Event-Based Access to Historical Italian War Memoirs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Network Scan Data
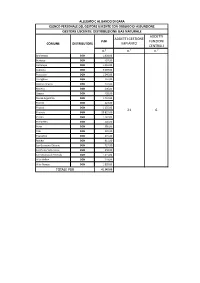
ALLEGATO C AL BANDO DI GARA ELENCO PERSONALE DEL GESTORE USCENTE CON OBBLIGO DI ASSUNZIONE GESTORE USCENTE: DISTRIBUZIONE GAS NATURALE ADDETTI ADDETTI GESTIONE PdR FUNZIONI COMUNE DISTRIBUTORE IMPIANTO CENTRALI n.° n.° n.° Bricherasio DGN 1.808,00 Buriasco DGN 497,00 Cantalupa DGN 1.046,00 Cumiana DGN 3.039,00 Frossasco DGN 1.240,00 Garzigliana DGN 197,00 Inverso Pinasca DGN 207,00 Macello DGN 406,00 Osasco DGN 428,00 Perosa ArgenQna DGN 1.404,00 Perrero DGN 224,00 Pinasca DGN 1.155,00 21 6 Pinerolo DGN 20.825,00 Piscina DGN 1.542,00 PomareSo DGN 446,00 Porte DGN 580,00 Prali DGN 229,00 PrarosQno DGN 271,00 RoleSo DGN 911,00 San Germano Chisone DGN 727,00 San Pietro Val Lemina DGN 658,00 San Secondo di Pinerolo DGN 1.415,00 Villar Pellice DGN 259,00 Villar Perosa DGN 1.828,00 TOTALE PDR 41.342,00 ALLEGATO C AL BANDO DI GARA ELENCO PERSONALE DEL GESTORE USCENTE CON OBBLIGO DI ASSUNZIONE AL 31.12.2013 GESTORE USCENTE: ITALGAS ADDETTI ADDETTI GESTIONE PdR FUNZIONI COMUNE DISTRIBUTORE IMPIANTO CENTRALI n.° n.° n.° AIRASCA ITALGAS 1.908,00 Angrogna ITALGAS 82,00 BiBiana ITALGAS 1.257,00 Campiglione-Fenile ITALGAS 524,00 Candiolo ITALGAS 23,00 Candiolo (TO) ITALGAS 2.919,00 Carmagnola ITALGAS 15.621,00 Castagnole Piemonte ITALGAS 996,00 Cavour ITALGAS 2.162,00 Cercenasco ITALGAS 912,00 LomBriasco ITALGAS 507,00 Luserna San Giovanni ITALGAS 4.129,00 Lusernea ITALGAS 116,00 None ITALGAS 4.011,00 Osasio ITALGAS 456,00 Pancalieri ITALGAS 856,00 PioBesi Torinese ITALGAS 1.952,00 15 10 Scalenghe ITALGAS 1.500,00 Torre Pellice ITALGAS 3.555,00 Vigone -

Distant Reading, Computational Stylistics, and Corpus Linguistics the Critical Theory of Digital Humanities for Literature Subject Librarians David D
CHAPTER FOUR Distant Reading, Computational Stylistics, and Corpus Linguistics The Critical Theory of Digital Humanities for Literature Subject Librarians David D. Oberhelman FOR LITERATURE librarians who frequently assist or even collaborate with faculty, researchers, IT professionals, and students on digital humanities (DH) projects, understanding some of the tacit or explicit literary theoretical assumptions involved in the practice of DH can help them better serve their constituencies and also equip them to serve as a bridge between the DH community and the more traditional practitioners of literary criticism who may not fully embrace, or may even oppose, the scientific leanings of their DH colleagues.* I will therefore provide a brief overview of the theory * Literary scholars’ opposition to the use of science and technology is not new, as Helle Porsdam has observed by looking at the current debates over DH in the academy in terms of the academic debate in Great Britain in the 1950s and 1960s between the chemist and novelist C. P. Snow and the literary critic F. R. Leavis over the “two cultures” of science and the humanities (Helle Porsdam, “Too Much ‘Digital,’ Too Little ‘Humanities’? An Attempt to Explain Why Humanities Scholars Are Reluctant Converts to Digital Humanities,” Arcadia project report, 2011, DSpace@Cambridge, www.dspace.cam.ac.uk/handle/1810/244642). 54 DISTANT READING behind the technique of DH in the case of literature—the use of “distant reading” as opposed to “close reading” of literary texts as well as the use of computational linguistics, stylistics, and corpora studies—to help literature subject librarians grasp some of the implications of DH for the literary critical tradition and learn how DH practitioners approach literary texts in ways that are fundamentally different from those employed by many other critics.† Armed with this knowledge, subject librarians may be able to play a role in integrating DH into the traditional study of literature. -

