Romanization of Korean
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Unicode Nearly Plain-Text Encoding of Mathematics Murray Sargent III Office Authoring Services, Microsoft Corporation 4-Apr-06
Unicode Nearly Plain Text Encoding of Mathematics Unicode Nearly Plain-Text Encoding of Mathematics Murray Sargent III Office Authoring Services, Microsoft Corporation 4-Apr-06 1. Introduction ............................................................................................................ 2 2. Encoding Simple Math Expressions ...................................................................... 3 2.1 Fractions .......................................................................................................... 4 2.2 Subscripts and Superscripts........................................................................... 6 2.3 Use of the Blank (Space) Character ............................................................... 7 3. Encoding Other Math Expressions ........................................................................ 8 3.1 Delimiters ........................................................................................................ 8 3.2 Literal Operators ........................................................................................... 10 3.3 Prescripts and Above/Below Scripts........................................................... 11 3.4 n-ary Operators ............................................................................................. 11 3.5 Mathematical Functions ............................................................................... 12 3.6 Square Roots and Radicals ........................................................................... 13 3.7 Enclosures..................................................................................................... -

End-Of-Line Hyphenation of Chemical Names (IUPAC Provisional
Pure Appl. Chem. 2020; aop IUPAC Recommendations Albert J. Dijkstra*, Karl-Heinz Hellwich, Richard M. Hartshorn, Jan Reedijk and Erik Szabó End-of-line hyphenation of chemical names (IUPAC Provisional Recommendations) https://doi.org/10.1515/pac-2019-1005 Received October 16, 2019; accepted January 21, 2020 Abstract: Chemical names and in particular systematic chemical names can be so long that, when a manu- script is printed, they have to be hyphenated/divided at the end of a line. Many systematic names already contain hyphens, but sometimes not in a suitable division position. In some cases, using these hyphens as end-of-line divisions can lead to illogical divisions in print, as can also happen when hyphens are added arbi- trarily without considering the ‘chemical’ context. The present document provides recommendations and guidelines for authors of chemical manuscripts, their publishers and editors, on where to divide chemical names at the end of a line and instructions on how to avoid these names being divided at illogical places as often suggested by desk dictionaries. Instead, readability and chemical sense should prevail when authors insert optional hyphens. Accordingly, the software used to convert electronic manuscripts to print can now be programmed to avoid illogical end-of-line hyphenation and thereby save the author much time and annoy- ance when proofreading. The recommendations also allow readers of the printed article to determine which end-of-line hyphens are an integral part of the name and should not be deleted when ‘undividing’ the name. These recommendations may also prove useful in languages other than English. -

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

Community College of Denver's Style Guide for Web and Print Publications
Community College of Denver’s Style Guide for Web and Print Publications CCD’s Style Guide supplies all CCD employees with one common goal: to create a functioning, active, and up-to-date publications with universal and consistent styling, grammar, and punctuation use. About the College-Wide Editorial Style Guide The following strategies are intended to enhance consistency and accuracy in the written communications of CCD, with particular attention to local peculiarities and frequently asked questions. For additional guidelines on the mechanics of written communication, see The AP Style Guide. If you have a question about this style guide, please contact the director of marketing and communication. Web Style Guide Page 1 of 10 Updated 2019 Contents About the College-Wide Editorial Style Guide ............................................... 1 One-Page Quick Style Guide ...................................................................... 4 Building Names ............................................................................................................. 4 Emails .......................................................................................................................... 4 Phone Numbers ............................................................................................................. 4 Academic Terms ............................................................................................................ 4 Times .......................................................................................................................... -

