Trends in Programmable Instruction-Set Processor Architectures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 Introduction
Cambridge University Press 978-0-521-76992-1 - Microprocessor Architecture: From Simple Pipelines to Chip Multiprocessors Jean-Loup Baer Excerpt More information 1 Introduction Modern computer systems built from the most sophisticated microprocessors and extensive memory hierarchies achieve their high performance through a combina- tion of dramatic improvements in technology and advances in computer architec- ture. Advances in technology have resulted in exponential growth rates in raw speed (i.e., clock frequency) and in the amount of logic (number of transistors) that can be put on a chip. Computer architects have exploited these factors in order to further enhance performance using architectural techniques, which are the main subject of this book. Microprocessors are over 30 years old: the Intel 4004 was introduced in 1971. The functionality of the 4004 compared to that of the mainframes of that period (for example, the IBM System/370) was minuscule. Today, just over thirty years later, workstations powered by engines such as (in alphabetical order and without specific processor numbers) the AMD Athlon, IBM PowerPC, Intel Pentium, and Sun UltraSPARC can rival or surpass in both performance and functionality the few remaining mainframes and at a much lower cost. Servers and supercomputers are more often than not made up of collections of microprocessor systems. It would be wrong to assume, though, that the three tenets that computer archi- tects have followed, namely pipelining, parallelism, and the principle of locality, were discovered with the birth of microprocessors. They were all at the basis of the design of previous (super)computers. The advances in technology made their implementa- tions more practical and spurred further refinements. -

Towards Attack-Tolerant Trusted Execution Environments
Master’s Programme in Security and Cloud Computing Towards attack-tolerant trusted execution environments Secure remote attestation in the presence of side channels Max Crone MASTER’S THESIS Aalto University — KTH Royal Institute of Technology MASTER’S THESIS 2021 Towards attack-tolerant trusted execution environments Secure remote attestation in the presence of side channels Max Crone Thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Technology. Espoo, 12 July 2021 Supervisors: Prof. N. Asokan Prof. Panagiotis Papadimitratos Advisors: Dr. HansLiljestrand Dr. Lachlan Gunn Aalto University School of Science KTH Royal Institute of Technology School of Electrical Engineering and Computer Science Master’s Programme in Security and Cloud Computing Abstract Aalto University, P.O. Box 11000, FI-00076 Aalto www.aalto.fi Author Max Crone Title Towards attack-tolerant trusted execution environments: Secure remote attestation in the presence of side channels School School of Science Master’s programme Security and Cloud Computing Major Security and Cloud Computing Code SCI3113 Supervisors Prof. N. Asokan, Prof. Panagiotis Papadimitratos Advisors Dr. Hans Liljestrand, Dr. Lachlan Gunn Level Master’s thesis Date 12 July 2021 Pages 64 Language English Abstract In recent years, trusted execution environments (TEEs) have seen increasing deployment in comput- ing devices to protect security-critical software from run-time attacks and provide isolation from an untrustworthy operating system (OS). A trusted party verifies the software that runs in a TEE using remote attestation procedures. However, the publication of transient execution attacks such as Spectre and Meltdown revealed fundamental weaknesses in many TEE architectures, including Intel Software Guard Exentsions (SGX) and Arm TrustZone. -

