The Unicode Standard, Version 4.0, Issued by the Unicode Consor- Tium and Published by Addison-Wesley
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Bibliography
Bibliography Many books were read and researched in the compilation of Binford, L. R, 1983, Working at Archaeology. Academic Press, The Encyclopedic Dictionary of Archaeology: New York. Binford, L. R, and Binford, S. R (eds.), 1968, New Perspectives in American Museum of Natural History, 1993, The First Humans. Archaeology. Aldine, Chicago. HarperSanFrancisco, San Francisco. Braidwood, R 1.,1960, Archaeologists and What They Do. Franklin American Museum of Natural History, 1993, People of the Stone Watts, New York. Age. HarperSanFrancisco, San Francisco. Branigan, Keith (ed.), 1982, The Atlas ofArchaeology. St. Martin's, American Museum of Natural History, 1994, New World and Pacific New York. Civilizations. HarperSanFrancisco, San Francisco. Bray, w., and Tump, D., 1972, Penguin Dictionary ofArchaeology. American Museum of Natural History, 1994, Old World Civiliza Penguin, New York. tions. HarperSanFrancisco, San Francisco. Brennan, L., 1973, Beginner's Guide to Archaeology. Stackpole Ashmore, w., and Sharer, R. J., 1988, Discovering Our Past: A Brief Books, Harrisburg, PA. Introduction to Archaeology. Mayfield, Mountain View, CA. Broderick, M., and Morton, A. A., 1924, A Concise Dictionary of Atkinson, R J. C., 1985, Field Archaeology, 2d ed. Hyperion, New Egyptian Archaeology. Ares Publishers, Chicago. York. Brothwell, D., 1963, Digging Up Bones: The Excavation, Treatment Bacon, E. (ed.), 1976, The Great Archaeologists. Bobbs-Merrill, and Study ofHuman Skeletal Remains. British Museum, London. New York. Brothwell, D., and Higgs, E. (eds.), 1969, Science in Archaeology, Bahn, P., 1993, Collins Dictionary of Archaeology. ABC-CLIO, 2d ed. Thames and Hudson, London. Santa Barbara, CA. Budge, E. A. Wallis, 1929, The Rosetta Stone. Dover, New York. Bahn, P. -

Rank of Weighted Digraphs with Blocks
Rank of weighted digraphs with blocks∗ Ranveer Singh† Swarup Kumar Panda ‡ Naomi Shaked-Monderer§ Abraham Berman¶ October 10, 2018 Abstract Let G be a digraph and r(G) be its rank. Many interesting results on the rank of an undirected graph appear in the literature, but not much information about the rank of a digraph is available. In this article, we study the rank of a digraph using the ranks of its blocks. In particular, we define classes of digraphs, namely r2-digraph, and r0-digraph, for which the rank can be exactly determined in terms of the ranks of subdigraphs of the blocks. Furthermore, the rank of directed trees, simple biblock graphs, and some simple block graphs are studied. Keywords: r2-digraphs, r0-digraphs, tree digraphs, block graphs, biblock graphs AMS Subject Classifications. 15A15, 15A18, 05C50 1 Introduction A well-known problem, proposed in 1957 by Collatz and Sinogowitz, is to characterize graphs with positive nullity [19]. Nullity of graphs is applicable in various branches of science, in particular, quantum chemistry, H¨uckel molecular orbital theory [10], [13] and social network theory [14]. For more detail on the applications see [10]. Many significant results on the nullity of undirected graphs are available in the literature, see [4, 7, 11, 12, 15, 12, 2, 3, 20]. Recently in [9, 8, 6] nullity of undirected graphs was studied using cut-vertices and connected components. The results are used to calculate the nullity of line graphs of undirected graphs. Apart from the connected components, it turns out that the blocks are also interesting subgraphs of a graph, which can be utilized to know its determinant [17, 16]. -
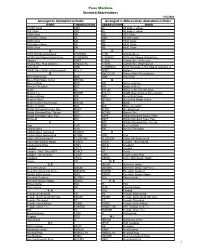
Arranged in Abbreviation Alphabetical Order Arranged in Alphabetical Order Penn Machine Standard Abbreviations
Penn Machine Standard Abbreviations 1/25/2008 Arranged in Alphabetical Order Arranged in Abbreviation Alphabetical Order WORD ABBREVIATION ABBREVIATION WORD 10,000 Class 10M 45 45 degree elbow 150 Class 150 90 90 degree elbow 3000 Class 3M 150 150 Class 45 degree elbow 45 10M 10,000 Class 6000 Class 6M 3M 3000 Class 90 degree elbow 90 6M 6000 Class 9000 Class 9M 9M 9000 Class A A A105 Hot Dip Galvanized A105HDG A105 Carbon Steel A105N Hot Dipped Galvanized A105NHDG A105HDG A105 Hot Dipped Galvanized Adapter ADPT A105A Carbon Steel Annealed Amoco Pipe Plug w/groove AMOCO PL A105N Carbon Steel Normalized Annealed ANN A105NHDG A105 Normalized Hot Dipped Galvanized ASME Spec Defines Dimensions* B16.11 ADPT Adapter B AMOCO PL Amoco Pipe Plug w/groove Bevel Both Ends BBE ANN Annealed Bevel End Nipple Outlet BE NOL B Bevel x Plain BXP B/B Brass to Brass Bevel x Threaded BXT B/S Brass to Steel Blank BL B/S UN Brass to Steel Seat Union Branch Tee BRTEE B16.11 ASME Spec Defines Dimensions* Brass to Brass B/B BBE Bevel Both Ends Brass to Steel B/S BE NOL Bevel End Nipple Outlet Brass to Steel Seat Union B/S UN BL Blank Braze-on Outlet BOL BOL Braze-on Outlet British Standard Parallel Pipe BSPP BOSS Welding Boss British Standard Pipe Thread BST BRTEE Branch Tee British Standard Taper Pipe BSPT BSPP British Standard Parallel Pipe Buttweld BW BSPT British Standard Taper Pipe C BST British Standard Pipe Thread Cap CAP BXP Bevel x Plain Carbon Steel A105 BXT Bevel x Threaded Carbon Steel Annealed A105HT C Carbon Steel Normalized A105N CAP Cap Class 200 -

