Elliptical Fourier Analysis of Lateral Skull Profiles As a Tool to Aid Skeletal Identification Jodi Caple Bforensicsc, Bbiomedsc(Hons)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
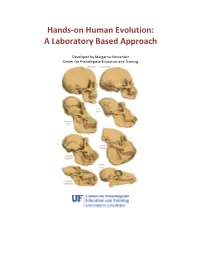
Hands-On Human Evolution: a Laboratory Based Approach
Hands-on Human Evolution: A Laboratory Based Approach Developed by Margarita Hernandez Center for Precollegiate Education and Training Author: Margarita Hernandez Curriculum Team: Julie Bokor, Sven Engling A huge thank you to….. Contents: 4. Author’s note 5. Introduction 6. Tips about the curriculum 8. Lesson Summaries 9. Lesson Sequencing Guide 10. Vocabulary 11. Next Generation Sunshine State Standards- Science 12. Background information 13. Lessons 122. Resources 123. Content Assessment 129. Content Area Expert Evaluation 131. Teacher Feedback Form 134. Student Feedback Form Lesson 1: Hominid Evolution Lab 19. Lesson 1 . Student Lab Pages . Student Lab Key . Human Evolution Phylogeny . Lab Station Numbers . Skeletal Pictures Lesson 2: Chromosomal Comparison Lab 48. Lesson 2 . Student Activity Pages . Student Lab Key Lesson 3: Naledi Jigsaw 77. Lesson 3 Author’s note Introduction Page The validity and importance of the theory of biological evolution runs strong throughout the topic of biology. Evolution serves as a foundation to many biological concepts by tying together the different tenants of biology, like ecology, anatomy, genetics, zoology, and taxonomy. It is for this reason that evolution plays a prominent role in the state and national standards and deserves thorough coverage in a classroom. A prime example of evolution can be seen in our own ancestral history, and this unit provides students with an excellent opportunity to consider the multiple lines of evidence that support hominid evolution. By allowing students the chance to uncover the supporting evidence for evolution themselves, they discover the ways the theory of evolution is supported by multiple sources. It is our hope that the opportunity to handle our ancestors’ bone casts and examine real molecular data, in an inquiry based environment, will pique the interest of students, ultimately leading them to conclude that the evidence they have gathered thoroughly supports the theory of evolution. -

Subject Index
431 Subject Index 3D CT AIDS 348 articular disc 16 – normal bone anatomy of the face alcohol 425 articular tubercle (eminence) 16 and skull 2 allergic sinusitis 270 artificial bone chips 194 alveolar process 186 astrocytes 371 alveolar recess of maxillary sinus 4 astrocytoma 371 A ameloblastoma asymmetric tongue 315 – desmoplastic type 47 atlantoaxial dislocation 365 abscess 119, 335, 339, 376 – desmoplastic, mandible 55, 56 atrophy 249 – and cellulitis in parotid region 337 – mandible 57 – with fatty replacement – epidural 390 – solid/multicystic type 47 of medial pterygoid muscle 313 – in cheek 141 – solid/multicystic – with fatty replacement of most – in masticator space – – mandible 48, 49, 50 of the lateral pterygoid muscle 313 with intracranial spread 310 – – maxilla 48 autopsy specimen 147 – in middle cranial fossa 310 – unicystic type 47 avascular necrosis 154 – in parotid gland 336 – unicystic, mandible 51, 53 – parapharyngeal 138, 139, 140 amorphous calcification 363 – parenchymal 390 aneurysmal bone cyst 62 B – subdural 390 angiofollicular hyperplasia 388 – submandibular 137 angle of mandible 321 bacterial – subperiosteal 390 ankyloses 164 – infection 335 – thyroid 377 ankylosing spondylitis 160, 363 – meningitis 303 absence of zygoma 251 ankylosis 164, 165, 263 – rhinosinusitis 267 absent anorexia 369 ballooning 418, 420, 421 – zygoma 250 antegonial notching 251 base of tongue 4, 322, 324 – zygomatic arch 263 anterior band of articular disc 16 basket retrieval 418 absolute alcohol 425 anterior belly of digastric muscle 4 benign -

