Modular Radiance Transfer
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Governing Biosafety in India: the Relevance of the Cartagena Protocol
Belfer Center for Science & International Affairs Governing Biosafety in India: The Relevance of the Cartagena Protocol Aarti Gupta 2000-24 October 2000 Global Environmental Assessment Project Environment and Natural Resources Program CITATION, CONTEXT, AND PROJECT ACKNOWLEDGEMENTS This paper may be cited as: Gupta, Aarti. “Governing Biosafety in India: The Relevance of the Cartagena Protocol.” Belfer Center for Science and International Affairs (BCSIA) Discussion Paper 2000-24, Environment and Natural Resources Program, Kennedy School of Government, Harvard University, 2000. Available at http://environment.harvard.edu/gea. No further citation is allowed without permission of the author. Comments are welcome and may be directed to the author at the Belfer Center for Science and International Affairs, John F. Kennedy School of Government, Harvard University, 79 John F. Kennedy Street, Cambridge, MA 02138; Email aarti_gupta@ harvard.edu. The Global Environmental Assessment project is a collaborative team study of global environmental assessment as a link between science and policy. The Team is based at Harvard University. The project has two principal objectives. The first is to develop a more realistic and synoptic model of the actual relationships among science, assessment, and management in social responses to global change, and to use that model to understand, critique, and improve current practice of assessment as a bridge between science and policy making. The second is to elucidate a strategy of adaptive assessment and policy for global environmental problems, along with the methods and institutions to implement such a strategy in the real world. The Global Environmental Assessment (GEA) Project is supported by a core grant from the National Science Foundation (Award No. -

Directx™ 12 Case Studies
DirectX™ 12 Case Studies Holger Gruen Senior DevTech Engineer, 3/1/2017 Agenda •Introduction •DX12 in The Division from Massive Entertainment •DX12 in Anvil Next Engine from Ubisoft •DX12 in Hitman from IO Interactive •DX12 in 'Game AAA' •AfterMath Preview •Nsight VSE & DirectX12 Games •Q&A www.gameworks.nvidia.com 2 Agenda •Introduction •DX12 in The Division from Massive Entertainment •DX12 in Anvil Next Engine from Ubisoft •DX12 in Hitman from IO Interactive •DX12 in 'Game AAA' •AfterMath Preview •Nsight VSE & DirectX12 Games •Q&A www.gameworks.nvidia.com 3 Introduction •DirectX 12 is here to stay • Games do now support DX12 & many engines are transitioning to DX12 •DirectX 12 makes 3D programming more complex • see DX12 Do’s & Don’ts in developer section on NVIDIA.com •Goal for this talk is to … • Hear what talented developers have done to cope with DX12 • See what developers want to share when asked to describe their DX12 story • Gain insights for your own DX11 to DX12 transition www.gameworks.nvidia.com 4 Thanks & Credits •Carl Johan Lejdfors Technical Director & Daniel Wesslen Render Architect - Massive •Jonas Meyer Lead Render Programmer & Anders Wang Kristensen Render Programmer - Io-Interactive •Tiago Rodrigues 3D Programmer - Ubisoft Montreal www.gameworks.nvidia.com 5 Before we really start … •Things we’ll be hearing about a lot • Memory Managment • Barriers • Pipeline State Objects • Root Signature and Shader Bindings • Multiple Queues • Multi threading If you get a chance check out the DX12 presentation from Monday’s ‘The -

ARBOR, FRIDAY, APRIL 18, 1862. Tsto. 848
Hardy Eveareer.s. In all cities, villages and to some ex- tent in the country, it is becoming quite PL'BI.TSilKP EVERY KKIIMY .MUHMNC, in th« Third fashionable to plant different kinds of S orv if £tlM iii-ick l~> a •.. • I " r aM HflMB and Huron S weta trees for the purpose of ornameut; and in a few cases for protection from tho cold winds This " fashion" is very laud, Entrance <»n Hare* SI reet, opposite the Franklin. able, nnd there is no danger of its ever becoming too prevalent; indued, it isasu. EL1HU 13. [POJNTJD a:iy ' more honored in the breach thau KdiLor and. 1'ublisrier. in tho observance.' No man was ever I'E.'IMS, «.l,5O A VEiB IK ADVANCE. heard to say that ho had set out too many shade trees, or that ho was sorrv ADVERTISING-. "Vol. ARBOR, FRIDAY, APRIL 18, 1862. TSTo. 848. for the time .spent or the money outlay One square (12 Une« or less": unc greek, M)o©Bt»; ana1 in thu endeavor to make his home moru 15 oenis for«vcvy insertion tin.it-;iiler, less than three n——•— comfortable or beautiful. Many persons ^ months... -S3 Quarter col. 1 year $20 From Si H:S h r the Littlu Ones >t Hi>mc. t Of Fed, a« it he had not seen a com Her father heard her Bobbing a Postal Incident. The Peninsula Between the York and Brilliant Exploit of Col. Geary. arc deterred from putting out evegreens, >ue do 6 do Hfilfcornin G mos 18 Jamea Rivers llali do 1 year 35 The Snowdrop. -

