Unicode Nearly Plain-Text Encoding of Mathematics Murray Sargent III Office Authoring Services, Microsoft Corporation 4-Apr-06
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Origins of the Underline As Visual Representation of the Hyperlink on the Web: a Case Study in Skeuomorphism
The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Romano, John J. 2016. The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism. Master's thesis, Harvard Extension School. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:33797379 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism John J Romano A Thesis in the Field of Visual Arts for the Degree of Master of Liberal Arts in Extension Studies Harvard University November 2016 Abstract This thesis investigates the process by which the underline came to be used as the default signifier of hyperlinks on the World Wide Web. Created in 1990 by Tim Berners- Lee, the web quickly became the most used hypertext system in the world, and most browsers default to indicating hyperlinks with an underline. To answer the question of why the underline was chosen over competing demarcation techniques, the thesis applies the methods of history of technology and sociology of technology. Before the invention of the web, the underline–also known as the vinculum–was used in many contexts in writing systems; collecting entities together to form a whole and ascribing additional meaning to the content. -

Supreme Court of the State of New York Appellate Division: Second Judicial Department
Supreme Court of the State of New York Appellate Division: Second Judicial Department A GLOSSARY OF TERMS FOR FORMATTING COMPUTER-GENERATED BRIEFS, WITH EXAMPLES The rules concerning the formatting of briefs are contained in CPLR 5529 and in § 1250.8 of the Practice Rules of the Appellate Division. Those rules cover technical matters and therefore use certain technical terms which may be unfamiliar to attorneys and litigants. The following glossary is offered as an aid to the understanding of the rules. Typeface: A typeface is a complete set of characters of a particular and consistent design for the composition of text, and is also called a font. Typefaces often come in sets which usually include a bold and an italic version in addition to the basic design. Proportionally Spaced Typeface: Proportionally spaced type is designed so that the amount of horizontal space each letter occupies on a line of text is proportional to the design of each letter, the letter i, for example, being narrower than the letter w. More text of the same type size fits on a horizontal line of proportionally spaced type than a horizontal line of the same length of monospaced type. This sentence is set in Times New Roman, which is a proportionally spaced typeface. Monospaced Typeface: In a monospaced typeface, each letter occupies the same amount of space on a horizontal line of text. This sentence is set in Courier, which is a monospaced typeface. Point Size: A point is a unit of measurement used by printers equal to approximately 1/72 of an inch. -

End-Of-Line Hyphenation of Chemical Names (IUPAC Provisional
Pure Appl. Chem. 2020; aop IUPAC Recommendations Albert J. Dijkstra*, Karl-Heinz Hellwich, Richard M. Hartshorn, Jan Reedijk and Erik Szabó End-of-line hyphenation of chemical names (IUPAC Provisional Recommendations) https://doi.org/10.1515/pac-2019-1005 Received October 16, 2019; accepted January 21, 2020 Abstract: Chemical names and in particular systematic chemical names can be so long that, when a manu- script is printed, they have to be hyphenated/divided at the end of a line. Many systematic names already contain hyphens, but sometimes not in a suitable division position. In some cases, using these hyphens as end-of-line divisions can lead to illogical divisions in print, as can also happen when hyphens are added arbi- trarily without considering the ‘chemical’ context. The present document provides recommendations and guidelines for authors of chemical manuscripts, their publishers and editors, on where to divide chemical names at the end of a line and instructions on how to avoid these names being divided at illogical places as often suggested by desk dictionaries. Instead, readability and chemical sense should prevail when authors insert optional hyphens. Accordingly, the software used to convert electronic manuscripts to print can now be programmed to avoid illogical end-of-line hyphenation and thereby save the author much time and annoy- ance when proofreading. The recommendations also allow readers of the printed article to determine which end-of-line hyphens are an integral part of the name and should not be deleted when ‘undividing’ the name. These recommendations may also prove useful in languages other than English. -

