Nibbler: Debloating Binary Shared Libraries
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Magazine Lip Forming Tools
MAGAZINE LIP FORMING TOOLS Brownells Lip Forming Anvil and Yoke help the gunsmith alter original equipment-style, .45 caliber, 1911 Auto magazines to properly feed ammuni- tion with semi-wadcutter bullets. Issue-style feed lips are designed for round nose, 230 grain, jacketed bul- lets which have a long ogive and ride up the barrel’s feed ramp easily. Rounds loaded with shorter, lighter, blunt nosed or semi-wadcutter bullets can ei- ther run into the feed ramp as the slide carries them forward or “stand up” too soon and cause a smokestack jam. Changing the lip contour with these tools causes the magazine to release the rear of the cartridge sooner so the extractor can pick it up and help direct it up the ramp and into the chamber. Most aftermarket magazines like those made by Metalform, Wilson, Mc- Cormick, Pachmayr and others, already have a similar feed lip shape. The Lip Forming Anvil and Yoke can often be used to restore the lips on these magazines if they get damaged. READ & FOLLOW THESE m WARNING m Never attempt to disassemble or reassemble a firearm unless you are INSTRUCTIONS absolutely certain that it is empty and unloaded. Visually inspect the chamber, the magazine and firing mechanism to be absolutely certain that no ammunition remains in the firearm. Disassembly and reas- BROWNELLS GUNSMITHS DATA RING BINDER GUNSMITHS BROWNELLS DATA sembly should follow the manufacturer’s instructions. If such instruc- tions are not immediately available, contact the manufacturer to see if they are available. If they are not available at all, then you should 200 S. -

S2P Conference
The 9th International Conference on Semi-Solid Processing of Alloys and Composites —S2P Busan, Korea, Conference September 11-13, 2006 Qingyue Pan, Research Associate Professor Metal Processing Institute, WPI Worcester, Massachusetts Busan, a bustling city of approximately 3.7 million resi- Pusan National University, in conjunction with the Korea dents, is located on the Southeastern tip of the Korean Institute of Industrial Technology, and the Korea Society peninsula. It is the second largest city in Korea. Th e natu- for Technology of Plasticity hosted the 9th S2P confer- ral environment of Busan is a perfect example of harmony ence. About 180 scientists and engineers coming from 23 between mountains, rivers and sea. Its geography includes countries attended the conference to present and discuss all a coastline with superb beaches and scenic cliff s, moun- aspects on semi-solid processing of alloys and composites. tains which provide excellent hiking and extraordinary Eight distinct sessions contained 113 oral presentations views, and hot springs scattered throughout the city. and 61 posters. Th e eight sessions included: 1) alloy design, Th e 9th International Conference on Semi-Solid Pro- 2) industrial applications, 3) microstructure & properties, cessing of Alloys and Composites was held Sept. 11-13, 4) novel processes, 5) rheocasting, 6) rheological behavior, 2006 at Paradise Hotel, Busan. Th e fi ve-star hotel off ered a modeling and simulation, 7) semi-solid processing of high spectacular view of Haeundae Beach – Korea’s most popular melting point materials, and 8) semi-solid processing of resort, which was the setting for the 9th S2P conference. -

Monte Carlo Stock
Gun Stocks STOCK DESIGN AND STOCK STYLE Types of Gun Stocks A gunsmith requires a basic understanding of stock function prior to becoming a stock maker. A rifle stock, in function, is nothing more than a segment of wood, fiberglass, plastic, or other material shaped to support the rifle’s barrel and action. It also functions to conform to the shooter’s body so the shooter can control the firearm. That’s the mechanical side of it. However, arms lovers the world over consider a stock much more than a mechanical device. They think of a gun stock as a work of art and function (Figure 1). As a prospec- tive gunsmith, we hope this is your position. FIGURE 1—Notice the attractive oak-leaf pattern on this Bishop-III stock. (Photo courtesy of Reinhart Fajen, Inc.) Stocks can be built in a multitude of styles with a stock shape to fit everyone. Even factory rifles come in a wide variety of stock styles. Factory stocks, incidentally, have come a long way and can be considered quite good today, although cer- tainly not in the realm of a custom-made stock. Figure 2 shows a gun stock labeled with its proper nomenclature. 1 FIGURE 2—Become familiar with the names of the parts of a gun stock. Early Stock Design Turning the pages of gun history to an earlier time reveals that the first stocks well known to American shooters had a great deal to do with contemporary stock designs. However, such muzzleloader stocks left a lot to be desired. -