Is the Skeleton Male Or Female? the Pelvis Tells the Story
Activity: Is the Skeleton Male or Female? The pelvis tells the story. Distinct features adapted for childbearing distinguish adult females from males. Other bones and the skull also have features that can indicate sex, though less reliably. In young children, these sex-related features are less obvious and more difficult to interpret. Subtle sex differences are detectable in younger skeletons, but they become more defined following puberty and sexual maturation. What are the differences? Compare the two illustrations below in Figure 1. Female Pelvic Bones Male Pelvic Bones Broader sciatic notch Narrower sciatic notch Raised auricular surface Flat auricular surface Figure 1. Female and male pelvic bones. (Source: Smithsonian Institution, illustrated by Diana Marques) Figure 2. Pelvic bone of the skeleton in the cellar. (Source: Smithsonian Institution) Skull (Cranium and Mandible) Male Skulls Generally larger than female Larger projections behind the Larger brow ridges, with sloping, ears (mastoid processes) less rounded forehead Square chin with a more vertical Greater definition of muscle (acute) angle of the jaw attachment areas on the back of the head Figure 3. Male skulls. (Source: Smithsonian Institution, illustrated by Diana Marques) Female Skulls Smoother bone surfaces where Smaller projections behind the muscles attach ears (mastoid processes) Less pronounced brow ridges, Chin more pointed, with a larger, with more vertical forehead obtuse angle of the jaw Sharp upper margins of the eye orbits Figure 4. Female skulls. (Source: Smithsonian Institution, illustrated by Diana Marques) What Do You Think? Comparing the skull from the cellar in Figure 5 (below) with the illustrated male and female skulls in Figures 3 and 4, write Male or Female to note the sex depicted by each feature. -

Pocket Atlas of Human Anatomy 4Th Edition
I Pocket Atlas of Human Anatomy 4th edition Feneis, Pocket Atlas of Human Anatomy © 2000 Thieme All rights reserved. Usage subject to terms and conditions of license. III Pocket Atlas of Human Anatomy Based on the International Nomenclature Heinz Feneis Wolfgang Dauber Professor Professor Formerly Institute of Anatomy Institute of Anatomy University of Tübingen University of Tübingen Tübingen, Germany Tübingen, Germany Fourth edition, fully revised 800 illustrations by Gerhard Spitzer Thieme Stuttgart · New York 2000 Feneis, Pocket Atlas of Human Anatomy © 2000 Thieme All rights reserved. Usage subject to terms and conditions of license. IV Library of Congress Cataloging-in-Publication Data is available from the publisher. 1st German edition 1967 2nd Japanese edition 1983 7th German edition 1993 2nd German edition 1970 1st Dutch edition 1984 2nd Dutch edition 1993 1st Italian edition 1970 2nd Swedish edition 1984 2nd Greek edition 1994 3rd German edition 1972 2nd English edition 1985 3rd English edition 1994 1st Polish edition 1973 2nd Polish edition 1986 3rd Spanish edition 1994 4th German edition 1974 1st French edition 1986 3rd Danish edition 1995 1st Spanish edition 1974 2nd Polish edition 1986 1st Russian edition 1996 1st Japanese edition 1974 6th German edition 1988 2nd Czech edition 1996 1st Portuguese edition 1976 2nd Italian edition 1989 3rd Swedish edition 1996 1st English edition 1976 2nd Spanish edition 1989 2nd Turkish edition 1997 1st Danish edition 1977 1st Turkish edition 1990 8th German edition 1998 1st Swedish edition 1979 1st Greek edition 1991 1st Indonesian edition 1998 1st Czech edition 1981 1st Chinese edition 1991 1st Basque edition 1998 5th German edition 1982 1st Icelandic edition 1992 3rd Dutch edtion 1999 2nd Danish edition 1983 3rd Polish edition 1992 4th Spanish edition 2000 This book is an authorized and revised translation of the 8th German edition published and copy- righted 1998 by Georg Thieme Verlag, Stuttgart, Germany. -
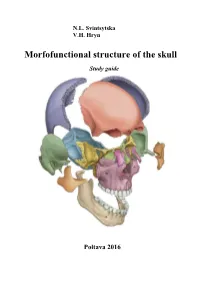
Morfofunctional Structure of the Skull
N.L. Svintsytska V.H. Hryn Morfofunctional structure of the skull Study guide Poltava 2016 Ministry of Public Health of Ukraine Public Institution «Central Methodological Office for Higher Medical Education of MPH of Ukraine» Higher State Educational Establishment of Ukraine «Ukranian Medical Stomatological Academy» N.L. Svintsytska, V.H. Hryn Morfofunctional structure of the skull Study guide Poltava 2016 2 LBC 28.706 UDC 611.714/716 S 24 «Recommended by the Ministry of Health of Ukraine as textbook for English- speaking students of higher educational institutions of the MPH of Ukraine» (minutes of the meeting of the Commission for the organization of training and methodical literature for the persons enrolled in higher medical (pharmaceutical) educational establishments of postgraduate education MPH of Ukraine, from 02.06.2016 №2). Letter of the MPH of Ukraine of 11.07.2016 № 08.01-30/17321 Composed by: N.L. Svintsytska, Associate Professor at the Department of Human Anatomy of Higher State Educational Establishment of Ukraine «Ukrainian Medical Stomatological Academy», PhD in Medicine, Associate Professor V.H. Hryn, Associate Professor at the Department of Human Anatomy of Higher State Educational Establishment of Ukraine «Ukrainian Medical Stomatological Academy», PhD in Medicine, Associate Professor This textbook is intended for undergraduate, postgraduate students and continuing education of health care professionals in a variety of clinical disciplines (medicine, pediatrics, dentistry) as it includes the basic concepts of human anatomy of the skull in adults and newborns. Rewiewed by: O.M. Slobodian, Head of the Department of Anatomy, Topographic Anatomy and Operative Surgery of Higher State Educational Establishment of Ukraine «Bukovinian State Medical University», Doctor of Medical Sciences, Professor M.V. -