Game Developer Index 2019
Game Developer Index 2019 Second edition October 2019 Published by the Swedish Games Industry Research: Nayomi Arvell Layout: Kim Persson Illustration, cover: Pontus Ullbors Text & analysis: Johanna Nylander The Swedish Games Industry is a collaboration between trade organizations ANGI and Spelplan-ASGD. ANGI represents publishers and distributors and Spelplan-ASGD represents developers and producers. Dataspelsbranschen Swedish Games Industry Magnus Ladulåsgatan 3, SE-116 35 Stockholm www.swedishgamesindustry.com Contact: [email protected] Key Figures KEY FIGURES 2018 2017 2016 2015 2014 2013 Number of companies 384 (+12%) 343 (+22%) 282 (+19%) 236 (+11%) 213 (25+%) 170 (+17%) Revenue EUR M 1 872 (+33%) 1 403 (+6%) 1 325 (+6%) 1 248 (+21%) 1 028 (+36%) 757 (+77%) Profit EUR M 335 (-25%) 446 (-49%) 872 (+65%) 525 (+43%) 369 (29+%) 287 (+639%) Employees 7 924 (+48%) 5 338 (+24%) 4 291 (+16%) 3 709 (+19%) 3 117 (+23%) 2 534 (+29%) Employees based in 5 320 (+14%) 4 670 (+25%) 3 750 No data No data No data Sweden Men 6 224 (79%) 4 297 (80%) 3 491 (81%) 3 060 (82%) 2 601 (83%) 2 128 (84%) Women 1 699 (21%) 1 041 (20%) 800 (19%) 651 (18%) 516 (17%) 405 (16%) Tom Clancy’s The Division 2, Ubisoft Massive Entertainment Index Preface Art and social impact – the next level for Swedish digital games 4 Preface 6 Summary The game developers just keep breaking records. What once was a sensation making news headlines 8 Revenue – “Swedish video games succeed internationally” 9 Revenue & Profit – is now the established order and every year new records are expected from the Game Developer 12 Employees Index. -
Contractor List
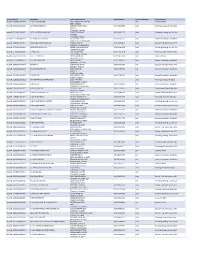
Active Licenses DBA Name Full Primary Address Work Phone # Licensee Category SIC Description buslicBL‐3205002/ 28/2020 1 ON 1 TECHNOLOGY 417 S ASSOCIATED RD #185 cntr Electrical Work BREA CA 92821 buslicBL‐1684702/ 28/2020 1ST CHOICE ROOFING 1645 SEPULVEDA BLVD (310) 251‐8662 subc Roofing, Siding, and Sheet Met UNIT 11 TORRANCE CA 90501 buslicBL‐3214602/ 28/2021 1ST CLASS MECHANICAL INC 5505 STEVENS WAY (619) 560‐1773 subc Plumbing, Heating, and Air‐Con #741996 SAN DIEGO CA 92114 buslicBL‐1617902/ 28/2021 2‐H CONSTRUCTION, INC 2651 WALNUT AVE (562) 424‐5567 cntr General Contractors‐Residentia SIGNAL HILL CA 90755‐1830 buslicBL‐3086102/ 28/2021 200 PSI FIRE PROTECTION CO 15901 S MAIN ST (213) 763‐0612 subc Special Trade Contractors, NEC GARDENA CA 90248‐2550 buslicBL‐0778402/ 28/2021 20TH CENTURY AIR, INC. 6695 E CANYON HILLS RD (714) 514‐9426 subc Plumbing, Heating, and Air‐Con ANAHEIM CA 92807 buslicBL‐2778302/ 28/2020 3 A ROOFING 762 HUDSON AVE (714) 785‐7378 subc Roofing, Siding, and Sheet Met COSTA MESA CA 92626 buslicBL‐2864402/ 28/2018 3 N 1 ELECTRIC INC 2051 S BAKER AVE (909) 287‐9468 cntr Electrical Work ONTARIO CA 91761 buslicBL‐3137402/ 28/2021 365 CONSTRUCTION 84 MERIDIAN ST (626) 599‐2002 cntr General Contractors‐Residentia IRWINDALE CA 91010 buslicBL‐3096502/ 28/2019 3M POOLS 1094 DOUGLASS DR (909) 630‐4300 cntr Special Trade Contractors, NEC POMONA CA 91768 buslicBL‐3104202/ 28/2019 5M CONTRACTING INC 2691 DOW AVE (714) 730‐6760 cntr General Contractors‐Residentia UNIT C‐2 TUSTIN CA 92780 buslicBL‐2201302/ 28/2020 7 STAR TECH 2047 LOMITA BLVD (310) 528‐8191 cntr General Contractors‐Residentia LOMITA CA 90717 buslicBL‐3156502/ 28/2019 777 PAINTING & CONSTRUCTION 1027 4TH AVE subc Painting and Paper Hanging LOS ANGELES CA 90019 buslicBL‐1920202/ 28/2020 A & A DOOR 10519 MEADOW RD (213) 703‐8240 cntr General Contractors‐Residentia NORWALK CA 90650‐8010 buslicBL‐2285002/ 28/2021 A & A HENINS, INC. -

