Multi-Dimensional Analyses Identify Genes of High Priority for Pancreatic Cancer Research
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genetic Analysis of Retinopathy in Type 1 Diabetes
Genetic Analysis of Retinopathy in Type 1 Diabetes by Sayed Mohsen Hosseini A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Institute of Medical Science University of Toronto © Copyright by S. Mohsen Hosseini 2014 Genetic Analysis of Retinopathy in Type 1 Diabetes Sayed Mohsen Hosseini Doctor of Philosophy Institute of Medical Science University of Toronto 2014 Abstract Diabetic retinopathy (DR) is a leading cause of blindness worldwide. Several lines of evidence suggest a genetic contribution to the risk of DR; however, no genetic variant has shown convincing association with DR in genome-wide association studies (GWAS). To identify common polymorphisms associated with DR, meta-GWAS were performed in three type 1 diabetes cohorts of White subjects: Diabetes Complications and Control Trial (DCCT, n=1304), Wisconsin Epidemiologic Study of Diabetic Retinopathy (WESDR, n=603) and Renin-Angiotensin System Study (RASS, n=239). Severe (SDR) and mild (MDR) retinopathy outcomes were defined based on repeated fundus photographs in each study graded for retinopathy severity on the Early Treatment Diabetic Retinopathy Study (ETDRS) scale. Multivariable models accounted for glycemia (measured by A1C), diabetes duration and other relevant covariates in the association analyses of additive genotypes with SDR and MDR. Fixed-effects meta- analysis was used to combine the results of GWAS performed separately in WESDR, ii RASS and subgroups of DCCT, defined by cohort and treatment group. Top association signals were prioritized for replication, based on previous supporting knowledge from the literature, followed by replication in three independent white T1D studies: Genesis-GeneDiab (n=502), Steno (n=936) and FinnDiane (n=2194). -

Architecture of a Lymphomyeloid Developmental Switch Controlled by PU.1, Notch and Gata3 Marissa Morales Del Real and Ellen V
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Caltech Authors DEVELOPMENT AND STEM CELLS RESEARCH ARTICLE 1207 Development 140, 1207-1219 (2013) doi:10.1242/dev.088559 © 2013. Published by The Company of Biologists Ltd Architecture of a lymphomyeloid developmental switch controlled by PU.1, Notch and Gata3 Marissa Morales Del Real and Ellen V. Rothenberg* SUMMARY Hematopoiesis is a classic system with which to study developmental potentials and to investigate gene regulatory networks that control choices among alternate lineages. T-cell progenitors seeding the thymus retain several lineage potentials. The transcription factor PU.1 is involved in the decision to become a T cell or a myeloid cell, and the developmental outcome of expressing PU.1 is dependent on exposure to Notch signaling. PU.1-expressing T-cell progenitors without Notch signaling often adopt a myeloid program, whereas those exposed to Notch signals remain in a T-lineage pathway. Here, we show that Notch signaling does not alter PU.1 transcriptional activity by degradation/alteration of PU.1 protein. Instead, Notch signaling protects against the downregulation of T-cell factors so that a T-cell transcriptional network is maintained. Using an early T-cell line, we describe two branches of this network. The first involves inhibition of E-proteins by PU.1 and the resulting inhibition of Notch signaling target genes. Effects of E- protein inhibition can be reversed by exposure to Notch signaling. The second network is dependent on the ability of PU.1 to inhibit important T-cell transcription factor genes such as Myb, Tcf7 and Gata3 in the absence of Notch signaling. -

