AMD Ryzen Processor Software Optimization
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Titan X Amd 1.2 V4 Ig 20210319
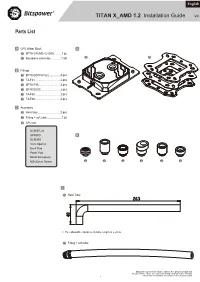
English TITAN X_AMD 1.2 Installation Guide V4 Parts List A CPU Water Block A A-1 BPTA-CPUMS-V2-SKA ..........1 pc A-1 A-2 A-2 Backplane assembly ..............1 set B Fittings B-1 BPTA-DOTFH1622 ...............4 pcs B-2 TA-F61 ...................................2 pcs B-3 BPTA-F95 ..............................2 pcs B-4 BP-RIGOS5 ...........................2 pcs B-5 TA-F60 ..................................2 pcs B-6 TA-F40 ..................................2 pcs C Accessory C-1 Hard tube ..............................2 pcs C-2 Fitting + soft tube ....................1 pc C-3 CPU set SCM3FL20 SPRING B SCM3F6 1mm Spacer Back Pad Paste Pad Metal Backplane M3x32mm Screw B-1 B-2 B-3 B-4 B-5 B-6 C C-1 Hard Tube ※ The allowable variance in tube length is ± 2mm C-2 Fitting + soft tube Bitspower reserves the right to change the product design and interpretations. These are subject to change without notice. Product colors and accessories are based on the actual product. — 1 — I. AMD Motherboard system 54 AMD SOCKET 939 / 754 / 940 IN 48 AMD SOCKET AM4 AMD SOCKET AM3 / AM3+ AMD SOCKET AM2 / AM2+ AMD SOCKET FM1 / FM2+ Bitspower Fan and DRGB RF Remote Controller Hub (Not included) are now available at microcenter.com DRGB PIN on Motherboard or other equipment. 96 90 BPTA-RFCHUB The CPU water block has a DRGB cable, which AMD SOCKET AM4 AMD SOCKET AM3 AM3+ / AMD SOCKET AM2 AM2+ / AMD SOCKET FM1 / FM2+ can be connected to the DRGB extension cable of the radiator fans. Fan and DRGB RF Remote Motherboard Controller Hub (Not included) OUT DRGB LED Do not over-tighten the thumb screws Installation (SCM3FL20). -

Effective Virtual CPU Configuration with QEMU and Libvirt
Effective Virtual CPU Configuration with QEMU and libvirt Kashyap Chamarthy <[email protected]> Open Source Summit Edinburgh, 2018 1 / 38 Timeline of recent CPU flaws, 2018 (a) Jan 03 • Spectre v1: Bounds Check Bypass Jan 03 • Spectre v2: Branch Target Injection Jan 03 • Meltdown: Rogue Data Cache Load May 21 • Spectre-NG: Speculative Store Bypass Jun 21 • TLBleed: Side-channel attack over shared TLBs 2 / 38 Timeline of recent CPU flaws, 2018 (b) Jun 29 • NetSpectre: Side-channel attack over local network Jul 10 • Spectre-NG: Bounds Check Bypass Store Aug 14 • L1TF: "L1 Terminal Fault" ... • ? 3 / 38 Related talks in the ‘References’ section Out of scope: Internals of various side-channel attacks How to exploit Meltdown & Spectre variants Details of performance implications What this talk is not about 4 / 38 Related talks in the ‘References’ section What this talk is not about Out of scope: Internals of various side-channel attacks How to exploit Meltdown & Spectre variants Details of performance implications 4 / 38 What this talk is not about Out of scope: Internals of various side-channel attacks How to exploit Meltdown & Spectre variants Details of performance implications Related talks in the ‘References’ section 4 / 38 OpenStack, et al. libguestfs Virt Driver (guestfish) libvirtd QMP QMP QEMU QEMU VM1 VM2 Custom Disk1 Disk2 Appliance ioctl() KVM-based virtualization components Linux with KVM 5 / 38 OpenStack, et al. libguestfs Virt Driver (guestfish) libvirtd QMP QMP Custom Appliance KVM-based virtualization components QEMU QEMU VM1 VM2 Disk1 Disk2 ioctl() Linux with KVM 5 / 38 OpenStack, et al. libguestfs Virt Driver (guestfish) Custom Appliance KVM-based virtualization components libvirtd QMP QMP QEMU QEMU VM1 VM2 Disk1 Disk2 ioctl() Linux with KVM 5 / 38 libguestfs (guestfish) Custom Appliance KVM-based virtualization components OpenStack, et al. -