CLOSURE of CRANIAL ARTICULATIONS in the SKULI1 of the AUSTRALIAN ABORIGINE by A
CLOSURE OF CRANIAL ARTICULATIONS IN THE SKULI1 OF THE AUSTRALIAN ABORIGINE By A. A. ABBIE, Department of Anatomy, University of Adelaide INTRODUCTION While it is well known that joint closure advances more or less progressively with age, there is still little certainty in matters of detail, mainly for lack of adequate series of documented skulls. In consequence, sundry beliefs have arisen which tend to confuse the issue. One view, now disposed of (see Martin, 1928), is that early suture closure indicates a lower or more primitive type of brain. A corollary, due to Broca (see Topinard, 1890), that the more the brain is exercised the more is suture closure postponed, is equally untenable. A very widespread belief is based on Gratiolet's statement (see Topinard, 1890; Frederic, 1906; Martin, 1928; Fenner, 1939; and others) that in 'lower' skulls the sutures are simple and commence to fuse from in front, while in 'higher' skulls the sutures are more complicated and tend to fuse from behind. This view was disproved by Ribbe (quoted from Frederic, 1906), who substituted the generalization that in dolicocephals synostosis begins in the coronal suture, and in brachycephals in the lambdoid suture. In addition to its purely anthropological interest the subject raises important biological considerations of brain-skull relationship, different foetalization in different ethnological groups (see Bolk, 1926; Weidenreich, 1941; Abbie, 1947), and so on. A survey of the literature reveals very little in the way of data on the age incidence of suture closure. The only substantial contribution accessible here comes from Todd & Lyon (1924) for Europeans, but their work is marred by arbitrary rejection of awkward material. -

A New Classification of Zygomatic Fracture Featuring Zygomaticofrontal Suture: Injury Mechanism and a Guide to Treatment
IBIMA Publishing Plastic Surgery: An International Journal http://www.ibimapublishing.com/journals/PSIJ/psij.html Vol. 2013 (2013), Article ID 383486, 6 pages DOI: 10.5171/2013.383486 Research Article A New Classification of Zygomatic Fracture Featuring Zygomaticofrontal Suture: Injury Mechanism and a Guide to Treatment Hisao Ogata, Yoshiaki Sakamoto and Kazuo Kishi Department of Plastic and Reconstructive Surgery, Keio University School of Medicine, Shinjuku-ward, Tokyo, Japan Received 21 November 2012; Accepted 10 December 2012; Published 26 January 2013 Academic Editor: Zubing Li ______________________________________________________________________________________________________________ Abstract The researchers establish a new classification system for zygomatic fractures based on computed tomography and mechanism of injury, which could be used to inform treatment options. Patients treated for isolated zygomatic fracture at the Keio University Hospital between 2004 and 2011 were recruited for this study. The cases were classified into 4 types based on the fracture pattern of the zygomaticofrontal suture and inferior orbital rim. In total, 113 patients aged 16 to 82 years (mean age (SD) = 39.8 (17.0) years), including 74 men and 39 women, were analyzed. Overall, 54 patients had shear fractures and 59 patients had greenstick type fractures. In both shear and greenstick fractures, the ratio of medial type fractures was significantly higher than that of lateral type fractures (p < 0.001). Furthermore, the number of shear type fractures in those <20 years old was lower than that in other age groups (p < 0.05). In conclusion, this classification is an epoch-making classification based on the mechanism of facial injury, and may be used to inform treatment options to achieve optimal biomechanical stability. -

