NVAX-Microprocessor VAX Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Engineering Specification for the KA43 Processor Module Revision 1.0 1–May–1989 COMPANY CONFIDENTIAL RESTRICTED DISTRIBUTION
Engineering Specification for the KA43 Processor Module Revision 1.0 1–May–1989 COMPANY CONFIDENTIAL RESTRICTED DISTRIBUTION COPYRIGHT (c) 1989 by DIGITAL EQUIPMENT CORPORATION This information shall not be disclosed to non-Digital personnel or generally distributed within Digital. Distribution is restricted to persons authorized and designated by the responsible en- gineer or manager. This document shall not be left unattended, and when not in use shall be stored in a locked storage container. The information in this document is subject to change without notice and should not be construed as a commitment by Digital Equipment Corporation. Digital Equipment Corporation assumes no responsibility for any errors that may occur in this document. The information in this document does not describe any program or product currently available from Digital Equipment Corporation. Nor does Digital Equipment Corporation commit to imple- ment this specification in any program or product. Digital Equipment Corporation makes no commitment that this document accurately describes any product which it might ever make. Digital Equipment Corporation CONTENTS Preface . ........................................................... v Chapter 1 INTRODUCTION .............................................. 1 1.1 Scope of Document ................................................... 1 1.2 General Description .................................................. 1 1.3 Applicable Documents ................................................. 2 Chapter 2 KA43 ROM MEMORY ........................................ -

Validated Products List, 1995 No. 3: Programming Languages, Database
NISTIR 5693 (Supersedes NISTIR 5629) VALIDATED PRODUCTS LIST Volume 1 1995 No. 3 Programming Languages Database Language SQL Graphics POSIX Computer Security Judy B. Kailey Product Data - IGES Editor U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 July 1995 QC 100 NIST .056 NO. 5693 1995 NISTIR 5693 (Supersedes NISTIR 5629) VALIDATED PRODUCTS LIST Volume 1 1995 No. 3 Programming Languages Database Language SQL Graphics POSIX Computer Security Judy B. Kailey Product Data - IGES Editor U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 July 1995 (Supersedes April 1995 issue) U.S. DEPARTMENT OF COMMERCE Ronald H. Brown, Secretary TECHNOLOGY ADMINISTRATION Mary L. Good, Under Secretary for Technology NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY Arati Prabhakar, Director FOREWORD The Validated Products List (VPL) identifies information technology products that have been tested for conformance to Federal Information Processing Standards (FIPS) in accordance with Computer Systems Laboratory (CSL) conformance testing procedures, and have a current validation certificate or registered test report. The VPL also contains information about the organizations, test methods and procedures that support the validation programs for the FIPS identified in this document. The VPL includes computer language processors for programming languages COBOL, Fortran, Ada, Pascal, C, M[UMPS], and database language SQL; computer graphic implementations for GKS, COM, PHIGS, and Raster Graphics; operating system implementations for POSIX; Open Systems Interconnection implementations; and computer security implementations for DES, MAC and Key Management. -

The Design and Verification of the Alphastation 600 5-Series Workstation by John H
The Design and Verification of the AlphaStation 600 5-series Workstation by John H. Zurawski, John E. Murray, and Paul J. Lemmon ABSTRACT The AlphaStation 600 5-series workstation is a high-performance, uniprocessor design based on the Alpha 21164 microprocessor and on the PCI bus. Six CMOS ASICs provide high-bandwidth, low-latency interconnects between the CPU, the main memory, and the I/O subsystem. The verification effort used directed, pseudorandom testing on a VERILOG software model. A hardware-based verification technique provided a test throughput that resulted in a significant improvement over software tests. This technique currently involves the use of graphics cards to emulate generic DMA devices. A PCI hardware demon is under development to further enhance the capability of the hardware-based verification. INTRODUCTION The high-performance AlphaStation 600 5-series workstation is based on the fastest Alpha microprocessor to date -- the Alpha 21164.[1] The I/O subsystem uses the 64-bit version of the Peripheral Component Interconnect (PCI) and the Extended Industry Standard Architecture (EISA) bus. The AlphaStation 600 supports three operating systems: Digital UNIX (formerly DEC OSF/1), OpenVMS, and Microsoft's Windows NT. This workstation series uses the DECchip 21171 chip set designed and built by Digital. These chips provide high-bandwidth, low-latency interconnects between the CPU, the main memory, and the PCI bus. This paper describes the architecture and features of the AlphaStation 600 5-series workstation and the DECchip 21171 chip set. The system overview is first presented, followed by a detailed discussion of the chip set. The paper then describes the cache and memory designs, detailing how the memory design evolved from the workstation's requirements. -