Real-Time Finite Element Method (FEM) and Tressfx
REAL-TIME FEM AND TRESSFX 4 ERIC LARSEN KARL HILLESLAND 1 FEBRUARY 2016 | CONFIDENTIAL FINITE ELEMENT METHOD (FEM) SIMULATION Simulates soft to nearly-rigid objects, with fracture Models object as mesh of tetrahedral elements Each element has material parameters: ‒ Young’s Modulus: How stiff the material is ‒ Poisson’s ratio: Effect of deformation on volume ‒ Yield strength: Deformation limit before permanent shape change ‒ Fracture strength: Stress limit before the material breaks 2 FEBRUARY 2016 | CONFIDENTIAL MOTIVATIONS FOR THIS METHOD Parameters give a lot of design control Can model many real-world materials ‒Rubber, metal, glass, wood, animal tissue Commonly used now for film effects ‒High-quality destruction Successful real-time use in Star Wars: The Force Unleashed 1 & 2 ‒DMM middleware [Parker and O’Brien] 3 FEBRUARY 2016 | CONFIDENTIAL OUR PROJECT New implementation of real-time FEM for games Planned CPU library release ‒Heavy use of multithreading ‒Open-source with GPUOpen license Some highlights ‒Practical method for continuous collision detection (CCD) ‒Mix of CCD and intersection contact constraints ‒Efficient integrals for intersection constraint 4 FEBRUARY 2016 | CONFIDENTIAL STATUS Proof-of-concept prototype First pass at optimization Offering an early look for feedback Several generic components 5 FEBRUARY 2016 | CONFIDENTIAL CCD Find time of impact between moving objects ‒Impulses can prevent intersections [Otaduy et al.] ‒Catches collisions with fast-moving objects Our approach ‒Conservative-advancement based ‒Geometric -

AMD's Llano Fusion
AMD’S “LLANO” FUSION APU Denis Foley, Maurice Steinman, Alex Branover, Greg Smaus, Antonio Asaro, Swamy Punyamurtula, Ljubisa Bajic Hot Chips 23, 19th August 2011 TODAY’S TOPICS . APU Architecture and floorplan . CPU Core Features . Graphics Features . Unified Video decoder Features . Display and I/O Capabilities . Power Gating . Turbo Core . Performance 2 | LLANO HOT CHIPS | August 19th, 2011 ARCHITECTURE AND FLOORPLAN A-SERIES ARCHITECTURE • Up to 4 Stars-32nm x86 Cores • 1MB L2 cache/core • Integrated Northbridge • 2 Chan of DDR3-1866 memory • 24 Lanes of PCIe® Gen2 • x4 UMI (Unified Media Interface) • x4 GPP (General Purpose Ports) • x16 Graphics expansion or display • 2 x4 Lanes dedicated display • 2 Head Display Controller • UVD (Unified Video Decoder) • 400 AMD Radeon™ Compute Units • GMC (Graphics Memory Controller) • FCL (Fusion Control Link) • RMB (AMD Radeon™ Memory Bus) • 227mm2, 32nm SOI • 1.45BN transistors 4 | LLANO HOT CHIPS | August 19th, 2011 INTERNAL BUS . Fusion Control Link (FCL) – 128b (each direction) path for IO access to memory – Variable clock based on throughput (LCLK) – GPU access to coherent memory space – CPU access to dedicated GPU framebuffer . AMD Radeon™ Memory Bus (RMB) – 256b (each direction) for each channel for GMC access to memory – Runs on Northbridge clock (NCLK) – Provides full bandwidth path for Graphics access to system memory – DRAM friendly stream of reads and write – Bypasses coherency mechanism 5 | LLANO HOT CHIPS | August 19th, 2011 Dual-channel DDR3 Unified Video DDR3 UVD Decoder NB CPU CPU Graphics SIMD Integrated Integrated GPU, Display Northbridge Array Controller I/O Controllers L2 Display L2 I/OMultimedia Controllers L2 PCI Express I/O - 24 lanes, optional 1 MB L2 cache L2 I/O per core digital display interfaces CPU CPU Digital display interfaces 4 Stars-32nm PCIe CPU cores PPL Display PCIe PCIe Display 6 | LLANO HOT CHIPS | August 19th, 2011 CPU, GPU, UVD AND IO FEATURES STARS-32nm CPU CORE FEATURES . -

