Oct Lrae2004
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
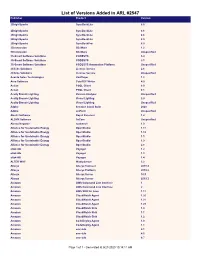
List of Versions Added in ARL #2547 Publisher Product Version
List of Versions Added in ARL #2547 Publisher Product Version 2BrightSparks SyncBackLite 8.5 2BrightSparks SyncBackLite 8.6 2BrightSparks SyncBackLite 8.8 2BrightSparks SyncBackLite 8.9 2BrightSparks SyncBackPro 5.9 3Dconnexion 3DxWare 1.2 3Dconnexion 3DxWare Unspecified 3S-Smart Software Solutions CODESYS 3.4 3S-Smart Software Solutions CODESYS 3.5 3S-Smart Software Solutions CODESYS Automation Platform Unspecified 4Clicks Solutions License Service 2.6 4Clicks Solutions License Service Unspecified Acarda Sales Technologies VoxPlayer 1.2 Acro Software CutePDF Writer 4.0 Actian PSQL Client 8.0 Actian PSQL Client 8.1 Acuity Brands Lighting Version Analyzer Unspecified Acuity Brands Lighting Visual Lighting 2.0 Acuity Brands Lighting Visual Lighting Unspecified Adobe Creative Cloud Suite 2020 Adobe JetForm Unspecified Alastri Software Rapid Reserver 1.4 ALDYN Software SvCom Unspecified Alexey Kopytov sysbench 1.0 Alliance for Sustainable Energy OpenStudio 1.11 Alliance for Sustainable Energy OpenStudio 1.12 Alliance for Sustainable Energy OpenStudio 1.5 Alliance for Sustainable Energy OpenStudio 1.9 Alliance for Sustainable Energy OpenStudio 2.8 alta4 AG Voyager 1.2 alta4 AG Voyager 1.3 alta4 AG Voyager 1.4 ALTER WAY WampServer 3.2 Alteryx Alteryx Connect 2019.4 Alteryx Alteryx Platform 2019.2 Alteryx Alteryx Server 10.5 Alteryx Alteryx Server 2019.3 Amazon AWS Command Line Interface 1 Amazon AWS Command Line Interface 2 Amazon AWS SDK for Java 1.11 Amazon CloudWatch Agent 1.20 Amazon CloudWatch Agent 1.21 Amazon CloudWatch Agent 1.23 Amazon -
Windows Authentication
Windows Authentication August 3, 2021 Verity Confidential Copyright 2011-2021 by Qualys, Inc. All Rights Reserved. Qualys and the Qualys logo are registered trademarks of Qualys, Inc. All other trademarks are the property of their respective owners. Qualys, Inc. 919 E Hillsdale Blvd 4th Floor Foster City, CA 94404 1 (650) 801 6100 Table of Contents Get Started .........................................................................................................4 Windows Domain Account Setup.................................................................6 Create an Administrator Account ......................................................................................... 6 Group Policy Settings .............................................................................................................. 6 Verify Functionality of the New Account (recommended) ................................................. 7 WMI Service Configuration ............................................................................ 8 How to increase WMI authentication level .......................................................................... 8 What happens when high level authentication is not provided? ...................................... 8 Manage Authentication Records...................................................................9 Create one or more Windows Records .................................................................................. 9 Windows Authentication Settings ...................................................................................... -

Profile Management 7.15, Such Configuration Is Applied to Not Only the Current Folder but Also the Subfolders
Profile Management 7.15 Aug 14, 2017 Profile Management is intended as a profile solution for XenApp servers, virtual desktops created with XenDesktop, and physical desktops. You install Profile Management on each computer whose profiles you want to manage. Active Directory Group Policy Objects allow you to control how Citrix user profiles behave. Although many settings can be adjusted, in general you only need to configure a subset, as described in these topics. The best way of choosing the right set of policy selections to suit your deployment is to answer the questions in the topic called Decide on a configuration. Usage rights for this feature are described in the end-user license agreement (EULA). For information on the terminology used in these topics, see Profile Management glossary. https://docs.citrix.com © 1999-2017 Citrix Systems, Inc. All rights reserved. p.1 What's new Aug 14, 2017 This version includes the following key enhancement and addresses several customer reported issues to improve the user experience. Enhancement for using wildcards. You can use the vertical bar ‘|’ for applying a policy to only the current folder without propagating it to the subfolders. For details, see Using wildcards. https://docs.citrix.com © 1999-2017 Citrix Systems, Inc. All rights reserved. p.2 Fixed issues Aug 14, 2017 Compared to: Citrix Profile Management 5.8 Profile Management 7.15 contains the following fixes compared to Profile Management 5.8: When you attempt to open files in a profile with Profile Streaming enabled, the file might appear empty after you log on. [#LC6996] Servers might experience a fatal exception, displaying a blue screen, on upmjit.sys with bugcheck code 0x135. -

