Medieval Latin Character Recommendations the Digital
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
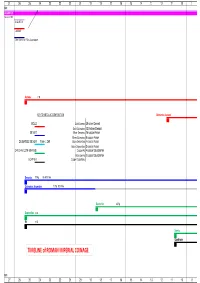
TIMELINE of ROMAN IMPERIAL COINAGE
27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 B.C. AUGUSTUS 16 Jan 27 BC AUGUSTUS CAESAR Other title: e.g. Filius Augustorum Aureus 7.8g KEY TO METALLIC COMPOSITION Quinarius Aureus GOLD Gold Aureus 25 silver Denarii Gold Quinarius 12.5 silver Denarii SILVER Silver Denarius 16 copper Asses Silver Quinarius 8 copper Asses DE-BASED SILVER from c. 260 Brass Sestertius 4 copper Asses Brass Dupondius 2 copper Asses ORICHALCUM (BRASS) Copper As 4 copper Quadrantes Brass Semis 2 copper Quadrantes COPPER Copper Quadrans Denarius 3.79g 96-98% fine Quinarius Argenteus 1.73g 92% fine Sestertius 25.5g Dupondius 12.5g As 10.5g Semis Quadrans TIMELINE of ROMAN IMPERIAL COINAGE B.C. 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 1 2 3 4 5 6 7 8 9 10 11 A.D.A.D. denominational relationships relationships based on Aureus Aureus 7.8g 1 Quinarius Aureus 3.89g 2 Denarius 3.79g 25 50 Sestertius 25.4g 100 Dupondius 12.4g 200 As 10.5g 400 Semis 4.59g 800 Quadrans 3.61g 1600 8 7 6 5 4 3 2 1 1 2 3 4 5 6 7 8 91011 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 19 Aug TIBERIUS TIBERIUS Aureus 7.75g Aureus Quinarius Aureus 3.87g Quinarius Aureus Denarius 3.76g 96-98% fine Denarius Sestertius 27g Sestertius Dupondius 14.5g Dupondius As 10.9g As Semis Quadrans 3.61g Quadrans 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 TIBERIUS CALIGULA CLAUDIUS Aureus 7.75g 7.63g Quinarius Aureus 3.87g 3.85g Denarius 3.76g 96-98% fine 3.75g 98% fine Sestertius 27g 28.7g -

Roman Numerals
History of Numbers 1c. I can distinguish between an additive and positional system, and convert between Roman and Hindu-Arabic numbers. Roman Numerals The numeric system represented by Roman numerals originated in ancient Rome (753 BC–476 AD) and remained the usual way of writing numbers throughout Europe well into the Late Middle Ages. By the 11th century, the more efJicient Hindu–Arabic numerals had been introduced into Europe by way of Arab traders. Roman numerals, however, remained in commo use well into the 14th and 15th centuries, even in accounting and other business records (where the actual calculations would have been made using an abacus). Roman numerals are still used today, in certain contexts. See: Modern Uses of Roman Numerals Numbers in this system are represented by combinations of letters from the Latin alphabet. Roman numerals, as used today, are based on seven symbols: The numbers 1 to 10 are expressed in Roman numerals as: I, II, III, IV, V, VI, VII, VIII, IX, X. This an additive system. Numbers are formed by combining symbols and adding together their values. For example, III is three (three ones) and XIII is thirteen (a ten plus three ones). Because each symbol (I, V, X ...) has a Jixed value rather than representing multiples of ten, one hundred and so on (according to the numeral's position) there is no need for “place holding” zeros, as in numbers like 207 or 1066. Using Roman numerals, those numbers are written as CCVII (two hundreds, plus a ive and two ones) and MLXVI (a thousand plus a ifty plus a ten, a ive and a one). -

The Roman Empire – Roman Coins Lesson 1
Year 4: The Roman Empire – Roman Coins Lesson 1 Duration 2 hours. Date: Planned by Katrina Gray for Two Temple Place, 2014 Main teaching Activities - Differentiation Plenary LO: To investigate who the Romans were and why they came Activities: Mixed Ability Groups. AFL: Who were the Romans? to Britain Cross curricular links: Geography, Numeracy, History Activity 1: AFL: Why did the Romans want to come to Britain? CT to introduce the topic of the Romans and elicit children’s prior Sort timeline flashcards into chronological order CT to refer back to the idea that one of the main reasons for knowledge: invasion was connected to wealth and money. Explain that Q Who were the Romans? After completion, discuss the events as a whole class to ensure over the next few lessons we shall be focusing on Roman Q What do you know about them already? that the children understand the vocabulary and events described money / coins. Q Where do they originate from? * Option to use CT to show children a map, children to locate Rome and Britain. http://www.schoolsliaison.org.uk/kids/preload.htm or RESOURCES Explain that the Romans invaded Britain. http://resources.woodlands-junior.kent.sch.uk/homework/romans.html Q What does the word ‘invade’ mean? for further information about the key dates and events involved in Websites: the Roman invasion. http://www.schoolsliaison.org.uk/kids/preload.htm To understand why they invaded Britain we must examine what http://www.sparklebox.co.uk/topic/past/roman-empire.html was happening in Britain before the invasion. -

