1 Bayes' Theorem 2 Statement of Bayes' Theorem 3 Bayes' Theorem in Terms of Likelihood
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Effective Program Reasoning Using Bayesian Inference
EFFECTIVE PROGRAM REASONING USING BAYESIAN INFERENCE Sulekha Kulkarni A DISSERTATION in Computer and Information Science Presented to the Faculties of the University of Pennsylvania in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy 2020 Supervisor of Dissertation Mayur Naik, Professor, Computer and Information Science Graduate Group Chairperson Mayur Naik, Professor, Computer and Information Science Dissertation Committee: Rajeev Alur, Zisman Family Professor of Computer and Information Science Val Tannen, Professor of Computer and Information Science Osbert Bastani, Research Assistant Professor of Computer and Information Science Suman Nath, Partner Research Manager, Microsoft Research, Redmond To my father, who set me on this path, to my mother, who leads by example, and to my husband, who is an infinite source of courage. ii Acknowledgments I want to thank my advisor Prof. Mayur Naik for giving me the invaluable opportunity to learn and experiment with different ideas at my own pace. He supported me through the ups and downs of research, and helped me make the Ph.D. a reality. I also want to thank Prof. Rajeev Alur, Prof. Val Tannen, Prof. Osbert Bastani, and Dr. Suman Nath for serving on my dissertation committee and for providing valuable feedback. I am deeply grateful to Prof. Alur and Prof. Tannen for their sound advice and support, and for going out of their way to help me through challenging times. I am also very grateful for Dr. Nath's able and inspiring mentorship during my internship at Microsoft Research, and during the collaboration that followed. Dr. Aditya Nori helped me start my Ph.D. -

1 Dependent and Independent Events 2 Complementary Events 3 Mutually Exclusive Events 4 Probability of Intersection of Events
1 Dependent and Independent Events Let A and B be events. We say that A is independent of B if P (AjB) = P (A). That is, the marginal probability of A is the same as the conditional probability of A, given B. This means that the probability of A occurring is not affected by B occurring. It turns out that, in this case, B is independent of A as well. So, we just say that A and B are independent. We say that A depends on B if P (AjB) 6= P (A). That is, the marginal probability of A is not the same as the conditional probability of A, given B. This means that the probability of A occurring is affected by B occurring. It turns out that, in this case, B depends on A as well. So, we just say that A and B are dependent. Consider these events from the card draw: A = drawing a king, B = drawing a spade, C = drawing a face card. Events A and B are independent. If you know that you have drawn a spade, this does not change the likelihood that you have actually drawn a king. Formally, the marginal probability of drawing a king is P (A) = 4=52. The conditional probability that your card is a king, given that it a spade, is P (AjB) = 1=13, which is the same as 4=52. Events A and C are dependent. If you know that you have drawn a face card, it is much more likely that you have actually drawn a king than it would be ordinarily. -

Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam
Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam Roger Barlow The University of Huddersfield August 2018 Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 1 / 34 Lecture 1: The Basics 1 Probability What is it? Frequentist Probability Conditional Probability and Bayes' Theorem Bayesian Probability 2 Probability distributions and their properties Expectation Values Binomial, Poisson and Gaussian 3 Hypothesis testing Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 2 / 34 Question: What is Probability? Typical exam question Q1 Explain what is meant by the Probability PA of an event A [1] Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 3 / 34 Four possible answers PA is number obeying certain mathematical rules. PA is a property of A that determines how often A happens For N trials in which A occurs NA times, PA is the limit of NA=N for large N PA is my belief that A will happen, measurable by seeing what odds I will accept in a bet. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 4 / 34 Mathematical Kolmogorov Axioms: For all A ⊂ S PA ≥ 0 PS = 1 P(A[B) = PA + PB if A \ B = ϕ and A; B ⊂ S From these simple axioms a complete and complicated structure can be − ≤ erected. E.g. show PA = 1 PA, and show PA 1.... But!!! This says nothing about what PA actually means. Kolmogorov had frequentist probability in mind, but these axioms apply to any definition. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 5 / 34 Classical or Real probability Evolved during the 18th-19th century Developed (Pascal, Laplace and others) to serve the gambling industry. -