Supplementary Figure 1. Qrt-PCR Analyses for Measuring the Knockdown Efficiency of Transcription Factors. A549 and U937 Cells Kn
Supplementary Figure 1. qRT-PCR analyses for measuring the knockdown efficiency of transcription factors. A549 and U937 cells knocking down or overexpressing different transcription factors including NF-κB subunits p65 and p50 (A), HIF1 (B), TCF4 (C), AP-1 subunits c-Jun and c-FOS (D), or FOXP3 (E) were subjected to RNA isolation, followed by qRT-PCR analyses to examine the expression of these transcription factors. **P<0.01 and ***P<0.001. 1 Supplementary Figure 2. Effects of FOXP3 downregulation and overexpression on the expression of NLRP1, IL1B and IL18. A549 and U937 cells were transfected with si-FOXP3 or pCDNA3-2×Flag-FOXP3. After 24 h, cells were subjected to RNA isolation, followed by qRT-PCR analyses to examine the expression of NLRP1 (A), IL1B (B) and IL18 (C). ***P<0.001. 2 Supplementary Figure 3. Effects of CtBP2 downregulation and overexpression on the expression of miR-199a-3p, NLRP1, IL1B and IL18. A549 and U937 cells were transfected with si-CtBP2 or pCDNA3-2×Flag-CtBP2. After 24 h, cells were subjected to RNA isolation, followed by qRT-PCR analyses to examine the expression of miR-199a-3p (A), NLRP1 (B), IL1B (C) and IL18 (D). ***P<0.001. 3 Supplementary Figure 4. CHFTC specifically bond to the promoter of miR-199a-3p. (A and B) Effects of CtBP2 knockdown and overexpression on HDAC1 and FOXP3 protein levels. A549 cells were transfected with two CtBP2-specific shRNAs and pCDNA3-2×Flag-CtBP2 to obtain two CtBP2-knockdown cell lines (KD-1 and KD-2) (A) and two CtBP2-overexpression cells lines (OE-1 and OE-2) (B), respectively. -

Aquaporin Channels in the Heart—Physiology and Pathophysiology
International Journal of Molecular Sciences Review Aquaporin Channels in the Heart—Physiology and Pathophysiology Arie O. Verkerk 1,2,* , Elisabeth M. Lodder 2 and Ronald Wilders 1 1 Department of Medical Biology, Amsterdam University Medical Centers, University of Amsterdam, 1105 AZ Amsterdam, The Netherlands; [email protected] 2 Department of Experimental Cardiology, Amsterdam University Medical Centers, University of Amsterdam, 1105 AZ Amsterdam, The Netherlands; [email protected] * Correspondence: [email protected]; Tel.: +31-20-5664670 Received: 29 March 2019; Accepted: 23 April 2019; Published: 25 April 2019 Abstract: Mammalian aquaporins (AQPs) are transmembrane channels expressed in a large variety of cells and tissues throughout the body. They are known as water channels, but they also facilitate the transport of small solutes, gasses, and monovalent cations. To date, 13 different AQPs, encoded by the genes AQP0–AQP12, have been identified in mammals, which regulate various important biological functions in kidney, brain, lung, digestive system, eye, and skin. Consequently, dysfunction of AQPs is involved in a wide variety of disorders. AQPs are also present in the heart, even with a specific distribution pattern in cardiomyocytes, but whether their presence is essential for proper (electro)physiological cardiac function has not intensively been studied. This review summarizes recent findings and highlights the involvement of AQPs in normal and pathological cardiac function. We conclude that AQPs are at least implicated in proper cardiac water homeostasis and energy balance as well as heart failure and arsenic cardiotoxicity. However, this review also demonstrates that many effects of cardiac AQPs, especially on excitation-contraction coupling processes, are virtually unexplored. -

Table S1 the Four Gene Sets Derived from Gene Expression Profiles of Escs and Differentiated Cells
Table S1 The four gene sets derived from gene expression profiles of ESCs and differentiated cells Uniform High Uniform Low ES Up ES Down EntrezID GeneSymbol EntrezID GeneSymbol EntrezID GeneSymbol EntrezID GeneSymbol 269261 Rpl12 11354 Abpa 68239 Krt42 15132 Hbb-bh1 67891 Rpl4 11537 Cfd 26380 Esrrb 15126 Hba-x 55949 Eef1b2 11698 Ambn 73703 Dppa2 15111 Hand2 18148 Npm1 11730 Ang3 67374 Jam2 65255 Asb4 67427 Rps20 11731 Ang2 22702 Zfp42 17292 Mesp1 15481 Hspa8 11807 Apoa2 58865 Tdh 19737 Rgs5 100041686 LOC100041686 11814 Apoc3 26388 Ifi202b 225518 Prdm6 11983 Atpif1 11945 Atp4b 11614 Nr0b1 20378 Frzb 19241 Tmsb4x 12007 Azgp1 76815 Calcoco2 12767 Cxcr4 20116 Rps8 12044 Bcl2a1a 219132 D14Ertd668e 103889 Hoxb2 20103 Rps5 12047 Bcl2a1d 381411 Gm1967 17701 Msx1 14694 Gnb2l1 12049 Bcl2l10 20899 Stra8 23796 Aplnr 19941 Rpl26 12096 Bglap1 78625 1700061G19Rik 12627 Cfc1 12070 Ngfrap1 12097 Bglap2 21816 Tgm1 12622 Cer1 19989 Rpl7 12267 C3ar1 67405 Nts 21385 Tbx2 19896 Rpl10a 12279 C9 435337 EG435337 56720 Tdo2 20044 Rps14 12391 Cav3 545913 Zscan4d 16869 Lhx1 19175 Psmb6 12409 Cbr2 244448 Triml1 22253 Unc5c 22627 Ywhae 12477 Ctla4 69134 2200001I15Rik 14174 Fgf3 19951 Rpl32 12523 Cd84 66065 Hsd17b14 16542 Kdr 66152 1110020P15Rik 12524 Cd86 81879 Tcfcp2l1 15122 Hba-a1 66489 Rpl35 12640 Cga 17907 Mylpf 15414 Hoxb6 15519 Hsp90aa1 12642 Ch25h 26424 Nr5a2 210530 Leprel1 66483 Rpl36al 12655 Chi3l3 83560 Tex14 12338 Capn6 27370 Rps26 12796 Camp 17450 Morc1 20671 Sox17 66576 Uqcrh 12869 Cox8b 79455 Pdcl2 20613 Snai1 22154 Tubb5 12959 Cryba4 231821 Centa1 17897 -