2014) ADVANCED)DIVISION) ) Page)1) ROUND)I
MASSACHUSETTS)CERTAMEN),)2014) ADVANCED)DIVISION) ) Page)1) ROUND)I 1:! TU:!!! What!pair!of!Babylonian!lovers!planned!to!meet!at!the!tomb!of!Ninus,!but!were!thwarted!by!a!lioness?) PYRAMUS)AND)THISBE! B1:!!! What!did!Pyramus!do!when!he!found!Thisbe’s!bloody!veil!and!thought!she!was!dead?! ! ! ! ! KILLED)HIMSELF! B2:!!! What!plant!forever!changed!color!when!it!was!splattered!with!Pyramus’!and!Thisbe’s!blood?! ! ! ! ! MULBERRY) ) ) 2:! TU:! For!the!verb!fallō,)give!the!3rd!person!singular,!perfect,!active!subjunctive.! ) FEFELLERIT! B1:! Give!the!corresponding!form!of!disco.! ) DIDICERIT! B2:! Give!the!corresponding!form!of!fio.! ) FACTUS)(A,UM))SIT) ) ) 3:! TU:! Who!was!the!victorious!general!at!the!battle!of!Pydna!in!168!BC?! ) AEMELIUS)PAULUS! B1:! Who!was!the!son!of!Aemelius!Paulus!that!sacked!Corinth!in!146!BC?! ! ! ! ! SCIPIO)AEMELIANUS) ! B2:! Scipio!Aemelianus!was!adopted!by!which!flamen-dialis,-thus!making!him!part!of!a!more!aristocratic!family?! ) (PUBLIUS)CORNELIUS))SCIPIO)AFRICANUS) ) ) 4:! TU:!! According!to!its!derivation,!an!irascible!person!is!easy!to!put!into!what!kind!of!mood?! ) ANGER/ANGRY! B1:!! Give!the!Latin!verb!and!its!meaning!from!which!the!English!word!“sample”!is!derived.) EMŌ)–)TO)BUY! B2:!! Give!the!Latin!noun!and!its!meaning!from!which!the!English!word!“rush”!is!derived.! ) CAUSA)–)REASON,)CAUSE) ) [SCORE)CHECK]) ) 5:! TU:!!! What!Paduan!prose!author!of!the!Augustan!age!wrote!a!history!of!Rome!in!142!books?) TITUS)LIVIUS/LIVY! B1:!!! What!was!the!Latin!title!of!Livy’s!history?! ) AB)URBE)CONDITA! B2:!!! Which!of!the!following!topics!is!not!covered!in!one!of!the!35!extant!books!of!Ab-Urbe-Condita:!!! -

Bana Braille Codes Update 2007
BANA BRAILLE CODES UPDATE 2007 Developed Under the Sponsorship of the BRAILLE AUTHORITY OF NORTH AMERICA Effective Date: January 1, 2008 BANA MEMBERS American Council of the Blind American Foundation for the Blind American Printing House for the Blind Associated Services for the Blind and Visually Impaired Association for Education and Rehabilitation of the Blind and Visually Impaired Braille Institute of America California Transcribers and Educators of the Visually Handicapped Canadian Association of Educational Resource Centres for Alternate Format Materials The Clovernook Center for the Blind and Visually Impaired CNIB (Canadian National Institute for the Blind) National Braille Association National Braille Press National Federation of the Blind National Library Service for the Blind and Physically Handicapped, Library of Congress Royal New Zealand Foundation of the Blind. Associate Member Publications Committee Susan Christensen, Chairperson Judy Dixon, Board Liaison Bob Brasher Warren Figueiredo Sandy Smith Joanna E. Venneri Copyright © by the Braille Authority of North America. This material may be duplicated but not altered. This document is available for download in various formats from www.brailleauthority.org. 2 TABLE OF CONTENTS INTRODUCTION ENGLISH BRAILLE, AMERICAN EDITION, REVISED 2002 ....... L1 Table of Changes.................................................................. L2 Definition of Braille ............................................................... L3 Rule I: Punctuation Signs .....................................................L13 -

