A Probabilistic Approach for Automated Discovery of Biomarkers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

University of California, San Diego
UNIVERSITY OF CALIFORNIA, SAN DIEGO The post-terminal differentiation fate of RNAs revealed by next-generation sequencing A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Biomedical Sciences by Gloria Kuo Lefkowitz Committee in Charge: Professor Benjamin D. Yu, Chair Professor Richard Gallo Professor Bruce A. Hamilton Professor Miles F. Wilkinson Professor Eugene Yeo 2012 Copyright Gloria Kuo Lefkowitz, 2012 All rights reserved. The Dissertation of Gloria Kuo Lefkowitz is approved, and it is acceptable in quality and form for publication on microfilm and electronically: __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ Chair University of California, San Diego 2012 iii DEDICATION Ma and Ba, for your early indulgence and support. Matt and James, for choosing more practical callings. Roy, my love, for patiently sharing the ups and downs of this journey. iv EPIGRAPH It is foolish to tear one's hair in grief, as though sorrow would be made less by baldness. ~Cicero v TABLE OF CONTENTS Signature Page .............................................................................................................. iii Dedication .................................................................................................................... -

POLR2L Antibody Cat
POLR2L Antibody Cat. No.: XW-7445 POLR2L Antibody Specifications HOST SPECIES: Chicken SPECIES REACTIVITY: Human, Mouse, Rat IMMUNOGEN: 1-67 TESTED APPLICATIONS: WB POLR2L antibody can be used for the detection of POLR2L by Western blot, may also work APPLICATIONS: for IHC and ICC. PREDICTED MOLECULAR 7.6 kDa (calculated) WEIGHT: Properties PURIFICATION: Antigen affinity-purified CLONALITY: Polyclonal CONJUGATE: Unconjugated PHYSICAL STATE: Liquid BUFFER: Phosphate-Buffered Saline. No preservatives added. CONCENTRATION: 1 mg/mL October 1, 2021 1 https://www.prosci-inc.com/polr2l-antibody-7445.html POLR2L antibody can be stored at 4˚C for short term (weeks). Long term storage should STORAGE CONDITIONS: be at -20˚C. As with all antibodies care should be taken to avoid repeated freeze thaw cycles. Antibodies should not be exposed to prolonged high temperatures. Additional Info OFFICIAL SYMBOL: POLR2L DNA-directed RNA polymerases I, II, and III subunit RPABC5, DNA-directed RNA ALTERNATE NAMES: polymerase III subunit L, RNA polymerases I, and III subunit ABC5, RBP10, RPB10, RPABC5, RPB7.6, hRPB7.6, RPB10beta, POLR2L ACCESSION NO.: NP_066951.1 PROTEIN GI NO.: 10863925 GENE ID: 5441 USER NOTE: Optimal dilutions for each application to be determined by the researcher. Background and References DNA directed RNA polymerase II polypeptide L; polymerase (RNA) II (DNA directed) polypeptide L (7.6kD); RNA polymerase II subunit. This protein is a subunit of RNA polymerase II, the polymerase responsible for synthesizing messenger RNA in eukaryotes. BACKGROUND: It contains four conserved cysteines characteristic of an atypical zinc-binding domain. Like its counterpart in yeast, this subunit may be shared by the other two DNA-directed RNA polymerases. -

DNA Methylation Changes in Down Syndrome Derived Neural Ipscs Uncover Co-Dysregulation of ZNF and HOX3 Families of Transcription
Laan et al. Clinical Epigenetics (2020) 12:9 https://doi.org/10.1186/s13148-019-0803-1 RESEARCH Open Access DNA methylation changes in Down syndrome derived neural iPSCs uncover co- dysregulation of ZNF and HOX3 families of transcription factors Loora Laan1†, Joakim Klar1†, Maria Sobol1, Jan Hoeber1, Mansoureh Shahsavani2, Malin Kele2, Ambrin Fatima1, Muhammad Zakaria1, Göran Annerén1, Anna Falk2, Jens Schuster1 and Niklas Dahl1* Abstract Background: Down syndrome (DS) is characterized by neurodevelopmental abnormalities caused by partial or complete trisomy of human chromosome 21 (T21). Analysis of Down syndrome brain specimens has shown global epigenetic and transcriptional changes but their interplay during early neurogenesis remains largely unknown. We differentiated induced pluripotent stem cells (iPSCs) established from two DS patients with complete T21 and matched euploid donors into two distinct neural stages corresponding to early- and mid-gestational ages. Results: Using the Illumina Infinium 450K array, we assessed the DNA methylation pattern of known CpG regions and promoters across the genome in trisomic neural iPSC derivatives, and we identified a total of 500 stably and differentially methylated CpGs that were annotated to CpG islands of 151 genes. The genes were enriched within the DNA binding category, uncovering 37 factors of importance for transcriptional regulation and chromatin structure. In particular, we observed regional epigenetic changes of the transcription factor genes ZNF69, ZNF700 and ZNF763 as well as the HOXA3, HOXB3 and HOXD3 genes. A similar clustering of differential methylation was found in the CpG islands of the HIST1 genes suggesting effects on chromatin remodeling. Conclusions: The study shows that early established differential methylation in neural iPSC derivatives with T21 are associated with a set of genes relevant for DS brain development, providing a novel framework for further studies on epigenetic changes and transcriptional dysregulation during T21 neurogenesis. -

