Types of Epidemiologic Studies
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction to Biostatistics
Introduction to Biostatistics Jie Yang, Ph.D. Associate Professor Department of Family, Population and Preventive Medicine Director Biostatistical Consulting Core Director Biostatistics and Bioinformatics Shared Resource, Stony Brook Cancer Center In collaboration with Clinical Translational Science Center (CTSC) and the Biostatistics and Bioinformatics Shared Resource (BB-SR), Stony Brook Cancer Center (SBCC). OUTLINE What is Biostatistics What does a biostatistician do • Experiment design, clinical trial design • Descriptive and Inferential analysis • Result interpretation What you should bring while consulting with a biostatistician WHAT IS BIOSTATISTICS • The science of (bio)statistics encompasses the design of biological/clinical experiments the collection, summarization, and analysis of data from those experiments the interpretation of, and inference from, the results How to Lie with Statistics (1954) by Darrell Huff. http://www.youtube.com/watch?v=PbODigCZqL8 GOAL OF STATISTICS Sampling POPULATION Probability SAMPLE Theory Descriptive Descriptive Statistics Statistics Inference Population Sample Parameters: Inferential Statistics Statistics: 흁, 흈, 흅… 푿ഥ , 풔, 풑ෝ,… PROPERTIES OF A “GOOD” SAMPLE • Adequate sample size (statistical power) • Random selection (representative) Sampling Techniques: 1.Simple random sampling 2.Stratified sampling 3.Systematic sampling 4.Cluster sampling 5.Convenience sampling STUDY DESIGN EXPERIEMENT DESIGN Completely Randomized Design (CRD) - Randomly assign the experiment units to the treatments -
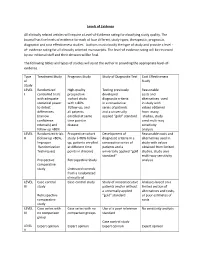
Levels of Evidence Table
Levels of Evidence All clinically related articles will require a Level-of-Evidence rating for classifying study quality. The Journal has five levels of evidence for each of four different study types; therapeutic, prognostic, diagnostic and cost effectiveness studies. Authors must classify the type of study and provide a level - of- evidence rating for all clinically oriented manuscripts. The level-of evidence rating will be reviewed by our editorial staff and their decision will be final. The following tables and types of studies will assist the author in providing the appropriate level-of- evidence. Type Treatment Study Prognosis Study Study of Diagnostic Test Cost Effectiveness of Study Study LEVEL Randomized High-quality Testing previously Reasonable I controlled trials prospective developed costs and with adequate cohort study diagnostic criteria alternatives used statistical power with > 80% in a consecutive in study with to detect follow-up, and series of patients values obtained differences all patients and a universally from many (narrow enrolled at same applied “gold” standard studies, study confidence time point in used multi-way intervals) and disease sensitivity follow up >80% analysis LEVEL Randomized trials Prospective cohort Development of Reasonable costs and II (follow up <80%, study (<80% follow- diagnostic criteria in a alternatives used in Improper up, patients enrolled consecutive series of study with values Randomization at different time patients and a obtained from limited Techniques) points in disease) universally -