Energy-Efficient VLSI Architectures for Next
UNIVERSITY OF CALIFORNIA Los Angeles Energy-Efficient VLSI Architectures for Next- Generation Software-Defined and Cognitive Radios A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Electrical Engineering by Fang-Li Yuan 2014 c Copyright by Fang-Li Yuan 2014 ABSTRACT OF THE DISSERTATION Energy-Efficient VLSI Architectures for Next- Generation Software-Defined and Cognitive Radios by Fang-Li Yuan Doctor of Philosophy in Electrical Engineering University of California, Los Angeles, 2014 Professor Dejan Markovic,´ Chair Dedicated radio hardware is no longer promising as it was in the past. Today, the support of diverse standards dictates more flexible solutions. Software-defined radio (SDR) provides the flexibility by replacing dedicated blocks (i.e. ASICs) with more general processors to adapt to various functions, standards and even allow mutable de- sign changes. However, such replacement generally incurs significant efficiency loss in circuits, hindering its feasibility for energy-constrained devices. The capability of dy- namic and blind spectrum analysis, as featured in the cognitive radio (CR) technology, makes chip implementation even more challenging. This work discusses several design techniques to achieve near-ASIC energy effi- ciency while providing the flexibility required by software-defined and cognitive radios. The algorithm-architecture co-design is used to determine domain-specific dataflow ii structures to achieve the right balance between energy efficiency and flexibility. The flexible instruction-set-architecture (ISA), the multi-scale interconnects, and the multi- core dynamic scheduling are also proposed to reduce the energy overhead. We demon- strate these concepts on two real-time blind classification chips for CR spectrum anal- ysis, as well as a 16-core processor for baseband SDR signal processing. -

Arithmetic and Logical Unit Design for Area Optimization for Microcontroller Amrut Anilrao Purohit 1,2 , Mohammed Riyaz Ahmed 2 and R
et International Journal on Emerging Technologies 11 (2): 668-673(2020) ISSN No. (Print): 0975-8364 ISSN No. (Online): 2249-3255 Arithmetic and Logical Unit Design for Area Optimization for Microcontroller Amrut Anilrao Purohit 1,2 , Mohammed Riyaz Ahmed 2 and R. Venkata Siva Reddy 2 1Research Scholar, VTU Belagavi (Karnataka), India. 2School of Electronics and Communication Engineering, REVA University Bengaluru, (Karnataka), India. (Corresponding author: Amrut Anilrao Purohit) (Received 04 January 2020, Revised 02 March 2020, Accepted 03 March 2020) (Published by Research Trend, Website: www.researchtrend.net) ABSTRACT: Arithmetic and Logic Unit (ALU) can be understood with basic knowledge of digital electronics and any engineer will go through the details only once. The advantage of knowing ALU in detail is two- folded: firstly, programming of the processing device can be efficient and secondly, can design a new ALU architecture as per the various constraints of the use cases. The miniaturization of digital circuits can be achieved by either reducing the size of transistor (Moore’s law) or by optimizing the gate count of the circuit. The first has been explored extensively while the latter has been ignored which deals with the application of Boolean rules and requires sound knowledge of logic design. The ultimate outcome is to have an area optimized architecture/approach that optimizes the circuit at gate level. The design of ALU is for various processing devices varies with the device/system requirements. The area optimization places a significant role in the chip design. Here in this work, we have attempted to design an ALU which is area efficient while being loaded with additional functionality necessary for microcontrollers. -