Molecular Pharmacology of Cancer Therapy in Human Colorectal Cancer by Gene Expression Profiling1,2
[CANCER RESEARCH 63, 6855–6863, October 15, 2003] Molecular Pharmacology of Cancer Therapy in Human Colorectal Cancer by Gene Expression Profiling1,2 Paul A. Clarke,3 Mark L. George, Sandra Easdale, David Cunningham, R. Ian Swift, Mark E. Hill, Diana M. Tait, and Paul Workman Cancer Research UK Centre for Cancer Therapeutics, Institute of Cancer Research, Sutton, Surrey SM2 5NG [P. A. C., M. L. G., S. E., P. W.]; Department of Gastrointestinal Oncology, Royal Marsden Hospital, Sutton, Surrey [D. C., M. E. H., D. M. T.]; and Department of Surgery, Mayday Hospital, Croydon, Surrey [M. L. G., R. I. S.], United Kingdom ABSTRACT ment with a single dose of MMC4 and during a continuous infusion of 5FU. In this study, we report for the first time gene expression Global gene expression profiling has potential for elucidating the com- profiling in cancer patients before, and critically, during the period of plex cellular effects and mechanisms of action of novel targeted anticancer exposure to chemotherapy. We have demonstrated that the approach agents or existing chemotherapeutics for which the precise molecular is feasible, and we have detected a novel molecular response that mechanism of action may be unclear. In this study, decreased expression would not have been predicted from in vitro studies and that would of genes required for RNA and protein synthesis, and for metabolism were have otherwise been missed by conventional approaches. The results detected in rectal cancer biopsies taken from patients during a 5-fluorou- also suggest a possible new therapeutic approach. Overall our obser- racil infusion. Our observations demonstrate that this approach is feasible and can detect responses that may have otherwise been missed by con- vations suggest that gene expression profiling in response to treatment ventional methods. -
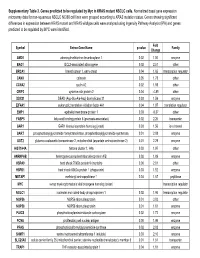
Supplementary Table 3. Genes Predicted to Be Regulated by Myc in KRAS Mutant NSCLC Cells
Supplementary Table 3. Genes predicted to be regulated by Myc in KRAS mutant NSCLC cells. Normalized basal gene expression microarray data for non-squamous NSCLC NCI60 cell lines were grouped according to KRAS mutation status. Genes showing significant differences in expression between KRAS mutant and KRAS wildtype cells were analyzed using Ingenuity Pathway Analysis (IPA) and genes predicted to be regulated by MYC were identified. Fold Symbol Entrez Gene Name p-value Family Change AMD1 adenosylmethionine decarboxylase 1 0.02 1.50 enzyme BAG1 BCL2-associated athanogene 0.02 2.57 other BRCA1 breast cancer 1, early onset 0.04 1.65 transcription regulator CANX calnexin 0.05 1.78 other CCNA2 cyclin A2 0.02 1.98 other CRIP2 cysteine-rich protein 2 0.04 -4.89 other DDX21 DEAD (Asp-Glu-Ala-Asp) box helicase 21 0.03 1.59 enzyme EIF4A1 eukaryotic translation initiation factor 4A1 0.04 1.87 translation regulator EMP1 epithelial membrane protein 1 0.03 -6.37 other FABP5 fatty acid binding protein 5 (psoriasis-associated) 0.02 2.26 transporter GAR1 GAR1 ribonucleoprotein homolog (yeast) 0.03 1.56 ion channel GART phosphoribosylglycinamide formyltransferase, phosphoribosylglycinamide synthetase, 0.01 2.08 enzyme GOT2 glutamic-oxaloacetic transaminase 2, mitochondrial (aspartate aminotransferase 2) 0.01 2.29 enzyme HIST1H4A histone cluster 1, H4a 0.03 1.97 other HNRNPAB heterogeneous nuclear ribonucleoprotein A/B 0.02 1.89 enzyme HSPA9 heat shock 70kDa protein 9 (mortalin) 0.00 2.01 other HSPD1 heat shock 60kDa protein 1 (chaperonin) 0.03 1.52 enzyme -