Experimentation Science: a Process Approach for the Complete Design of an Experiment
Kansas State University Libraries New Prairie Press Conference on Applied Statistics in Agriculture 1996 - 8th Annual Conference Proceedings EXPERIMENTATION SCIENCE: A PROCESS APPROACH FOR THE COMPLETE DESIGN OF AN EXPERIMENT D. D. Kratzer K. A. Ash Follow this and additional works at: https://newprairiepress.org/agstatconference Part of the Agriculture Commons, and the Applied Statistics Commons This work is licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works 4.0 License. Recommended Citation Kratzer, D. D. and Ash, K. A. (1996). "EXPERIMENTATION SCIENCE: A PROCESS APPROACH FOR THE COMPLETE DESIGN OF AN EXPERIMENT," Conference on Applied Statistics in Agriculture. https://doi.org/ 10.4148/2475-7772.1322 This is brought to you for free and open access by the Conferences at New Prairie Press. It has been accepted for inclusion in Conference on Applied Statistics in Agriculture by an authorized administrator of New Prairie Press. For more information, please contact [email protected]. Conference on Applied Statistics in Agriculture Kansas State University Applied Statistics in Agriculture 109 EXPERIMENTATION SCIENCE: A PROCESS APPROACH FOR THE COMPLETE DESIGN OF AN EXPERIMENT. D. D. Kratzer Ph.D., Pharmacia and Upjohn Inc., Kalamazoo MI, and K. A. Ash D.V.M., Ph.D., Town and Country Animal Hospital, Charlotte MI ABSTRACT Experimentation Science is introduced as a process through which the necessary steps of experimental design are all sufficiently addressed. Experimentation Science is defined as a nearly linear process of objective formulation, selection of experimentation unit and decision variable(s), deciding treatment, design and error structure, defining the randomization, statistical analyses and decision procedures, outlining quality control procedures for data collection, and finally analysis, presentation and interpretation of results. -

The Magic of Randomization Versus the Myth of Real-World Evidence
The new england journal of medicine Sounding Board The Magic of Randomization versus the Myth of Real-World Evidence Rory Collins, F.R.S., Louise Bowman, M.D., F.R.C.P., Martin Landray, Ph.D., F.R.C.P., and Richard Peto, F.R.S. Nonrandomized observational analyses of large safety and efficacy because the potential biases electronic patient databases are being promoted with respect to both can be appreciable. For ex- as an alternative to randomized clinical trials as ample, the treatment that is being assessed may a source of “real-world evidence” about the effi- well have been provided more or less often to cacy and safety of new and existing treatments.1-3 patients who had an increased or decreased risk For drugs or procedures that are already being of various health outcomes. Indeed, that is what used widely, such observational studies may in- would be expected in medical practice, since both volve exposure of large numbers of patients. the severity of the disease being treated and the Consequently, they have the potential to detect presence of other conditions may well affect the rare adverse effects that cannot plausibly be at- choice of treatment (often in ways that cannot be tributed to bias, generally because the relative reliably quantified). Even when associations of risk is large (e.g., Reye’s syndrome associated various health outcomes with a particular treat- with the use of aspirin, or rhabdomyolysis as- ment remain statistically significant after adjust- sociated with the use of statin therapy).4 Non- ment for all the known differences between pa- randomized clinical observation may also suf- tients who received it and those who did not fice to detect large beneficial effects when good receive it, these adjusted associations may still outcomes would not otherwise be expected (e.g., reflect residual confounding because of differ- control of diabetic ketoacidosis with insulin treat- ences in factors that were assessed only incom- ment, or the rapid shrinking of tumors with pletely or not at all (and therefore could not be chemotherapy). -

(Meta-Analyses of Observational Studies in Epidemiology) Checklist
MOOSE (Meta-analyses Of Observational Studies in Epidemiology) Checklist A reporting checklist for Authors, Editors, and Reviewers of Meta-analyses of Observational Studies. You must report the page number in your manuscript where you consider each of the items listed in this checklist. If you have not included this information, either revise your manuscript accordingly before submitting or note N/A. Reporting Criteria Reported (Yes/No) Reported on Page No. Reporting of Background Problem definition Hypothesis statement Description of Study Outcome(s) Type of exposure or intervention used Type of study design used Study population Reporting of Search Strategy Qualifications of searchers (eg, librarians and investigators) Search strategy, including time period included in the synthesis and keywords Effort to include all available studies, including contact with authors Databases and registries searched Search software used, name and version, including special features used (eg, explosion) Use of hand searching (eg, reference lists of obtained articles) List of citations located and those excluded, including justification Method for addressing articles published in languages other than English Method of handling abstracts and unpublished studies Description of any contact with authors Reporting of Methods Description of relevance or appropriateness of studies assembled for assessing the hypothesis to be tested Rationale for the selection and coding of data (eg, sound clinical principles or convenience) Documentation of how data were classified -

