“Implementing Non-Photorealistic Rendering Enhancements with Real-Time Performance”
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Creating Manga-Style Artwork in Corel Painter X
Creating manga-style artwork in Corel® Painter™ X Jared Hodges Manga is the Japanese word for comic. Manga-style comic books, graphic novels, and artwork are gaining international popularity. Bronco Boar, created by Jared Hodges in Corel Painter X The inspiration for Bronco Boar comes from my interest in fantastical beasts, Mesoamerican design motifs, and my background in Japanese manga-style imagery. In the image, I wanted to evoke a feeling of an American Southwest desert with a fantasy twist. I came up with the idea of an action scene portraying a cowgirl breaking in an aggressive oversized boar. In this tutorial, you will learn about • character design • creating a rough sketch of the composition • finalizing line art • the coloring process • adding texture, details, and final colors 1 Character Design This picture focuses on two characters: the cowgirl and the boar. I like to design the characters before I work on the actual image, so I can concentrate on their appearance before I consider pose and composition. The cowgirl's costume was inspired by western clothing: cowboy hat, chaps, gloves, and boots. I added my own twist to create a nontraditional design. I enlisted the help of fellow artist and partner, Lindsay Cibos, to create a couple of conceptual character designs based on my criteria. Two concept sketches by Lindsay Cibos. These sketches helped me decide which design elements and colors to use for the character's outfit. Combining our ideas, I sketched the final design using a custom 2B Pencil variant from the Pencils category, switching between a size of 3 pixels for detail work and 5 pixels for broader strokes. -

Texture Mapping for Cel Animation
Texture Mapping for Cel Animation 1 2 1 Wagner Toledo Corrˆea1 Robert J. Jensen Craig E. Thayer Adam Finkelstein 1 Princeton University 2 Walt Disney Feature Animation (a) Flat colors (b) Complex texture Figure 1: A frame of cel animation with the foreground character painted by (a) the conventional method, and (b) our system. Abstract 1 INTRODUCTION We present a method for applying complex textures to hand-drawn In traditional cel animation, moving characters are illustrated with characters in cel animation. The method correlates features in a flat, constant colors, whereas background scenery is painted in simple, textured, 3-D model with features on a hand-drawn figure, subtle and exquisite detail (Figure 1a). This disparity in render- and then distorts the model to conform to the hand-drawn artwork. ing quality may be desirable to distinguish the animated characters The process uses two new algorithms: a silhouette detection scheme from the background; however, there are many figures for which and a depth-preserving warp. The silhouette detection algorithm is complex textures would be advantageous. Unfortunately, there are simple and efficient, and it produces continuous, smooth, visible two factors that prohibit animators from painting moving charac- contours on a 3-D model. The warp distorts the model in only two ters with detailed textures. First, moving characters are drawn dif- dimensions to match the artwork from a given camera perspective, ferently from frame to frame, requiring any complex shading to yet preserves 3-D effects such as self-occlusion and foreshortening. be replicated for every frame, adapting to the movements of the The entire process allows animators to combine complex textures characters—an extremely daunting task. -

Guide to Digital Art Specifications
Guide to Digital Art Specifications Version 12.05.11 Image File Types Digital image formats for both Mac and PC platforms are accepted. Preferred file types: These file types work best and typically encounter few problems. tif (TIFF) jpg (JPEG) psd (Adobe Photoshop document) eps (Encapsulated PostScript) ai (Adobe Illustrator) pdf (Portable Document Format) Accepted file types: These file types are acceptable, although application versions and operating systems can introduce problems. A hardcopy, for cross-referencing, will ensure a more accurate outcome. doc, docx (Word) xls, xlsx (Excel) ppt, pptx (PowerPoint) fh (Freehand) cdr (Corel Draw) cvs (Canvas) Image sizing specifications should be discussed with the Editorial Office prior to digital file submission. Digital images should be submitted in the final size desired. White space around the image should be removed. Image Resolution The minimum acceptable resolution is 200 dpi at the desired final size in the paged article. To ensure the highest-quality published image, follow these optimum resolutions: • Line = 1200 dpi. Contains only black and white; no shades of gray. These images are typically ink drawings or charts. Other common terms used are monochrome or 1-bit. • Grayscale or Color = 300 dpi. Contains no text. A photograph or a painting is an example of this type of image. • Combination = 600 dpi. Grayscale or color image combined with a line image. An example is a photograph with letter labels, arrows, or text added outside the image area. Anytime a picture is combined with type outside the image area, the resolution must be high enough to maintain smooth, readable text. -