Steroid-Dependent Regulation of the Oviduct: a Cross-Species Transcriptomal Analysis
University of Kentucky UKnowledge Theses and Dissertations--Animal and Food Sciences Animal and Food Sciences 2015 Steroid-dependent regulation of the oviduct: A cross-species transcriptomal analysis Katheryn L. Cerny University of Kentucky, [email protected] Right click to open a feedback form in a new tab to let us know how this document benefits ou.y Recommended Citation Cerny, Katheryn L., "Steroid-dependent regulation of the oviduct: A cross-species transcriptomal analysis" (2015). Theses and Dissertations--Animal and Food Sciences. 49. https://uknowledge.uky.edu/animalsci_etds/49 This Doctoral Dissertation is brought to you for free and open access by the Animal and Food Sciences at UKnowledge. It has been accepted for inclusion in Theses and Dissertations--Animal and Food Sciences by an authorized administrator of UKnowledge. For more information, please contact [email protected]. STUDENT AGREEMENT: I represent that my thesis or dissertation and abstract are my original work. Proper attribution has been given to all outside sources. I understand that I am solely responsible for obtaining any needed copyright permissions. I have obtained needed written permission statement(s) from the owner(s) of each third-party copyrighted matter to be included in my work, allowing electronic distribution (if such use is not permitted by the fair use doctrine) which will be submitted to UKnowledge as Additional File. I hereby grant to The University of Kentucky and its agents the irrevocable, non-exclusive, and royalty-free license to archive and make accessible my work in whole or in part in all forms of media, now or hereafter known. -

Primate Specific Retrotransposons, Svas, in the Evolution of Networks That Alter Brain Function
Title: Primate specific retrotransposons, SVAs, in the evolution of networks that alter brain function. Olga Vasieva1*, Sultan Cetiner1, Abigail Savage2, Gerald G. Schumann3, Vivien J Bubb2, John P Quinn2*, 1 Institute of Integrative Biology, University of Liverpool, Liverpool, L69 7ZB, U.K 2 Department of Molecular and Clinical Pharmacology, Institute of Translational Medicine, The University of Liverpool, Liverpool L69 3BX, UK 3 Division of Medical Biotechnology, Paul-Ehrlich-Institut, Langen, D-63225 Germany *. Corresponding author Olga Vasieva: Institute of Integrative Biology, Department of Comparative genomics, University of Liverpool, Liverpool, L69 7ZB, [email protected] ; Tel: (+44) 151 795 4456; FAX:(+44) 151 795 4406 John Quinn: Department of Molecular and Clinical Pharmacology, Institute of Translational Medicine, The University of Liverpool, Liverpool L69 3BX, UK, [email protected]; Tel: (+44) 151 794 5498. Key words: SVA, trans-mobilisation, behaviour, brain, evolution, psychiatric disorders 1 Abstract The hominid-specific non-LTR retrotransposon termed SINE–VNTR–Alu (SVA) is the youngest of the transposable elements in the human genome. The propagation of the most ancient SVA type A took place about 13.5 Myrs ago, and the youngest SVA types appeared in the human genome after the chimpanzee divergence. Functional enrichment analysis of genes associated with SVA insertions demonstrated their strong link to multiple ontological categories attributed to brain function and the disorders. SVA types that expanded their presence in the human genome at different stages of hominoid life history were also associated with progressively evolving behavioural features that indicated a potential impact of SVA propagation on a cognitive ability of a modern human. -