Swedish Game Developer Index 2017-2018 Second Edition Published by Swedish Games Industry Research, Text & Design: Jacob Kroon Cover Illustration: Anna Nilsson
Swedish Game Developer Index 2017-2018 Second Edition Published by Swedish Games Industry Research, text & design: Jacob Kroon Cover Illustration: Anna Nilsson Dataspelsbranschen Swedish Games Industry Klara norra kyrkogata 31, Box 22307 SE-104 22 Stockholm www.dataspelsbranschen.se Contact: [email protected] 2 Table of Contents Summary 4 Preface 5 Revenue & Profit 8 Key Figures 10 Number of Companies 14 Employment 14 Gender Distribution 16 Employees & Revenue per Company 18 Biggest Companies 20 Platforms 22 Actual Consumer Sales Value 23 Game Developer Map 24 Globally 26 The Nordic Industry 28 Future 30 Copyright Infringement 34 Threats & Challenges 36 Conclusion 39 Method 39 Timeline 40 Glossary 42 3 Summary The Game Developer Index analyses Swedish game few decades, the video game business has grown developers’ operations and international sector trends from a hobby for enthusiasts to a global industry with over a year period by compiling the companies’ annual cultural and economic significance. The 2017 Game accounts. Swedish game development is an export Developer Index summarizes the Swedish companies’ business active in a highly globalized market. In a last reported business year (2016). The report in brief: Revenue increased to EUR 1.33 billion during 2016, doubling in the space of three years Most companies are profitable and the sector reports total profits for the eighth year in a row Jobs increased by 16 per cent, over 550 full time positions, to 4291 employees Compound annual growth rate since 2006 is 35 per cent Small and medium sized companies are behind 25 per cent of the earnings and half of the number of employees More than 70 new companies result in 282 active companies in total, an increase by 19 per cent Almost 10 per cent of the companies are working with VR in some capacity Game development is a growth industry with over half Swedish game developers are characterized by of the companies established post 2010. -

Download the Prologue
The Guns at Last Light THE WAR IN WESTERN EUROPE, -1944–1945 VOLUME THREE OF THE LIBERATION TRILOGY Rick Atkinson - Henry Holt and Company New York 020-52318_ch00_6P.indd v 3/2/13 10:57 AM Henry Holt and Company, LLC Publishers since 1866 175 Fift h Avenue New York, New York 10010 www .henryholt .com www .liberationtrilogy .com Henry Holt® and ® are registered trademarks of Henry Holt and Company, LLC. Copyright © 2013 by Rick Atkinson All rights reserved. Distributed in Canada by Raincoast Book Distribution Limited Library of Congress Cataloging- in- Publication Data Atkinson, Rick. Th e guns at last light : the war in Western Eu rope, 1944– 1945 / Rick Atkinson. —1st ed. p. cm. — (Th e liberation trilogy ; v. 3) Includes bibliographical references and index. ISBN 978- 0- 8050- 6290- 8 1. World War, 1939– 1945—Campaigns—Western Front. I. Title. D756.A78 2013 940.54'21—dc23 2012034312 Henry Holt books are available for special promotions and premiums. For details contact: Director, Special Markets. First Edition 2013 Maps by Gene Th orp Printed in the United States of America 1 3 5 7 9 10 8 6 4 2 020-52318_ch00_6P.indd vi 3/2/13 10:57 AM To those who knew neither thee nor me, yet suff ered for us anyway 020-52318_ch00_6P.indd vii 3/2/13 10:57 AM But pardon, gentles all, Th e fl at unraisèd spirits that hath dared On this unworthy scaff old to bring forth So great an object. Can this cockpit hold Th e vasty fi elds of France? Shakespeare, Henry V, Prologue 020-52318_ch00_6P.indd ix 3/2/13 10:57 AM Contents - LIST OF MAPS ............xiv MAP LEGEND ........... -