Arabic Numeral
CHAPTER 4 Number Representation and Calculation Copyright © 2015, 2011, 2007 Pearson Education, Inc. Section 4.4, Slide 1 4.4 Looking Back at Early Numeration Systems Copyright © 2015, 2011, 2007 Pearson Education, Inc. Section 4.4, Slide 2 Objectives 1. Understand and use the Egyptian system. 2. Understand and use the Roman system. 3. Understand and use the traditional Chinese system. 4. Understand and use the Ionic Greek system. Copyright © 2015, 2011, 2007 Pearson Education, Inc. Section 4.4, Slide 3 The Egyptian Numeration System The Egyptians used the oldest numeration system called hieroglyphic notation. Copyright © 2015, 2011, 2007 Pearson Education, Inc. Section 4.4, Slide 4 Example: Using the Egyptian Numeration System Write the following numeral as a Hindu-Arabic numeral: Solution: Using the table, find the value of each of the Egyptian numerals. Then add them. 1,000,000 + 10,000 + 10,000 + 10 + 10 + 10 + 1 + 1 + 1 + 1 = 1,020,034 Copyright © 2015, 2011, 2007 Pearson Education, Inc. Section 4.4, Slide 5 Example: Using the Egyptian Numeration System Write 1752 as an Egyptian numeral. Solution: First break down the Hindu-Arabic numeral into quantities that match the Egyptian numerals: 1752 = 1000 + 700 + 50 + 2 = 1000 + 100 + 100 + 100 + 100 + 100 + 100 + 100 + 10 + 10 + 10 + 10 + 10 + 1 + 1 Now use the table to find the Egyptian symbol that matches each quantity. Thus, 1752 can be expressed as Copyright © 2015, 2011, 2007 Pearson Education, Inc. Section 4.4, Slide 6 The Roman Numeration System Roman I V X L C D M Numeral Hindu- 1 5 10 50 100 500 1000 Arabic Numeral The Roman numerals were used until the eighteenth century and are still commonly used today for outlining, on clocks, and in numbering some pages in books. -

Ancient Roman Measures Page 1 of 6
Ancient Roman Measures Page 1 of 6 Ancient Rome Table of Measures of Length/Distance Name of Unit (Greek) Digitus Meters 01-Digitus (Daktylos) 1 0.0185 02-Uncia - Polex 1.33 0.0246 03-Duorum Digitorum (Condylos) 2 0.037 04-Palmus (Pala(i)ste) 4 0.074 05-Pes Dimidius (Dihas) 8 0.148 06-Palma Porrecta (Orthodoron) 11 0.2035 07-Palmus Major (Spithame) 12 0.222 08-Pes (Pous) 16 0.296 09-Pugnus (Pygme) 18 0.333 10-Palmipes (Pygon) 20 0.370 11-Cubitus - Ulna (pechus) 24 0.444 12-Gradus – Pes Sestertius (bema aploun) 40 0.74 13-Passus (bema diploun) 80 1.48 14-Ulna Extenda (Orguia) 96 1.776 15-Acnua -Dekempeda - Pertica (Akaina) 160 2.96 16-Actus 1920 35.52 17-Actus Stadium 10000 185 18-Stadium (Stadion Attic) 10000 185 19-Milliarium - Mille passuum 80000 1480 20-Leuka - Leuga 120000 2220 http://www.anistor.gr/history/diophant.html Ancient Roman Measures Page 2 of 6 Table of Measures of Area Name of Unit Pes Quadratus Meters2 01-Pes Quadratus 1 0.0876 02-Dimidium scrupulum 50 4.38 03-Scripulum - scrupulum 100 8.76 04-Actus minimus 480 42.048 05-Uncia 2400 210.24 06-Clima 3600 315.36 07-Sextans 4800 420.48 08-Actus quadratus 14400 1261.44 09-Arvum - Arura 22500 1971 10-Jugerum 28800 2522.88 11-Heredium 57600 5045.76 12-Centuria 5760000 504576 13-Saltus 23040000 2018304 http://www.anistor.gr/history/diophant.html Ancient Roman Measures Page 3 of 6 Table of Measures of Liquids Name of Unit Ligula Liters 01-Ligula 1 0.0114 02-Uncia (metric) 2 0.0228 03-Cyathus 4 0.0456 04-Acetabulum 6 0.0684 05-Sextans 8 0.0912 06-Quartarius – Quadrans 12 0.1368 -