Supplemental Materials ZNF281 Enhances Cardiac Reprogramming
Supplemental Materials ZNF281 enhances cardiac reprogramming by modulating cardiac and inflammatory gene expression Huanyu Zhou, Maria Gabriela Morales, Hisayuki Hashimoto, Matthew E. Dickson, Kunhua Song, Wenduo Ye, Min S. Kim, Hanspeter Niederstrasser, Zhaoning Wang, Beibei Chen, Bruce A. Posner, Rhonda Bassel-Duby and Eric N. Olson Supplemental Table 1; related to Figure 1. Supplemental Table 2; related to Figure 1. Supplemental Table 3; related to the “quantitative mRNA measurement” in Materials and Methods section. Supplemental Table 4; related to the “ChIP-seq, gene ontology and pathway analysis” and “RNA-seq” and gene ontology analysis” in Materials and Methods section. Supplemental Figure S1; related to Figure 1. Supplemental Figure S2; related to Figure 2. Supplemental Figure S3; related to Figure 3. Supplemental Figure S4; related to Figure 4. Supplemental Figure S5; related to Figure 6. Supplemental Table S1. Genes included in human retroviral ORF cDNA library. Gene Gene Gene Gene Gene Gene Gene Gene Symbol Symbol Symbol Symbol Symbol Symbol Symbol Symbol AATF BMP8A CEBPE CTNNB1 ESR2 GDF3 HOXA5 IL17D ADIPOQ BRPF1 CEBPG CUX1 ESRRA GDF6 HOXA6 IL17F ADNP BRPF3 CERS1 CX3CL1 ETS1 GIN1 HOXA7 IL18 AEBP1 BUD31 CERS2 CXCL10 ETS2 GLIS3 HOXB1 IL19 AFF4 C17ORF77 CERS4 CXCL11 ETV3 GMEB1 HOXB13 IL1A AHR C1QTNF4 CFL2 CXCL12 ETV7 GPBP1 HOXB5 IL1B AIMP1 C21ORF66 CHIA CXCL13 FAM3B GPER HOXB6 IL1F3 ALS2CR8 CBFA2T2 CIR1 CXCL14 FAM3D GPI HOXB7 IL1F5 ALX1 CBFA2T3 CITED1 CXCL16 FASLG GREM1 HOXB9 IL1F6 ARGFX CBFB CITED2 CXCL3 FBLN1 GREM2 HOXC4 IL1F7 -

Download Download
Supplementary Figure S1. Results of flow cytometry analysis, performed to estimate CD34 positivity, after immunomagnetic separation in two different experiments. As monoclonal antibody for labeling the sample, the fluorescein isothiocyanate (FITC)- conjugated mouse anti-human CD34 MoAb (Mylteni) was used. Briefly, cell samples were incubated in the presence of the indicated MoAbs, at the proper dilution, in PBS containing 5% FCS and 1% Fc receptor (FcR) blocking reagent (Miltenyi) for 30 min at 4 C. Cells were then washed twice, resuspended with PBS and analyzed by a Coulter Epics XL (Coulter Electronics Inc., Hialeah, FL, USA) flow cytometer. only use Non-commercial 1 Supplementary Table S1. Complete list of the datasets used in this study and their sources. GEO Total samples Geo selected GEO accession of used Platform Reference series in series samples samples GSM142565 GSM142566 GSM142567 GSM142568 GSE6146 HG-U133A 14 8 - GSM142569 GSM142571 GSM142572 GSM142574 GSM51391 GSM51392 GSE2666 HG-U133A 36 4 1 GSM51393 GSM51394 only GSM321583 GSE12803 HG-U133A 20 3 GSM321584 2 GSM321585 use Promyelocytes_1 Promyelocytes_2 Promyelocytes_3 Promyelocytes_4 HG-U133A 8 8 3 GSE64282 Promyelocytes_5 Promyelocytes_6 Promyelocytes_7 Promyelocytes_8 Non-commercial 2 Supplementary Table S2. Chromosomal regions up-regulated in CD34+ samples as identified by the LAP procedure with the two-class statistics coded in the PREDA R package and an FDR threshold of 0.5. Functional enrichment analysis has been performed using DAVID (http://david.abcc.ncifcrf.gov/) -