Statistical Modelling
Statistical Modelling Dave Woods and Antony Overstall (Chapters 1–2 closely based on original notes by Anthony Davison and Jon Forster) c 2016 StatisticalModelling ............................... ......................... 0 1. Model Selection 1 Overview............................................ .................. 2 Basic Ideas 3 Whymodel?.......................................... .................. 4 Criteriaformodelselection............................ ...................... 5 Motivation......................................... .................... 6 Setting ............................................ ................... 9 Logisticregression................................... .................... 10 Nodalinvolvement................................... .................... 11 Loglikelihood...................................... .................... 14 Wrongmodel.......................................... ................ 15 Out-of-sampleprediction ............................. ..................... 17 Informationcriteria................................... ................... 18 Nodalinvolvement................................... .................... 20 Theoreticalaspects.................................. .................... 21 PropertiesofAIC,NIC,BIC............................... ................. 22 Linear Model 23 Variableselection ................................... .................... 24 Stepwisemethods.................................... ................... 25 Nuclearpowerstationdata............................ .................... -
3.3 Bayes' Formula
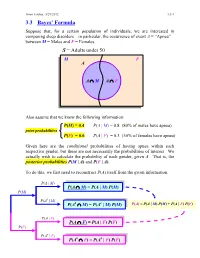
Ismor Fischer, 5/29/2012 3.3-1 3.3 Bayes’ Formula Suppose that, for a certain population of individuals, we are interested in comparing sleep disorders – in particular, the occurrence of event A = “Apnea” – between M = Males and F = Females. S = Adults under 50 M F A A ∩ M A ∩ F Also assume that we know the following information: P(M) = 0.4 P(A | M) = 0.8 (80% of males have apnea) prior probabilities P(F) = 0.6 P(A | F) = 0.3 (30% of females have apnea) Given here are the conditional probabilities of having apnea within each respective gender, but these are not necessarily the probabilities of interest. We actually wish to calculate the probability of each gender, given A. That is, the posterior probabilities P(M | A) and P(F | A). To do this, we first need to reconstruct P(A) itself from the given information. P(A | M) P(A ∩ M) = P(A | M) P(M) P(M) P(Ac | M) c c P(A ∩ M) = P(A | M) P(M) P(A) = P(A | M) P(M) + P(A | F) P(F) P(A | F) P(A ∩ F) = P(A | F) P(F) P(F) P(Ac | F) c c P(A ∩ F) = P(A | F) P(F) Ismor Fischer, 5/29/2012 3.3-2 So, given A… P(M ∩ A) P(A | M) P(M) P(M | A) = P(A) = P(A | M) P(M) + P(A | F) P(F) (0.8)(0.4) 0.32 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.64 and posterior P(F ∩ A) P(A | F) P(F) P(F | A) = = probabilities P(A) P(A | M) P(M) + P(A | F) P(F) (0.3)(0.6) 0.18 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.36 S Thus, the additional information that a M F randomly selected individual has apnea (an A event with probability 50% – why?) increases the likelihood of being male from a prior probability of 40% to a posterior probability 0.32 0.18 of 64%, and likewise, decreases the likelihood of being female from a prior probability of 60% to a posterior probability of 36%. -

Lecture 2: Modeling Random Experiments
Department of Mathematics Ma 3/103 KC Border Introduction to Probability and Statistics Winter 2021 Lecture 2: Modeling Random Experiments Relevant textbook passages: Pitman [5]: Sections 1.3–1.4., pp. 26–46. Larsen–Marx [4]: Sections 2.2–2.5, pp. 18–66. 2.1 Axioms for probability measures Recall from last time that a random experiment is an experiment that may be conducted under seemingly identical conditions, yet give different results. Coin tossing is everyone’s go-to example of a random experiment. The way we model random experiments is through the use of probabilities. We start with the sample space Ω, the set of possible outcomes of the experiment, and consider events, which are subsets E of the sample space. (We let F denote the collection of events.) 2.1.1 Definition A probability measure P or probability distribution attaches to each event E a number between 0 and 1 (inclusive) so as to obey the following axioms of probability: Normalization: P (?) = 0; and P (Ω) = 1. Nonnegativity: For each event E, we have P (E) > 0. Additivity: If EF = ?, then P (∪ F ) = P (E) + P (F ). Note that while the domain of P is technically F, the set of events, that is P : F → [0, 1], we may also refer to P as a probability (measure) on Ω, the set of realizations. 2.1.2 Remark To reduce the visual clutter created by layers of delimiters in our notation, we may omit some of them simply write something like P (f(ω) = 1) orP {ω ∈ Ω: f(ω) = 1} instead of P {ω ∈ Ω: f(ω) = 1} and we may write P (ω) instead of P {ω} . -