KB-Driven Information Extraction to Enable Distant Reading of Museum Collections Giovanni A
KB-Driven Information Extraction to Enable Distant Reading of Museum Collections Giovanni A. Cignoni, Progetto HMR, [email protected] Enrico Meloni, Progetto HMR, [email protected] Short abstract (same as the one submitted in ConfTool) Distant reading is based on the possibility to count data, to graph and to map them, to visualize the re- lations which are inside the data, to enable new reading perspectives by the use of technologies. By contrast, close reading accesses information by staying at a very fine detail level. Sometimes, we are bound to close reading because technologies, while available, are not applied. Collections preserved in the museums represent a relevant part of our cultural heritage. Cataloguing is the traditional way used to document a collection. Traditionally, catalogues are lists of records: for each piece in the collection there is a record which holds information on the object. Thus, a catalogue is just a table, a very simple and flat data structure. Each collection has its own catalogue and, even if standards exists, they are often not applied. The actual availability and usability of information in collections is impaired by the need of access- ing each catalogue individually and browse it as a list of records. This can be considered a situation of mandatory close reading. The paper discusses how it will be possible to enable distant reading of collections. Our proposed solution is based on a knowledge base and on KB-driven information extraction. As a case study, we refer to a particular domain of cultural heritage: history of information science and technology (HIST). -

The Origins of the European Integration: Staunch Italians, Cautious British Actors and the Intelligence Dimension (1942-1946) Di Claudia Nasini
Eurostudium3w gennaio-marzo 2014 The Origins of the European Integration: Staunch Italians, Cautious British Actors and the Intelligence Dimension (1942-1946) di Claudia Nasini The idea of unity in Europe is a concept stretching back to the Middle Ages to the exponents of the Respublica Christiana. Meanwhile the Enlightenment philosophers and political thinkers recurrently advocated it as a way of embracing all the countries of the Continent in some kind of pacific order1. Yet, until the second half of the twentieth century the nationalist ethos of Europeans prevented any limitation of national sovereignty. The First World War, the millions of casualties and economic ruin in Europe made the surrendering of sovereignty a conceivable way of overcoming the causes of recurring conflicts by bringing justice and prosperity to the Old World. During the inter-war years, it became evident that the European countries were too small to solve by their own efforts the problem of a modern economy2. As a result of the misery caused by world economic crisis and the European countries’ retreating in economic isolationism, various forms of Fascism emerged in almost half of the countries of Europe3. The League of Nations failed to prevent international unrest because it had neither the political power nor the material strength to enable itself to carry 1 Cfr. Andrea Bosco, Federal Idea, vol. I, The History of Federalism from Enlightenment to 1945, London and New York, Lothian foundation, 1991, p. 99 and fll.; and J.B. Duroselle, “Europe as an historical concept”, in C. Grove Haines (ed.by) European Integration, Baltimore, 1958, pp. -