Development of Guidelines for Warm Forging of Steel Parts
Development of Guidelines for Warm Forging of Steel Parts THESIS Presented in Partial Fulfillment of the Requirements for the Degree Master of Science in the Graduate School of The Ohio State University By Niranjan Rajagopal, B.Tech Graduate Program in Industrial and Systems Engineering The Ohio State University 2014 Master's Examination Committee: Dr.Taylan Altan, Advisor Dr.Jerald Brevick Copyright by Niranjan Rajagopal 2014 ABSTRACT Warm forging of steel is an alternative to the conventional hot forging technology and cold forging technology. It offers several advantages like no flash, reduced decarburization, no scale, better surface finish, tight tolerances and reduced energy when compared to hot forging and better formability, lower forming pressures and higher deformation ratios when compared to cold forging. A system approach to warm forging has been considered. Various aspects of warm forging process such as billet, tooling, billet/die interface, deformation zone/forging mechanics, presses for warm forging, warm forged products, economics of warm forging and environment & ecology have been presented in detail. A case study of forging of a hollow shaft has been discussed. A comparison of forging loads and energy required to forge the hollow shaft using cold, warm and hot forging process has been presented. ii DEDICATION This document is dedicated to my family. iii ACKNOWLEDGEMENTS I am grateful to my advisor, Prof. Taylan Altan for accepting me in his research group, Engineering Research Center for Net Shape Manufacturing (ERC/NSM) and allowing me to do thesis under his supervision. The support of Dr. Jerald Brevick along with other professors at The Ohio State University was also very important in my academic and professional development. -

Design of Forming Processes: Bulk Forming
1 Design of Forming Processes: Bulk Forming Chester J. Van Tyne Colorado School of Mines, Golden, Colorado, U.S.A. I. BULK DEFORMATION atures relative to the melting point of the metal. Hot working occurs at temperatures above tJllerecrystalliza- Bulk defonnation is a metal-fonning process where the tion temperature of the metal. There is a third temper- defonnation is three-dimensional in nature. The pri- ature range, warm working, which is being critically mary use of the tenn bulk deformation is to distinguish it examined due to energy savings and is, in some cases, from sheet-fonning processes. In sheet-forming opera- used by industries. tions, the defonnation stressesare usually in the plane of the sheet metal, whereas in bulk defonnation, the 1. Cold Working Temperatures defonnation stresses possess components in all three Cold working usually refers to metal deformation that is coordinate directions. Bulk defonnation includes metal carried out at room temperature. Th,~ phenomenon working processes such as forging, extrusion, rolling, associated with cold work occurs wht:n the metal is and drawing. deformed at temperatures that are about 30% or less of its melting temperature on an absolute temperature scale. During cold work, the metal ,~xperiences an II. CLASSIFICATION OF DEFORMATION increased number of dislocations and elltanglement of PROCESSES these dislocations, causing strain hardening. With strain hardening, the strength of the metal increases with The classification of deformation processescan be done deformation. To recrystallize the metal, ;i thermal treat- in one of several ways. The more common classification ment, called an anneal, is often needed. During anneal- schemes are based on temperature, flow behavior, and ing, the strength of the metal can be drastically reduced stressstate. -

Design, Construction, and First Tests of a Demonstration Spark Chamber
Design, Construction, and First Tests of a Demonstration Spark Chamber Lisa Lin,∗ Robin Peter,y Sophia Vlahakis,z and Tara Vogelx The University of Chicago, Illinois, 60637 (Dated: September 21, 2018) Once used extensively in particle physics research, the cosmic ray spark chamber is a tracking particle detector now favored for education and demonstration. We have constructed and are nearing installation of a chamber for educational and demonstration purposes, selecting a shelf-type design to prioritize aesthetic appeal and minimal maintenance. An incoming particle triggers a fast high- voltage pulse to metal plates within the chamber that allows sparking along the particle's ionized path. The shelf-style design and careful scintillator placement limits spurious edge sparking. The coincidence circuit comprised of scintillation counters and NIM units successfully delivers a logic pulse within 60 ns, and its 1.3-V pulse is amplified ten-fold in a total delay time of 500 ns from detection to spark gap pulse, triggering an 8-kV pulse in the chamber. The prototype chamber is tested independently with helium and argon gases. A plan is presented to predict lifetime based on the muon efficiency of the prototype chamber. Initial stages of an interactive soft-shut off are presented for safety and consideration of the chamber demonstration's surrounding academic environment. I. INTRODUCTION nents for a similar purpose; we have used their proce- dure as an initial guide [1]. This document tracks our Spark chambers have been used in the past as tracking major considerations, revisions, and additions to their particle detectors, and are most widely used today for work, and presents that information for the perusal and educational purposes [1]. -