Quasi-Experimental Studies in the Fields of Infection Control and Antibiotic Resistance, Ten Years Later: a Systematic Review
HHS Public Access Author manuscript Author ManuscriptAuthor Manuscript Author Infect Control Manuscript Author Hosp Epidemiol Manuscript Author . Author manuscript; available in PMC 2019 November 12. Published in final edited form as: Infect Control Hosp Epidemiol. 2018 February ; 39(2): 170–176. doi:10.1017/ice.2017.296. Quasi-experimental Studies in the Fields of Infection Control and Antibiotic Resistance, Ten Years Later: A Systematic Review Rotana Alsaggaf, MS, Lyndsay M. O’Hara, PhD, MPH, Kristen A. Stafford, PhD, MPH, Surbhi Leekha, MBBS, MPH, Anthony D. Harris, MD, MPH, CDC Prevention Epicenters Program Department of Epidemiology and Public Health, University of Maryland School of Medicine, Baltimore, Maryland. Abstract OBJECTIVE.—A systematic review of quasi-experimental studies in the field of infectious diseases was published in 2005. The aim of this study was to assess improvements in the design and reporting of quasi-experiments 10 years after the initial review. We also aimed to report the statistical methods used to analyze quasi-experimental data. DESIGN.—Systematic review of articles published from January 1, 2013, to December 31, 2014, in 4 major infectious disease journals. METHODS.—Quasi-experimental studies focused on infection control and antibiotic resistance were identified and classified based on 4 criteria: (1) type of quasi-experimental design used, (2) justification of the use of the design, (3) use of correct nomenclature to describe the design, and (4) statistical methods used. RESULTS.—Of 2,600 articles, 173 (7%) featured a quasi-experimental design, compared to 73 of 2,320 articles (3%) in the previous review (P<.01). Moreover, 21 articles (12%) utilized a study design with a control group; 6 (3.5%) justified the use of a quasi-experimental design; and 68 (39%) identified their design using the correct nomenclature. -

Epidemiology and Biostatistics (EPBI) 1
Epidemiology and Biostatistics (EPBI) 1 Epidemiology and Biostatistics (EPBI) Courses EPBI 2219. Biostatistics and Public Health. 3 Credit Hours. This course is designed to provide students with a solid background in applied biostatistics in the field of public health. Specifically, the course includes an introduction to the application of biostatistics and a discussion of key statistical tests. Appropriate techniques to measure the extent of disease, the development of disease, and comparisons between groups in terms of the extent and development of disease are discussed. Techniques for summarizing data collected in samples are presented along with limited discussion of probability theory. Procedures for estimation and hypothesis testing are presented for means, for proportions, and for comparisons of means and proportions in two or more groups. Multivariable statistical methods are introduced but not covered extensively in this undergraduate course. Public Health majors, minors or students studying in the Public Health concentration must complete this course with a C or better. Level Registration Restrictions: May not be enrolled in one of the following Levels: Graduate. Repeatability: This course may not be repeated for additional credits. EPBI 2301. Public Health without Borders. 3 Credit Hours. Public Health without Borders is a course that will introduce you to the world of disease detectives to solve public health challenges in glocal (i.e., global and local) communities. You will learn about conducting disease investigations to support public health actions relevant to affected populations. You will discover what it takes to become a field epidemiologist through hands-on activities focused on promoting health and preventing disease in diverse populations across the globe. -