User Name Character Restrictions
User Name Character Restrictions • Feature Summary and Revision History, page 1 • Feature Changes, page 2 Feature Summary and Revision History Summary Data Applicable Product(s) or Functional All Area Applicable Platform(s) All Feature Default Enabled - Always-on Related Changes in This Release Not Applicable Related Documentation • System Administration Guide Revision History Note Revision history details are not provided for features introduced before releases 21.2 and N5.5. Revision Details Release User names can now only contain alphanumeric characters (a-z, A-Z, 0-9), hyphen, 21.3 underscore, and period. The hyphen character cannot be the first character. Release Change Reference, StarOS Release 21.3/Ultra Services Platform Release N5.5 1 User Name Character Restrictions Feature Changes Feature Changes Previous Behavior: User names previously could be made up of any string, including spaces within quotations. New Behavior: With this release, AAA user names and local user names can only use alphanumeric characters (a-z, A-Z, 0-9), hyphen, underscore, and period. The hyphen character cannot be the first character. If you attempt to create a user name that does not adhere to these standards, you will receive the following message: "Invalid character; legal characters are "0123456789.-_abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ". Impact on Customer: Existing customers with user names configured with special characters must re-configure those impacted users before upgrading to 21.3. Otherwise, those users will no longer be able to login after the upgade as their user name is invalid and is removed from the user database. Release Change Reference, StarOS Release 21.3/Ultra Services Platform Release N5.5 2. -
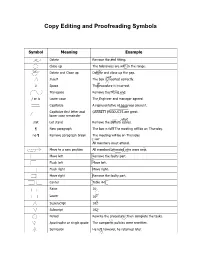
Copy Editing and Proofreading Symbols
Copy Editing and Proofreading Symbols Symbol Meaning Example Delete Remove the end fitting. Close up The tolerances are with in the range. Delete and Close up Deltete and close up the gap. not Insert The box is inserted correctly. # # Space Theprocedure is incorrect. Transpose Remove the fitting end. / or lc Lower case The Engineer and manager agreed. Capitalize A representative of nasa was present. Capitalize first letter and GARRETT PRODUCTS are great. lower case remainder stet stet Let stand Remove the battery cables. ¶ New paragraph The box is full. The meeting will be on Thursday. no ¶ Remove paragraph break The meeting will be on Thursday. no All members must attend. Move to a new position All members attended who were new. Move left Remove the faulty part. Flush left Move left. Flush right Move right. Move right Remove the faulty part. Center Table 4-1 Raise 162 Lower 162 Superscript 162 Subscript 162 . Period Rewrite the procedure. Then complete the tasks. ‘ ‘ Apostrophe or single quote The companys policies were rewritten. ; Semicolon He left however, he returned later. ; Symbol Meaning Example Colon There were three items nuts, bolts, and screws. : : , Comma Apply pressure to the first second and third bolts. , , -| Hyphen A valuable byproduct was created. sp Spell out The info was incorrect. sp Abbreviate The part was twelve feet long. || or = Align Personnel Facilities Equipment __________ Underscore The part was listed under Electrical. Run in with previous line He rewrote the pages and went home. Em dash It was the beginning so I thought. En dash The value is 120 408. -

Classifying Type Thunder Graphics Training • Type Workshop Typeface Groups
Classifying Type Thunder Graphics Training • Type Workshop Typeface Groups Cla sifying Type Typeface Groups The typefaces you choose can make or break a layout or design because they set the tone of the message.Choosing The the more right you font know for the about job is type, an important the better design your decision.type choices There will are be. so many different fonts available for the computer that it would be almost impossible to learn the names of every one. However, manys typefaces share similar qualities. Typographers classify fonts into groups to help Typographers classify type into groups to help remember the different kinds. Often, a font from within oneremember group can the be different substituted kinds. for Often, one nota font available from within to achieve one group the samecan be effect. substituted Different for anothertypographers usewhen different not available groupings. to achieve The classifi the samecation effect. system Different used by typographers Thunder Graphics use different includes groups. seven The major groups.classification system used byStevenson includes seven major groups. Use the Right arrow key to move to the next page. • Use the Left arrow key to move back a page. Use the key combination, Command (⌘) + Q to quit the presentation. Thunder Graphics Training • Type Workshop Typeface Groups ����������������������� ��������������������������������������������������������������������������������� ���������������������������������������������������������������������������� ������������������������������������������������������������������������������ -