UNIVERSAL REGISTRATION DOCUMENT and Annual Financial Report Contents
2021 UNIVERSAL REGISTRATION DOCUMENT and Annual Financial Report Contents Message from the Chairman and Chief Executive Offi cer 3 1 Key fi gures AFR 5 6 Financial statements 195 1.1 Quarterly and annual consolidated 6.1 Consolidated fi nancial sales 6 statements for the year 1.2 Sales by platform (net bookings) 7 ended March 31, 2021 AFR 196 1.3 Sales by geographic region 6.2 Statutory Auditors’ report (net bookings) 8 on the consolidated fi nancial statements AFR 262 2 Group presentation 9 6.3 Separate fi nancial statements of Ubisoft Entertainment SA for 2.1 Group business model the year ended March 31, 2021 AFR 267 and strategy AFR DPEF 10 6.4 Statutory Auditors’ report 2.2 History 14 on the separate fi nancial 2.3 Financial year highlights AFR 15 statements AFR 300 2.4 Subsidiaries and equity 6.5 Statutory Auditors’ special report investments AFR 17 on regulated agreements and 2.5 Research and development, commitments 305 investment and fi nancing policy AFR 19 6.6 Ubisoft (parent company) results 2.6 2020-2021 performance review for the past fi ve fi nancial years AFR 306 (non-IFRS data) AFR 21 2.7 Outlook AFR 25 7 Information on the Company 3 Risks and internal control AFR 27 and its capital 307 3.1 Risk factors 28 7.1 Legal information AFR 308 3.2 Risk management and internal 7.2 Share capital AFR 311 control mechanisms 38 7.3 Share ownership AFR 316 7.4 Securities market 321 7.5 Additional information AFR 326 4 Corporate g overnance r eport AFR 45 4.1 Corporate governance 46 8 Glossary, cross-reference tables 4.2 Compensation of corporate -

The Gmo Emperor Has No Clothes
THE GMO EMPEROR HAS NO CLOTHES Published by A Global Citizens Report on the State of GMOs THE GMO EMPEROR HAS NO CLOTHES A Global Citizens Report on the State of GMOs - False Promises, Failed Technologies Coordinated by Vandana Shiva, Navdanya Debbie Barker, Centre for Food Safety Caroline Lockhart, Navdanya International Front page cartoon: Sergio Staino Layout, production and printing: SICREA srl, Florence Contact: [email protected] Available for download at www.navdanyainternational.it www.navdanya.org Thanks go to all those who readily contributed in the realization of this report, particularly Sergio Staino, creator of the cover cartoon, Maurizio Izzo of Sicrea for production and Massimo Orlandi for press and communications. Thanks also go to Christina Stafford and interns Tara McNerney and Tanvi Gadhia of Center for Food Safety (CFS) and Sulakshana Fontana, Elena Bellini and Filippo Cimo of Navdanya International for their diligent coordination, editing and translation efforts. Final thanks also go to Giannozzo Pucci, Maria Grazia Mammuccini and Natale Bazzanti for their cooperation and assistance in realizing this report. This publication is printed on ecological paper SYMBOL FREELIFE SATIN ECF A Global Citizens Report on the State of GMOs - False Promises, Failed Technologies Coordinated by Navdanya and Navdanya International, the International Commission on the Future of Food and Agriculture, with the participation of The Center for Food Safety (CFS) Contributing organizations: THE AMERICAS Center for Food Safety -

