Fully Automatic Anime Character Colorization with Painting of Details on Empty Pupils
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Creating Manga-Style Artwork in Corel Painter X
Creating manga-style artwork in Corel® Painter™ X Jared Hodges Manga is the Japanese word for comic. Manga-style comic books, graphic novels, and artwork are gaining international popularity. Bronco Boar, created by Jared Hodges in Corel Painter X The inspiration for Bronco Boar comes from my interest in fantastical beasts, Mesoamerican design motifs, and my background in Japanese manga-style imagery. In the image, I wanted to evoke a feeling of an American Southwest desert with a fantasy twist. I came up with the idea of an action scene portraying a cowgirl breaking in an aggressive oversized boar. In this tutorial, you will learn about • character design • creating a rough sketch of the composition • finalizing line art • the coloring process • adding texture, details, and final colors 1 Character Design This picture focuses on two characters: the cowgirl and the boar. I like to design the characters before I work on the actual image, so I can concentrate on their appearance before I consider pose and composition. The cowgirl's costume was inspired by western clothing: cowboy hat, chaps, gloves, and boots. I added my own twist to create a nontraditional design. I enlisted the help of fellow artist and partner, Lindsay Cibos, to create a couple of conceptual character designs based on my criteria. Two concept sketches by Lindsay Cibos. These sketches helped me decide which design elements and colors to use for the character's outfit. Combining our ideas, I sketched the final design using a custom 2B Pencil variant from the Pencils category, switching between a size of 3 pixels for detail work and 5 pixels for broader strokes. -

Texture Mapping for Cel Animation
Texture Mapping for Cel Animation 1 2 1 Wagner Toledo Corrˆea1 Robert J. Jensen Craig E. Thayer Adam Finkelstein 1 Princeton University 2 Walt Disney Feature Animation (a) Flat colors (b) Complex texture Figure 1: A frame of cel animation with the foreground character painted by (a) the conventional method, and (b) our system. Abstract 1 INTRODUCTION We present a method for applying complex textures to hand-drawn In traditional cel animation, moving characters are illustrated with characters in cel animation. The method correlates features in a flat, constant colors, whereas background scenery is painted in simple, textured, 3-D model with features on a hand-drawn figure, subtle and exquisite detail (Figure 1a). This disparity in render- and then distorts the model to conform to the hand-drawn artwork. ing quality may be desirable to distinguish the animated characters The process uses two new algorithms: a silhouette detection scheme from the background; however, there are many figures for which and a depth-preserving warp. The silhouette detection algorithm is complex textures would be advantageous. Unfortunately, there are simple and efficient, and it produces continuous, smooth, visible two factors that prohibit animators from painting moving charac- contours on a 3-D model. The warp distorts the model in only two ters with detailed textures. First, moving characters are drawn dif- dimensions to match the artwork from a given camera perspective, ferently from frame to frame, requiring any complex shading to yet preserves 3-D effects such as self-occlusion and foreshortening. be replicated for every frame, adapting to the movements of the The entire process allows animators to combine complex textures characters—an extremely daunting task. -

Guide to Digital Art Specifications
Guide to Digital Art Specifications Version 12.05.11 Image File Types Digital image formats for both Mac and PC platforms are accepted. Preferred file types: These file types work best and typically encounter few problems. tif (TIFF) jpg (JPEG) psd (Adobe Photoshop document) eps (Encapsulated PostScript) ai (Adobe Illustrator) pdf (Portable Document Format) Accepted file types: These file types are acceptable, although application versions and operating systems can introduce problems. A hardcopy, for cross-referencing, will ensure a more accurate outcome. doc, docx (Word) xls, xlsx (Excel) ppt, pptx (PowerPoint) fh (Freehand) cdr (Corel Draw) cvs (Canvas) Image sizing specifications should be discussed with the Editorial Office prior to digital file submission. Digital images should be submitted in the final size desired. White space around the image should be removed. Image Resolution The minimum acceptable resolution is 200 dpi at the desired final size in the paged article. To ensure the highest-quality published image, follow these optimum resolutions: • Line = 1200 dpi. Contains only black and white; no shades of gray. These images are typically ink drawings or charts. Other common terms used are monochrome or 1-bit. • Grayscale or Color = 300 dpi. Contains no text. A photograph or a painting is an example of this type of image. • Combination = 600 dpi. Grayscale or color image combined with a line image. An example is a photograph with letter labels, arrows, or text added outside the image area. Anytime a picture is combined with type outside the image area, the resolution must be high enough to maintain smooth, readable text. -