A Private 16Q24.2Q24.3 Microduplication in a Boy with Intellectual Disability, Speech Delay and Mild Dysmorphic Features
G C A T T A C G G C A T genes Article A Private 16q24.2q24.3 Microduplication in a Boy with Intellectual Disability, Speech Delay and Mild Dysmorphic Features Orazio Palumbo * , Pietro Palumbo , Ester Di Muro, Luigia Cinque, Antonio Petracca, Massimo Carella and Marco Castori Division of Medical Genetics, Fondazione IRCCS-Casa Sollievo della Sofferenza, San Giovanni Rotondo, 71013 Foggia, Italy; [email protected] (P.P.); [email protected] (E.D.M.); [email protected] (L.C.); [email protected] (A.P.); [email protected] (M.C.); [email protected] (M.C.) * Correspondence: [email protected]; Tel.: +39-088-241-6350 Received: 5 June 2020; Accepted: 24 June 2020; Published: 26 June 2020 Abstract: No data on interstitial microduplications of the 16q24.2q24.3 chromosome region are available in the medical literature and remain extraordinarily rare in public databases. Here, we describe a boy with a de novo 16q24.2q24.3 microduplication at the Single Nucleotide Polymorphism (SNP)-array analysis spanning ~2.2 Mb and encompassing 38 genes. The patient showed mild-to-moderate intellectual disability, speech delay and mild dysmorphic features. In DECIPHER, we found six individuals carrying a “pure” overlapping microduplication. Although available data are very limited, genomic and phenotype comparison of our and previously annotated patients suggested a potential clinical relevance for 16q24.2q24.3 microduplication with a variable and not (yet) recognizable phenotype predominantly affecting cognition. Comparing the cytogenomic data of available individuals allowed us to delineate the smallest region of overlap involving 14 genes. Accordingly, we propose ANKRD11, CDH15, and CTU2 as candidate genes for explaining the related neurodevelopmental manifestations shared by these patients. -

Supplementary Table 1: Adhesion Genes Data Set
Supplementary Table 1: Adhesion genes data set PROBE Entrez Gene ID Celera Gene ID Gene_Symbol Gene_Name 160832 1 hCG201364.3 A1BG alpha-1-B glycoprotein 223658 1 hCG201364.3 A1BG alpha-1-B glycoprotein 212988 102 hCG40040.3 ADAM10 ADAM metallopeptidase domain 10 133411 4185 hCG28232.2 ADAM11 ADAM metallopeptidase domain 11 110695 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 195222 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 165344 8751 hCG20021.3 ADAM15 ADAM metallopeptidase domain 15 (metargidin) 189065 6868 null ADAM17 ADAM metallopeptidase domain 17 (tumor necrosis factor, alpha, converting enzyme) 108119 8728 hCG15398.4 ADAM19 ADAM metallopeptidase domain 19 (meltrin beta) 117763 8748 hCG20675.3 ADAM20 ADAM metallopeptidase domain 20 126448 8747 hCG1785634.2 ADAM21 ADAM metallopeptidase domain 21 208981 8747 hCG1785634.2|hCG2042897 ADAM21 ADAM metallopeptidase domain 21 180903 53616 hCG17212.4 ADAM22 ADAM metallopeptidase domain 22 177272 8745 hCG1811623.1 ADAM23 ADAM metallopeptidase domain 23 102384 10863 hCG1818505.1 ADAM28 ADAM metallopeptidase domain 28 119968 11086 hCG1786734.2 ADAM29 ADAM metallopeptidase domain 29 205542 11085 hCG1997196.1 ADAM30 ADAM metallopeptidase domain 30 148417 80332 hCG39255.4 ADAM33 ADAM metallopeptidase domain 33 140492 8756 hCG1789002.2 ADAM7 ADAM metallopeptidase domain 7 122603 101 hCG1816947.1 ADAM8 ADAM metallopeptidase domain 8 183965 8754 hCG1996391 ADAM9 ADAM metallopeptidase domain 9 (meltrin gamma) 129974 27299 hCG15447.3 ADAMDEC1 ADAM-like, -
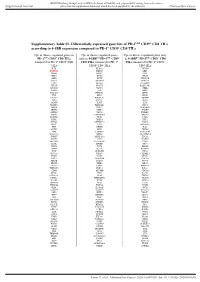
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al.