Romanization Examples
Romanization examples Each title of a language or a writing system is followed by a note on the appropriate romanization system used (UN = United Nations, BGN/PCGN = US Board on Geographic Names and Permanent Committee on Geographical Names for British Official Use) Amharic [UN 1967, I/17] Lao [national 1966] ኢትዮጵያ Ityop’ya [ Ethiopia ], አዲስ አበባ Addis Abe ̱ ba ລາວ Lao [ Laos ], ວງຈັ ນ Viangchan Arabic [UN 1972, II/8] Macedonian Cyrillic [UN 1977, III/11] Jaz īrat al-‘Arab [ Arabian Peninsula ] Скопје Skopje, Битола Bitola ز رة ارب Armenian [BGN/PCGN 1981] Malayalam [UN 1972, II/11; 1977, III/12] Հայաստան Hayastan [ Armenia ], Երևան Yerevan Kera ḷaṁ, Tiruvanantapura ṁ Assamese [UN 1972, II/11; 1977, III/12] Maldivian [national 1987] Asam [ Assam ], Dichhapura [ Dispur ] ޖ އ ރ ހ ވ ދ Dhivehi Raajje [ Maldives ], ލ މ Maale Bengali [UN 1972, II/11; 1977, III/12] Marathi [UN 1972, II/11; 1977, III/12] Bāṁ lādesh, Dhaka महारा Mah ārāṣhṭra, मुंबई Mu ṁba ī Bulgarian [UN 1977, III/10] Mongolian (Cyrillic) [BGN/PCGN 1964] Република България Republika B ǎlgarija Монгол улс Mongol uls, Улаанбаатар Ulaanbaatar Burmese [BGN/PCGN 1970] Nepalese [UN 1972, II/11; 1977, III/12] ြမန်မာ Myanma, ရန်ကန် Yangôn नेपाल Nepāl, काठमाड Kāṭhm āḍau ṁ [Kathmandu ] Byelorussian [national 2007] Беларусь Bielaru ś, Минск Minsk Oriya [UN 1972, II/11; 1977, III/12] Chinese [UN 1977, III/8] Oṙish ā, Bhubaneshbar 中国 Zhongguo, 北京 Beijing Pashto [BGN/PCGN 1968] XQY Kābulل ,Afgh ānist ān اQRSTQUVن [Dzongkha [national 1997 འག་ལ Drukyuel [Bhutan ], ཐིམ་ Thimphu Persian -

Korean Romanization
Checked for validity and accuracy – October 2017 ROMANIZATION OF KOREAN FOR THE DEMOCRATIC PEOPLE’S REPUBLIC OF KOREA McCune-Reischauer System (with minor modifications) BGN/PCGN 1945 Agreement This system for romanizing Korean was devised by G.M. McCune and E.O. Reischauer, and was originally published in the Transactions of the Korea Branch of the Royal Asiatic Society, Volume XXIX, 1939. It has been used by the BGN since 1943, and was later adopted for use by the PCGN. Until 2011 it was used by BGN and PCGN for the romanization of Korean geographical names in Korea as a whole. In 2011 BGN and PCGN approved the use of the Republic of Korea’s national system (created by the ROK’s Ministry of Culture and Tourism in 2000) for the romanization of Korean in the Republic of Korea only. As of 2011, therefore, this McCune-Reischauer system is used by BGN and PCGN only for the romanization of geographical names in the Democratic People’s Republic of Korea. A main characteristic of this system is the attempt to represent approximate Korean pronunciation, while systematically converting the han’gŭl characters to corresponding Roman-script letters. Since Korean pronunciation is often inconsistently represented in han’gŭl, the McCune-Reischauer conversion tables are rather elaborate, and reverse conversion (from Roman-script back to han’gŭl) presents varied difficulties. Since the McCune-Reischauer system was first introduced, there have been a number of orthographical developments in Korean, giving rise to han’gŭl letter combinations not addressed by the original system. These additional graphic environments have been assessed, and are addressed here. -