Learning to Shadow Hand-Drawn Sketches
Learning to Shadow Hand-drawn Sketches Qingyuan Zheng∗1, Zhuoru Li∗2, and Adam Bargteil1 1University of Maryland, Baltimore County 2Project HAT fqing3, [email protected], [email protected] Abstract We present a fully automatic method to generate detailed and accurate artistic shadows from pairs of line drawing sketches and lighting directions. We also contribute a new dataset of one thousand examples of pairs of line draw- ings and shadows that are tagged with lighting directions. Remarkably, the generated shadows quickly communicate the underlying 3D structure of the sketched scene. Con- sequently, the shadows generated by our approach can be used directly or as an excellent starting point for artists. We demonstrate that the deep learning network we propose takes a hand-drawn sketch, builds a 3D model in latent space, and renders the resulting shadows. The generated shadows respect the hand-drawn lines and underlying 3D space and contain sophisticated and accurate details, such Figure 1: Top: our shadowing system takes in a line drawing and as self-shadowing effects. Moreover, the generated shadows a lighting direction label, and outputs the shadow. Bottom: our contain artistic effects, such as rim lighting or halos ap- training set includes triplets of hand-drawn sketches, shadows, and pearing from back lighting, that would be achievable with lighting directions. Pairs of sketches and shadow images are taken traditional 3D rendering methods. from artists’ websites and manually tagged with lighting directions with the help of professional artists. The cube shows how we de- note the 26 lighting directions (see Section 3.1). c Toshi, Clement 1. -

Sleek Illustration That Fades from Line Art to Color
Sleek Illustration that Fades from Line Art to Color In this tutorial, you will work with a few images you chose and you will create a nice looking illustration. The idea behind this illustration was to create a war between reality and line art. Video Tutorial Our video editor Gavin Steele has created this series of video tutorials to compliment this line art + image tutorial. Step 1 First create a new document that is 1100 pixels wide by 1500 pixels high at a resolution of 300 pixels per inch. For this project I will use a texture that I like very much. I would like to thank the author of this texture Princess-of-Shadows for putting this together. Now, move the texture into your document. Step 2 Next you need to select the images you will use for this design. I bought three nice images that you might be familiar with 1, 2, 3. Let’s start with image 1, and using the Pen Tool (P) you need to create a path around the dancer. Step 3 Now that you finished creating the path you need to set your brush size to 1px and Hardness at 100%. Next create a new layer and name it "contour1." Next, using the Pen Tool (P) right-click then select Stroke Path, select the brush and make sure the Simulate Pressure is not selected. Also, you need to make the stroke black. Step 4 Now that you have created the stroke do not delete the path. Next you need to press Command + Enter to transform the path into a selection and then you need to press the Add Layer Mask button. -
Inking and Painting for Animation Old and New Methods of Coloring Animation by Prof
D’source 1 Digital Learning Environment for Design - www.dsource.in Design Course Inking and Painting for Animation Old and new methods of Coloring Animation by Prof. Phani Tetali and Geetanjali Barthwal IDC, IIT Bombay Source: http://www.dsource.in/course/inking-and-painting-an- imation 1. About 2. Traditional Ink and Paint 3. Digital Ink and Paint 4. Exercise 5. Traditional and Digital Process 6. Links and References 7. Video 8. Contact Details D’source 2 Digital Learning Environment for Design - www.dsource.in Design Course About Inking and Painting for Animation created on paper is referred as 2d animation. It is the flipping of paper frames that creates an illusion Animation of movement in the still drawings. Old and new methods of Coloring Animation by If we talk about the past, one of the very first animations of this method is Blackton’s animation called as “Hu- Prof. Phani Tetali and Geetanjali Barthwal morous Phases of Funny Faces” and Winsor McCay’s “Gertie -the Dinosaur” . It was in early twenties when tra- IDC, IIT Bombay ditional animation techniques were developed and more sophisticated cartoons were produced. Walt Disney is called as a pioneer of hand drawn animation method. Links: • www.youtube.com/watch?v=bJuD4AlLINU Source: http://www.dsource.in/course/inking-and-painting-an- The simplest examples of animated drawings are the flipbooks, which gives illusion of movement. imation/about Here, the animator is creating 2d animation by referring the movement and repeatedly flipping the frames. He is taking help of the light box to make the paper base semi-transparent for animating the drawings. -

