Translingual Topic Tracking with PRISE
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Language Contact in Nanning: Nanning Pinghua and Nanning Cantonese
20140303 draft of : de Sousa, Hilário. 2015a. Language contact in Nanning: Nanning Pinghua and Nanning Cantonese. In Chappell, Hilary (ed.), Diversity in Sinitic languages, 157–189. Oxford: Oxford University Press. Do not quote or cite this draft. LANGUAGE CONTACT IN NANNING — FROM THE POINT OF VIEW OF NANNING PINGHUA AND NANNING CANTONESE1 Hilário de Sousa Radboud Universiteit Nijmegen, École des hautes études en sciences sociales — ERC SINOTYPE project 1 Various topics discussed in this paper formed the body of talks given at the following conferences: Syntax of the World’s Languages IV, Dynamique du Langage, CNRS & Université Lumière Lyon 2, 2010; Humanities of the Lesser-Known — New Directions in the Descriptions, Documentation, and Typology of Endangered Languages and Musics, Lunds Universitet, 2010; 第五屆漢語方言語法國際研討會 [The Fifth International Conference on the Grammar of Chinese Dialects], 上海大学 Shanghai University, 2010; Southeast Asian Linguistics Society Conference 21, Kasetsart University, 2011; and Workshop on Ecology, Population Movements, and Language Diversity, Université Lumière Lyon 2, 2011. I would like to thank the conference organizers, and all who attended my talks and provided me with valuable comments. I would also like to thank all of my Nanning Pinghua informants, my main informant 梁世華 lɛŋ11 ɬi55wa11/ Liáng Shìhuá in particular, for teaching me their language(s). I have learnt a great deal from all the linguists that I met in Guangxi, 林亦 Lín Yì and 覃鳳餘 Qín Fèngyú of Guangxi University in particular. My colleagues have given me much comments and support; I would like to thank all of them, our director, Prof. Hilary Chappell, in particular. Errors are my own. -

Written at the Service of Oral: Topolect Literature Movement in Hong Kong* Yu
2020 ВЕСТНИК САНКТ-ПЕТЕРБУРГСКОГО УНИВЕРСИТЕТА Т. 12. Вып. 3 ВОСТОКОВЕДЕНИЕ И АФРИКАНИСТИКА ГЕОКУЛЬТУРНЫЕ ПРОСТРАНСТВА И КОДЫ КУЛЬТУР СТРАН АЗИИ И АФРИКИ UDC 811.581.12 Written at the Service of Oral: Topolect Literature Movement in Hong Kong* Yu. A. Dreyzis Lomonosov Moscow State University, 1, Leninskie gory, Moscow, 119991, Russian Federation For citation: Dreyzis Yu. A. Written at the Service of Oral: Topolect Literature Movement in Hong Kong. Vestnik of Saint Petersburg University. Asian and African Studies, 2020, vol. 12, issue 3, pp. 415– 425. https://doi.org/10.21638/spbu13.2020.307 The article describes the history of the Topolect Literature Movement (TLM), which devel- oped in Hong Kong in the 1940s, and analyzes its typological features. TLM was one of the most radical projects implemented to replace writing in the national standard language based on northern dialects with writing in the local language variety (Cantonese / Yue). This variety was a non-northern idiom that performed the function of the L-language in diglossia. TLM authors did not try to break the connection between the written language and its oral form: many, primarily poetic, texts were somehow intended for public performance; in other types of texts, a close connection with the spoken language was supported by the strong presence of a narrator. Texts were recorded using Chinese characters (a standard character with an identical / similar reading was used to write down a topolect morpheme, or a character using it as a phonetic element indicating reading was created). The final failure of TLM, in addi- tion to purely political factors, can be explained by a shift in attention from the urban literate audience to peasants. -

Information to Users
INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UMI films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer. The quality of this reproduction is dependent upon the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper aligmnent can adversely affect reproduction. In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion. Oversize materials (e.g., maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-hand corner and continuing firom left to right in equal sections with small overlaps. Each original is also photographed in one exposure and is included in reduced form at the back of the book. Photographs included in the original manuscript have been reproduced xerographically in this copy. Higher quality 6" x 9" black and white photographic prints are available for any photographs or illustrations appearing in this copy for an additional charge. Contact UMI directly to order. University Microfilms International A Bell & Howell Information Com pany 300 Norifi Zeeb Road. Ann Arbor. Ml 48106-1346 USA 313.'761-4700 800.'521-0600 Order Number 9411999 Comparative, diachronic and experimental perspectives on the interaction between tone and vowel in Standard Cantonese Lee, Gina Maureen, Ph.D. -

THE MEDIA's INFLUENCE on SUCCESS and FAILURE of DIALECTS: the CASE of CANTONESE and SHAAN'xi DIALECTS Yuhan Mao a Thesis Su
THE MEDIA’S INFLUENCE ON SUCCESS AND FAILURE OF DIALECTS: THE CASE OF CANTONESE AND SHAAN’XI DIALECTS Yuhan Mao A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Arts (Language and Communication) School of Language and Communication National Institute of Development Administration 2013 ABSTRACT Title of Thesis The Media’s Influence on Success and Failure of Dialects: The Case of Cantonese and Shaan’xi Dialects Author Miss Yuhan Mao Degree Master of Arts in Language and Communication Year 2013 In this thesis the researcher addresses an important set of issues - how language maintenance (LM) between dominant and vernacular varieties of speech (also known as dialects) - are conditioned by increasingly globalized mass media industries. In particular, how the television and film industries (as an outgrowth of the mass media) related to social dialectology help maintain and promote one regional variety of speech over others is examined. These issues and data addressed in the current study have the potential to make a contribution to the current understanding of social dialectology literature - a sub-branch of sociolinguistics - particularly with respect to LM literature. The researcher adopts a multi-method approach (literature review, interviews and observations) to collect and analyze data. The researcher found support to confirm two positive correlations: the correlative relationship between the number of productions of dialectal television series (and films) and the distribution of the dialect in question, as well as the number of dialectal speakers and the maintenance of the dialect under investigation. ACKNOWLEDGMENTS The author would like to express sincere thanks to my advisors and all the people who gave me invaluable suggestions and help. -
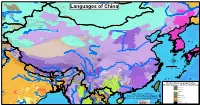
Map by Steve Huffman Data from World Language Mapping System 16
Mandarin Chinese Evenki Oroqen Tuva China Buriat Russian Southern Altai Oroqen Mongolia Buriat Oroqen Russian Evenki Russian Evenki Mongolia Buriat Kalmyk-Oirat Oroqen Kazakh China Buriat Kazakh Evenki Daur Oroqen Tuva Nanai Khakas Evenki Tuva Tuva Nanai Languages of China Mongolia Buriat Tuva Manchu Tuva Daur Nanai Russian Kazakh Kalmyk-Oirat Russian Kalmyk-Oirat Halh Mongolian Manchu Salar Korean Ta tar Kazakh Kalmyk-Oirat Northern UzbekTuva Russian Ta tar Uyghur SalarNorthern Uzbek Ta tar Northern Uzbek Northern Uzbek RussianTa tar Korean Manchu Xibe Northern Uzbek Uyghur Xibe Uyghur Uyghur Peripheral Mongolian Manchu Dungan Dungan Dungan Dungan Peripheral Mongolian Dungan Kalmyk-Oirat Manchu Russian Manchu Manchu Kyrgyz Manchu Manchu Manchu Northern Uzbek Manchu Manchu Manchu Manchu Manchu Korean Kyrgyz Northern Uzbek West Yugur Peripheral Mongolian Ainu Sarikoli West Yugur Manchu Ainu Jinyu Chinese East Yugur Ainu Kyrgyz Ta jik i Sarikoli East Yugur Sarikoli Sarikoli Northern Uzbek Wakhi Wakhi Kalmyk-Oirat Wakhi Kyrgyz Kalmyk-Oirat Wakhi Kyrgyz Ainu Tu Wakhi Wakhi Khowar Tu Wakhi Uyghur Korean Khowar Domaaki Khowar Tu Bonan Bonan Salar Dongxiang Shina Chilisso Kohistani Shina Balti Ladakhi Japanese Northern Pashto Shina Purik Shina Brokskat Amdo Tibetan Northern Hindko Kashmiri Purik Choni Ladakhi Changthang Gujari Kashmiri Pahari-Potwari Gujari Japanese Bhadrawahi Zangskari Kashmiri Baima Ladakhi Pangwali Mandarin Chinese Churahi Dogri Pattani Gahri Japanese Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Ladakhi Northern Qiang -