IXA-Pipe) and Parsing (Alpino)
Details from a distance? CLIN26 Amsterdam A Dutch pipeline for event detection Chantal van Son, Marieke van Erp, Antske Fokkens, Paul Huygen, Ruben Izquierdo Bevia & Piek Vossen CLOSE READING DISTANT READING NewsReader & BiographyNet Apply the detailed analyses typically associated with close (or at least non-distant) reading to large amounts of textual data ✤ NewsReader: (financial) news data ✤ Day-by-day processing of news; reconstructing a coherent story ✤ Four languages: English, Spanish, Italian, Dutch ✤ BiographyNet: biographical data ✤ Answering historical questions with digitalized data from Biography Portal of the Netherlands (www.biografischportaal.nl) using computational methods http://www.newsreader-project.eu/ http://www.biographynet.nl/ Event extraction and representation 1. Intra-document processing: Dutch NLP pipeline generating NAF files ✤ pipeline includes tokenization, parsing, SRL, NERC, etc. ✤ NLP Annotation Format (NAF) is a multi-layered annotation format for representing linguistic annotations in complex NLP architectures 2. Cross-document processing: event coreference to convert NAF to RDF representation 3. Store the NAF and RDF in a KnowledgeStore Event extraction and representation 1. Intra-document processing: Dutch NLP pipeline generating NAF files ✤ pipeline includes tokenization, parsing, SRL, NERC, etc. ✤ NLP Annotation Format (NAF) is a multi-layered annotation format for representing linguistic annotations in complex NLP architectures 2. Cross-document processing: event coreference to convert NAF to RDF 3. -

Alta Val Susa & Chisone
ALTA VAL SUSA & CHISONE SKI ITALIA/PIEMONTE/ALPI WELCOME PIACERE DI CONOSCERVI! Le montagne di Torino hanno una delle più estese aree sciistiche di tutte le Alpi, conosciuta in tutto il mondo per la qualità e la quantità dei servizi offerti. In una parola: emozioni. AltaL’ Val Susa e Chisone, teatro degli eventi montani delle Olimpiadi Torino 2006, offre vaste e moderne aree per lo sci e lo snowboard, come Vialattea e Bardonecchia Ski, terreno ideale sia per i principianti che per i più esperti. Gli impianti moderni regalano piste tecniche ai praticanti dello sci alpino ed anche agli amanti dello sci di fondo. I numerosi snowpark offrono salti e trick per sciatori e snowboarder amanti delle acrobazie e del divertimento puro. Maestri e guide alpine possono accompagnarvi su meravigliosi itinerari fuori pista, tra pinete e plateau, in completa sicurezza. Gli amanti della montagna al naturale potranno anche praticare sci alpinismo ed escursionismo con le racchette da neve, sulle vette più selvagge, per godere di panorami mozzafiato. Non potrete mai più fare a meno della neve sotto i piedi! Tutto servito nel migliore stile italiano, per quello che riguarda ospitalità, cucina e cultura, a solo un’ora di treno o di auto dalla città di Torino, una vera meraviglia per monumenti, storia, cultura e stile di vita. Le stesse montagne, quando indossano l’abito estivo, si trasformano in un paradiso per gli appassionati delle due ruote, con e senza motore, su asfalto e sui sentieri. Bike park, single-track, strade militari sterrate e colli che fanno la storia del Giro d’Italia e del Tour de France ed una ricettività pronta ad accogliervi con tutti i servizi e la flessibilità richiesti da chi si diverte in bici o in moto, dagli atleti alle famiglie. -

Quando I Partigiani Divennero Il Corpo Volontari Della Libertà
Storia Il grande esercito che riunì tutti i combattenti antifascisti Quando i partigiani divennero il Corpo Volontari della Libertà di Andrea Liparoto l 21 marzo 1958 è una data storica 1943 quando il Comitato di Liberazione per i partigiani. Quel giorno, infatti, Nazionale di Milano decide di istituire I venne approvata la legge n. 285 che un Comitato Militare, rappresentativo di al comma 1 così recitava: «Il Corpo Vo- tutti i partiti antifascisti, per coordinare lontari della Libertà (CVL) è riconosciu- al meglio l’attività delle bande. A fare da to, ad ogni effetto di legge, come Corpo guida è Ferruccio Parri, esponente del 50 anni fa militare organizzato inquadrato nelle Partito d’Azione, già protagonista di im- il riconoscimento Forze armate dello Stato, per l’attività portanti operazioni militari nella Prima svolta fin all’insediamento del Governo guerra mondiale, figura di spicco nel dello Stato. militare alleato nelle singole località». quadro della storia democratica del no- I dirigenti Un provvedimento di grande importan- stro Paese. Ha carattere da vendere, è un dei primi giorni za, poiché confermava e stabiliva defini- accentratore e queste qualità non tarde- e i contrasti politici. tivamente che la Resistenza, nel trava- ranno a procurare beghe al neonato or- Poi la lotta comune gliato processo di Liberazione, era stata ganismo. Il Comitato si mette subito al e la vittoria. una preziosa comprimaria, responsabile e lavoro e comincia ad affrontare i nodi organizzata: aveva dato, come si sa, alla più spinosi: la mancanza di fondi e di ar- L’alto prezzo pagato lotta contro il nazifascismo migliaia e mi. -