Unit 8 : Microprocessor Architecture
Unit 8 : Microprocessor Architecture Lesson 1 : Microcomputer Structure 1.1. Learning Objectives On completion of this lesson you will be able to : ♦ draw the block diagram of a simple computer ♦ understand the function of different units of a microcomputer ♦ learn the basic operation of microcomputer bus system. 1.2. Digital Computer A digital computer is a multipurpose, programmable machine that reads A digital computer is a binary instructions from its memory, accepts binary data as input and multipurpose, programmable processes data according to those instructions, and provides results as machine. output. 1.3. Basic Computer System Organization Every computer contains five essential parts or units. They are Basic computer system organization. i. the arithmetic logic unit (ALU) ii. the control unit iii. the memory unit iv. the input unit v. the output unit. 1.3.1. The Arithmetic and Logic Unit (ALU) The arithmetic and logic unit (ALU) is that part of the computer that The arithmetic and logic actually performs arithmetic and logical operations on data. All other unit (ALU) is that part of elements of the computer system - control unit, register, memory, I/O - the computer that actually are there mainly to bring data into the ALU to process and then to take performs arithmetic and the results back out. logical operations on data. An arithmetic and logic unit and, indeed, all electronic components in the computer are based on the use of simple digital logic devices that can store binary digits and perform simple Boolean logic operations. Data are presented to the ALU in registers. These registers are temporary storage locations within the CPU that are connected by signal paths of the ALU. -

Mi!!Lxlosalamos SCIENTIFIC LABORATORY
LA=8902-MS C3b ClC-l 4 REPORT COLLECTION REPRODUCTION COPY VAXNMS Benchmarking 1-’ > .— u) 9 g .— mi!!lxLOS ALAMOS SCIENTIFIC LABORATORY Post Office Box 1663 Los Alamos. New Mexico 87545 — wAifiimative Action/Equal Opportunity Employer b . l)lS(”L,\l\ll K “Thisreport wm prcpmd J, an xcttunt ,,1”wurk ,pmwrd by an dgmcy d the tlnitwl SIdtcs (kvcm. mm:. Ncit her t hc llniml SIJIL.. ( Lwcrnmcm nor any .gcncy tlhmd. nor my 08”Ihcif cmployccs. makci my wur,nly. mprcss w mphd. or JwImL.s m> lcg.d Iululity ur rcspmuhdily ltw Ilw w.cur- acy. .vmplctcncs. w uscftthtc>. ttt”any ml’ormdt ml. dpprdl us. prudu.i. w proccw didowd. or rep. resent%Ihd IIS us wuukl not mfrm$e priwtcly mvnd rqdtts. Itcl”crmcti herein 10 my sp.xi!l tom. mrcial ptotlucr. prtxcm. or S.rvskc hy tdc mmw. Irdcnmrl.. nmu(a.lurm. or dwrwi~.. does nut mmwsuily mnstitutc or reply its mdursmwnt. rccummcnddton. or favorin: by the llniwd States (“mvcmment ormy qxncy thctcd. rhc V!C$VSmd opinmm d .mthor% qmxd herein do nut net’. UMrily r;~lt or died lhow. ol”the llnttcd SIJIL.S( ;ovwnnwnt or my ugcncy lhure of. UNITED STATES .. DEPARTMENT OF ENERGY CONTRACT W-7405 -ENG. 36 . ... LA-8902-MS UC-32 Issued: July 1981 G- . VAX/VMS Benchmarking Larry Creel —. I . .._- -- ----- ,. .- .-. .: .- ,.. .. ., ..,..: , .. .., . ... ..... - .-, ..:. .. *._–: - . VAX/VMS BENCHMARKING by Larry Creel ABSTRACT Primary emphasis in this report is on the perform- ance of three Digital Equipment Corporation VAX-11/780 computers at the Los Alamos National Laboratory. Programs used in the study are part of the Laboratory’s set of benchmark programs. -