The Light Verb Lai in the Chinese Comparative Correlative∗
LANGUAGE AND LINGUISTICS 9.1:69-99, 2008 2008-0-009-001-000237-1 The Light Verb lai in the Chinese Comparative Correlative∗ Chen-Sheng Luther Liu National Chiao Tung University The Chinese yue lai yue ‘more come more’ construction is a subtype of the Chinese comparative correlative rather than an analogue of the English more and more (or -er and -er) construction. The verb lai ‘come’ inside is the overt realization of the light verb BECOME, which selects as complement a state. Through an internet search of large Chinese corpora, we further argue that the yue lai yue ‘more come more’ sequence is on the way to being lexicalized as a degree adverb with some properties that provide indirect evidence for the light verb analysis made here. Key words: comparative correlative, yue lai yue, light verb 1. Introduction Chao (1968:121) suggests that, in the Chinese yue … yue ‘more’ … ‘more’ correlative construction, each correlative degree adverb yue ‘more’ must co-occur with a predicate. If no specific action can be ascribed to the first verb (or predicate), the dummy verb lai ‘come’, bian ‘change’, or guo ‘as (one) lives’ or ‘as (time) passes’ is used to complete the formula, for example (1) (henceforth the yue lai yue ‘more come more’ construction). (1) a. Zhangsan yue lai/bian/guo yue hutu le. Zhangsan more come/change/pass more muddle-headed SFP ‘Zhangsan is getting more and more muddle-headed.’ b. Zhangsan yue lai/?bian yue xihuan ni le. Zhangsan more come/change more like you SFP ‘Zhangsan likes you more and more.’ ∗ In the past four years, I have almost fully devoted myself to the writing of papers about Chinese comparative correlatives in the hope of getting closer to the dream that I have been chasing after since 1997. -

{PDF} Moon Living Abroad in China Including Hong Kong & Macau 3Rd
MOON LIVING ABROAD IN CHINA INCLUDING HONG KONG & MACAU 3RD EDITION PDF, EPUB, EBOOK Barbara Strother | 9781612386355 | | | | | Moon Living Abroad in China Including Hong Kong & Macau 3rd edition PDF Book Cantonese Siyi incl. The youngest amongst gigantic hotels along the Cotai Strip is the Parisian Macao. What did you learn from the Chumakov family? TN: What challenges do you face as a black expat in China? How can we improve? I have come to love Macau as my second home. Writing is also a hobby of his, though mediocre at best, and is half the other half is his wife of the people behind the blog Young OFW. The global economy will shrink 4. Darwin Cheng, 31, who has been living in Australia for 11 years, said he wanted to vote without the need to fly eight hours back to Hong Kong. Bolsonaro slams Chinese vaccine. Macau is good for expats because they do not discriminate. It seems like so many people miss that point in expat interviews. Vietnamese authorities took an aggressive approach to the viral outbreak from the start. Can you apply for a Chinese visa in another country? But the support for reform on its own, she says, cannot bring justice to America. It was my aunt who told me to try looking for a job, so I tendered my resignation abruptly and took the plane to the city. This multi-faceted city has welcomed millions of tourists every year and is continually proving travelers with once in a lifetime experience. During the epidemic period, it is not very likely to apply for a China visa from Macau. -

Unisonance in Kung Fu Film Music, Or the Wong Fei-Hung Theme Song As a Cantonese Transnational Anthem