Instruction Latencies and Throughput for AMD and Intel X86 Processors
Instruction latencies and throughput for AMD and Intel x86 processors Torbj¨ornGranlund 2019-08-02 09:05Z Copyright Torbj¨ornGranlund 2005{2019. Verbatim copying and distribution of this entire article is permitted in any medium, provided this notice is preserved. This report is work-in-progress. A newer version might be available here: https://gmplib.org/~tege/x86-timing.pdf In this short report we present latency and throughput data for various x86 processors. We only present data on integer operations. The data on integer MMX and SSE2 instructions is currently limited. We might present more complete data in the future, if there is enough interest. There are several reasons for presenting this report: 1. Intel's published data were in the past incomplete and full of errors. 2. Intel did not publish any data for 64-bit operations. 3. To allow straightforward comparison of an important aspect of AMD and Intel pipelines. The here presented data is the result of extensive timing tests. While we have made an effort to make sure the data is accurate, the reader is cautioned that some errors might have crept in. 1 Nomenclature and notation LNN means latency for NN-bit operation.TNN means throughput for NN-bit operation. The term throughput is used to mean number of instructions per cycle of this type that can be sustained. That implies that more throughput is better, which is consistent with how most people understand the term. Intel use that same term in the exact opposite meaning in their manuals. The notation "P6 0-E", "P4 F0", etc, are used to save table header space. -
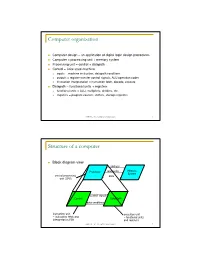
Computer Organization
Computer organization Computer design – an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs = machine instruction, datapath conditions outputs = register transfer control signals, ALU operation codes instruction interpretation = instruction fetch, decode, execute Datapath = functional units + registers functional units = ALU, multipliers, dividers, etc. registers = program counter, shifters, storage registers CSE370 - XI - Computer Organization 1 Structure of a computer Block diagram view address Processor read/write Memory System central processing data unit (CPU) control signals Control Data Path data conditions instruction unit execution unit œ instruction fetch and œ functional units interpretation FSM and registers CSE370 - XI - Computer Organization 2 Registers Selectively loaded – EN or LD input Output enable – OE input Multiple registers – group 4 or 8 in parallel LD OE D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they D5 Q5 are left unconnected (high impedance) D4 Q4 D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs D0 CLK Q0 CSE370 - XI - Computer Organization 3 Register transfer Point-to-point connection MUX MUX MUX MUX dedicated wires muxes on inputs of each register rs rt rd R4 Common input from multiplexer load enables rs rt rd R4 for each register control signals MUX for multiplexer Common bus with output enables output enables and load rs rt rd R4 enables for each register BUS CSE370 - XI - Computer Organization 4 Register files Collections of registers in one package two-dimensional array of FFs address used as index to a particular word can have separate read and write addresses so can do both at same time 4 by 4 register file 16 D-FFs organized as four words of four bits each write-enable (load) 3E RB read-enable (output enable) RA WE (- WB (. -

Data-Flow Prescheduling for Large Instruction Windows in Out-Of-Order Processors
Data-Flow Prescheduling for Large Instruction Windows in Out-of-Order Processors Pierre Michaud, Andr´e Seznec IRISA/INRIA Campus de Beaulieu, 35042 Rennes Cedex, France {pmichaud, seznec}@irisa.fr Abstract We introduce data-flow prescheduling. Instructions are sent to the issue buffer in a predicted data-flow order instead The performance of out-of-order processors increases of the sequential order, allowing a smaller issue buffer. The with the instruction window size. In conventional proces- rationale of this proposal is to avoid using entries in the is- sors, the effective instruction window cannot be larger than sue buffer for instructions which operands are known to be the issue buffer. Determining which instructions from the yet unavailable. issue buffer can be launched to the execution units is a time- In our proposal, this reordering of instructions is accom- critical operation which complexity increases with the issue plished through an array of schedule lines. Each schedule buffer size. We propose to relieve the issue stage by reorder- line corresponds to a different depth in the data-flow graph. ing instructions before they enter the issue buffer. This study The depth of each instruction in the data-flow graph is de- introduces the general principle of data-flow prescheduling. termined, and the instruction is inserted in the correspond- Then we describe a possible implementation. Our prelim- ing schedule line. Lines are consumed by the issue buffer inary results show that data-flow prescheduling makes it sequentially. possible to enlarge the effective instruction window while Section 2 briefly describes issue buffers and discusses re- keeping the issue buffer small. -