Rendering 3D Graphics As an Aid to Stylized Line Drawings in Perspective
Original scientific paper http://doi.org/10.24867/JGED-2016-2-005 rendering 3d graphics as an aid to stylized line drawings in perspective ABSTRACT The aim of the research was to study the issue of drawing 2D objects Mark Arandjus, and environments in perspective and attempted to ease the process of Helena Gabrijelčič Tomc drawing them with the aid of three-dimensional computer graphics. The goal of the research was to develop the method, which would exclude the need to trace three-dimensional models, which many digital artists use University of Ljubljana, as a guide when making drawings. The need to trace has been eliminat- Faculty of Natural Sciences and ed by finding a procedure to render three-dimensional models to appear Engineering, Ljubljana, Slovenia drawn – to appear drawn by an artist who has a stylized line style. After researching various techniques of rendering, Sketchup was used to make Corresponding author: and apply a Sketchup style which emulated a line style. After that, various Helena Gabrijelčič Tomc tests were performed using computer measurements and questionnaires e-mail: to determine if the observers could distinguish between three-dimen- [email protected] sional renders and two-dimensional drawings. The results have shown that very few participants notice three-dimensional graphics rendered with Sketchup. Even among the few observers who did notice the pres- First recieved: 24.12.2015. ence of three-dimensional models, none detected even half. The results Accepted: 26.10.2016. confirmed the adequateness of the methodology, which enables a more correct creation of element in perspective and convinces the observ- ers that the entire image is stylistically uniform hand drawn image. -

A Procedural Approach to Style for NPR Line Drawing from 3D Models
INSTITUT NATIONAL DE RECHERCHE EN INFORMATIQUE ET EN AUTOMATIQUE A Procedural Approach to Style for NPR Line Drawing from 3D models Stéphane Grabli — Frédo Durand — Emmanuel Turquin — François Sillion N° 4724 Février 2003 THÈME 3 apport de recherche ISSN 0249-6399 A Procedural Approach to Style for NPR Line Drawing from 3D models Stéphane Grabli £ , Frédo Durand†, Emmanuel Turquin‡ , François Sillion§ Thème 3 — Interaction homme-machine, images, données, connaissances Projets ARTIS et MIT Graphics Group Rapport de recherche n° 4724 — Février 2003 — 25 pages Abstract: This paper introduces a procedural approach to non-photorealistic line drawing from 3D models. The approach is inspired both by procedural shaders in classical rendering and by the power of procedural modeling. We propose a new image creation model where all operations are controlled procedurally. A view map describing all relevant support lines in the drawing is first created from the 3d model; a number of style modules operate on this map, by procedurally selecting and chaining lines before creating strokes and assigning drawing attributes. Two different levels of user control are provided, ranging from a low-level programming API to a parameterized building-block assembly mechanism. The resulting drawing system allows very flexible control of all elements of drawing style: first, different style modules can be applied to different types of lines in a view; second, stroke attributes are assigned procedurally and can be correlated at will with various scene or view properties. -

Pixelating Vector Line Art
Pixelating Vector Line Art Tiffany C. Inglis (Advisor: Craig S. Kaplan) University of Waterloo Abstract Rasterization is a widely studied problem that forms part of the foundation of computer graphics. Numerous algorithms have been Pixel artists rasterize vector paths by hand to minimize artifacts at developed in the past few decades, with an emphasis of improving low resolutions and emphasize the aesthetics of visible pixels. We efficiency. All these rasterization algorithms assume pixels to be describe Superpixelator, an algorithm that automates this process small enough to produce a continuous signal that can be processed by rasterizing vector line art in a low-resolution pixel art style. Our seamlessly by the human visual system. However, the assumption method successfully eliminates most rasterization artifacts in order that pixels are infinitesimal is not true and often we encounter lim- to draw smoother curves, and an optimization-based approach is itations on the pixel level. In typography, for example, fonts are used to preserve various path properties. A user study compares frequently rendered as pixel-thin paths. Na¨ıvely applying rasteri- our algorithm to commercial software and human subjects for its zation to font outlines will introduce various artifacts, drastically ability to rasterize effectively at low resolutions. A professional reducing readability (compare the text renderings in Figure2). pixel artist reports our results as on par with hand-drawn pixel art. Pixel art is another area in which pixel placement is extremely im- 1 Problem and Motivation portant and current rasterization algorithms cannot replace human effort adequately (see the image comparison in Figure2). Pixel art Digital images are represented in one of two ways: as raster graph- is a style of digital art created and edited on the pixel level. -