A Mutation in Histone H2B Represents a New Class of Oncogenic Driver
Author Manuscript Published OnlineFirst on July 23, 2019; DOI: 10.1158/2159-8290.CD-19-0393 Author manuscripts have been peer reviewed and accepted for publication but have not yet been edited. A Mutation in Histone H2B Represents A New Class Of Oncogenic Driver Richard L. Bennett1, Aditya Bele1, Eliza C. Small2, Christine M. Will2, Behnam Nabet3, Jon A. Oyer2, Xiaoxiao Huang1,9, Rajarshi P. Ghosh4, Adrian T. Grzybowski5, Tao Yu6, Qiao Zhang7, Alberto Riva8, Tanmay P. Lele7, George C. Schatz9, Neil L. Kelleher9 Alexander J. Ruthenburg5, Jan Liphardt4 and Jonathan D. Licht1 * 1 Division of Hematology/Oncology, University of Florida Health Cancer Center, Gainesville, FL 2 Division of Hematology/Oncology, Northwestern University 3 Department of Cancer Biology, Dana Farber Cancer Institute and Department of Biological Chemistry and Molecular Pharmacology, Harvard Medical School 4 Department of Bioengineering, Stanford University 5 Department of Molecular Genetics and Cell Biology, The University of Chicago 6 Department of Chemistry, Tennessee Technological University 7 Department of Chemical Engineering, University of Florida 8 Bioinformatics Core, Interdisciplinary Center for Biotechnology Research, University of Florida 9 Department of Chemistry, Northwestern University, Evanston IL 60208 Running title: Histone mutations in cancer *Corresponding Author: Jonathan D. Licht, MD The University of Florida Health Cancer Center Cancer and Genetics Research Complex, Suite 145 2033 Mowry Road Gainesville, FL 32610 352-273-8143 [email protected] Disclosures: The authors have no conflicts of interest to declare Downloaded from cancerdiscovery.aacrjournals.org on September 27, 2021. © 2019 American Association for Cancer Research. Author Manuscript Published OnlineFirst on July 23, 2019; DOI: 10.1158/2159-8290.CD-19-0393 Author manuscripts have been peer reviewed and accepted for publication but have not yet been edited. -

Human Recombinant Protein – TP760406
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for TP760406 H4C1 (NM_003538) Human Recombinant Protein Product data: Product Type: Recombinant Proteins Description: Purified recombinant protein of Human histone cluster 1, H4a (HIST1H4A), full length, with N- terminal HIS tag, expressed in E.Coli, 50ug Species: Human Expression Host: E. coli Tag: N-His Predicted MW: 11.2 kDa Concentration: >50 ug/mL as determined by microplate BCA method Purity: > 80% as determined by SDS-PAGE and Coomassie blue staining Buffer: 25mM Tris, pH8.0, 150 mM NaCl, 10% glycerol, 1 % Sarkosyl Storage: Store at -80°C. Stability: Stable for 12 months from the date of receipt of the product under proper storage and handling conditions. Avoid repeated freeze-thaw cycles. RefSeq: NP_003529 Locus ID: 8359 UniProt ID: P62805, B2R4R0 RefSeq Size: 372 Cytogenetics: 6p22.2 RefSeq ORF: 309 Synonyms: H4-16; H4C2; H4C3; H4C4; H4C5; H4C6; H4C8; H4C9; H4C11; H4C12; H4C13; H4C14; H4C15; H4FA; HIST1H4A This product is to be used for laboratory only. Not for diagnostic or therapeutic use. View online » ©2021 OriGene Technologies, Inc., 9620 Medical Center Drive, Ste 200, Rockville, MD 20850, US 1 / 2 H4C1 (NM_003538) Human Recombinant Protein – TP760406 Summary: Histones are basic nuclear proteins that are responsible for the nucleosome structure of the chromosomal fiber in eukaryotes. Two molecules of each of the four core histones (H2A, H2B, H3, and H4) form an octamer, around which approximately 146 bp of DNA is wrapped in repeating units, called nucleosomes. -