Instruction Pipelining (1 of 7)
Chapter 5 A Closer Look at Instruction Set Architectures Objectives • Understand the factors involved in instruction set architecture design. • Gain familiarity with memory addressing modes. • Understand the concepts of instruction- level pipelining and its affect upon execution performance. 5.1 Introduction • This chapter builds upon the ideas in Chapter 4. • We present a detailed look at different instruction formats, operand types, and memory access methods. • We will see the interrelation between machine organization and instruction formats. • This leads to a deeper understanding of computer architecture in general. 5.2 Instruction Formats (1 of 31) • Instruction sets are differentiated by the following: – Number of bits per instruction. – Stack-based or register-based. – Number of explicit operands per instruction. – Operand location. – Types of operations. – Type and size of operands. 5.2 Instruction Formats (2 of 31) • Instruction set architectures are measured according to: – Main memory space occupied by a program. – Instruction complexity. – Instruction length (in bits). – Total number of instructions in the instruction set. 5.2 Instruction Formats (3 of 31) • In designing an instruction set, consideration is given to: – Instruction length. • Whether short, long, or variable. – Number of operands. – Number of addressable registers. – Memory organization. • Whether byte- or word addressable. – Addressing modes. • Choose any or all: direct, indirect or indexed. 5.2 Instruction Formats (4 of 31) • Byte ordering, or endianness, is another major architectural consideration. • If we have a two-byte integer, the integer may be stored so that the least significant byte is followed by the most significant byte or vice versa. – In little endian machines, the least significant byte is followed by the most significant byte. -

Review of Computer Architecture
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I made some modifications to the note for clarity. Assume some background information from CSCE 430 or equivalent von Neumann architecture Memory holds data and instructions. Central processing unit (CPU) fetches instructions from memory. Separate CPU and memory distinguishes programmable computer. CPU registers help out: program counter (PC), instruction register (IR), general- purpose registers, etc. von Neumann Architecture Memory Unit Input CPU Output Unit Control + ALU Unit CPU + memory address 200PC memory data CPU 200 ADD r5,r1,r3 ADD IRr5,r1,r3 Recalling Pipelining Recalling Pipelining What is a potential Problem with von Neumann Architecture? Harvard architecture address data memory data PC CPU address program memory data von Neumann vs. Harvard Harvard can’t use self-modifying code. Harvard allows two simultaneous memory fetches. Most DSPs (e.g Blackfin from ADI) use Harvard architecture for streaming data: greater memory bandwidth. different memory bit depths between instruction and data. more predictable bandwidth. Today’s Processors Harvard or von Neumann? RISC vs. CISC Complex instruction set computer (CISC): many addressing modes; many operations. Reduced instruction set computer (RISC): load/store; pipelinable instructions. Instruction set characteristics Fixed vs. variable length. Addressing modes. Number of operands. Types of operands. Tensilica Xtensa RISC based variable length But not CISC Programming model Programming model: registers visible to the programmer. Some registers are not visible (IR). Multiple implementations Successful architectures have several implementations: varying clock speeds; different bus widths; different cache sizes, associativities, configurations; local memory, etc. -