ISSN: 1647-0818 Lingua
lingua Volume 12, Número 2 (2020) ISSN: 1647-0818 lingua Volume 12, N´umero 2 { 2020 Linguamatica´ ISSN: 1647{0818 Editores Alberto Sim~oes Jos´eJo~aoAlmeida Xavier G´omezGuinovart Conteúdo Artigos de Investiga¸c~ao Adapta¸c~aoLexical Autom´atica em Textos Informativos do Portugu^esBrasileiro para o Ensino Fundamental Nathan Siegle Hartmann & Sandra Maria Alu´ısio .................3 Avaliando entidades mencionadas na cole¸c~ao ELTeC-por Diana Santos, Eckhard Bick & Marcin Wlodek ................... 29 Avalia¸c~aode recursos computacionais para o portugu^es Matilde Gon¸calves, Lu´ısaCoheur, Jorge Baptista & Ana Mineiro ........ 51 Projetos, Apresentam-se! Aplicaci´onde WordNet e de word embeddings no desenvolvemento de proto- tipos para a xeraci´onautom´atica da lingua Mar´ıaJos´eDom´ınguezV´azquez ........................... 71 Editorial Ainda h´apouco public´avamosa primeira edi¸c~aoda Linguam´atica e, subitamente, eis-nos a comemorar uma d´uziade anos. A todos os que colaboraram durante todos estes anos, tenham sido leitores, autores ou revisores, a todos o nosso muito obrigado. N~ao´ef´acilmanter um projeto destes durante tantos anos, sem qualquer financi- amento. Todo este sucesso ´egra¸cas a trabalho volunt´ario de todos, o que nos permite ter artigos de qualidade publicados e acess´ıveisgratuitamente a toda a comunidade cient´ıfica. Nestes doze anos muitos foram os que nos acompanharam, nomeadamente na comiss~aocient´ıfica. Alguns dos primeiros membros, convidados em 2008, continuam ativamente a participar neste projeto, realizando revis~oesapuradas. Outros, por via do seu percurso acad´emico e pessoal, j´an~aocolaboram connosco. Como sinal de agradecimento temos mantido os seus nomes na publica¸c~ao. -

Torino Olympic Winter Games Official Report Volume
Rapporto di Sostenibilità_2006 Sustainability Report_2006 XX Giochi Olimpici invernali -XX Olympic Winter Games Torino 2006 Il Rapporto di Sostenibilità_2006 è un progetto della Direzione Ambiente del Comitato per l'Organizzazione dei XX Giochi Olimpici Invernali Torino 2006, Benedetta Ciampi, Giuseppe Feola, Paolo Revellino (Responsabile di Progetto). Il Documento è stato realizzato in collaborazione con l'Istituto dì Economìa e Politica dell'Energia e dell'Ambiente dell'Università Commerciale Luigi Bocconi ed ERM Italia. ©Torino 2006. Non è ammessa alcuna riproduzione parziale della seguente pubblicazione, salvo approvazione per iscritto del TOROC. Tutti i diritti riservati. Novembre 2006. The Susta inability Report__2006 is a project by the Environment Department of the Organising Committee for the XX Olympic Winter Games Torino 2006. Benedetta Ciampi, Giuseppe Feola, Paolo Revellino (Project Manager). The Document has been realised with the support of the "Istituto di Economia e Politica dell' Energia e dell'Ambiente dell'Università Commerciale Luigi Bocconi " and ERM Italia. ©Torino 2006. No part of this publication may be reproduced in any form without prior-written permission of TOROC . All rights reserved. Novembre 2006. La versione stampata di questo prodotto è stata realizzata su carta Cyclus, certificata Ecolabel (licenza DK/11/1). Cyclus è una carta realizzata impiegando interamente fibre riciclate (100% Riciclato). Nulla di ciò che viene utilizzato nel processo produttivo viene eliminato e anche gii scarti provenienti dalla lavorazione sono a loro volta riutilizzati per la combustione, la produzione di fertilizzanti e di materiali per l'edilizia. La carta Cyclus è sbiancata senza uso di sbiancanti ottici e cloro. The printed version of this product has been realised on Cyclus paper, Ecolabel (licence DK/11/1) certified. -