UCC Library and UCC researchers have made this item openly available. Please let us know how this has helped you. Thanks! Title Unisonance in kung fu film music, or the Wong Fei-hung theme song as a Cantonese transnational anthem Author(s) McGuire, Colin P. Publication date 2018-05-04 Original citation McGuire, C. P. (2018) 'Unisonance in kung fu film music, or the Wong Fei-hung theme song as a Cantonese transnational anthem', Ethnomusicology Forum, 27(1), pp. 48-67. doi: 10.1080/17411912.2018.1463549 Type of publication Article (peer-reviewed) Link to publisher's https://www.tandfonline.com/doi/citedby/10.1080/17411912.2018.1463 version 549 http://dx.doi.org/10.1080/17411912.2018.1463549 Access to the full text of the published version may require a subscription. Rights © 2018 The Author. Published by Informa UK Limited, trading as Taylor & Francis Group. This is an Open Access article distributed under the terms of the Creative Commons Attribution- NonCommercial-NoDerivatives License (http://creativecommons.org/licenses/by-nc-nd/4.0/), which permits non-commercial re-use, distribution, and reproduction in any medium, provided the original work is properly cited, and is not altered, transformed, or built upon in any way. http://creativecommons.org/licenses/by-nc-nd/4.0/ Item downloaded http://hdl.handle.net/10468/6619 from Downloaded on 2021-10-10T17:37:44Z Ethnomusicology Forum ISSN: 1741-1912 (Print) 1741-1920 (Online) Journal homepage: http://www.tandfonline.com/loi/remf20 Unisonance in kung fu film music, or the Wong Fei- hung theme song as a Cantonese transnational anthem Colin P. -

UC Santa Barbara Electronic Theses and Dissertations
UC Santa Barbara UC Santa Barbara Electronic Theses and Dissertations Title Writing Modernity: Constructing a History of Chinese Architecture, 1920-1949 Permalink https://escholarship.org/uc/item/2sg0n862 Author Yan, Wencheng Yan Publication Date 2016 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA Santa Barbara Writing Modernity: Constructing a History of Chinese Architecture, 1920 – 1949 A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in History of Art & Architecture by Yan Wencheng Committee in charge: Professor Swati Chattopadhyay, Chair Professor Richard Wittman Professor Xiaowei Zheng March 2016 The dissertation of Yan Wencheng is approved. _____________________________________________ Richard Wittman _____________________________________________ Xiaowei Zheng _____________________________________________ Swati Chattopadhyay, Committee Chair March 2016 Writing Modernity: Constructing a History of Chinese Architecture, 1920 – 1949 Copyright © 2016 by Yan Wencheng iii ACKNOWLEDGEMENTS This dissertation has taken longer than I had imagined at the beginning of my graduate career. It would not have been possible without the help of many along the way. I wish to thank my home department of the History of Art & Architecture at the University of California, Santa Barbara, for providing academic and financial support for my studies. I thank the professors who have given support and assistance whenever I needed it, making the department my home for almost a decade. In particular, my thanks go to Professors E. Bruce Robertson, Peter Sturman, Jeremy White, Volker M. Welter and Ann Jensen Adams. I thank the staff at the C.V. Starr East Asian Library of the University of California, Berkeley, where I conducted preliminary research during the spring of 2012. -

Languages and Power in China Arienne M
Dwyer, Arienne M. 1998. The Texture of Tongues: Languages and Power in China. In Willam Safran, ed., Nationalism and Ethnoregional Identities in China . Frank Cass, pp. 68–85. Preprint. The Texture of Tongues: Languages and Power in China Arienne M. Dwyer 1. Introduction The way speakers and nations use language reflects the power relationships of a society. Languages are inherently dynamic, interactive, and multi-layered. Nation- states are stabilizing and isolating to preserve territorial integrity. Multilingual nation- states seek to preserve territorial boundaries in part by delimiting hierarchical boundaries between their languages. Mandarin, canonized as the standard language, stands at the pinnacle of a metalinguistic hierarchy which mirrors the vertical basis of power in China today. State language policies establish official minority languages (and Chinese “dialects”) under the arching umbrella of the Chinese state; yet their domain, or horizontal scope, is strictly constrained through prescriptive standardization. The dynamic change and variation of spoken languages is reduced to a single text. This paper explores the tension between this codifying imperative of the Chinese state and the dynamic force of speakers. I survey Chinese language policy in theory and practice, then focus on the expressions of power through language use. 2. Language policy in China: theory and practice According to the Chinese Constitution, all 56 minzu (“nationalities”) are equal and enjoy equal status “in the Zhonghua Minzu Chinese Nation”. 