31 Vowel Digraph Oo
Sort Vowel Digraph oo 31 Objectives • To identify spelling patterns of vowel digraph oo Words • To read, sort, and write words with vowel digraph oo o˘o oˉo = uˉ Oddball brook nook fool spool could Materials for Within Word Pattern crook soot groom spoon should Big Book of Rhymes, “The Puppet Show,” page 55 foot stood hoop stool would hood wood noon tool Whiteboard Activities DVD-ROM, Sort 31 hook wool root troop Teacher Resource CD-ROM, Sort 31 and Follow the Dragon Game Student Book, pages 121–124 Words Their Way Library, The House That Stood on Booker Hill Introduce/Model Small Groups • Read a Rhyme Read “The Puppet Show,” and Extend the Sort emphasize words with the vowel digraph oo. (wood, book, took; soon, noon) Ask students to locate these Alternative Sort: Brainstorming words, and help them write the words in two columns, Ask students to think of other words that contain according to vowel sound. Help students hear the oo. Write their responses on index cards. When different pronunciations of the vowel digraph oo. students have completed brainstorming, ask them to identify and sort all the words they named • Model Use the whiteboard DVD or the CD word according to the vowel sound of oo. cards. Define in context any that may be unfamiliar to students. Demonstrate how to sort the words ELL English Language Learners according to the sound of the digraph oo. Point out Explain that a nook is “a hidden place,” and that that would, could, and should do not contain the groom can have several meanings, including “a digraph oo, so they belong in the oddball category. -

Alphabetization† †† Wendy Korwin*, Haakon Lund** *119 W
Knowl. Org. 46(2019)No.3 209 W. Korwin and H. Lund. Alphabetization Alphabetization† †† Wendy Korwin*, Haakon Lund** *119 W. Dunedin Rd., Columbus, OH 43214, USA, <[email protected]> **University of Copenhagen, Department of Information Studies, DK-2300 Copenhagen S Denmark, <[email protected]> Wendy Korwin received her PhD in American studies from the College of William and Mary in 2017 with a dissertation entitled Material Literacy: Alphabets, Bodies, and Consumer Culture. She has worked as both a librarian and an archivist, and is currently based in Columbus, Ohio, United States. Haakon Lund is Associate Professor at the University of Copenhagen, Department of Information Studies in Denmark. He is educated as a librarian (MLSc) from the Royal School of Library and Information Science, and his research includes research data management, system usability and users, and gaze interaction. He has pre- sented his research at international conferences and published several journal articles. Korwin, Wendy and Haakon Lund. 2019. “Alphabetization.” Knowledge Organization 46(3): 209-222. 62 references. DOI:10.5771/0943-7444-2019-3-209. Abstract: The article provides definitions of alphabetization and related concepts and traces its historical devel- opment and challenges, covering analog as well as digital media. It introduces basic principles as well as standards, norms, and guidelines. The function of alphabetization is considered and related to alternatives such as system- atic arrangement or classification. Received: 18 February 2019; Revised: 15 March 2019; Accepted: 21 March 2019 Keywords: order, orders, lettering, alphabetization, arrangement † Derived from the article of similar title in the ISKO Encyclopedia of Knowledge Organization Version 1.0; published 2019-01-10. -