Hot Brass Magazine, Vol 25, 2016
In This Issue 3 Offhand Shots from the Editor 24 7 A Note from the President . A Piece of History Thriving in the Present LIEUTENANT 9 COLONEL 38 34 CHARLES KETTLES: 12 AMERICAN HERO Rhonda Ezell Still on Target! 44 16 Articles: Email your articles to GCA [email protected] FELLOWSHIP Submissions and Contributions: We welcome you to submit articles, stories, and Send in your articles, photos for publication in Hot Brass. GCA pays for submissions and contributions jokes, tips, hints, stories, with "AGI Bucks." These coupons are redeemable dollar-for-dollar towards the shooting activities, purchase of any AGI product or AGI video course. We pay for stories and articles we pictures, recipes, - print by the word: 100-300 words = 20 AGI Bucks, 300-500 words = 50 AGI Bucks, all those things you 500+ words = 100 AGI Bucks. Articles and stories must be submitted in MS Word or tell your friends . MS publisher format. Photos: Electronic photos must be submitted in a jpeg format with a resolution of at LEAST 640x480. Print photos are accepted but GCA cannot return Let’s share it with any printed photos and all submitted photos will become the property of GCA. the world. ©Copyright GCA 2016. All rights reserved. Hot Brass Magazine is published and produced by GCA and distributed to GCA Members. No part of this magazine may be copied, reproduced, rented, or transmitted for any reason without the written permission of the copyright holder. Contacting GCA: GCA, 351 Second Street, Napa, CA 94559, 1-800-435-GCOA (4262), Fax 707-253-2150, www.GunClubOfAmerica.com Subscriber Information: Missing or Damaged Issues: If an issue of Hot Brass is lost in the mail or arrives damaged, simply contact GCA at 1-800-435-GCOA (4262) for a replacement. -
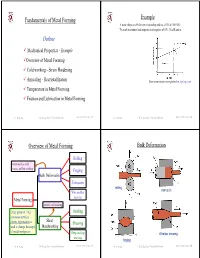
Metal Forming Fundamentals
Fundamentals of Metal Forming Example A metal obeys the Hollomon relationship and has a UTS of 300 MPa. To reach maximum load requires an elongation of 35%. Find K and n. Outline 9 Mechanical Properties - Example 9Overview of Metal Forming 9 Cold working - Strain Hardening 9 Annealing - Recrystallization True stress-strain curve plotted on log-log scale 9 Temperature in Metal Forming 9 Friction and Lubrication in Metal Forming Dr. M. Medraj Mech. Eng. Dept. - Concordia University Mech 421/6511 lecture 3/1 Dr. M. Medraj Mech. Eng. Dept. - Concordia University Mech 421/6511 lecture 3/2 Overview of Metal Forming Bulk Deformation Rolling Performed as cold, warm, and hot working Forging Bulk Deformation Extrusion rolling extrusion Wire and bar drawing Metal Forming Mainly cold working Large group of mfg Bending processes in which Sheet plastic deformation is Shearing used to change the shape Metalworking of metal workpieces Deep and cup Wire/bar drawing drawing forging Dr. M. Medraj Mech. Eng. Dept. - Concordia University Mech 421/6511 lecture 3/3 Dr. M. Medraj Mech. Eng. Dept. - Concordia University Mech 421/6511 lecture 3/4 Sheet Metalworking Formability (workability) Formability of the material depends on: (1) process variables - ……………… Desirable material properties in metal forming: - ……………… – Low yield strength and high ductility - ……………… (2) Metallurgical changes during deformation bending Deep/cup drawing - formation of voids, composition, inclusions, precipitation, .... etc. Ductility increases and yield strength decreases when work temperature is raised → Any deformation operation can be accomplished with lower forces and power at elevated temperature shearing Dr. M. Medraj Mech. Eng. Dept. - Concordia University Mech 421/6511 lecture 3/5 Dr. -

Spark Ignition Measurements in Jet A: Part II
Spark Ignition Measurements in Jet A: part II Julian J. Lee and Joseph E. Shepherd Graduate Aeronautical Laboratories California Institute of Technology Pasadena, CA 91125 January 22, 2000 Explosion Dynamics Laboratory Report FM 99-7 Prepared for and supported by the National Transportation Safety Board Under Order NTSB12-98-CB-0415 Abstract An improved system for measuring the ignition energy of liquid fuel was built to perform experiments on aviation kerosene (Jet A). Compared to a previously used system (Shepherd et al. 1998), the present vessel has a more uniform temperature which can be held constant for long periods of time. This ensures thermal equilibrium of the liquid fuel and the vapor inside the vessel. A capacitive spark discharge circuit was used to generate damped sparks and an arrangement of resistors and measurement probes recorded the voltage and current histories during the discharge. This permitted measurement of the energy dissipated in the spark, providing a more reliable, quantitative measure of the ignition spark strength. With this improved system, the ignition energy of Jet A was measured at temperatures from 35◦Cto 50◦C, pressures from 0.300 bar (ambient pressure at 30 kft) to 0.986 bar (ambient pressure near sea level), mass-volume ratios down to 3 kg/m3, with sparks ranging from 10 mJ to 0.3 J. ◦ ◦ Special fuel blends with flash points (Tfp) from 29 C to 73.5 C were also tested. The statistical properties of the ignition threshold energy were investigated using techniques developed for high-explosive testing. Ignition energy measurements at 0.585 bar with high mass-volume ratios (also referred to as mass loadings) showed that the trend of the dependence of ignition energy on temperature was similar for tests using the stored capacitive energy and the measured spark energy. -