CLI User's Guide
AccuRev® CLI User’s Guide Version 7.2 Revised 11-April-2018 Copyright and Trademarks Copyright © Micro Focus 2018. All rights reserved. This product incorporates technology that may be covered by one or more of the following patents: U.S. Patent Numbers: 7,437,722; 7,614,038; 8,341,590; 8,473,893; 8,548,967. AccuRev, AgileCycle, and TimeSafe are registered trademarks of Micro Focus. AccuBridge, AccuReplica, AccuSync, AccuWork, Kando, and StreamBrowser are trademarks of Micro Focus. All other trade names, trademarks, and service marks used in this document are the property of their respective owners. Table of Contents Preface........................................................................................................................vii Using This Book ................................................................................................................................ vii Typographical Conventions ............................................................................................................... vii Contacting Technical Support............................................................................................................ vii 1. Overview of the AccuRev® Command-Line Interface ........................................................................................ 1 Using AccuRev with a Secure AccuRev Server............................................................................ 1 Working with Files in a Workspace ..............................................................................................3 -

OS/2 Server Transitionsition
Front cover OS/2 Server Transitionsition Extract data from OS/2 Servers Migrate OS/2 domains to Windows 2000 Migrate OS/2 domains to Linux with Samba 3.0 Leif Braeuer Bart Jacob Oliver Mark Wynand Pretorius Marc Schneider Richard Spurlock Andrei Vlad ibm.com/redbooks International Technical Support Organization OS/2 Server Transition October 2003 SG24-6631-00 Note: Before using this information and the product it supports, read the information in “Notices” on page xvii. First Edition (October 2003) © Copyright International Business Machines Corporation 2003. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Figures . xv Notices . xvii Trademarks . xviii Preface . xix The team that wrote this redbook. xxi Become a published author . xxiv Comments welcome. xxiv Part 1. Introduction and preparation . 1 Chapter 1. OS/2 Server environment . 3 1.1 IBM OS/2 Warp Server for e-business base installation . 4 1.2 Sample domain . 5 1.3 Configured TCP/IP-based services . 6 1.4 Product stack on OS/2 . 7 1.4.1 IBM Universal Database . 7 1.4.2 IBM e-Network Communications Server . 7 1.4.3 Lotus Domino Server . 8 1.4.4 IBM HTTP Server . 8 1.4.5 IBM Tivoli Storage Manager Client . 9 1.4.6 IBM LAN Distributed Platform . 9 1.4.7 IBM WebSphere MQ . 10 1.4.8 IBM Netfinity® Manager™ . 11 1.5 Recommended steps prior to migration . 11 1.5.1 General architectural thoughts . 11 1.5.2 Security . -

License Administration Guide Flexnet Publisher 2014 R1 (11.12.1) Legal Information
License Administration Guide FlexNet Publisher 2014 R1 (11.12.1) Legal Information Book Name: License Administration Guide Part Number: FNP-11121-LAG01 Product Release Date: March 2014 Copyright Notice Copyright © 2014 Flexera Software LLC. All Rights Reserved. This product contains proprietary and confidential technology, information and creative works owned by Flexera Software LLC and its licensors, if any. Any use, copying, publication, distribution, display, modification, or transmission of such technology in whole or in part in any form or by any means without the prior express written permission of Flexera Software LLC is strictly prohibited. Except where expressly provided by Flexera Software LLC in writing, possession of this technology shall not be construed to confer any license or rights under any Flexera Software LLC intellectual property rights, whether by estoppel, implication, or otherwise. All copies of the technology and related information, if allowed by Flexera Software LLC, must display this notice of copyright and ownership in full. FlexNet Publisher incorporates software developed by others and redistributed according to license agreements. Copyright notices and licenses for these external libraries are provided in a supplementary document that accompanies this one. Intellectual Property For a list of trademarks and patents that are owned by Flexera Software, see http://www.flexerasoftware.com/intellectual-property. All other brand and product names mentioned in Flexera Software products, product documentation, and -