Introduction to Bayesian Estimation
Introduction to Bayesian Estimation March 2, 2016 The Plan 1. What is Bayesian statistics? How is it different from frequentist methods? 2. 4 Bayesian Principles 3. Overview of main concepts in Bayesian analysis Main reading: Ch.1 in Gary Koop's Bayesian Econometrics Additional material: Christian P. Robert's The Bayesian Choice: From decision theoretic foundations to Computational Implementation Gelman, Carlin, Stern, Dunson, Wehtari and Rubin's Bayesian Data Analysis Probability and statistics; What's the difference? Probability is a branch of mathematics I There is little disagreement about whether the theorems follow from the axioms Statistics is an inversion problem: What is a good probabilistic description of the world, given the observed outcomes? I There is some disagreement about how we interpret data/observations and how we make inference about unobservable parameters Why probabilistic models? Is the world characterized by randomness? I Is the weather random? I Is a coin flip random? I ECB interest rates? It is difficult to say with certainty whether something is \truly" random. Two schools of statistics What is the meaning of probability, randomness and uncertainty? Two main schools of thought: I The classical (or frequentist) view is that probability corresponds to the frequency of occurrence in repeated experiments I The Bayesian view is that probabilities are statements about our state of knowledge, i.e. a subjective view. The difference has implications for how we interpret estimated statistical models and there is no general -

Naïve Bayes Classifier
CS 60050 Machine Learning Naïve Bayes Classifier Some slides taken from course materials of Tan, Steinbach, Kumar Bayes Classifier ● A probabilistic framework for solving classification problems ● Approach for modeling probabilistic relationships between the attribute set and the class variable – May not be possible to certainly predict class label of a test record even if it has identical attributes to some training records – Reason: noisy data or presence of certain factors that are not included in the analysis Probability Basics ● P(A = a, C = c): joint probability that random variables A and C will take values a and c respectively ● P(A = a | C = c): conditional probability that A will take the value a, given that C has taken value c P(A,C) P(C | A) = P(A) P(A,C) P(A | C) = P(C) Bayes Theorem ● Bayes theorem: P(A | C)P(C) P(C | A) = P(A) ● P(C) known as the prior probability ● P(C | A) known as the posterior probability Example of Bayes Theorem ● Given: – A doctor knows that meningitis causes stiff neck 50% of the time – Prior probability of any patient having meningitis is 1/50,000 – Prior probability of any patient having stiff neck is 1/20 ● If a patient has stiff neck, what’s the probability he/she has meningitis? P(S | M )P(M ) 0.5×1/50000 P(M | S) = = = 0.0002 P(S) 1/ 20 Bayesian Classifiers ● Consider each attribute and class label as random variables ● Given a record with attributes (A1, A2,…,An) – Goal is to predict class C – Specifically, we want to find the value of C that maximizes P(C| A1, A2,…,An ) ● Can we estimate -

Numerical Physics with Probabilities: the Monte Carlo Method and Bayesian Statistics Part I for Assignment 2
Numerical Physics with Probabilities: The Monte Carlo Method and Bayesian Statistics Part I for Assignment 2 Department of Physics, University of Surrey module: Energy, Entropy and Numerical Physics (PHY2063) 1 Numerical Physics part of Energy, Entropy and Numerical Physics This numerical physics course is part of the second-year Energy, Entropy and Numerical Physics mod- ule. It is online at the EENP module on SurreyLearn. See there for assignments, deadlines etc. The course is about numerically solving ODEs (ordinary differential equations) and PDEs (partial differential equations), and introducing the (large) part of numerical physics where probabilities are used. This assignment is on numerical physics of probabilities, and looks at the Monte Carlo (MC) method, and at the Bayesian statistics approach to data analysis. It covers MC and Bayesian statistics, in that order. MC is a widely used numerical technique, it is used, amongst other things, for modelling many random processes. MC is used in fields from statistical physics, to nuclear and particle physics. Bayesian statistics is a powerful data analysis method, and is used everywhere from particle physics to spam-email filters. Data analysis is fundamental to science. For example, analysis of the data from the Large Hadron Collider was required to extract a most probable value for the mass of the Higgs boson, together with an estimate of the region of masses where the scientists think the mass is. This region is typically expressed as a range of mass values where the they think the true mass lies with high (e.g., 95%) probability. Many of you will be analysing data (physics data, commercial data, etc) for your PTY or RY, or future careers1 . -