A Description of Some Tasmanian Skulls
AUSTRALIAN MUSEUM SCIENTIFIC PUBLICATIONS Ramsay Smith, W., 1916. A description of some Tasmanian skulls. Records of the Australian Museum 11(2): 15–29, plates viii–xiii. [1 May 1916]. doi:10.3853/j.0067-1975.11.1916.907 ISSN 0067-1975 Published by the Australian Museum, Sydney naturenature cultureculture discover discover AustralianAustralian Museum Museum science science is is freely freely accessible accessible online online at at www.australianmuseum.net.au/publications/www.australianmuseum.net.au/publications/ 66 CollegeCollege Street,Street, SydneySydney NSWNSW 2010,2010, AustraliaAustralia A "!:lESGRIPTION OF SOME TASMANIAN SKULLS. By W. RAMSAY SMITH, M.D., D.Sc., F.R.S. (Edin.). (Plates viii-xiii.) I.-INTRODUCTION. III July, 1910, the Trustees of the Aust;>alian Museum, Sydney, were good enough to send me th,' Tasmanian skulls in their collection for the purpose;, 'If meaSl.rement and description. 1'he specimens consisted of two ~omp~ete skulls and the upper portion of a third. About the sa,me time I was fortunate III obtainillg a cast of a skull from the 1'asmaniall Museum, and also, from another source the skull and most of the bones of an aged Tasmanian woman that had not previously been described. 'I'hese specimens form the subject of the present contribution. To Mr. R. Etheridge, Curator of the Australian Museum, I am much indebted for assistance in sending the Museum skulls and giving their origin and history. These description~were writtell nearly five years ago; but the leisure for putting the necessary finishing touches for publication has been long delayed. 1'he sagittal contours (PI. -

A Description of the Geological Context, Discrete Traits, and Linear Morphometrics of the Middle Pleistocene Hominin from Dali, Shaanxi Province, China
AMERICAN JOURNAL OF PHYSICAL ANTHROPOLOGY 150:141–157 (2013) A Description of the Geological Context, Discrete Traits, and Linear Morphometrics of the Middle Pleistocene Hominin from Dali, Shaanxi Province, China Xinzhi Wu1 and Sheela Athreya2* 1Laboratory for Human Evolution, Institute of Vertebrate Paleontology and Paleoanthropology, Chinese Academy of Sciences, Beijing 100044, China 2Department of Anthropology, Texas A&M University, College Station, TX 77843 KEY WORDS Homo heidelbergensis; Homo erectus; Asia ABSTRACT In 1978, a nearly complete hominin Afro/European Middle Pleistocene Homo and align it fossil cranium was recovered from loess deposits at the with Asian H. erectus.Atthesametime,itdisplaysa site of Dali in Shaanxi Province, northwestern China. more derived morphology of the supraorbital torus and It was subsequently briefly described in both English supratoral sulcus and a thinner tympanic plate than and Chinese publications. Here we present a compre- H. erectus, a relatively long upper (lambda-inion) occi- hensive univariate and nonmetric description of the pital plane with a clear separation of inion and opis- specimen and provide comparisons with key Middle thocranion, and an absolute and relative increase in Pleistocene Homo erectus and non-erectus hominins brain size, all of which align it with African and Euro- from Eurasia and Africa. In both respects we find pean Middle Pleistocene Homo. Finally, traits such as affinities with Chinese H. erectus as well as African the form of the frontal keel and the relatively short, and European Middle Pleistocene hominins typically broad midface align Dali specifically with other referred to as Homo heidelbergensis.Specifically,the Chinese specimens from the Middle Pleistocene Dali specimen possesses a low cranial height, relatively and Late Pleistocene, including H. -

Humans Preserve Non-Human Primate Pattern of Climatic Adaptation
Quaternary Science Reviews 192 (2018) 149e166 Contents lists available at ScienceDirect Quaternary Science Reviews journal homepage: www.elsevier.com/locate/quascirev Humans preserve non-human primate pattern of climatic adaptation * Laura T. Buck a, b, , Isabelle De Groote c, Yuzuru Hamada d, Jay T. Stock a, e a PAVE Research Group, Department of Archaeology, University of Cambridge, Pembroke Street, Cambridge, CB2 3QG, UK b Human Origins Research Group, Department of Earth Sciences, Natural History Museum, Cromwell Road, London, SW7 5BD, UK c School of Natural Science and Psychology, Liverpool John Moores University, James Parsons Building, Byrom Street, Liverpool, L3 3AF, UK d Primate Research Institute, University of Kyoto, Inuyama, Aichi, 484-8506, Japan e Department of Anthropology, Western University, London, Ontario, N6A 3K7, Canada article info abstract Article history: There is evidence for early Pleistocene Homo in northern Europe, a novel hominin habitat. Adaptations Received 9 October 2017 enabling this colonisation are intriguing given suggestions that Homo exhibits physiological and Received in revised form behavioural malleability associated with a ‘colonising niche’. Differences in body size/shape between 2 May 2018 conspecifics from different climates are well-known in mammals, could relatively flexible size/shape Accepted 22 May 2018 have been important to Homo adapting to cold habitats? If so, at what point did this evolutionary stragegy arise? To address these questions a base-line for adaptation to climate must be established by comparison with outgroups. We compare skeletons of Japanese macaques from four latitudes and find Keywords: Adaptation inter-group differences in postcranial and cranial size and shape. Very small body mass and cranial size in Variation the Southern-most (island) population are most likely affected by insularity as well as ecogeographic Colonisation scaling. -