AMD Powerpoint- White Template
RDNA Architecture Forward-looking statement This presentation contains forward-looking statements concerning Advanced Micro Devices, Inc. (AMD) including, but not limited to, the features, functionality, performance, availability, timing, pricing, expectations and expected benefits of AMD’s current and future products, which are made pursuant to the Safe Harbor provisions of the Private Securities Litigation Reform Act of 1995. Forward-looking statements are commonly identified by words such as "would," "may," "expects," "believes," "plans," "intends," "projects" and other terms with similar meaning. Investors are cautioned that the forward-looking statements in this presentation are based on current beliefs, assumptions and expectations, speak only as of the date of this presentation and involve risks and uncertainties that could cause actual results to differ materially from current expectations. Such statements are subject to certain known and unknown risks and uncertainties, many of which are difficult to predict and generally beyond AMD's control, that could cause actual results and other future events to differ materially from those expressed in, or implied or projected by, the forward-looking information and statements. Investors are urged to review in detail the risks and uncertainties in AMD's Securities and Exchange Commission filings, including but not limited to AMD's Quarterly Report on Form 10-Q for the quarter ended March 30, 2019 2 Highlights of the RDNA Workgroup Processor (WGP) ▪ Designed for lower latency and higher -

AMD Accelerated Parallel Processing Opencl Programming Guide
AMD Accelerated Parallel Processing OpenCL Programming Guide November 2013 rev2.7 © 2013 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, AMD Accelerated Parallel Processing, the AMD Accelerated Parallel Processing logo, ATI, the ATI logo, Radeon, FireStream, FirePro, Catalyst, and combinations thereof are trade- marks of Advanced Micro Devices, Inc. Microsoft, Visual Studio, Windows, and Windows Vista are registered trademarks of Microsoft Corporation in the U.S. and/or other jurisdic- tions. Other names are for informational purposes only and may be trademarks of their respective owners. OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. The information contained herein may be of a preliminary or advance nature and is subject to change without notice. No license, whether express, implied, arising by estoppel or other- wise, to any intellectual property rights is granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as compo- nents in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other application in which the failure of AMD’s product could create a situation where personal injury, death, or severe property or envi- ronmental damage may occur. -

AMD EPYC™ 7371 Processors Accelerating HPC Innovation
AMD EPYC™ 7371 Processors Solution Brief Accelerating HPC Innovation March, 2019 AMD EPYC 7371 processors (16 core, 3.1GHz): Exceptional Memory Bandwidth AMD EPYC server processors deliver 8 channels of memory with support for up The right choice for HPC to 2TB of memory per processor. Designed from the ground up for a new generation of solutions, AMD EPYC™ 7371 processors (16 core, 3.1GHz) implement a philosophy of Standards Based AMD is committed to industry standards, choice without compromise. The AMD EPYC 7371 processor delivers offering you a choice in x86 processors outstanding frequency for applications sensitive to per-core with design innovations that target the performance such as those licensed on a per-core basis. evolving needs of modern datacenters. No Compromise Product Line Compute requirements are increasing, datacenter space is not. AMD EPYC server processors offer up to 32 cores and a consistent feature set across all processor models. Power HPC Workloads Tackle HPC workloads with leading performance and expandability. AMD EPYC 7371 processors are an excellent option when license costs Accelerate your workloads with up to dominate the overall solution cost. In these scenarios the performance- 33% more PCI Express® Gen 3 lanes. per-dollar of the overall solution is usually best with a CPU that can Optimize Productivity provide excellent per-core performance. Increase productivity with tools, resources, and communities to help you “code faster, faster code.” Boost AMD EPYC processors’ innovative architecture translates to tremendous application performance with Software performance. More importantly, the performance you’re paying for can Optimization Guides and Performance be matched to the appropriate to the performance you need. -