VAX 4000 V96-2.3—10 Feb 1997
TM VAX 4000 V96-2.3—10 Feb 1997 DIGITAL Systems and Options Catalog Product Description VAX 4000 systems provide commercial systems performance, high availability, and a compact footprint. They support a wide range of applications and options, including FDDI networks and Q-bus peripherals. System enclosure supports internal storage and Q-bus expansion through a B400X expansion cabinet. VAX 4000 systems come in three packages: Desktop Model 106A, Desktop/Deskside Model 108, and Pedestal/Deskside Model 505A/705A DSSI and Ethernet adapter chips—each driven by a 10-MIP on-chip RISC processor—are tightly integrated on the CPU module with direct access to memory. Digital's DSSI to SCSI HSD10 storage solutions replace DSSI RF36 disk technology in all VAX 4000 systems. Digital’s HSD10 DSSI-to-SCSI controller. mounted internally in system cabinet, supports standard RZxx SCSI storage on VAX 4000 systems while still supporting DSSI clustering. External StorageWorks HSD10 controllers are supported. VAX 4000 Model 106A offers performance of 10-ns NVAX chip. Systems achieve 215 transactions per second (TPS). With internal support for the HSD10, DSSI-to-SCSI controller, VAX 4000 customers can take advantage of low-cost, more flexible and open StorageWorks solutions. VAX 4000 Model 108 offers identical performance, is compatible with Model 106A, but is housed in a new Desktop/Deskside minitower enclosure. In addition, these systems offer enchancements in the memory and storage capacity, supporting up to 512 MB of standard SIMM memory and six storage devices in the system enclosure. VAX 4000 Model 505A and 705A offer 12 ns and 9 ns performance, respectively in a Q-bus Pedestal package. -
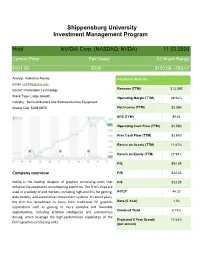
Shippensburg University Investment Management Program
Shippensburg University Investment Management Program Hold NVIDIA Corp. (NASDAQ: NVDA) 11.03.2020 Current Price Fair Value 52 Week Range $501.36 $300 $180.68 - 589.07 Analyst: Valentina Alonso Key Stock Statistics Email: [email protected] Sector: Information Technology Revenue (TTM) $13.06B Stock Type: Large Growth Operating Margin (TTM) 28.56% Industry: Semiconductors and Semiconductors Equipment Market Cap: $309.697B Net Income (TTM) $3.39B EPS (TTM) $5.44 Operating Cash Flow (TTM) $5.58B Free Cash Flow (TTM) $3.67B Return on Assets (TTM) 11.67% Return on Equity (TTM) 27.94% P/E $92.59 Company overview P/B $22.32 Nvidia is the leading designer of graphics processing units that P/S $23.29 enhance the experience on computing platforms. The firm's chips are used in a variety of end markets, including high-end PCs for gaming, P/FCF 44.22 data centers, and automotive infotainment systems. In recent years, the firm has broadened its focus from traditional PC graphics Beta (5-Year) 1.54 applications such as gaming to more complex and favorable Dividend Yield 0.13% opportunities, including artificial intelligence and autonomous driving, which leverage the high-performance capabilities of the Projected 5 Year Growth 17.44% firm's graphics processing units. (per annum) Contents Executive Summary ....................................................................................................................................................3 Company Overview ....................................................................................................................................................4 -

A Machine-Independent DMA Framework for Netbsd
AMachine-Independent DMA Framework for NetBSD Jason R. Thorpe1 Numerical Aerospace Simulation Facility NASA Ames Research Center Abstract 1.1. Host platform details One of the challenges in implementing a portable In the example platforms listed above,there are at kernel is finding good abstractions for semantically- least three different mechanisms used to perform DMA. similar operations which often have very machine- The first is used by the i386 platform. This mechanism dependent implementations. This is especially impor- can be described as "what you see is what you get": the tant on modern machines which share common archi- address that the device uses to perform the DMA trans- tectural features, e.g. the PCI bus. fer is the same address that the host CPU uses to access This paper describes whyamachine-independent the memory location in question. DMA mapping abstraction is needed, the design consid- DMA address Host address erations for such an abstraction, and the implementation of this abstraction in the NetBSD/alpha and NetBSD/i386 kernels. 1. Introduction NetBSD is a portable, modern UNIX-likeoperat- ing system which currently runs on eighteen platforms covering nine processor architectures. Some of these platforms, including the Alpha and i3862,share the PCI busasacommon architectural feature. In order to share device drivers for PCI devices between different platforms, abstractions that hide the details of bus access must be invented. The details that must be hid- den can be broken down into twoclasses: CPU access Figure 1 - WYSIWYG DMA to devices on the bus (bus_space)and device access to host memory (bus_dma). Here we will discuss the lat- The second mechanism, employed by the Alpha, ter; bus_space is a complicated topic in and of itself, is very similar to the first; the address the host CPU and is beyond the scope of this paper. -