POWERVR 3D Application Development Recommendations
Imagination Technologies Copyright POWERVR 3D Application Development Recommendations Copyright © 2009, Imagination Technologies Ltd. All Rights Reserved. This publication contains proprietary information which is protected by copyright. The information contained in this publication is subject to change without notice and is supplied 'as is' without warranty of any kind. Imagination Technologies and the Imagination Technologies logo are trademarks or registered trademarks of Imagination Technologies Limited. All other logos, products, trademarks and registered trademarks are the property of their respective owners. Filename : POWERVR. 3D Application Development Recommendations.1.7f.External.doc Version : 1.7f External Issue (Package: POWERVR SDK 2.05.25.0804) Issue Date : 07 Jul 2009 Author : POWERVR POWERVR 1 Revision 1.7f Imagination Technologies Copyright Contents 1. Introduction .................................................................................................................................4 1. Golden Rules...............................................................................................................................5 1.1. Batching.........................................................................................................................5 1.1.1. API Overhead ................................................................................................................5 1.2. Opaque objects must be correctly flagged as opaque..................................................6 1.3. Avoid mixing -
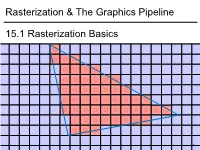
Rasterization & the Graphics Pipeline 15.1 Rasterization Basics
1 1 0.8 0.6 0.4 0.2 0 -0.2 -0.4 -0.6 -0.8 15.1Rasterization Basics Rasterization & TheGraphics Pipeline Rasterization& -1 -1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1 In This Video • The Graphics Pipeline and how it processes triangles – Projection, rasterisation, shading, depth testing • DirectX12 and its stages 2 Modern Graphics Pipeline • Input – Geometric model • Triangle vertices, vertex normals, texture coordinates – Lighting/material model (shader) • Light source positions, colors, intensities, etc. • Texture maps, specular/diffuse coefficients, etc. – Viewpoint + projection plane – You know this, you’ve done it! • Output – Color (+depth) per pixel Colbert & Krivanek 3 The Graphics Pipeline • Project vertices to 2D (image) • Rasterize triangle: find which pixels should be lit • Compute per-pixel color • Test visibility (Z-buffer), update frame buffer color 4 The Graphics Pipeline • Project vertices to 2D (image) • Rasterize triangle: find which pixels should be lit – For each pixel, test 3 edge equations • if all pass, draw pixel • Compute per-pixel color • Test visibility (Z-buffer), update frame buffer color 5 The Graphics Pipeline • Perform projection of vertices • Rasterize triangle: find which pixels should be lit • Compute per-pixel color • Test visibility, update frame buffer color – Store minimum distance to camera for each pixel in “Z-buffer” • ~same as tmin in ray casting! – if new_z < zbuffer[x,y] zbuffer[x,y]=new_z framebuffer[x,y]=new_color frame buffer Z buffer 6 The Graphics Pipeline For each triangle transform into eye space (perform projection) setup 3 edge equations for each pixel x,y if passes all edge equations compute z if z<zbuffer[x,y] zbuffer[x,y]=z framebuffer[x,y]=shade() 7 (Simplified version) DirectX 12 Pipeline (Vulkan & Metal are highly similar) Vertex & Textures, index data etc. -

Learning to Shadow Hand-Drawn Sketches
Learning to Shadow Hand-drawn Sketches Qingyuan Zheng∗1, Zhuoru Li∗2, and Adam Bargteil1 1University of Maryland, Baltimore County 2Project HAT fqing3, [email protected], [email protected] Abstract We present a fully automatic method to generate detailed and accurate artistic shadows from pairs of line drawing sketches and lighting directions. We also contribute a new dataset of one thousand examples of pairs of line draw- ings and shadows that are tagged with lighting directions. Remarkably, the generated shadows quickly communicate the underlying 3D structure of the sketched scene. Con- sequently, the shadows generated by our approach can be used directly or as an excellent starting point for artists. We demonstrate that the deep learning network we propose takes a hand-drawn sketch, builds a 3D model in latent space, and renders the resulting shadows. The generated shadows respect the hand-drawn lines and underlying 3D space and contain sophisticated and accurate details, such Figure 1: Top: our shadowing system takes in a line drawing and as self-shadowing effects. Moreover, the generated shadows a lighting direction label, and outputs the shadow. Bottom: our contain artistic effects, such as rim lighting or halos ap- training set includes triplets of hand-drawn sketches, shadows, and pearing from back lighting, that would be achievable with lighting directions. Pairs of sketches and shadow images are taken traditional 3D rendering methods. from artists’ websites and manually tagged with lighting directions with the help of professional artists. The cube shows how we de- note the 26 lighting directions (see Section 3.1). c Toshi, Clement 1. -