Conversion Table a = 1 B = 2 C = 3 D = 4 E = 5 F = 6 G = 7 H = 8 I = 9 J = 10 K =11 L = 12 M = 13 N =14 O =15 P = 16 Q =17 R
Classroom Activity 2 Math 113 The Dating Game Introduction: Disclaimer: Although this is called the “Dating Game”, it is merely intended to help the student gain understanding of the concept of Standard Deviation. It is not intended to help students find dates. The day after Thanksgiving, 1996, I was driving my sister, Conversion Table brother-in-law, and sister-in-law over to meet my brother in A=1 K=11 U=21 Springfield at the Mission where he and his wife helped out. B=2 L=12 V=22 During this drive, I ask my sister, “How do you know which C=3 M=13 W=23 woman is the right one for you?”. Now, my sister was born D=4 N=14 X=24 a Jones, and like the rest of the family, she can make E=5 O=15 Y=25 anything sound believable. Without missing a beat, she F=6 P=16 Z=26 said, “You take the letters in her name, convert them to G=7 Q=17 numbers, find the standard deviation, and whoever’s H=8 R=18 standard deviation is closest to yours is the woman for you.” I=9S=19 I was so proud of my sister, that was a really good answer. J=10 T=20 Then, she followed it up with “Actually, if you can find a woman who knows what a standard deviation is, that’s the woman for you.” The first part was easy, take each letter in your name and convert it to a number. Use the system where an A=1, B=2, .. -

Russia Imperial Russia & Soviet Union May 26, 2014
© 2014, David Feldman S.A. All rights reserved All content of this catalogue, such as text, images and their arrangement, is the property of David Feldman S.A., and is protected by international copyright laws. The objects displayed in this catalogue are shown with the expressed permission of their owners. Produced through The Bookmaker Printed in China by CTPS Russia Imperial Russia & Soviet Union May 26, 2014 Genève - Feldman Galleries Imperial Russia 10000-10454 Soviet Union 10455-10584 Contact Us Geneva 175, Route de Chancy, P.O. Box 81, CH-1213 Onex, Geneva, Switzerland Tel. +41 (0)22 727 07 77 – Fax +41 (0)22 727 07 78 – [email protected] www.davidfeldman.com Russia Imperial Russia & Soviet Union May 26, 2014 You are invited to participate VIEWING / VisiTE des LOTS / ANZeige Geneva / Genève / Genf Before May 23 Feldman Galleries 175 route de Chancy, 1213 Onex, Geneva, Switzerland By appointment: contact Tel.: +41 (0)22 727 07 77 (Viewing of lots on weekends or evenings can be arranged) From May 26 General viewing from 09:00 to 19:00 daily AUCTION / VENTE / AUKTION May 26 at 15:00 Lots 10000-10584 Phone line during the auction / Ligne téléphonique pendant la vente / Telefonleitung während der Auktion Tel. +41 22 727 07 77 British Guiana The John E. Du Pont Grand Prix Collection Geneva, June 27, 2014 One of the most important collections ever formed of the famous primitive issues Tasmania The Koichi Sato Grand Prix d’Honneur Collection Geneva, June 27, 2014 A wonderful collection of this rarely offered Australian State Geneva Hong Kong New York 175, Route de Chancy, P.O. -

Optimal Interleaving: Serial Phonology-Morphology Interaction in a Constraint-Based Model
OPTIMAL INTERLEAVING: SERIAL PHONOLOGY-MORPHOLOGY INTERACTION IN A CONSTRAINT-BASED MODEL A Dissertation Presented by MATTHEW ADAM WOLF Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY September 2008 Department of Linguistics © Copyright by Matthew Adam Wolf 2008 All Rights Reserved OPTIMAL INTERLEAVING: SERIAL PHONOLOGY-MORPHOLOGY INTERACTION IN A CONSTRAINT-BASED MODEL A Dissertation Presented by MATTHEW A. WOLF Approved as to style and content by: ____________________________________ John J. McCarthy, Chair ____________________________________ Joseph V. Pater, Member ____________________________________ Elisabeth O. Selkirk, Member ____________________________________ Mark H. Feinstein, Member ___________________________________ Elisabeth O. Selkirk, Head Department of Linguistics ACKNOWLEDGEMENTS I’ve learned from my own habits over the years that the acknowledgements are likely to be the most-read part of any dissertation. It is therefore with a degree of trepidation that I set down these words of thanks, knowing that any omissions or infelicities I might commit will be a source of amusement for who-knows-how-many future generations of first-year graduate students. So while I’ll make an effort to avoid cliché, falling into it will sometimes be inevitable—for example, when I say (as I must, for it is true) that this work could never have been completed without the help of my advisor, John McCarthy. John’s willingness to patiently hear out half-baked ideas, his encyclopedic knowledge of the phonology literature, his almost unbelievably thorough critical eye, and his dogged insistence on making the vague explicit have made this dissertation far better, and far better presented, than I could have hoped to achieve on my own. -