Outcome Reporting Bias in COVID-19 Mrna Vaccine Clinical Trials
medicina Perspective Outcome Reporting Bias in COVID-19 mRNA Vaccine Clinical Trials Ronald B. Brown School of Public Health and Health Systems, University of Waterloo, Waterloo, ON N2L3G1, Canada; [email protected] Abstract: Relative risk reduction and absolute risk reduction measures in the evaluation of clinical trial data are poorly understood by health professionals and the public. The absence of reported absolute risk reduction in COVID-19 vaccine clinical trials can lead to outcome reporting bias that affects the interpretation of vaccine efficacy. The present article uses clinical epidemiologic tools to critically appraise reports of efficacy in Pfzier/BioNTech and Moderna COVID-19 mRNA vaccine clinical trials. Based on data reported by the manufacturer for Pfzier/BioNTech vaccine BNT162b2, this critical appraisal shows: relative risk reduction, 95.1%; 95% CI, 90.0% to 97.6%; p = 0.016; absolute risk reduction, 0.7%; 95% CI, 0.59% to 0.83%; p < 0.000. For the Moderna vaccine mRNA-1273, the appraisal shows: relative risk reduction, 94.1%; 95% CI, 89.1% to 96.8%; p = 0.004; absolute risk reduction, 1.1%; 95% CI, 0.97% to 1.32%; p < 0.000. Unreported absolute risk reduction measures of 0.7% and 1.1% for the Pfzier/BioNTech and Moderna vaccines, respectively, are very much lower than the reported relative risk reduction measures. Reporting absolute risk reduction measures is essential to prevent outcome reporting bias in evaluation of COVID-19 vaccine efficacy. Keywords: mRNA vaccine; COVID-19 vaccine; vaccine efficacy; relative risk reduction; absolute risk reduction; number needed to vaccinate; outcome reporting bias; clinical epidemiology; critical appraisal; evidence-based medicine Citation: Brown, R.B. -

Ethics of Vaccine Research
COMMENTARY Ethics of vaccine research Christine Grady Vaccination has attracted controversy at every stage of its development and use. Ethical debates should consider its basic goal, which is to benefit the community at large rather than the individual. accines truly represent one of the mira- include value, validity, fair subject selection, the context in which it will be used and Vcles of modern science. Responsible for favorable risk/benefit ratio, independent acceptable to those who will use it. This reducing morbidity and mortality from sev- review, informed consent and respect for assessment considers details about the pub- eral formidable diseases, vaccines have made enrolled participants. Applying these princi- lic health need (such as the prevalence, bur- substantial contributions to global public ples to vaccine research allows consideration den and natural history of the disease, as health. Generally very safe and effective, vac- of some of the particular challenges inherent well as existing strategies to prevent or con- cines are also an efficient and cost-effective in testing vaccines (Box 1). trol it), the scientific data and possibilities way of preventing disease. Yet, despite their Ethically salient features of clinical vac- (preclinical and clinical data, expected brilliant successes, vaccines have always been cine research include the fact that it involves mechanism of action and immune corre- controversial. Concerns about the safety and healthy subjects, often (or ultimately) chil- lates) and the likely use of the vaccine (who untoward effects of vaccines, about disturb- dren and usually (at least when testing effi- will use and benefit from it, safety, cost, dis- ing the natural order, about compelling indi- cacy) in very large numbers. -

Observational Clinical Research
E REVIEW ARTICLE Clinical Research Methodology 2: Observational Clinical Research Daniel I. Sessler, MD, and Peter B. Imrey, PhD * † Case-control and cohort studies are invaluable research tools and provide the strongest fea- sible research designs for addressing some questions. Case-control studies usually involve retrospective data collection. Cohort studies can involve retrospective, ambidirectional, or prospective data collection. Observational studies are subject to errors attributable to selec- tion bias, confounding, measurement bias, and reverse causation—in addition to errors of chance. Confounding can be statistically controlled to the extent that potential factors are known and accurately measured, but, in practice, bias and unknown confounders usually remain additional potential sources of error, often of unknown magnitude and clinical impact. Causality—the most clinically useful relation between exposure and outcome—can rarely be defnitively determined from observational studies because intentional, controlled manipu- lations of exposures are not involved. In this article, we review several types of observa- tional clinical research: case series, comparative case-control and cohort studies, and hybrid designs in which case-control analyses are performed on selected members of cohorts. We also discuss the analytic issues that arise when groups to be compared in an observational study, such as patients receiving different therapies, are not comparable in other respects. (Anesth Analg 2015;121:1043–51) bservational clinical studies are attractive because Group, and the American Society of Anesthesiologists they are relatively inexpensive and, perhaps more Anesthesia Quality Institute. importantly, can be performed quickly if the required Recent retrospective perioperative studies include data O 1,2 data are already available. -