Sleek Illustration That Fades from Line Art to Color
Sleek Illustration that Fades from Line Art to Color In this tutorial, you will work with a few images you chose and you will create a nice looking illustration. The idea behind this illustration was to create a war between reality and line art. Video Tutorial Our video editor Gavin Steele has created this series of video tutorials to compliment this line art + image tutorial. Step 1 First create a new document that is 1100 pixels wide by 1500 pixels high at a resolution of 300 pixels per inch. For this project I will use a texture that I like very much. I would like to thank the author of this texture Princess-of-Shadows for putting this together. Now, move the texture into your document. Step 2 Next you need to select the images you will use for this design. I bought three nice images that you might be familiar with 1, 2, 3. Let’s start with image 1, and using the Pen Tool (P) you need to create a path around the dancer. Step 3 Now that you finished creating the path you need to set your brush size to 1px and Hardness at 100%. Next create a new layer and name it "contour1." Next, using the Pen Tool (P) right-click then select Stroke Path, select the brush and make sure the Simulate Pressure is not selected. Also, you need to make the stroke black. Step 4 Now that you have created the stroke do not delete the path. Next you need to press Command + Enter to transform the path into a selection and then you need to press the Add Layer Mask button. -
Inking and Painting for Animation Old and New Methods of Coloring Animation by Prof
D’source 1 Digital Learning Environment for Design - www.dsource.in Design Course Inking and Painting for Animation Old and new methods of Coloring Animation by Prof. Phani Tetali and Geetanjali Barthwal IDC, IIT Bombay Source: http://www.dsource.in/course/inking-and-painting-an- imation 1. About 2. Traditional Ink and Paint 3. Digital Ink and Paint 4. Exercise 5. Traditional and Digital Process 6. Links and References 7. Video 8. Contact Details D’source 2 Digital Learning Environment for Design - www.dsource.in Design Course About Inking and Painting for Animation created on paper is referred as 2d animation. It is the flipping of paper frames that creates an illusion Animation of movement in the still drawings. Old and new methods of Coloring Animation by If we talk about the past, one of the very first animations of this method is Blackton’s animation called as “Hu- Prof. Phani Tetali and Geetanjali Barthwal morous Phases of Funny Faces” and Winsor McCay’s “Gertie -the Dinosaur” . It was in early twenties when tra- IDC, IIT Bombay ditional animation techniques were developed and more sophisticated cartoons were produced. Walt Disney is called as a pioneer of hand drawn animation method. Links: • www.youtube.com/watch?v=bJuD4AlLINU Source: http://www.dsource.in/course/inking-and-painting-an- The simplest examples of animated drawings are the flipbooks, which gives illusion of movement. imation/about Here, the animator is creating 2d animation by referring the movement and repeatedly flipping the frames. He is taking help of the light box to make the paper base semi-transparent for animating the drawings. -

Powervr Graphics - Latest Developments and Future Plans
PowerVR Graphics - Latest Developments and Future Plans Latest Developments and Future Plans A brief introduction • Joe Davis • Lead Developer Support Engineer, PowerVR Graphics • With Imagination’s PowerVR Developer Technology team for ~6 years • PowerVR Developer Technology • SDK, tools, documentation and developer support/relations (e.g. this session ) facebook.com/imgtec @PowerVRInsider │ #idc15 2 Company overview About Imagination Multimedia, processors, communications and cloud IP Driving IP innovation with unrivalled portfolio . Recognised leader in graphics, GPU compute and video IP . #3 design IP company world-wide* Ensigma Communications PowerVR Processors Graphics & GPU Compute Processors SoC fabric PowerVR Video MIPS Processors General Processors PowerVR Vision Processors * source: Gartner facebook.com/imgtec @PowerVRInsider │ #idc15 4 About Imagination Our IP plus our partners’ know-how combine to drive and disrupt Smart WearablesGaming Security & VR/AR Advanced Automotive Wearables Retail eHealth Smart homes facebook.com/imgtec @PowerVRInsider │ #idc15 5 About Imagination Business model Licensees OEMs and ODMs Consumers facebook.com/imgtec @PowerVRInsider │ #idc15 6 About Imagination Our licensees and partners drive our business facebook.com/imgtec @PowerVRInsider │ #idc15 7 PowerVR Rogue Hardware PowerVR Rogue Recap . Tile-based deferred renderer . Building on technology proven over 5 previous generations . Formally announced at CES 2012 . USC - Universal Shading Cluster . New scalar SIMD shader core . General purpose compute is a first class citizen in the core … . … while not forgetting what makes a shader core great for graphics facebook.com/imgtec @PowerVRInsider │ #idc15 9 TBDR Tile-based . Tile-based . Split each render up into small tiles (32x32 for the most part) . Bin geometry after vertex shading into those tiles . Tile-based rasterisation and pixel shading . -