Campusroman Pro Presentation
MacCampus® Fonts CampusRoman Pro our Unicode Reference font UNi UC .otf code 7.0 .ttf € $ MacCampus® Fonts CampusRoman Pro • Supports everything Latin, Cyrillic, Greek, and Coptic, Lisu; • phonetics, combining diacritics, spacing modifiers, punctuation, editorial marks, tone letters, counting rod numerals; mathematical alphanumerics; • transliterated Armenian, Georgian, Glagolitic, Gothic, and Old Persian Cuneiform; • superscripts & subscripts, currency signs, letterlike symbols, number forms, enclosed alphanumerics, dingbats... contains ca. 5.000 characters, incl. 133 (!) completely new additions from Unicode v. 7.0 (July 2014), esp. for German dialectology UC 7.0 MacCampus® Fonts CampusRoman Pro UC NEW: LatinExtended-E: Letters for 7.0 German dialectology and Americanist orthographies MacCampus® Fonts CampusRoman Pro UC NEW: LatinExtended-D: Lithuanian 7.0 dialectology, middle Vietnamese,Ewe, Volapük, Celtic epigraphy, Americanist orthographies, etc. MacCampus® Fonts CampusRoman Pro UC NEW: Cyrillic Supplement: Orok, 7.0 Komi, Khanty letters MacCampus® Fonts CampusRoman Pro UC NEW: CyrillicExtended-B: Letters 7.0 for Old Cyrillic and Lithuanian dialectology MacCampus® Fonts CampusRoman Pro UC NEW: Supplemental Punctuation: 7.0 alternate, historic and reversed punctuation; double hyphen MacCampus® Fonts CampusRoman Pro UC NEW: Currency: Nordic Mark, 7.0 Manat, Ruble MacCampus® Fonts CampusRoman Pro UC NEW: Combining Diacritics Extended 7.0 + Combining Halfmarks: German dialectology; comb. halfmarks below MacCampus® Fonts CampusRoman Pro UC NEW: Combining Diacritics Supplement: 7.0 Superscript letters for German dialectology MacCampus® Fonts CampusRoman Pro • available now • single and multi-user licenses • embeddable • OpenType and TrueType • professionally designed • from a linguist for linguists • for scholars-philologists UC 7.0 • one weight (upright) only • Unicode 7.0 compliant MacCampus® Fonts A Lang. Font З ABC List www.maccampus.de www.maccampus.de/fonts/CampusRoman-Pro.htm © Sebastian Kempgen 2014. -

The Gentics of Civilization: an Empirical Classification of Civilizations Based on Writing Systems
Comparative Civilizations Review Volume 49 Number 49 Fall 2003 Article 3 10-1-2003 The Gentics of Civilization: An Empirical Classification of Civilizations Based on Writing Systems Bosworth, Andrew Bosworth Universidad Jose Vasconcelos, Oaxaca, Mexico Follow this and additional works at: https://scholarsarchive.byu.edu/ccr Recommended Citation Bosworth, Bosworth, Andrew (2003) "The Gentics of Civilization: An Empirical Classification of Civilizations Based on Writing Systems," Comparative Civilizations Review: Vol. 49 : No. 49 , Article 3. Available at: https://scholarsarchive.byu.edu/ccr/vol49/iss49/3 This Article is brought to you for free and open access by the Journals at BYU ScholarsArchive. It has been accepted for inclusion in Comparative Civilizations Review by an authorized editor of BYU ScholarsArchive. For more information, please contact [email protected], [email protected]. Bosworth: The Gentics of Civilization: An Empirical Classification of Civil 9 THE GENETICS OF CIVILIZATION: AN EMPIRICAL CLASSIFICATION OF CIVILIZATIONS BASED ON WRITING SYSTEMS ANDREW BOSWORTH UNIVERSIDAD JOSE VASCONCELOS OAXACA, MEXICO Part I: Cultural DNA Introduction Writing is the DNA of civilization. Writing permits for the organi- zation of large populations, professional armies, and the passing of complex information across generations. Just as DNA transmits biolog- ical memory, so does writing transmit cultural memory. DNA and writ- ing project information into the future and contain, in their physical structure, imprinted knowledge.