Virtualbox R
Oracle R VM VirtualBox R Programming Guide and Reference Version 6.1.20 c 2004-2021 Oracle Corporation http://www.virtualbox.org Contents 1 Introduction 24 1.1 Modularity: the building blocks of VirtualBox................... 24 1.2 Two guises of the same “Main API”: the web service or COM/XPCOM...... 25 1.3 About web services in general............................ 26 1.4 Running the web service............................... 27 1.4.1 Command line options of vboxwebsrv................... 27 1.4.2 Authenticating at web service logon.................... 28 2 Environment-specific notes 30 2.1 Using the object-oriented web service (OOWS)................... 30 2.1.1 The object-oriented web service for JAX-WS................ 30 2.1.2 The object-oriented web service for Python................ 32 2.1.3 The object-oriented web service for PHP................. 33 2.2 Using the raw web service with any language................... 33 2.2.1 Raw web service example for Java with Axis............... 34 2.2.2 Raw web service example for Perl..................... 35 2.2.3 Programming considerations for the raw web service.......... 35 2.3 Using COM/XPCOM directly............................. 39 2.3.1 Python COM API.............................. 39 2.3.2 Common Python bindings layer...................... 40 2.3.3 C++ COM API............................... 41 2.3.4 Event queue processing........................... 42 2.3.5 Visual Basic and Visual Basic Script (VBS) on Windows hosts...... 42 2.3.6 C binding to VirtualBox API........................ 43 3 Basic VirtualBox concepts; some examples 50 3.1 Obtaining basic machine information. Reading attributes............. 50 3.2 Changing machine settings: Sessions........................ 50 3.3 Launching virtual machines............................ -
Proceedings of the FREENIX Track: 2003 USENIX Annual Technical Conference
USENIX Association Proceedings of the FREENIX Track: 2003 USENIX Annual Technical Conference San Antonio, Texas, USA June 9-14, 2003 THE ADVANCED COMPUTING SYSTEMS ASSOCIATION © 2003 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649 FAX: 1 510 548 5738 Email: [email protected] WWW: http://www.usenix.org Rights to individual papers remain with the author or the author's employer. Permission is granted for noncommercial reproduction of the work for educational or research purposes. This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein. POSIX Access Control Lists on Linux Andreas Grunbacher¨ SuSE Labs, SuSE Linux AG Nuremberg, Germany [email protected] Abstract This paper gives an overview of the most successful ACL scheme for UNIX-like systems that has resulted This paper discusses file system Access Control Lists from the POSIX 1003.1e/1003.2c working group. as implemented in several UNIX-like operating systems. After briefly describing the concepts, some examples After recapitulating the concepts of these Access Con- of how these are used are given for better understanding. trol Lists that never formally became a POSIX standard, Following that, the paper discusses Extended Attributes, we focus on the different aspects of implementation and the abstraction layer upon which ACLs are based on use on Linux. Linux. The rest of the paper deals with implementation, performance, interoperability, application support, and 1 Introduction -

HPSS Error Manual
HPSS Error Manual High Performance Storage System, version 9.2.0.0.0, 10 May 2021 HPSS Error Manual High Performance Storage System, version 9.2.0.0.0, 10 May 2021 Table of Contents .............................................................................................................................................................. vii 1. Problem diagnosis and resolution ..................................................................................................... 1 1.1. HPSS infrastructure problems ................................................................................................ 1 1.1.1. RPC problems .............................................................................................................. 1 1.1.1.1. One HPSS server cannot communicate with another ....................................... 1 1.1.1.2. A server cannot obtain its credentials .............................................................. 2 1.1.1.3. A server cannot register its RPC info .............................................................. 2 1.1.1.4. The connection table may have overflowed ..................................................... 2 1.1.2. DB2 problems .............................................................................................................. 2 1.1.2.1. HPSS servers cannot communicate with DB2 ................................................. 2 1.1.2.2. One or more HPSS servers are receiving metadata or DB2 errors ................... 3 1.1.2.3. Cannot start DB2 instance ............................................................................... -

Data ONTAP® 8.1 File Access and Protocols Management Guide for 7-Mode
Data ONTAP® 8.1 File Access and Protocols Management Guide For 7-Mode NetApp, Inc. 495 East Java Drive Sunnyvale, CA 94089 USA Telephone: +1 (408) 822-6000 Fax: +1 (408) 822-4501 Support telephone: +1 (888) 463-8277 Web: www.netapp.com Feedback: [email protected] Part number: 210-05621_A0 Updated for Data ONTAP 8.1.1 on 14 June 2012 Table of Contents | 3 Contents Introduction to file access management ................................................... 13 File protocols that Data ONTAP supports ................................................................ 13 How Data ONTAP controls access to files ............................................................... 13 Authentication-based restrictions .................................................................. 13 File-based restrictions ................................................................................... 13 File access using NFS ................................................................................. 15 Configuring NFS licenses ......................................................................................... 15 Exporting or unexporting file system paths .............................................................. 15 Editing the /etc/exports file ........................................................................... 16 Using the exportfs command ......................................................................... 17 Enabling and disabling fencing of one or more NFS clients from one or more file system paths ................................................................................................. -