Real-Time Ray Traced Ambient Occlusion and Animation Image Quality and Performance of Hardware- Accelerated Ray Traced Ambient Occlusion
DEGREE PROJECTIN COMPUTER SCIENCE AND ENGINEERING, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2021 Real-time Ray Traced Ambient Occlusion and Animation Image quality and performance of hardware- accelerated ray traced ambient occlusion FABIAN WALDNER KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE Real-time Ray Traced Ambient Occlusion and Animation Image quality and performance of hardware-accelerated ray traced ambient occlusion FABIAN Waldner Master’s Programme, Industrial Engineering and Management, 120 credits Date: June 2, 2021 Supervisor: Christopher Peters Examiner: Tino Weinkauf School of Electrical Engineering and Computer Science Swedish title: Strålspårad ambient ocklusion i realtid med animationer Swedish subtitle: Bildkvalité och prestanda av hårdvaruaccelererad, strålspårad ambient ocklusion © 2021 Fabian Waldner Abstract | i Abstract Recently, new hardware capabilities in GPUs has opened the possibility of ray tracing in real-time at interactive framerates. These new capabilities can be used for a range of ray tracing techniques - the focus of this thesis is on ray traced ambient occlusion (RTAO). This thesis evaluates real-time ray RTAO by comparing it with ground- truth ambient occlusion (GTAO), a state-of-the-art screen space ambient occlusion (SSAO) method. A contribution by this thesis is that the evaluation is made in scenarios that includes animated objects, both rigid-body animations and skinning animations. This approach has some advantages: it can emphasise visual artefacts that arise due to objects moving and animating. Furthermore, it makes the performance tests better approximate real-world applications such as video games and interactive visualisations. This is particularly true for RTAO, which gets more expensive as the number of objects in a scene increases and have additional costs from managing the ray tracing acceleration structures. -

Rendering 3D Graphics As an Aid to Stylized Line Drawings in Perspective
Original scientific paper http://doi.org/10.24867/JGED-2016-2-005 rendering 3d graphics as an aid to stylized line drawings in perspective ABSTRACT The aim of the research was to study the issue of drawing 2D objects Mark Arandjus, and environments in perspective and attempted to ease the process of Helena Gabrijelčič Tomc drawing them with the aid of three-dimensional computer graphics. The goal of the research was to develop the method, which would exclude the need to trace three-dimensional models, which many digital artists use University of Ljubljana, as a guide when making drawings. The need to trace has been eliminat- Faculty of Natural Sciences and ed by finding a procedure to render three-dimensional models to appear Engineering, Ljubljana, Slovenia drawn – to appear drawn by an artist who has a stylized line style. After researching various techniques of rendering, Sketchup was used to make Corresponding author: and apply a Sketchup style which emulated a line style. After that, various Helena Gabrijelčič Tomc tests were performed using computer measurements and questionnaires e-mail: to determine if the observers could distinguish between three-dimen- [email protected] sional renders and two-dimensional drawings. The results have shown that very few participants notice three-dimensional graphics rendered with Sketchup. Even among the few observers who did notice the pres- First recieved: 24.12.2015. ence of three-dimensional models, none detected even half. The results Accepted: 26.10.2016. confirmed the adequateness of the methodology, which enables a more correct creation of element in perspective and convinces the observ- ers that the entire image is stylistically uniform hand drawn image. -

Michael Doggett Department of Computer Science Lund University Overview
Graphics Architectures and OpenCL Michael Doggett Department of Computer Science Lund university Overview • Parallelism • Radeon 5870 • Tiled Graphics Architectures • Important when Memory and Bandwidth limited • Different to Tiled Rasterization! • Tessellation • OpenCL • Programming the GPU without Graphics © mmxii mcd “Only 10% of our pixels require lots of samples for soft shadows, but determining which 10% is slower than always doing the samples. ” by ID_AA_Carmack, Twitter, 111017 Parallelism • GPUs do a lot of work in parallel • Pipelining, SIMD and MIMD • What work are they doing? © mmxii mcd What’s running on 16 unifed shaders? 128 fragments in parallel 16 cores = 128 ALUs MIMD 16 simultaneous instruction streams 5 Slide courtesy Kayvon Fatahalian vertices/fragments primitives 128 [ OpenCL work items ] in parallel CUDA threads vertices primitives fragments 6 Slide courtesy Kayvon Fatahalian Unified Shader Architecture • Let’s take the ATI Radeon 5870 • From 2009 • What are the components of the modern graphics hardware pipeline? © mmxii mcd Unified Shader Architecture Grouper Rasterizer Unified shader Texture Z & Alpha FrameBuffer © mmxii mcd Unified Shader Architecture Grouper Rasterizer Unified Shader Texture Z & Alpha FrameBuffer ATI Radeon 5870 © mmxii mcd Shader Inputs Vertex Grouper Tessellator Geometry Grouper Rasterizer Unified Shader Thread Scheduler 64 KB GDS SIMD 32 KB LDS Shader Processor 5 32bit FP MulAdd Texture Sampler Texture 16 Shader Processors 256 KB GPRs 8 KB L1 Tex Cache 20 SIMD Engines Shader Export Z & Alpha 4