Jetson TX2 • NVIDIA Jetson Xavier • GPU Programming • Algorithm Mapping: • Convolutions Parallel Algorithm Execution
GPU and multicore CPU architectures. Algorithm mapping Contributors: N. Tsapanos, I. Karakostas, I. Pitas Aristotle University of Thessaloniki, Greece Presenter: Prof. Ioannis Pitas Aristotle University of Thessaloniki [email protected] www.multidrone.eu Presentation version 1.3 GPU and multicore CPU architectures. Algorithm mapping • GPU and multicore CPU processing boards • Graphics cards • NVIDIA Jetson TX2 • NVIDIA Jetson Xavier • GPU programming • Algorithm mapping: • Convolutions Parallel algorithm execution • Graphics computing: • Highly parallelizable • Linear algebra parallelization: • Vector inner products: 푐 = 풙푇풚. • Matrix-vector multiplications 풚 = 푨풙. • Matrix multiplications: 푪 = 푨푩. Parallel algorithm execution • Convolution: 풚 = 푨풙 • CNN architectures, linear systems, signal filtering. • Correlation: 풚 = 푨풙 • template matching, tracking. • Signal transforms (DFT, DCT, Haar, etc): • Matrix vector product form: 푿 = 푾풙 • 2D transforms (matrix product form): 푿’ = 푾푿. Processing Units • Multicore (CPU): • MIMD. • Focused on latency. • Best single thread performance. • Manycore (GPU): • SIMD. • Focused on throughput. • Best for embarrassingly parallel tasks. Pascal microarchitecture https://devblogs.nvidia.com/inside-pascal/gp100_block_diagram-2/ Pascal microarchitecture https://devblogs.nvidia.com/inside-pascal/gp100_sm_diagram/ GeForce GTX 1080 • Microarchitecture: Pascal. • DRAM: 8 GB GDDR5X at 10000 MHz. • SMs: 20. • Memory bandwidth: 320 GB/s. • CUDA cores: 2560. • L2 Cache: 2048 KB. • Clock (base/boost): 1607/1733 MHz. • L1 Cache: 48 KB per SM. • GFLOPs: 8873. • Shared memory: 96 KB per SM. GPU and multicore CPU architectures. Algorithm mapping • GPU and multicore CPU processing boards • Graphics cards • NVIDIA Jetson TX2 • NVIDIA Jetson Xavier • GPU programming • Algorithm mapping: • Convolutions ARM Cortex-A57: High-End ARMv8 CPU • ARMv8 architecture • Architecture evolution that extends ARM’s applicability to all markets. • Full ARM 32-bit compatibility, streamlined 64-bit capability. -

V850ES/SA2, V850ES/SA3 32-Bit Single-Chip Microcontrollers
To our customers, Old Company Name in Catalogs and Other Documents On April 1st, 2010, NEC Electronics Corporation merged with Renesas Technology Corporation, and Renesas Electronics Corporation took over all the business of both companies. Therefore, although the old company name remains in this document, it is a valid Renesas Electronics document. We appreciate your understanding. Renesas Electronics website: http://www.renesas.com April 1st, 2010 Renesas Electronics Corporation Issued by: Renesas Electronics Corporation (http://www.renesas.com) Send any inquiries to http://www.renesas.com/inquiry. Notice 1. All information included in this document is current as of the date this document is issued. Such information, however, is subject to change without any prior notice. Before purchasing or using any Renesas Electronics products listed herein, please confirm the latest product information with a Renesas Electronics sales office. Also, please pay regular and careful attention to additional and different information to be disclosed by Renesas Electronics such as that disclosed through our website. 2. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 3. You should not alter, modify, copy, or otherwise misappropriate any Renesas Electronics product, whether in whole or in part. 4. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. -

Cost-Effective Compilation Techniques for Java Just-In-Time Compilers 3
IEICE TRANS. ??, VOL.Exx–??, NO.xx XXXX 200x 1 PAPER Cost-Effective Compilation Techniques for Java Just-in-Time Compilers Kazuyuki SHUDO†, Satoshi SEKIGUCHI†, Nonmembers, and Yoichi MURAOKA ††, Fel low SUMMARY Java Just-in-Time compilers have to satisfy a policies. number of requirements in conflict with each other. Effective execution of a generated code is not the only requirement, but 1. Ease of use as a base of researches. compilation time, memory consumption and compliance with the 2. Cost-effective development. Less labor and rela- Java Virtual Machine specification are also important. We have tively much effect. developed a Java Just-in-Time compiler keeping implementation 3. Adequate quality and performance for practical labor little. Another important objective is developing an ad- equate base of following researches which utilize this compiler. use. The proposed compilation techniques take low compilation cost and low development cost. This paper also describes optimization Compiler development involves much work on a methods implemented in the compiler, for instance, instruction parser, intermediate representations and a number of folding, exception handling with signals and code patching. optimizations. Because of it, we have to consider those key words: Runtime compilation, Java Virtual Machine, Stack human and engineering factor seriously in addition to caching, Instruction folding, Code patching technical requirements like performance. Our plan on the development of the JIT compiler was to have a prac- 1. Introduction tical compiler with work several man-month. Our an- other goal was specifically having a research base on Just-in-Time (JIT) compilers for Java bytecode have which we do following researches with less labor while to satisfy a number of requirements, which are differ- developing it with less work. -