Design Guidelines Pressure Forming
Design Guidelines For Pressure Forming Plastics Design & Manufacturing Centennial, Colorado Pressure Forming 101 This checklist is a guideline for the design and development of pressure formed parts in order to facilitate manufacturability, quality assurance and cost containment. There are several aspects in designing pressure formed parts which should be considered in product development. Attention to these aspects in the design and development of a pressure formed part will help provide a part which can be manufactured to the highest quality in a cost effective manner. Materials Part Size and Draw Ratios Surface Radii Draft Angles and Part Shape Undercuts and Ribbing Textures and Finishes Toleranceing Part Dimensioning Material Selection In looking at materials, consideration should be given to the environment the part is exposed to including U/V, temperature and chemical exposures as well as structural requirements. In addition, toleranceing requirements should be taken into consideration since some materials are not as stable and tight tolerance will be difficult to achieve. Cosmetic requirements should also be reviewed when selecting raw materials in order to accommodate necessary esthetics such as color, textures as well as paint, shielding or part marking. Different raw materials will have varying positive or negative effects on the final product with respect to cosmetics and finish. Common materials include: ABS, Flame Retardant ABS, ABS/PVC, Acrylic/PVC, Polycarbonate, PETG, Polypropylene, Polyethylene, and HMWPE. Part Size and Draw Ratio While both large and small parts can be produced with the process, Pressure forming tends to be most competitive in medium to large parts, due to the competitive nature of small injection molded parts produced in very large quantities. -

Classic Sheet Metal Processing in New Dimensions – Punching, Nibbling, Forming
PUNCHING Classic sheet metal processing in new dimensions – punching, nibbling, forming Since the fifties, as advances were made in sheet metal processing machines, the significance of the sheet metal as a material increased accordingly. Whereas punching machines were first used primarily for creating precision holes, they are used today for a multitude of manufacturing tasks in flexible processing. Their outstanding feature is that when used for punching, nibbling and forming, they can process quickly while retaining high precision. he term punching describes a slit- information were used. The floppy disk ting process, in which a punching finally superseded the punched tape as Tmachine or press separates a sheet a data carrier. Moreover, tool changing of metal by striking it. Initially, eccentric and loading and unloading of the work- presses were employed for punching piece were automated. holes. Sheet contours were processed by The development of the electrohy- stamping machines. By equipping these draulic ram drive finally allowed a work- with nibbling tools, the nibbling ma- piece to be processed while taking the chine was born. required punching power, stroke speed, Nibbling refers to separating a mate- and stroke position into account. Pro- rial bit by bit along any formed cutting cesses such as forming and tapping line by punching several individual, over- rounded off the processing possibilities lapping holes. of a complete metal sheet on a punching Whereas an operator once moved machine. the workpiece by hand, partial automa- The rapid development of punching tion was later made possible thanks to technology forms the foundation for to- the development of a machine with a day’s high-tech machines with their coordinate guide and a template. -

Nibbler Medium
Nibbler Medium Press lines Power Presses Coil- handling Nibbler Ancillary SMV Nibbler Medium Nibbler sheet metal machine is a sheet metal workshop in itself - providing, in the minimum of space, all the functions of a punching and nibbling machine for shearing straight, circular and curved shapes and also for beading, joggling, flanging, edging and profile bending. With its wide Service versatility, it is indispensable in the sheet metal workshop, but it also find application in technical colleges, experimental and development laboratories. Nibbler Medium has a 2-speed motor giving 700 - 1400 - 2800 strokes/min and stroke lengths of 1, 2, 3 or 4,5 mm. The lowest rate of stroking is intended mainly for nibbling. Nibbler can be used not only for steel, brass, copper and aluminium but also for cutting plastics sheeting, rubber, compressed fibre, cork and paper. Automation SMV Nibbler can supply over 20 different standard tools and these, together with a wide range of accessories, are described on a separate Optionlist for the Nibbler machines. Nibbler solves many of the sheet metal processing problems which would otherwise require heavy investment in machines and tooling. Smålandsstenars Mekaniska Verkstad SMV AB Tel: +46(0)371 343 40•Fax: +46(0)371 343 41 Education [email protected] www.smv.se 20 REASONS WHY YOU SHOULD BUY NIBBLER - sturdy welded machine frame, made from high-quality steel plate - totally enclosed fan-cooled motor meeting requirements of IEC - totally enclosed toggle-lever system operating in an oil-bath Standards - well balanced