University of California, San Diego
UC San Diego UC San Diego Electronic Theses and Dissertations Title The post-terminal differentiation fate of RNAs revealed by next-generation sequencing Permalink https://escholarship.org/uc/item/7324r1rj Author Lefkowitz, Gloria Kuo Publication Date 2012 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA, SAN DIEGO The post-terminal differentiation fate of RNAs revealed by next-generation sequencing A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Biomedical Sciences by Gloria Kuo Lefkowitz Committee in Charge: Professor Benjamin D. Yu, Chair Professor Richard Gallo Professor Bruce A. Hamilton Professor Miles F. Wilkinson Professor Eugene Yeo 2012 Copyright Gloria Kuo Lefkowitz, 2012 All rights reserved. The Dissertation of Gloria Kuo Lefkowitz is approved, and it is acceptable in quality and form for publication on microfilm and electronically: __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ Chair University of California, San Diego 2012 iii DEDICATION Ma and Ba, for your early indulgence and support. Matt and James, for choosing more practical callings. Roy, my love, for patiently sharing the ups and downs -

A Network Based Approach to Identify the Genetic Influence Caused By
bioRxiv preprint doi: https://doi.org/10.1101/482760; this version posted November 30, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. A Network based Approach to Identify the Genetic Influence Caused by Associated Factors and Disorders for the Parkinsons Disease Progression 1st Najmus Sakib 1st Utpala Nanda Chowdhury Dept. of Applied Physics and Electronic Engineering Dept. of Computer Science and Engineering University of Rajshahi University of Rajshahi Rakshahi, Bangladesh Rakshahi, Bangladesh najmus:sakib1995@outlook:com unchowdhury@ru:ac:bd 2nd M. Babul Islam 3rd Julian M.W. Quinn 4th Mohammad Ali Moni Dept. of Applied Physics and Electronic Engg. Bone biology divisions School of Medical Science University of Rajshahi Garvan Institute of Medical Research The University of Sydney Rakshahi, Bangladesh NSW 2010 NSW, Australia babul:apee@ru:ac:bd j:quinn@garvan:org:au mohammad:moni@sydney:edu:au Abstract—Actual causes of Parkinsons disease (PD) are still the central nervous system [1]. It is one of the most common unknown. In any case, a better comprehension of genetic and neurodegenerative problems after Alzheimers illness all over ecological influences to the PD and their interaction will assist the world [2]. The PD is characterized by progressive damage physicians and patients to evaluate individual hazard for the PD, and definitely, there will be a possibility to find a way to of dopaminergic neurons in the substantia nigra pars compacta reduce the progression of the PD. -

Acetyl-Histone H4-K12 Pab Cat
Acetyl-Histone H4-K12 pAb Cat. No.: 15-437 Acetyl-Histone H4-K12 pAb Immunohistochemistry of paraffin- embedded rat ovary using Acetyl-Histone Immunohistochemistry of paraffin-embedded mouse testis using H4-K12 antibody (15-437) at dilution of 1:200 Acetyl-Histone H4-K12 antibody (15-437) at dilution of 1:200 (40x lens). (40x lens). Immunohistochemistry of paraffin- Immunofluorescence analysis of C6 cells using Acetyl-Histone H4-K12 embedded mouse spinal cord using Acetyl- antibody (15-437) at dilution of 1:100.C6 cells were treated by TSA (1 Histone H4-K12 antibody (15-437) at dilution uM) at 37? for 18 hours. Blue: DAPI for nuclear staining. of 1:200 (40x lens). September 27, 2021 1 https://www.prosci-inc.com/acetyl-histone-h4-k12-pab-15-437.html Immunofluorescence analysis of NIH/3T3 cells using Acetyl-Histone H4-K12 antibody (15-437) at dilution of 1:100.NIH/3T3 cells were treated by TSA (1 uM) at 37? for 18 hours. Blue: DAPI for nuclear staining. Specifications HOST SPECIES: Rabbit SPECIES REACTIVITY: Human, Mouse IMMUNOGEN: A synthetic acetylated peptide around K12 of human Histone H4 (NP_001029249.1). TESTED APPLICATIONS: IF, IHC, WB WB: ,1:500 - 1:2000 APPLICATIONS: IHC: ,1:50 - 1:200 IF: ,1:50 - 1:200 Properties PURIFICATION: Affinity purification CLONALITY: Polyclonal ISOTYPE: IgG CONJUGATE: Unconjugated PHYSICAL STATE: Liquid BUFFER: PBS with 0.02% sodium azide, 50% glycerol, pH7.3. STORAGE CONDITIONS: Store at -20˚C. Avoid freeze / thaw cycles. Additional Info OFFICIAL SYMBOL: H4K12ac September 27, 2021 2 https://www.prosci-inc.com/acetyl-histone-h4-k12-pab-15-437.html H4/A, H4FA, HIST1H4B, H4/I, H4FI, HIST1H4C, H4/G, H4FG, HIST1H4D, H4/B, H4FB, HIST1H4E, H4/J, H4FJ, HIST1H4F, H4/C, H4FC, HIST1H4H, H4/H, H4FH, HIST1H4I, H4/M, ALTERNATE NAMES: H4FM, HIST1H4J, H4/E, H4FE, HIST1H4K, H4/D, H4FD, HIST1H4L, H4/K, H4FK, HIST2H4A, H4/N, H4F2, H4FN, HIST2H4, HIST2H4B, H4/O, H4FO, HIST4H4, Histone H4H4FA GENE ID: 8366 USER NOTE: Optimal dilutions for each application to be determined by the researcher. -