1 “Official policy condemns both ‘Han Chauvinism’, the belief that the Han, or Chinese, are superior to other groups, and ‘Local Nationality Chauvinism’, which denies that groups other than the Han are integral parts of the Chinese nation.” 2 But in practice, only non- Han speakers are referred to as minzu . -
Dear Sir/Madam
CURRICULUM VITAE Carine Yuk-man YIU Personal Address: Division of Humanities, The Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong Contact number: 2358-7801 E-mail Address: [email protected] Employment 2014 – Associate Professor of Humanities, The Hong Kong University of Science and Technology 2007 – 2014 Assistant Professor of Humanities, The Hong Kong University of Science and Technology 2006 – 2007 Research Assistant Professor of Humanities, The Hong Kong University of Science and Technology 1997 – 2005 Tutor (part-time), School of Arts and Social Sciences, The Open University of Hong Kong 1999 Research Assistant (part-time), Department of Chinese, Translation and Linguistics, The City University of Hong Kong 1998 – 1999 Demonstrator (part-time), Department of Chinese, Translation and Linguistics, The City University of Hong Kong 1997 – 1998 Research Assistant, Department of English, The Chinese University of Hong Kong 1997 Research Assistant, Department of English, The Hong Kong Polytechnic University 1996 – 1997 Research Assistant, Department of Chinese and Bilingual Studies, The Hong Kong Polytechnic University Education 2005 Ph.D. in Humanities (Linguistics), The Hong Kong University of Science and Technology 2001 MPhil. in Humanities (Linguistics), The Hong Kong University of Science and Technology 1996 MA (Linguistics), University of Manitoba, Canada 1994 BA advanced (Linguistics), University of Manitoba, Canada 1 Scholarships and academic awards 2018 – 2019 Harvard-Yenching Institute Visiting Scholar -
The Cartography of Sentence-Final Particles in Yue Chinese – Evidence from Comparative Analysis and Language Contact
The Cartography of Sentence-Final Particles in Yue Chinese – Evidence from Comparative Analysis and Language Contact by CHAN, Tsan Tsai Division of Humanities, School of Humanities and Social Science The Hong Kong University of Science and Technology Abstract In this thesis, I test Cinque’s (1999) cartographic theory that grammatical items with the same meaning appear in the same relative position in any natural language. I focus on the sequence of sentence-final particles (SFPs, also geoi3mut6 zo6ci4 句末助詞 or mei5jam1 尾 音), words which are normally found at the end of sentences in certain languages and express various meanings, from grammatical time to surprise and annoyance. My data comes largely from Yue Chinese, which is rich in SFPs. Comparing the sequence of SFPs in four Yue varieties (Guangzhou, Hong Kong, and Singapore Cantonese, alongside Tangxia Siyi Yue) with that in other Chinese and non-Chinese languages, I find that in different languages, SFPs with certain meanings can appear in more than one position. Having SFPs similar in meaning appear in different positions does not fit in with the theory that grammatical items are assigned to one position based on the meaning they express. I work out a theoretical explanation for this apparent deviation and propose that SFPs with similar meanings but occupying different positions may in fact belong to different grammatical classes. The label “SFP” would therefore refer to several grammatical classes, instead of just one. To support this theory, I discuss how languages with SFPs borrow these words from each other. I show in the process that borrowing affects SFPs differently if they occupy different positions, even though they may be similar in meaning.