COVID-19 Vaccine Trials
COVID-19 VACCINE TRIALS SUMMARY OF PFIZER AND MODERNA COVID-19 VACCINE RESULTS Some of the most common concerns voiced involve the A review of unblinded reactogenicity data from the speed with which these vaccines were developed and final analysis which consisted of a randomized subset whether they are safe or not. How were the companies of at least 8,000 participants 18 years and older in able to get these vaccines developed and ready for the phase 2/3 study demonstrates that the vaccine distribution so fast? Were they tested in persons who was well tolerated, with most solicited adverse events are most vulnerable? Are the vaccines safe? resolving shortly after vaccination. Even though COVID-19 vaccines were developed at While the vaccine was well tolerated overall, and side an extraordinary speed, companies were required effects lasted for only a day or two, persons taking to take all of the regulatory and operational steps the vaccine should be aware that the side effects normally required for all vaccine trials, so none of are more than is seen in general for the flu vaccine these steps were skipped. What did occur that does and be prepared for them. Most side effects were not normally occur was some upfront financial mild to moderate and included injection-site pain, assistance from the federal government (Moderna redness and swelling at the injection site, fatigue/ accepted, Pfizer declined) and federal regulatory tiredness, headache, chills, muscle pain, and joint agencies working closely with the companies, pain. “Severe” side effects, defined as those that providing near real-time data with companies prevent persons from continuing daily activities were receiving review and advice more quickly. -

Guidelines for Reporting Meta-Epidemiological Methodology Research
EBM Primer Evid Based Med: first published as 10.1136/ebmed-2017-110713 on 12 July 2017. Downloaded from Guidelines for reporting meta-epidemiological methodology research Mohammad Hassan Murad, Zhen Wang 10.1136/ebmed-2017-110713 Abstract The goal is generally broad but often focuses on exam- Published research should be reported to evidence users ining the impact of certain characteristics of clinical studies on the observed effect, describing the distribu- Evidence-Based Practice with clarity and transparency that facilitate optimal tion of research evidence in a specific setting, exam- Center, Mayo Clinic, Rochester, appraisal and use of evidence and allow replication Minnesota, USA by other researchers. Guidelines for such reporting ining heterogeneity and exploring its causes, identifying are available for several types of studies but not for and describing plausible biases and providing empirical meta-epidemiological methodology studies. Meta- evidence for hypothesised associations. Unlike classic Correspondence to: epidemiological studies adopt a systematic review epidemiology, the unit of analysis for meta-epidemio- Dr Mohammad Hassan Murad, or meta-analysis approach to examine the impact logical studies is a study, not a patient. The outcomes Evidence-based Practice Center, of certain characteristics of clinical studies on the of meta-epidemiological studies are usually not clinical Mayo Clinic, 200 First Street 6–8 observed effect and provide empirical evidence for outcomes. SW, Rochester, MN 55905, USA; hypothesised associations. The unit of analysis in meta- In this guide, we adapt the items used in the PRISMA murad. mohammad@ mayo. edu 9 epidemiological studies is a study, not a patient. The statement for reporting systematic reviews and outcomes of meta-epidemiological studies are usually meta-analysis to fit the setting of meta- epidemiological not clinical outcomes.