PROJECT MANAGERS - PROGRAMMERS UBISOFT 1.007 a Creator of Billion EURO Revenue Rabbids® Watch Dogs®
PROJECT MANAGERS - PROGRAMMERS UBISOFT 1.007 A CREAtor OF BILLION EURO REVENUE RABBIDS® WatcH_DOGS® IN 2013-2014 Ubisoft’s family brand has recently Watch Dogs is Ubisoft’s STRONG invaded millions of TV screens already iconic new brand worldwide with the Rabbids Invasion that sold 4 million copies animated series. in just one week and is set to be a reference for this BRANDS new generation of gaming. MORE THAN Ubisoft’s solid and diverse portfolio of blockbuster brands has sold millions of units around the world. 9200 Iconic franchises such as Assassin’s Creed, TALENTS Just Dance, Watch Dogs and Rabbids are the foundation of Ubisoft’s reputation as a leading JUST DANCE® IN 29 COUNTRIES creator of interactive entertainment experiences. ASSASSin’S CREED® Just Dance is a global Ubisoft games are renowned for their high quality phenomenon that has MORE With more than 77 million copies sold, reached over 110 million THAN and the immersive experience they offer across Assassin’s Creed is the leader on the historical players around the world all platforms - console, mobile, tablet and PC. action-adventure game segment and has and consistently ranks in As part of its strategy, Ubisoft has extended expanded into comic books, novels the top video game the reach of its brands to other entertainment and an upcoming feature-length film. charts year after year. 500 media including TV, movies, books, comics and MILLION theme parks. GAMES SOLD A GLOBAL MARKET LEADER By creating original and memorable gaming experiences for over a quarter-century, Ubisoft has secured its position as a leading actor in the video game industry. -

January 2021 CGD Monthly Issue #6
Augmented reality games have gained plenty of momentum the past few years. Pokemon GO is currently the high- est grossing AR video game in the mobile market and that’s not surprising. Popular titles like these take advantage of the player’s constant need for discovery and interactivity. And this new technology takes advantage of it. Minecraft is the pure definition of endless exploration and creativity, so it was bound for Microsoft to produce an Augmented Reality title that makes the user travel around the city and interact with the game, just by using a smartphone. The users can travel around the virtual space and discover different biomes where they can build stuff and let other people see them, all in the real world at life-size. In October of 2019, the game launched with the title “Minecraft Earth”. In January the 5th of 2021, Mojang announced the unfortunate news that the game will be shut down on June 30th of the same year. The studio announced the following in a Q&A: “Due to the current global situation, we have re-al- located our resources to other areas that provide value to the Minecraft community and we have made the difficult decision to sunset Minecraft Earth”. Understandably, many other AR games suffered the same fate due to the strict quarantine rules applied by the governments in populated cities and countries across the world. This resulted in huge drops of player base and to make up for it, developers attempted to make the game playable from home. Mojang decided to keep the game running for a few more months and push a final update on the 5th of June, which will remove all real-money transactions and accelerate player progression, allowing the last of the users to purely enjoy the game with minimal overcomings. -

Seeds of Suicide the Ecological and Human Costs of Seed Monopolies and Globalisation of Agriculture
Seeds of Suicide The Ecological and Human Costs of Seed Monopolies and Globalisation of Agriculture Dr Vandana Shiva, Kunwar Jalees Navdanya A-60, Hauz Khas, New Delhi – 110 016, INDIA Tel : 2653 5422; 2696 8077; 2656 1868 Fax : 2685 6795; 2696 2589 e-mail: [email protected] [email protected] URL : http://www.navdanya.org i Seeds of Suicide : The Ecological and Human Costs of Seed Monopolies and Globalisation of Agriculture © Navdanya First edition : December 1998 Second edition : December 2000 Revised Third edition : January 2002 Revised Fourth edition : May 2006 Author: Vandana Shiva, Kunwar Jalees Published by : Navdanya A-60, Hauz Khas New Delhi - 110 016, India Tel: 91-11-2696 8077, 2685 3772 Fax: 91-11-2685 6795 E-mail: [email protected] Website: www.vshiva.net Cover Design : Systems Vision Printed by : Systems Vision A-199 Okhla Ph-I, New Delhi - 110 020 Ph.: 2681 1195, 2681 1841 ii Dedicated to the Farmers of India who committed suicide, with a hope for a farming future which is suicide free. iii iv Contents Introduction Seeds of Suicides ............................................................................ vii The Changing Nature of Seed From Public Resource to Private Property .......................... 1 1. Diverse Seeds for Diversity ......................................................... 1 2. The Decline of the Public Sector ............................................... 3 3. The Privatisation of the Seed Sector .......................................... 7 4. Big Companies Getting Bigger...................................................