Validated Processor List
NISTIR 4557 Programming Languages and Database Language SQL VALIDATED PROCESSOR UST Including GOSIP Conformance Testing Registers Judy B. Kailey Editor U.S. DEPARTMENT OF COMMERCE National Institute of Standards and Technology National Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 April 1991 (Supersedes January 1991 Issue) U.S. DEPARTMENT OF COMMERCE Robert A. Mosbacher, Secretary NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY John W. Lyons, Director NIST > NISTIR 4557 Programming Languages and Database Language SQL VALIDATED PROCESSOR LIST Including GOSIP Conformance Testing Registers Judy B. Kailey Editor U.S. DEPARTMENT OF COMMERCE National Institute of Standards and Technology National Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 April 1991 (Supersedes January 1991 Issue) U.S. DEPARTMENT OF COMMERCE Robert A. Mosbacher, Secretary NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY John W. Lyons, Director lib t TABLE OF CONTENTS 1. INTRODUCTION 1 1.1 Purpose 1 1.2 Document Organization 1 1.2.1 Language Processors 1 1.2.2 Contributors to the VPL 2 1.2.3 Other FIPS Conformance Testing Products 2 1.2.4 GOSIP Registers 2 1.3 FIPS Programming and Database Language Standards 3 1.4 Validation of Processors 3 1.4.1 Validation Requirements 3 1.4.2 Placement in the List 4 1.4.3 Removal from the List 4 1.4.4 Validation Procedures 4 1.5 Certificate of Validation 4 1.6 Registered Report 4 1.7 Processor Validation Suites 5 2. COBOL PROCESSORS 7 3. FORTRAN PROCESSORS 13 4. Ada PROCESSORS 21 5. Pascal PROCESSORS 35 6. SQL PROCESSORS 37 APPENDIX A CONTRIBUTORS TO THE LIST A-1 APPENDIX B OTHER FIPS CONFORMANCE TESTING B-1 APPENDIX C REGISTER OF GOSIP ABSTRACT TEST SUITES C-1 APPENDIX D REGISTER OF GOSIP MEANS OF TESTING D-1 APPENDIX E REGISTER OF GOSIP CONFORMANCE TESTING LABORATORIES E-1 . -

Digital Technical Journal, Number 7, August 1988: CVAX
Digital Technical Tournal Digital Equipment Corporation Managing Editor Richard W Beam Edltor Jane C. Dlak Pcoductloa St& Production Editor - Helen 1 Partenon Designer - Charlotte Bell Typographers -Jonathan M. Bohy Macgaret Burdine lllusultor - Deborah Kc~lcy Advisoiy Board Samuel H. Fuller, Chairman Robert M. Glorioso John W. McCredle Mahendra R. Patel F. Grant Saviers William D. Srrcckr Victor A. Vyssutsky The Digital Technical Journal is published by Digital Equipment Corporatloa, 77 Reed Road, Hudson, Magsachu~etts0 1749. Changes of address should be sent to Digital Equipment Corporation. attention: List Maintenance. I0 Forbes Road, Northboro, MA 01532 Please indude the address label wlth changes marked. Comments on the content of any paper arc welcomed. Write to the editor at Mall Stop HL02.3/K11 at the published~bpaddress. Comments can ahbe sent on the BNET to RDVAX: :BIAKEor on the ARPANET to B~%RDVAX.DE~DE~. Copyright @ 1988 Digital Equipment Corporation. Copying without fee is permitted provided that such copies are made for use in educational lnstltutions by faculty members and are nor distributed for commercial advantage. Abstncting with credit of Digital Equipment Corporation's authorship is permltted. Requests for other copies for a Pee may br made to Digiul Press of Digital Equipment Corporation. A11 rights reserved. The information in this journal is subject to change without notice and should not bc construed as a com- mltment by Digital Equipment Corporation. Digital Equipment Corpmtion assumes no responslbllity for any errors that may appcss in this document ISSN 0898.901X Documentatlcm Number EY-6742H-DP The following are wademarks of Digital Gquipmcnt Corporation: ALL.IN-I.