MIPS Architecture • MIPS (Microprocessor Without Interlocked Pipeline Stages) • MIPS Computer Systems Inc
Spring 2011 Prof. Hyesoon Kim MIPS Architecture • MIPS (Microprocessor without interlocked pipeline stages) • MIPS Computer Systems Inc. • Developed from Stanford • MIPS architecture usages • 1990’s – R2000, R3000, R4000, Motorola 68000 family • Playstation, Playstation 2, Sony PSP handheld, Nintendo 64 console • Android • Shift to SOC http://en.wikipedia.org/wiki/MIPS_architecture • MIPS R4000 CPU core • Floating point and vector floating point co-processors • 3D-CG extended instruction sets • Graphics – 3D curved surface and other 3D functionality – Hardware clipping, compressed texture handling • R4300 (embedded version) – Nintendo-64 http://www.digitaltrends.com/gaming/sony- announces-playstation-portable-specs/ Not Yet out • Google TV: an Android-based software service that lets users switch between their TV content and Web applications such as Netflix and Amazon Video on Demand • GoogleTV : search capabilities. • High stream data? • Internet accesses? • Multi-threading, SMP design • High graphics processors • Several CODEC – Hardware vs. Software • Displaying frame buffer e.g) 1080p resolution: 1920 (H) x 1080 (V) color depth: 4 bytes/pixel 4*1920*1080 ~= 8.3MB 8.3MB * 60Hz=498MB/sec • Started from 32-bit • Later 64-bit • microMIPS: 16-bit compression version (similar to ARM thumb) • SIMD additions-64 bit floating points • User Defined Instructions (UDIs) coprocessors • All self-modified code • Allow unaligned accesses http://www.spiritus-temporis.com/mips-architecture/ • 32 64-bit general purpose registers (GPRs) • A pair of special-purpose registers to hold the results of integer multiply, divide, and multiply-accumulate operations (HI and LO) – HI—Multiply and Divide register higher result – LO—Multiply and Divide register lower result • a special-purpose program counter (PC), • A MIPS64 processor always produces a 64-bit result • 32 floating point registers (FPRs). -

Picojava-II™ Programmer's Reference Manual
picoJava-II™ Programmer’s Reference Manual Sun Microsystems, Inc. 901 San Antonio Road Palo Alto, CA 94303 USA 650 960-1300 Part No.: 805-2800-06 March 1999 Copyright 1999 Sun Microsystems, Inc. 901 San Antonio Road, Palo Alto, California 94303 U.S.A. All rights reserved. The contents of this document are subject to the current version of the Sun Community Source License, picoJava Core (“the License”). You may not use this document except in compliance with the License. You may obtain a copy of the License by searching for “Sun Community Source License” on the World Wide Web at http://www.sun.com. See the License for the rights, obligations, and limitations governing use of the contents of this document. Sun, Sun Microsystems, the Sun logo and all Sun-based trademarks and logos, Java, picoJava, and all Java-based trademarks and logos are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. DOCUMENTATION IS PROVIDED “AS IS” AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON- INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. THIS PUBLICATION COULD INCLUDE TECHNICAL INACCURACIES OR TYPOGRAPHICAL ERRORS. CHANGES ARE PERIODICALLY ADDED TO THE INFORMATION HEREIN; THESE CHANGES WILL BE INCORPORATED IN NEW EDITIONS OF THE PUBLICATION.