The Joy of Storytelling: Incorporating Classic Art Styles with Visual Storytelling Techniques ______
Running head: THE JOY OF STORYTELLING: INCORPORATING CLASSIC ART 1 THE JOY OF STORYTELLING: INCORPORATING CLASSIC ART STYLES WITH VISUAL STORYTELLING TECHNIQUES ____________________________________ A Thesis Presented to The Honors Tutorial College Ohio University _______________________________________ In Partial Fulfillment of the Requirements for Graduation from the Honors Tutorial College with the degree of Bachelor of Science of Communication Studies, Media Arts and Studies ______________________________________ by Maia Hamilton August 2019 THE JOY OF STORYTELLING: INCORPORATING CLASSIC ART 2 THE JOY OF STORYTELLING: INCORPORATING CLASSIC ART 3 Abstract The purpose of this paper is to understand the influences of art style in the development of animated film. By observing animated films with period settings, we can draw comparisons between their art direction and the art styles of their time. By understanding the historical era and its culture, a creator can then begin to build a world that uses these elements as inspiration. For my animated short film, I use the history and culture of 19th century Paris to illustrate the story. By using influences of period artists such as Degas, Toulouse-Lautrec, and Pissarro I must understand their techniques and incorporate their stylistic choices into the film using visual storytelling techniques. Keywords: traditional animation, 2d animation, modern animation, narratives, storytelling, visual storytelling, storytelling techniques, THE JOY OF STORYTELLING: INCORPORATING CLASSIC ART 4 Introduction - Showing Without Saying “People are storytellers - they tell narratives about their experiences and the meanings that these experiences have for their lives.” - Julia Chaitin, Narratives and Story-Telling, 2003 Storytelling is an integral part of humanity. It is an essential part of all cultures, and it has instilled values and desires into people throughout history. -
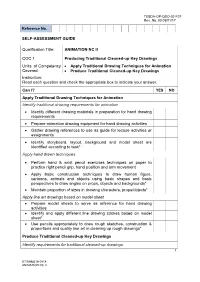
ANIMATION NC II COC 1 Producing Traditional Cleaned-Up Key
TESDA-OP-QSO-02-F07 Rev. No. 00 03/01/17 Reference No. SELF-ASSESSMENT GUIDE Qualification Title: ANIMATION NC II COC 1 Producing Traditional Cleaned-up Key Drawings Units of Competency Apply Traditional Drawing Techniques for Animation Covered Produce Traditional Cleaned-up Key Drawings Instruction: Read each question and check the appropriate box to indicate your answer. Can I? YES NO Apply Traditional Drawing Techniques for Animation Identify traditional drawing requirements for animation Identify different drawing materials in preparation for hand drawing requirements Prepare animation drawing equipment for hand drawing activities Gather drawing references to use as guide for lecture activities or assignments Identify storyboard, layout, background and model sheet are identified according to task* Apply hand drawn techniques Perform hand & wrist pencil exercises techniques on paper to practice right pencil grip, hand position and arm movement Apply basic construction techniques to draw human figure, cartoons, animals and objects using basic shapes and basic perspectives to draw angles on props, objects and backgrounds* Maintain proportion of sizes in drawing characters, props/objects* Apply line art drawings based on model sheet Prepare model sheets to serve as reference for hand drawing activities Identify and apply different line drawing strokes based on model sheet* Use pencils appropriately to draw rough sketches, construction & proportions and quality line art in cleaning up rough drawings* Produce Traditional Cleaned-up -

Optimizing 2D Animation Production Time in Creating Traditional Watercolor Looks by Integrating Traditional and Digital Media
Received December 1, 2017; Accepted March 11, 2017 Purwaningsih, Dominika Anggraeni Faculty of Art and Design Optimizing 2D Animation Production Multimedia Nusantara University [email protected] Time in Creating Traditional 2nd Author (*if applicable) Watercolor Looks by Integrating Affiliation E-mail address Traditional and Digital Media e.g. Obama, Barack H. Using traditional watercolor for backgrounds in digital 2D animation *** University AbstrAbstractact Sed2D dapibus,animation libero is laborious. id eleifend Each viverra, frame massahas to magnabe drawn malesuada individual mi,ly, vel be it faucibustraditional massa or paperless/ velit sit amet digital ante. animation Aenean. placeratHowever, convallis 2D animation bibendum. keeps Nunc auguereinventing metus, itself auctor. With sit amet current gravida technology ut, ultrices in digital a neque. 2D animaFusce tion,non nibhwe’re eu turpisoffered faucibus the opportunity posuere utto idmake felis. hand Phasellus-drawn condimentum animation in adui way eget that arcu we euismodcouldn’t aliquam.even imagine Etiam fifteen aliquam years lobortis ago with lectus smaller sed pellentesque. team and lower Donec sed conguebudget. sapien. However Lorem we can’t ipsum deny dolor that sit traditional amet, consectetur 2D animation adipiscing has its elit. own Sed inappeal massa which dolor, makes quis lacinia 2D animation nibh. Vivamus. more precious and memorable. That being said, each traditional and digital 2D animation has its own strengths. In this paper, I’m going to combine digital and traditional 2D animation techniques to produce a short animated movie according to their Keywords:strengths in vorderisual tostyle, optimize background the production, 2D animation, time in mix2D animationmedia pipeline. Traditional media that is used in this research is watercolor.