Passmark Intel Vs AMD CPU Benchmarks - High End
PassMark Intel vs AMD CPU Benchmarks - High End http://www.cpubenchmark.net/high_end_cpus.html Shopping cart | Search Home Software Hardware Benchmarks Services Store Support Forums About Us Home » CPU Benchmarks » High End CPU's CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android iOS / iPhone CPU Benchmarks Over 600,000 CPUs Benchmarked High End CPU's - Intel vs AMD How does your CPU compare? This chart comparing high end CPU's is made using thousands of PerformanceTest benchmark Add your CPU to our benchmark results and is updated daily. These are the high end AMD and Intel CPUs are typically those chart with PerformanceTest V8 found in newer computers. The chart below compares the performance of Intel Xeon CPUs, Intel Core i7 CPUs, AMD Phenom II CPUs and AMD Opterons with multiple cores. Intel processors vs ---- Select A Page ---- AMD chips - find out which CPU's performance is best for your new gaming rig or server! CPU Mark | Price Performance (Click to select desired chart) PassMark - CPU Mark High End CPUs - Updated 26th of August 2013 Price (USD) Intel Xeon E5-2687W @ 3.10GHz 14,564 $1,929.99 Intel Xeon E5-2690 @ 2.90GHz 14,511 $1,920.99 Intel Xeon E5-2680 @ 2.70GHz 13,949 $1,725.99 Intel Xeon E5-2689 @ 2.60GHz 13,444 NA Intel Xeon E5-2670 @ 2.60GHz 13,312 $1,509.00 Intel Core i7-3970X @ 3.50GHz 12,873 $1,006.99 Intel Core i7-3960X @ 3.30GHz 12,749 $965.99 Intel Xeon E5-1660 @ 3.30GHz 12,457 $1,086.99 Intel Xeon E5-2665 @ 2.40GHz 12,453 $1,499.99 Intel Core i7-3930K @ 3.20GHz 12,086 $567.27 Intel Xeon -

Vorbereitung Auf Comptia A+
Markus Kammermann, Ramon Kratzer CompTIA A+ Systemtechnik und Support von A bis Z Vorbereitung auf die Prüfungen 220-901 und 220-902 Bibliografische Information der Deutschen Nationalbibliothek Die Deutsche Nationalbibliothek verzeichnet diese Publikation in der Deutschen Nationalbibliografie; detaillierte bibliografische Daten sind im Internet über <http://dnb.d-nb.de> abrufbar. ISBN 978-3-95845-466-8 4. Auflage 2016 www.mitp.de E-Mail: [email protected] Telefon: +49 7953 / 7189 – 079 Telefax: +49 7953 / 7189 – 082 © 2016 mitp Verlags GmbH & Co. KG Dieses Werk, einschließlich aller seiner Teile, ist urheberrechtlich geschützt. Jede Verwertung außerhalb der engen Grenzen des Urheberrechtsgesetzes ist ohne Zustimmung des Verlages unzulässig und straf- bar. Dies gilt insbesondere für Vervielfältigungen, Übersetzungen, Mikroverfilmungen und die Einspei- cherung und Verarbeitung in elektronischen Systemen. Die Wiedergabe von Gebrauchsnamen, Handelsnamen, Warenbezeichnungen usw. in diesem Werk berechtigt auch ohne besondere Kennzeichnung nicht zu der Annahme, dass solche Namen im Sinne der Warenzeichen- und Markenschutz-Gesetzgebung als frei zu betrachten wären und daher von jedermann benutzt werden dürften. Dieses Lehrmittel wurde für das CompTIA Authorized Curriculum durch ProCert Labs geprüft und ist CAQC-zertifiziert. Weitere Informationen zu dieser Qualifizierung erhalten Sie unter www.comptia.org/ certification/caqc/ sowie unter der Adresse www.procertlabs.com Das Bildmaterial in diesem Buch, soweit es nicht von uns selber erstellt -

Comparison of Technologies for General-Purpose Computing on Graphics Processing Units
Master of Science Thesis in Information Coding Department of Electrical Engineering, Linköping University, 2016 Comparison of Technologies for General-Purpose Computing on Graphics Processing Units Torbjörn Sörman Master of Science Thesis in Information Coding Comparison of Technologies for General-Purpose Computing on Graphics Processing Units Torbjörn Sörman LiTH-ISY-EX–16/4923–SE Supervisor: Robert Forchheimer isy, Linköpings universitet Åsa Detterfelt MindRoad AB Examiner: Ingemar Ragnemalm isy, Linköpings universitet Organisatorisk avdelning Department of Electrical Engineering Linköping University SE-581 83 Linköping, Sweden Copyright © 2016 Torbjörn Sörman Abstract The computational capacity of graphics cards for general-purpose computing have progressed fast over the last decade. A major reason is computational heavy computer games, where standard of performance and high quality graphics con- stantly rise. Another reason is better suitable technologies for programming the graphics cards. Combined, the product is high raw performance devices and means to access that performance. This thesis investigates some of the current technologies for general-purpose computing on graphics processing units. Tech- nologies are primarily compared by means of benchmarking performance and secondarily by factors concerning programming and implementation. The choice of technology can have a large impact on performance. The benchmark applica- tion found the difference in execution time of the fastest technology, CUDA, com- pared to the slowest, OpenCL, to be twice a factor of two. The benchmark applica- tion also found out that the older technologies, OpenGL and DirectX, are compet- itive with CUDA and OpenCL in terms of resulting raw performance. iii Acknowledgments I would like to thank Åsa Detterfelt for the opportunity to make this thesis work at MindRoad AB. -