Research Article Common Expression Quantitative Trait Loci Shared by Histone Genes
Hindawi International Journal of Genomics Volume 2017, Article ID 6202567, 14 pages https://doi.org/10.1155/2017/6202567 Research Article Common Expression Quantitative Trait Loci Shared by Histone Genes Hanseol Kim, Yujin Suh, and Chaeyoung Lee Department of Bioinformatics and Life Science, Soongsil University, Seoul, Republic of Korea Correspondence should be addressed to Chaeyoung Lee; [email protected] Received 29 May 2017; Revised 26 July 2017; Accepted 2 August 2017; Published 27 August 2017 Academic Editor: Marco Gerdol Copyright © 2017 Hanseol Kim et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. A genome-wide association study (GWAS) was conducted to examine expression quantitative trait loci (eQTLs) for histone genes. We examined common eQTLs for multiple histone genes in 373 European lymphoblastoid cell lines (LCLs). A linear regression model was employed to identify single-nucleotide polymorphisms (SNPs) associated with expression of the histone genes, and the number of eQTLs was determined by linkage disequilibrium analysis. Additional associations of the identified eQTLs with other genes were also examined. We identified 31 eQTLs for 29 histone genes through genome-wide analysis using 29 histone genes (P <297 × 10−10). Among them, 12 eQTLs were associated with the expression of multiple histone genes. Transcriptome- wide association analysis using the identified eQTLs showed their associations with additional 80 genes (P <475 × 10−6). In particular, expression of RPPH1, SCARNA2, and SCARNA7 genes was associated with 26, 25, and 23 eQTLs, respectively. -

Reduction in Reproductive Lifespan of Tissue Inhibitor of Metalloproteinase
REPRODUCTIONRESEARCH RNA polymerase II interacts with the Hspa1b promoter in mouse epididymal spermatozoa Donald C Wilkerson and Kevin D Sarge Department of Molecular and Cellular Biochemistry, University of Kentucky, 741 S. Limestone Street, Lexington, Kentucky 40536, USA Correspondence should be addressed to K D Sarge; Email: [email protected] Abstract The Hspa1b (Hsp70.1) gene is one of the first genes expressed after fertilization, with expression occurring during the minor zygotic genome activation (ZGA) in the absence of stress. This expression can take place in the male pronucleus as early as the one-cell stage of embryogenesis. The importance of HSPA1B for embryonic viability during times of stress is supported by studies showing that depletion of this protein results in a significant reduction in embryos developing to the blastocyte stage. Recently, we have begun addressing the mechanism responsible for allowing expression of Hspa1b during the minor ZGA and found that heat shock transcription factor (HSF) 1 and 2 bind the Hspa1b promoter during late spermatogenesis. In this report, we have extended those studies using western blots and chromatin immunoprecipitation assays and found that RNA polymerase II (Pol II) is present in epididymal spermatozoa and bound to the Hspa1b promoter. These present results, in addition to our previous results, support a model in which the binding of HSF1, HSF2, SP1, and Pol II to the promoter of Hspa1b would allow the rapid formation of a transcription-competent state during the minor ZGA, thereby allowing Hspa1b expression. Reproduction (2009) 137 923–929 Introduction promoter-driven reporter genes confirm this embryonic pattern of expression (Thompson et al.