Download Poster
Sutural Variability in the Hominoid Anterior Cranial Fossa Robert McCarthy, Monica Kunkel, Department of Biological Sciences, Benedictine University Email contact information: [email protected]; [email protected] SAMPLE ABSTRACT Table 2. Results split by age. Table 4. Specimens used in scaling analyses. Group Age A-M434; M555 This study Combined In anthropoids, the orbital plates of frontal bone meet at a “retro-ethmoid” Species Symbol FMNH CMNH USNM % Contact S-E S-E S-E % % % frontal suture in the midline anterior cranial fossa (ACF), separating the contact/n contact/n contact/n presphenoid and mesethmoid bones. Previous research indicates that this Hylobatid 0 0 23 13.0 Hylobatid Adult 0/6 0 4/13 30.8 4/19 21.1 configuration appears variably in chimpanzees and gorillas and infrequently in modern humans, with speculation that its incidence is related to differential Juvenile 0/2 0 3/10 30.0 3/12 25.0 Orangutan 6 0 37 100.0 growth of the brain and orbits, size of the brow ridges or face, or upper facial Combined 0/9 0 7/23 30.4 7/32 21.9 prognathism. We collected qualitative and quantitative data from 164 Gorilla 3 0 4 28.6 previously-opened cranial specimens from 15 hominoid species in addition to A Orangutan Adult 12/12 100.0 21/21 100.0 21/21 100.0 Chimpanzee 1 0 7 57.1 qualitative observations on non-hominoid and hominin specimens in order to Juvenile 13/13 100.0 13/13 100.0 13/13 100.0 (1) document sutural variability in the primate ACF, (2) rethink the evolutionary trajectory of frontal bone contribution to the midline ACF, and Combined 26/26 100.0 34/34 100.0 34/34 34/34 Human 0 83 0 91.8 (3) create a database of ACF observations and measurements which can be Gorilla Adult 3/7 42.9 1/2 50.0 3/7 42.9 used to test hypotheses about structural relationships in the hominoid ACF. -

Cranio-Orbito Zygomatic Normative Measurements in Adult Sudanese: CT Based Study
Global Advanced Research Journal of Medicine and Medical Sciences (ISSN: 2315-5159) Vol. 4(11) pp. 477-484, November, 2015 Available online http://garj.org/garjmms Copyright © 2015 Global Advanced Research Journals Full Length Research Paper Cranio-Orbito Zygomatic Normative Measurements In Adult Sudanese: CT Based Study Maisa Mohammed Elzaki 1, Caroline Edward Ayad 2*, Hussein Ahmed Hassan 2, and Elsafi Ahmed Abdalla 2 1Alzaiem Alazhari University, Faculty of Radiology Science and Medical Imaging, P.O. Box 1432 Khartoum North, Sudan 2Sudan University of Science and Technology, College of Medical Radiological Science, P.O. Box 1908, Khartoum, Sudan Khartoum-Sudan Accepted 19 November, 2015 The measurements of craniofacial parameters have clinical and anthropologic significance. Local data on Cranio-orbito zygomatic normative measurements reveal the pattern of changes in craniofacial features resulting from gender and age. In the present study, we provide normative data on anthropometric variation within the normal adult Sudanese measurements by using computerized tomography (CT) images and to determine the effects of age and gender on anthropometry. A systematic method was obtained to align head (CT) images for both axial and coronal assessment, and to measure the variable parameters obtained from 110 Sudanese subjects in both genders and in different age groups ( ≤20 ≥61years). To quantify the orbits: 4 measurements were collected along both orbits including orbital breadth, height, bi orbital roof and anterior inter orbital distance; 2 for zygomatic bones including bi zygomatic breadth and zygomatic arches length, 2 for cranium counting length and width were also measured. All measurements were taken in (mm). As a result; measurements of the orbita, zygomatic arches and cranium were found to be higher at the age of 51-61 years and showed similar measurements attainment at this age with no significant difference detected at various age intervals.