Language and Linguistics, **Mie University Japanese loanwords from English display many interesting phenomena concerning the occurrence or non-occurrence of sokuon, or geminate obstruent. One of them concerns the so-called ‘positional effect’ by which gemination tends to restrictively occur in word-final position. One typical example is the English word picnic [piknik], which yields a geminate consonant only in the original second syllable when borrowed into Japanese: /pi.ku.nik.ku/, */pik.ku.ni.ku/, */pik.ku.nik.ku/. Other examples are given in (1) and (2). Words in (1) have a geminate obstruent, whereas those in (2) do not. (1) cap kyap.pu, dock dok.ku, mix mik.ku.su, sax sak.ku.su, box bok.ku.su, fax fak.ku.su (2) captain kya.pu.ten, doctor do.ku.taa, mixer mi.ki.saa, saxophone sa.ki.so.fon, boxer bo.ku.saa, facsimile fa.ku.si.mi.ri The primary question we would like to address in this talk is where this positional effect comes from. There are at least two possibilities. One hypothesis is that the phonological position itself is a pivotal factor to which native speakers of Japanese are sensitive. According to this hypothesis, native Japanese speakers hear a geminate consonant in word-final position, but not in other positions, for purely structural/positional reasons. Alternatively, it is possible that phonetic properties in the input English words differ between word-medial and final syllables and that native speakers of Japanese display the positional effect in question by reacting to these phonetic properties sensitively. -

AIX Globalization
AIX Version 7.1 AIX globalization IBM Note Before using this information and the product it supports, read the information in “Notices” on page 233 . This edition applies to AIX Version 7.1 and to all subsequent releases and modifications until otherwise indicated in new editions. © Copyright International Business Machines Corporation 2010, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document............................................................................................vii Highlighting.................................................................................................................................................vii Case-sensitivity in AIX................................................................................................................................vii ISO 9000.....................................................................................................................................................vii AIX globalization...................................................................................................1 What's new...................................................................................................................................................1 Separation of messages from programs..................................................................................................... 1 Conversion between code sets.............................................................................................................