Community College of Denver's Style Guide for Web and Print Publications
Community College of Denver’s Style Guide for Web and Print Publications CCD’s Style Guide supplies all CCD employees with one common goal: to create a functioning, active, and up-to-date publications with universal and consistent styling, grammar, and punctuation use. About the College-Wide Editorial Style Guide The following strategies are intended to enhance consistency and accuracy in the written communications of CCD, with particular attention to local peculiarities and frequently asked questions. For additional guidelines on the mechanics of written communication, see The AP Style Guide. If you have a question about this style guide, please contact the director of marketing and communication. Web Style Guide Page 1 of 10 Updated 2019 Contents About the College-Wide Editorial Style Guide ............................................... 1 One-Page Quick Style Guide ...................................................................... 4 Building Names ............................................................................................................. 4 Emails .......................................................................................................................... 4 Phone Numbers ............................................................................................................. 4 Academic Terms ............................................................................................................ 4 Times .......................................................................................................................... -

User Name Character Restrictions
User Name Character Restrictions • Feature Summary and Revision History, page 1 • Feature Changes, page 2 Feature Summary and Revision History Summary Data Applicable Product(s) or Functional All Area Applicable Platform(s) All Feature Default Enabled - Always-on Related Changes in This Release Not Applicable Related Documentation • System Administration Guide Revision History Note Revision history details are not provided for features introduced before releases 21.2 and N5.5. Revision Details Release User names can now only contain alphanumeric characters (a-z, A-Z, 0-9), hyphen, 21.3 underscore, and period. The hyphen character cannot be the first character. Release Change Reference, StarOS Release 21.3/Ultra Services Platform Release N5.5 1 User Name Character Restrictions Feature Changes Feature Changes Previous Behavior: User names previously could be made up of any string, including spaces within quotations. New Behavior: With this release, AAA user names and local user names can only use alphanumeric characters (a-z, A-Z, 0-9), hyphen, underscore, and period. The hyphen character cannot be the first character. If you attempt to create a user name that does not adhere to these standards, you will receive the following message: "Invalid character; legal characters are "0123456789.-_abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ". Impact on Customer: Existing customers with user names configured with special characters must re-configure those impacted users before upgrading to 21.3. Otherwise, those users will no longer be able to login after the upgade as their user name is invalid and is removed from the user database. Release Change Reference, StarOS Release 21.3/Ultra Services Platform Release N5.5 2. -
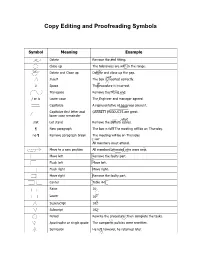
Copy Editing and Proofreading Symbols
Copy Editing and Proofreading Symbols Symbol Meaning Example Delete Remove the end fitting. Close up The tolerances are with in the range. Delete and Close up Deltete and close up the gap. not Insert The box is inserted correctly. # # Space Theprocedure is incorrect. Transpose Remove the fitting end. / or lc Lower case The Engineer and manager agreed. Capitalize A representative of nasa was present. Capitalize first letter and GARRETT PRODUCTS are great. lower case remainder stet stet Let stand Remove the battery cables. ¶ New paragraph The box is full. The meeting will be on Thursday. no ¶ Remove paragraph break The meeting will be on Thursday. no All members must attend. Move to a new position All members attended who were new. Move left Remove the faulty part. Flush left Move left. Flush right Move right. Move right Remove the faulty part. Center Table 4-1 Raise 162 Lower 162 Superscript 162 Subscript 162 . Period Rewrite the procedure. Then complete the tasks. ‘ ‘ Apostrophe or single quote The companys policies were rewritten. ; Semicolon He left however, he returned later. ; Symbol Meaning Example Colon There were three items nuts, bolts, and screws. : : , Comma Apply pressure to the first second and third bolts. , , -| Hyphen A valuable byproduct was created. sp Spell out The info was incorrect. sp Abbreviate The part was twelve feet long. || or = Align Personnel Facilities Equipment __________ Underscore The part was listed under Electrical. Run in with previous line He rewrote the pages and went home. Em dash It was the beginning so I thought. En dash The value is 120 408. -