Coins and Medals Including Renaissance and Later Medals from the Collection of Dr Charles Avery and Byzantine Coins from the Estate of Carroll F
Coins and Medals including Renaissance and Later Medals from the Collection of Dr Charles Avery and Byzantine Coins from the Estate of Carroll F. Wales (Part I) To be sold by auction at: Sotheby’s, in the Upper Grosvenor Gallery The Aeolian Hall, Bloomfield Place New Bond Street London W1 Days of Sale: Wednesday 11 and Thursday 12 June 2008 10.00 am and 2.00 pm Public viewing: 45 Maddox Street, London W1S 2PE Friday 6 June 10.00 am to 4.30 pm Monday 9 June 10.00 am to 4.30 pm Tuesday 10 June 10.00 am to 4.30 pm Or by previous appointment. Catalogue no. 31 Price £10 Enquiries: James Morton, Tom Eden, Paul Wood, Jeremy Cheek or Stephen Lloyd Cover illustrations: Lot 465 (front); Lot 1075 (back); Lot 515 (inside front and back covers, all at two-thirds actual size) in association with 45 Maddox Street, London W1S 2PE Tel.: +44 (0)20 7493 5344 Fax: +44 (0)20 7495 6325 Email: [email protected] Website: www.mortonandeden.com This auction is conducted by Morton & Eden Ltd. in accordance with our Conditions of Business printed at the back of this catalogue. All questions and comments relating to the operation of this sale or to its content should be addressed to Morton & Eden Ltd. and not to Sotheby’s. Important Information for Buyers All lots are offered subject to Morton & Eden Ltd.’s Conditions of Business and to reserves. Estimates are published as a guide only and are subject to review. The actual hammer price of a lot may well be higher or lower than the range of figures given and there are no fixed “starting prices”. -

Cuomo, Serafina (2007) Measures for an Emperor: Volusius Maecianus’ Monetary Pamphlet for Marcus Aurelius
CORE Metadata, citation and similar papers at core.ac.uk Provided by Birkbeck Institutional Research Online Birkbeck ePrints: an open access repository of the research output of Birkbeck College http://eprints.bbk.ac.uk Cuomo, Serafina (2007) Measures for an emperor: Volusius Maecianus’ monetary pamphlet for Marcus Aurelius. In: König, Jason and Whitmarsh, Tim Ordering knowledge in the Roman Empire. Cambridge: Cambridge University Press. pp.206- 228. This is an author-produced version of a chapter published by Cambridge University Press in 2007 (ISBN 9780521859691). All articles available through Birkbeck ePrints are protected by intellectual property law, including copyright law. Any use made of the contents should comply with the relevant law. © Cambridge University Press 2007. Reprinted with permission. Citation for this version: Cuomo, Serafina (2007) Measures for an emperor: Volusius Maecianus’ monetary pamphlet for Marcus Aurelius. London: Birkbeck ePrints. Available at: http://eprints.bbk.ac.uk/631 Citation for the publisher’s version: Cuomo, Serafina (2007) Measures for an emperor: Volusius Maecianus’ monetary pamphlet for Marcus Aurelius. In: König, Jason and Whitmarsh, Tim Ordering knowledge in the Roman Empire. Cambridge: Cambridge University Press. pp.206-228. http://eprints.bbk.ac.uk Contact Birkbeck ePrints at [email protected] 1 Measures for an emperor: Volusius Maecianus’ monetary pamphlet for Marcus Aurelius To the Greeks the Muse gave intellect and well-rounded speech; they are greedy only for praise. Roman children, with lengthy calculations, learn to divide the as into a hundred parts.1 Like many clichés, Horace’s sour depiction of Roman pragmatism has some truth to it – except that the Greeks were just as interested as the Romans in correctly dividing currency into parts. -