Evaluation of AMD EPYC
Evaluation of AMD EPYC Chris Hollowell <[email protected]> HEPiX Fall 2018, PIC Spain What is EPYC? EPYC is a new line of x86_64 server CPUs from AMD based on their Zen microarchitecture Same microarchitecture used in their Ryzen desktop processors Released June 2017 First new high performance series of server CPUs offered by AMD since 2012 Last were Piledriver-based Opterons Steamroller Opteron products cancelled AMD had focused on low power server CPUs instead x86_64 Jaguar APUs ARM-based Opteron A CPUs Many vendors are now offering EPYC-based servers, including Dell, HP and Supermicro 2 How Does EPYC Differ From Skylake-SP? Intel’s Skylake-SP Xeon x86_64 server CPU line also released in 2017 Both Skylake-SP and EPYC CPU dies manufactured using 14 nm process Skylake-SP introduced AVX512 vector instruction support in Xeon AVX512 not available in EPYC HS06 official GCC compilation options exclude autovectorization Stock SL6/7 GCC doesn’t support AVX512 Support added in GCC 4.9+ Not heavily used (yet) in HEP/NP offline computing Both have models supporting 2666 MHz DDR4 memory Skylake-SP 6 memory channels per processor 3 TB (2-socket system, extended memory models) EPYC 8 memory channels per processor 4 TB (2-socket system) 3 How Does EPYC Differ From Skylake (Cont)? Some Skylake-SP processors include built in Omnipath networking, or FPGA coprocessors Not available in EPYC Both Skylake-SP and EPYC have SMT (HT) support 2 logical cores per physical core (absent in some Xeon Bronze models) Maximum core count (per socket) Skylake-SP – 28 physical / 56 logical (Xeon Platinum 8180M) EPYC – 32 physical / 64 logical (EPYC 7601) Maximum socket count Skylake-SP – 8 (Xeon Platinum) EPYC – 2 Processor Inteconnect Skylake-SP – UltraPath Interconnect (UPI) EYPC – Infinity Fabric (IF) PCIe lanes (2-socket system) Skylake-SP – 96 EPYC – 128 (some used by SoC functionality) Same number available in single socket configuration 4 EPYC: MCM/SoC Design EPYC utilizes an SoC design Many functions normally found in motherboard chipset on the CPU SATA controllers USB controllers etc. -

Mairjason2015phd.Pdf (1.650Mb)
Power Modelling in Multicore Computing Jason Mair a thesis submitted for the degree of Doctor of Philosophy at the University of Otago, Dunedin, New Zealand. 2015 Abstract Power consumption has long been a concern for portable consumer electron- ics, but has recently become an increasing concern for larger, power-hungry systems such as servers and clusters. This concern has arisen from the asso- ciated financial cost and environmental impact, where the cost of powering and cooling a large-scale system deployment can be on the order of mil- lions of dollars a year. Such a substantial power consumption additionally contributes significant levels of greenhouse gas emissions. Therefore, software-based power management policies have been used to more effectively manage a system’s power consumption. However, man- aging power consumption requires fine-grained power values for evaluating the run-time tradeoff between power and performance. Despite hardware power meters providing a convenient and accurate source of power val- ues, they are incapable of providing the fine-grained, per-application power measurements required in power management. To meet this challenge, this thesis proposes a novel power modelling method called W-Classifier. In this method, a parameterised micro-benchmark is designed to reproduce a selection of representative, synthetic workloads for quantifying the relationship between key performance events and the cor- responding power values. Using the micro-benchmark enables W-Classifier to be application independent, which is a novel feature of the method. To improve accuracy, W-Classifier uses run-time workload classification and derives a collection of workload-specific linear functions for power estima- tion, which is another novel feature for power modelling.