Classifying Type Thunder Graphics Training • Type Workshop Typeface Groups
Classifying Type Thunder Graphics Training • Type Workshop Typeface Groups Cla sifying Type Typeface Groups The typefaces you choose can make or break a layout or design because they set the tone of the message.Choosing The the more right you font know for the about job is type, an important the better design your decision.type choices There will are be. so many different fonts available for the computer that it would be almost impossible to learn the names of every one. However, manys typefaces share similar qualities. Typographers classify fonts into groups to help Typographers classify type into groups to help remember the different kinds. Often, a font from within oneremember group can the be different substituted kinds. for Often, one nota font available from within to achieve one group the samecan be effect. substituted Different for anothertypographers usewhen different not available groupings. to achieve The classifi the samecation effect. system Different used by typographers Thunder Graphics use different includes groups. seven The major groups.classification system used byStevenson includes seven major groups. Use the Right arrow key to move to the next page. • Use the Left arrow key to move back a page. Use the key combination, Command (⌘) + Q to quit the presentation. Thunder Graphics Training • Type Workshop Typeface Groups ����������������������� ��������������������������������������������������������������������������������� ���������������������������������������������������������������������������� ������������������������������������������������������������������������������ -

5 the Rules of Typography
The Rules of Typography Typographic Terminology THE RULES OF TYPOGRAPHY Typographic Terminology TYPEFACE VS. FONT: Two Definitions Typeface Font THE FULL FAMILY vs. ONE WEIGHT A full family of fonts A member of a typeface family example: Helvetica Neue example: Helvetica Neue Bold THE DESIGN vs. THE DIGITAL FILE The intellectual property created A digital file of a typeface by a type designer THE RULES OF TYPOGRAPHY Typographic Terminology LEADING 16/20 16/29 “In a badly designed book, the letters “In a badly designed book, the letters Leading refers to the amount of space mill and stand like starving horses in a mill and stand like starving horses in a between lines of type using points as field. In a book designed by rote, they the measurement. The name was sit like stale bread and mutton on field. In a book designed by rote, they derived from the strips of lead that the page. In a well-made book, where sit like stale bread and mutton on were used during the typesetting designer, compositor and printer have process to create the space. Now we all done their jobs, no matter how the page. In a well-made book, where perform this digitally—also with many thousands of lines and pages, the designer, compositor and printer have consideration to the optimal setting letters are alive. They dance in their for any particular typeface. seats. Sometimes they rise and dance all done their jobs, no matter how When speaking about leading we in the margins and aisles.” many thousands of lines and pages, the first say the type size “on” the leading. -

Book Typography 101 at the End of This Session, Participants Should Be Able To: 1
3/21/2016 Objectives Book Typography 101 At the end of this session, participants should be able to: 1. Evaluate typeset pages for adherence Dick Margulis to traditional standards of good composition 2. Make sensible design recommendations to clients based on readability of text and clarity of communication © 2013–2016 Dick Margulis Creative Services © 2013–2016 Dick Margulis Creative Services What is typography? Typography encompasses • The design and layout of the printed or virtual page • The selection of fonts • The specification of typesetting variables • The actual composition of text © 2013–2016 Dick Margulis Creative Services © 2013–2016 Dick Margulis Creative Services What is typography? What is typography? The goal of good typography is to allow Typography that intrudes its own cleverness the unencumbered communication and interferes with the dialogue of the author’s meaning to the reader. between author and reader is almost always inappropriate. Assigned reading: “The Crystal Goblet,” by Beatrice Ward http://www.arts.ucsb.edu/faculty/reese/classes/artistsbooks/Beatrice%20Warde,%20The%20Crystal%20Goblet.pdf (or just google it) © 2013–2016 Dick Margulis Creative Services © 2013–2016 Dick Margulis Creative Services 1 3/21/2016 How we read The basics • Saccades • Page size and margins The quick brown fox jumps over the lazy dog. Mary had a little lamb, a little bread, a little jam. • Line length and leading • Boules • Justification My very educated mother just served us nine. • Typeface My very educated mother just served us nine. -