A Handbook of Greek and Roman Coins
CORNELL UNIVERSITY LIBRARY BOUGHT WITH THE INCOME OF THE SAGE ENDOWMENT FUND GIVEN IN 1891 BY HENRY WILLIAMS SAGE Cornell University Library CJ 237.H64 A handbook of Greek and Roman coins. 3 1924 021 438 399 Cornell University Library The original of this book is in the Cornell University Library. There are no known copyright restrictions in the United States on the use of the text. http://www.archive.org/details/cu31924021438399 f^antilioofcs of glrcfjaeologj) anU Antiquities A HANDBOOK OF GREEK AND ROMAN COINS A HANDBOOK OF GREEK AND ROMAN COINS G. F. HILL, M.A. OF THE DEPARTMENT OF COINS AND MEDALS IN' THE bRITISH MUSEUM WITH FIFTEEN COLLOTYPE PLATES Hon&on MACMILLAN AND CO., Limited NEW YORK: THE MACMILLAN COMPANY l8 99 \_All rights reserved'] ©jcforb HORACE HART, PRINTER TO THE UNIVERSITY PREFACE The attempt has often been made to condense into a small volume all that is necessary for a beginner in numismatics or a young collector of coins. But success has been less frequent, because the knowledge of coins is essentially a knowledge of details, and small treatises are apt to be un- readable when they contain too many references to particular coins, and unprofltably vague when such references are avoided. I cannot hope that I have passed safely between these two dangers ; indeed, my desire has been to avoid the second at all risk of encountering the former. At the same time it may be said that this book is not meant for the collector who desires only to identify the coins which he happens to possess, while caring little for the wider problems of history, art, mythology, and religion, to which coins sometimes furnish the only key. -

On the Roman Frontier1
Rome and the Worlds Beyond Its Frontiers Impact of Empire Roman Empire, c. 200 B.C.–A.D. 476 Edited by Olivier Hekster (Radboud University, Nijmegen, The Netherlands) Editorial Board Lukas de Blois Angelos Chaniotis Ségolène Demougin Olivier Hekster Gerda de Kleijn Luuk de Ligt Elio Lo Cascio Michael Peachin John Rich Christian Witschel VOLUME 21 The titles published in this series are listed at brill.com/imem Rome and the Worlds Beyond Its Frontiers Edited by Daniëlle Slootjes and Michael Peachin LEIDEN | BOSTON This is an open access title distributed under the terms of the CC-BY-NC 4.0 License, which permits any non-commercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited. The Library of Congress Cataloging-in-Publication Data is available online at http://catalog.loc.gov LC record available at http://lccn.loc.gov/2016036673 Typeface for the Latin, Greek, and Cyrillic scripts: “Brill”. See and download: brill.com/brill-typeface. issn 1572-0500 isbn 978-90-04-32561-6 (hardback) isbn 978-90-04-32675-0 (e-book) Copyright 2016 by Koninklijke Brill NV, Leiden, The Netherlands. Koninklijke Brill NV incorporates the imprints Brill, Brill Hes & De Graaf, Brill Nijhoff, Brill Rodopi and Hotei Publishing. All rights reserved. No part of this publication may be reproduced, translated, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without prior written permission from the publisher. Authorization to photocopy items for internal or personal use is granted by Koninklijke Brill NV provided that the appropriate fees are paid directly to The Copyright Clearance Center, 222 Rosewood Drive, Suite 910, Danvers, MA 01923, USA. -

3927 25.90 Brass 6 Obols / Sestertius 3928 24.91
91 / 140 THE COINAGE SYSTEM OF CLEOPATRA VII, MARC ANTONY AND AUGUSTUS IN CYPRUS 3927 25.90 brass 6 obols / sestertius 3928 24.91 brass 6 obols / sestertius 3929 14.15 brass 3 obols / dupondius 3930 16.23 brass same (2 examples weighed) 3931 6.72 obol / 2/3 as (3 examples weighed) 3932 9.78 3/2 obol / as *Not struck at a Cypriot mint. 92 / 140 THE COINAGE SYSTEM OF CLEOPATRA VII, MARC ANTONY AND AUGUSTUS IN CYPRUS Cypriot Coinage under Tiberius and Later, After 14 AD To the people of Cyprus, far from the frontiers of the Empire, the centuries of the Pax Romana formed an uneventful although contented period. Mattingly notes, “Cyprus . lay just outside of the main currents of life.” A population unused to political independence or democratic institutions did not find Roman rule oppressive. Radiate Divus Augustus and laureate Tiberius on c. 15.6g Cypriot dupondius - triobol. In c. 15-16 AD the laureate head of Tiberius was paired with Livia seated right (RPC 3919, as) and paired with that of Divus Augustus (RPC 3917 and 3918 dupondii). Both types are copied from Roman Imperial types of the early reign of Tiberius. For his son Drusus, hemiobols were struck with the reverse designs begun by late in the reign of Cleopatra: Zeus Salaminios and the Temple of Aphrodite at Paphos. In addition, a reverse with both of these symbols was struck. Drusus obverse was paired with either Zeus Salaminios, or Temple of Aphrodite reverses, as well as this reverse that shows both. (4.19g) Conical black stone found in 1888 near the ruins of the temple of Aphrodite at Paphos, now in the Museum of Kouklia.