Tom S. Rodman Perl Developer Deployment Automation Engineer
January 30, 2017 firm: open to jobs w/in 100mi of 53207 latest resume: http://trodman.com www -dot- trodman -dot- com Tom S. Rodman c 414-678-9284 [email protected] Milwaukee, WI 53207 USA Citizen Support java builds/Software Development Life Cycle and Software Configuration management under Subversion (svn), Linux RHEL, and Atlassian: Bamboo, Confluence (and Jira: at jr level). Provide best practice advice on SCM and UNIX server administration. Write and maintain support scripts in bash shell, perl, ant and python. • strong in shell scripting, perl scripting • awk, sed, make, m4, cron, tcl/tclsh, expect, • strong UNIX and Windows OS system rsync, find, egrep, mercurial (hg), rcs, SCCS, administration skills xargs, diff, dd, vi, vim, HTML, Centos/RHEL, LAT X, Cygwin • skilled w/several hundred UNIX and GNU E • tools Atlassian tools: Confluence, Jira, Bamboo • Intel server hardware troubleshooting and • support and administration for Subversion builds; DAT, LTO tapedrives (svn), TFS, Telelogic Change, and Telelogic • some experience with Electric Commander, C, Synergy (SCM) Informix, PL/SQL queries, SAN, LDAP, • experience configuring/deploying: DNS RAID, CGI, autom4te, CIFS, Samba, curses, (bind/named), NFS, NIS, ssh/sshd, apache, CSS, Tivolii backup, wiki markup, YAML, jira, SMTP, sendmail, confluence, bamboo, XML, Virtualbox, VMware, Pascal and NTP, procmail, spamassassin, exim Fortran • TCP/IP networking administration and • thorough skills assessment on last page, debugging more at: http://trodman.com perl developer Jan 2015, Jan 2017 Ringlead Inc. Brookfield, WI Consulting with Ringlead.com, as a perl software developer supporting 3 legacy Salesforce related web applications; bug fixing; enhancements; implementing perl best practices; used git; developed ’git, bash, and make’ based deployment process; did all upgrades and releases; level 3 application support, was backup and consultant for RHEL 5 and 7 infrastructure/Linux system administration for several cloud VMs - both production and developement. -

PS Package Management Packages 24-APR-2016 Page 1 Acmesharp-Posh-All 0.8.1.0 Chocolatey Powershell Module to Talk to Let's Encrypt CA and Other ACME Serve
Name Version Source Summary ---- ------- ------ ------- 0ad 0.0.20 chocolatey Open-source, cross-platform, real-time strategy (RTS) game of anci... 0install 2.10.0 chocolatey Decentralised cross-distribution software installation system 0install.install 2.10.0 chocolatey Decentralised cross-distribution software installation system 0install.install 2.10.0 chocolatey Decentralised cross-distribution software installation system 0install.portable 2.10.0 chocolatey Decentralised cross-distribution software installation system 1password 4.6.0.603 chocolatey 1Password - Have you ever forgotten a password? 1password-desktoplauncher 1.0.0.20150826 chocolatey Launch 1Password from the desktop (CTRL + Backslash). 2gis 3.14.12.0 chocolatey 2GIS - Offline maps and business listings 360ts 5.2.0.1074 chocolatey A feature-packed software solution that provides users with a powe... 3PAR-Powershell 0.4.0 PSGallery Powershell module for working with HP 3PAR StoreServ array 4t-tray-minimizer 5.52 chocolatey 4t Tray Minimizer is a lightweight but powerful window manager, wh... 7KAA 2.14.15 chocolatey Seven Kingdoms is a classic strategy game. War, Economy, Diplomacy... 7-taskbar-tweaker 5.1 chocolatey 7+ Taskbar Tweaker allows you to configure various aspects of the ... 7zip 15.14 chocolatey 7-Zip is a file archiver with a high compression ratio. 7zip.commandline 15.14 chocolatey 7-Zip is a file archiver with a high compression ratio. 7zip.install 15.14 chocolatey 7-Zip is a file archiver with a high compression ratio. 7Zip4Powershell 1.3.0 PSGallery Powershell module for creating and extracting 7-Zip archives aacgain 1.9.0.2 chocolatey aacgain normalizes the volume of digital music files using the..