Lesson 3 8,UNBELIEVABLE60 HE SAYS4
L 3 Qotatio M, A, Pnt, S B, O, L L (U), Ssh Now learn the following additional punctuation signs: apostrophe ’ [or] ' ' (dot 3) opening one-cell (non-specific) quotation mark 8 (dots 236) closing one-cell (non-specific) quotation mark 0 (dots 356) opening single quotation mark ‘ [or] ' ,8 (dots 6, 236) closing single quotation mark ’ [or] ' ,0 (dots 6, 356) opening parenthesis ( "< (dots 5, 126) closing parenthesis ) "> (dots 5, 345) opening square bracket [ .< (dots 46, 126) (dots 46, 345) closing square bracket ] .> 3.1 S D Qotatio M [UEB §7.6] In braille, there are several different symbols to represent the various types of print quotation marks (additional information about quotation marks will be studied in Lesson 16). In most cases, the opening and clo one- (-ecific) tatio marks should be used to represent the primary or outer quotation marks in the text, and the two- cell opening and closing single quotation marks should represent the inner quotation marks. Examples: "Unbelievable!" he says. 8,BEIEABE60 HE A4 "I only wrote 'come home soon'," he claims. 3 - 1 8,I E ,8CE HE ,010 HE CAI4 3.2 Arop Follow print for the use of apostrophes. Example: "Tell 'em Sam's favorite music is new—1990's too old." 8,E 'E ,A' FAIE IC I E,-#AIIJ' D40 3.2 A api lette. A capital indicator is always placed immediately before the letter to which it applies. Therefore, if an apostrophe comes before a capital letter in print, the apostrophe is brailled before the capital indicator. Example: "'Twas a brilliant plan," says Dan O'Reilly. -

List of Approved Special Characters
List of Approved Special Characters The following list represents the Graduate Division's approved character list for display of dissertation titles in the Hooding Booklet. Please note these characters will not display when your dissertation is published on ProQuest's site. To insert a special character, simply hold the ALT key on your keyboard and enter in the corresponding code. This is only for entering in a special character for your title or your name. The abstract section has different requirements. See abstract for more details. Special Character Alt+ Description 0032 Space ! 0033 Exclamation mark '" 0034 Double quotes (or speech marks) # 0035 Number $ 0036 Dollar % 0037 Procenttecken & 0038 Ampersand '' 0039 Single quote ( 0040 Open parenthesis (or open bracket) ) 0041 Close parenthesis (or close bracket) * 0042 Asterisk + 0043 Plus , 0044 Comma ‐ 0045 Hyphen . 0046 Period, dot or full stop / 0047 Slash or divide 0 0048 Zero 1 0049 One 2 0050 Two 3 0051 Three 4 0052 Four 5 0053 Five 6 0054 Six 7 0055 Seven 8 0056 Eight 9 0057 Nine : 0058 Colon ; 0059 Semicolon < 0060 Less than (or open angled bracket) = 0061 Equals > 0062 Greater than (or close angled bracket) ? 0063 Question mark @ 0064 At symbol A 0065 Uppercase A B 0066 Uppercase B C 0067 Uppercase C D 0068 Uppercase D E 0069 Uppercase E List of Approved Special Characters F 0070 Uppercase F G 0071 Uppercase G H 0072 Uppercase H I 0073 Uppercase I J 0074 Uppercase J K 0075 Uppercase K L 0076 Uppercase L M 0077 Uppercase M N 0078 Uppercase N O 0079 Uppercase O P 0080 Uppercase -

Generating Postscript Names for Fonts Using Opentype Font Variations
bc Adobe Enterprise & Developer Support Adobe Technical Note #5902 Generating PostScript Names for Fonts Using OpenType Font Variations Version 1.0, September 14 2016 1 Introduction This document specifies how to generate PostScript names for OpenType variable font instances. Please see the OpenType specification chapter, OpenType Font Variations Overview for an overview of variable fonts and related terms, and the chapter fvar - Font Variations Table for the terms specific to this discussion. The ‘fvar’ table optionally allows for PostScript names for named instances of an OpenType variations fonts to be specified. However, the PostScript names for named instances may be omitted, and there is no mechanism to provide a PostScript name for instances at arbitrary points in the variable font design space. This document describes how to generate PostScript names for such cases. This is useful in several workflows. For the foreseeable future, arbitrary instances of a variable font must be exported as a non- variable font for legacy applications and for printing: a PostScript name is required for this. The primary goal of the document is to provide a standard method for providing human readable PostScript names, using the instance font design space coordinates and axis tags. A secondary goal is to allow the PostScript name for a variable font instance to be used as a font reference, such that the design space coordinates of the instance can be recovered from the PostScript name. However, a descriptive PostScript name is possible only for a limited number of design axes, and some fonts may exceed this. For such fonts, a last resort method is described which serves the purpose of generating a PostScript name, but without semantic content.