Inventory of Romanization Tools
Inventory of Romanization Tools Standards Intellectual Management Office Library and Archives Canad Ottawa 2006 Inventory of Romanization Tools page 1 Language Script Romanization system for an English Romanization system for a French Alternate Romanization system catalogue catalogue Amharic Ethiopic ALA-LC 1997 BGN/PCGN 1967 UNGEGN 1967 (I/17). http://www.eki.ee/wgrs/rom1_am.pdf Arabic Arabic ALA-LC 1997 ISO 233:1984.Transliteration of Arabic BGN/PCGN 1956 characters into Latin characters NLC COPIES: BS 4280:1968. Transliteration of Arabic characters NL Stacks - TA368 I58 fol. no. 00233 1984 E DMG 1936 NL Stacks - TA368 I58 fol. no. DIN-31635, 1982 00233 1984 E - Copy 2 I.G.N. System 1973 (also called Variant B of the Amended Beirut System) ISO 233-2:1993. Transliteration of Arabic characters into Latin characters -- Part 2: Lebanon national system 1963 Arabic language -- Simplified transliteration Morocco national system 1932 Royal Jordanian Geographic Centre (RJGC) System Survey of Egypt System (SES) UNGEGN 1972 (II/8). http://www.eki.ee/wgrs/rom1_ar.pdf Update, April 2004: http://www.eki.ee/wgrs/ung22str.pdf Armenian Armenian ALA-LC 1997 ISO 9985:1996. Transliteration of BGN/PCGN 1981 Armenian characters into Latin characters Hübschmann-Meillet. Assamese Bengali ALA-LC 1997 ISO 15919:2001. Transliteration of Hunterian System Devanagari and related Indic scripts into Latin characters UNGEGN 1977 (III/12). http://www.eki.ee/wgrs/rom1_as.pdf 14/08/2006 Inventory of Romanization Tools page 2 Language Script Romanization system for an English Romanization system for a French Alternate Romanization system catalogue catalogue Azerbaijani Arabic, Cyrillic ALA-LC 1997 ISO 233:1984.Transliteration of Arabic characters into Latin characters. -

Task Force for the Review of the Romanization of Greek RE: Report of the Task Force
CC:DA/TF/ Review of the Romanization of Greek/3 Report, May 18, 2010 page: 1 TO: ALA/ALCTS/CCS/Committee on Cataloging: Description and Access (CC:DA) FROM: ALA/ALCTS/CCS/CC:DA Task Force for the Review of the Romanization of Greek RE: Report of the Task Force CHARGE TO THE TASK FORCE The Task Force is charged with assessing draft Romanization tables for Greek, educating CC:DA as necessary, and preparing necessary reports to support the revision process, leading to ultimate approval of an updated ALA-LC Romanization scheme for Greek. In particular, the Task Force should review the May 2010 draft for a timely report by ALA to LC. Review of subsequent tables may be called for, depending on the viability of this latest draft. The ALA-LC Romanization table - Greek, Proposed Revision May 2010 is located at the LC Policy and Standards Division website at: http://www.loc.gov/catdir/cpso/romanization/greekrev.pdf [archived as a supplement to this report on the CC:DA site] BACKGROUND INFORMATION FROM THE LIBRARY OF CONGRESS We note that when the May 2010 Greek table was presented for general review via email, the LC Policy and Standards Division offered the following information comparing the May 2010 table with the existing table, Greek (Also Coptic), available at the LC policy and Standards Division web site at: http://www.loc.gov/catdir/cpso/romanization/greek.pdf: "The Policy and Standards Division has taken another look at the revised Greek Romanization tables in conjunction with comments from the library community and its own staff with knowledge of Greek. -

Learn to Read Korean: an Introduction to the Hangul Alphabet* Z
Proceedings of IPAC2016, Busan, Korea THEA01 LEARN TO READ KOREAN: AN INTRODUCTION TO THE HANGUL ALPHABET* Z. Handel†, University of Washington, Seattle, USA Abstract Here, for example, is the graph writing the word mǎ In the mid 15th century the Korean scholar-king Sejong meaning ‘horse’. invented Hangul, the native Korean alphabet. This was the beginning of a long process by which Hangul gradual- ly supplanted Chinese characters as Korea's primary writ- Figure 1: Oracle bone character for ‘horse’. ing system, a process which is still ongoing but nearly It’s sideways, but otherwise quite recognizable: we can complete today. This presentation will introduce the his- see the mouth, the eye, the mane, two legs, and a tail. torical and cultural background behind the invention of Here’s the modern form. Hangul and describe the systematic linguistic principles on which the script is based. The 1446 text that intro- duced Hangul proclaimed that it was so simple that “a Figure 2: Modern character for ‘horse’. wise man can master it in a morning, and even a stupid By the fourth century, Chinese characters had essential- person can learn it in ten days.” In this presentation we ly reached their modern form. As you can see, they have put this claim to the test by attempting to learn to read become highly stylized and conventionalized, losing their Korean in under an hour. pictographic quality. INTRODUCTION Early Korean Writing If you leave the convention center where IPAC’16 is It was this type of writing that was first encountered by held and have a chance to look around during your stay in the Koreans, as the expanding Chinese empire moved into Korea—you will everywhere see the Korean alphabet, an the Korean peninsula.