The Bayesian Approach to Statistics
THE BAYESIAN APPROACH TO STATISTICS ANTHONY O’HAGAN INTRODUCTION the true nature of scientific reasoning. The fi- nal section addresses various features of modern By far the most widely taught and used statisti- Bayesian methods that provide some explanation for the rapid increase in their adoption since the cal methods in practice are those of the frequen- 1980s. tist school. The ideas of frequentist inference, as set out in Chapter 5 of this book, rest on the frequency definition of probability (Chapter 2), BAYESIAN INFERENCE and were developed in the first half of the 20th century. This chapter concerns a radically differ- We first present the basic procedures of Bayesian ent approach to statistics, the Bayesian approach, inference. which depends instead on the subjective defini- tion of probability (Chapter 3). In some respects, Bayesian methods are older than frequentist ones, Bayes’s Theorem and the Nature of Learning having been the basis of very early statistical rea- Bayesian inference is a process of learning soning as far back as the 18th century. Bayesian from data. To give substance to this statement, statistics as it is now understood, however, dates we need to identify who is doing the learning and back to the 1950s, with subsequent development what they are learning about. in the second half of the 20th century. Over that time, the Bayesian approach has steadily gained Terms and Notation ground, and is now recognized as a legitimate al- ternative to the frequentist approach. The person doing the learning is an individual This chapter is organized into three sections. -

Hybrid of Naive Bayes and Gaussian Naive Bayes for Classification: a Map Reduce Approach
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8, Issue-6S3, April 2019 Hybrid of Naive Bayes and Gaussian Naive Bayes for Classification: A Map Reduce Approach Shikha Agarwal, Balmukumd Jha, Tisu Kumar, Manish Kumar, Prabhat Ranjan Abstract: Naive Bayes classifier is well known machine model could be used without accepting Bayesian probability learning algorithm which has shown virtues in many fields. In or using any Bayesian methods. Despite their naive design this work big data analysis platforms like Hadoop distributed and simple assumptions, Naive Bayes classifiers have computing and map reduce programming is used with Naive worked quite well in many complex situations. An analysis Bayes and Gaussian Naive Bayes for classification. Naive Bayes is manily popular for classification of discrete data sets while of the Bayesian classification problem showed that there are Gaussian is used to classify data that has continuous attributes. sound theoretical reasons behind the apparently implausible Experimental results show that Hybrid of Naive Bayes and efficacy of types of classifiers[5]. A comprehensive Gaussian Naive Bayes MapReduce model shows the better comparison with other classification algorithms in 2006 performance in terms of classification accuracy on adult data set showed that Bayes classification is outperformed by other which has many continuous attributes. approaches, such as boosted trees or random forests [6]. An Index Terms: Naive Bayes, Gaussian Naive Bayes, Map Reduce, Classification. advantage of Naive Bayes is that it only requires a small number of training data to estimate the parameters necessary I. INTRODUCTION for classification. The fundamental property of Naive Bayes is that it works on discrete value. -

Probability and Counting Rules
blu03683_ch04.qxd 09/12/2005 12:45 PM Page 171 C HAPTER 44 Probability and Counting Rules Objectives Outline After completing this chapter, you should be able to 4–1 Introduction 1 Determine sample spaces and find the probability of an event, using classical 4–2 Sample Spaces and Probability probability or empirical probability. 4–3 The Addition Rules for Probability 2 Find the probability of compound events, using the addition rules. 4–4 The Multiplication Rules and Conditional 3 Find the probability of compound events, Probability using the multiplication rules. 4–5 Counting Rules 4 Find the conditional probability of an event. 5 Find the total number of outcomes in a 4–6 Probability and Counting Rules sequence of events, using the fundamental counting rule. 4–7 Summary 6 Find the number of ways that r objects can be selected from n objects, using the permutation rule. 7 Find the number of ways that r objects can be selected from n objects without regard to order, using the combination rule. 8 Find the probability of an event, using the counting rules. 4–1 blu03683_ch04.qxd 09/12/2005 12:45 PM Page 172 172 Chapter 4 Probability and Counting Rules Statistics Would You Bet Your Life? Today Humans not only bet money when they gamble, but also bet their lives by engaging in unhealthy activities such as smoking, drinking, using drugs, and exceeding the speed limit when driving. Many people don’t care about the risks involved in these activities since they do not understand the concepts of probability.