Progetto Preliminare
Comune di Inverso Pinasca Verifiche di compatibilità idraulica da effettuarsi ai sensi dell’art. 18 comma 2 della Deliberazione n. 1/99 dell’Autorità di Bacino per i Comuni inseriti nelle classi di rischio R2 ed R3 REGIONE PIEMONTE PROVINCIA DI TORINO COMUNITA’ MONTANA VALLI CHISONE GERMANASCA PELLICE PINEROLESE PEDEMONTANO VERIFICHE DI COMPATIBILITA’ IDRAULICA DA EFFETTUARSI AI SENSI DELL’ART. 18 COMMA 2 DELLA DELIBERAZIONE N. 1/99 DELL’AUTORITA’ DI BACINO PER I COMUNI INSERITI NELLE CLASSI DI RISCHIO R2 ED R3 MEDIA VAL CHISONE COMUNE DI INVERSO PINASCA: STUDIO DELLA DINAMICA IDRAULICA DI FONDOVALLE NELLE AREE DI FLECCIA, PIANI E GRANGE Indice: 1 PREMESSA ............................................................................................................................. 3 2 ANALISI GEOLOGICA - MORFOLOGICA ............................................................................... 3 2.1 INQUADRAMENTO TERRITORIALE ............................................................................... 3 2.2 ASSETTO GEOLOGICO E GEOMORFOLOGICO ........................................................... 4 2.2.1 INQUADRAMENTO GEOLOGICO ............................................................................ 4 2.2.2 CARATTERI GEOMORFOLOGICI ............................................................................ 5 2.2.3 SEGNALAZIONI DI DISSESTO TRATTE DALLE BANCHE DATI ............................. 6 2.2.3.1 Archivio IFFI ....................................................................................................... 6 2.2.3.2 -

Thesis Submission
Rebuilding a Culture: Studies in Italian Music after Fascism, 1943-1953 Peter Roderick PhD Music Department of Music, University of York March 2010 Abstract The devastation enacted on the Italian nation by Mussolini’s ventennio and the Second World War had cultural as well as political effects. Combined with the fading careers of the leading generazione dell’ottanta composers (Alfredo Casella, Gian Francesco Malipiero and Ildebrando Pizzetti), it led to a historical moment of perceived crisis and artistic vulnerability within Italian contemporary music. Yet by 1953, dodecaphony had swept the artistic establishment, musical theatre was beginning a renaissance, Italian composers featured prominently at the Darmstadt Ferienkurse , Milan was a pioneering frontier for electronic composition, and contemporary music journals and concerts had become major cultural loci. What happened to effect these monumental stylistic and historical transitions? In addressing this question, this thesis provides a series of studies on music and the politics of musical culture in this ten-year period. It charts Italy’s musical journey from the cultural destruction of the post-war period to its role in the early fifties within the meteoric international rise of the avant-garde artist as institutionally and governmentally-endorsed superman. Integrating stylistic and aesthetic analysis within a historicist framework, its chapters deal with topics such as the collective memory of fascism, internationalism, anti- fascist reaction, the appropriation of serialist aesthetics, the nature of Italian modernism in the ‘aftermath’, the Italian realist/formalist debates, the contradictory politics of musical ‘commitment’, and the growth of a ‘new-music’ culture. In demonstrating how the conflict of the Second World War and its diverse aftermath precipitated a pluralistic and increasingly avant-garde musical society in Italy, this study offers new insights into the transition between pre- and post-war modernist aesthetics and brings musicological focus onto an important but little-studied era. -

On the Role of Thematic Roles in a Historical Event Ontology
AperTO - Archivio Istituzionale Open Access dell'Università di Torino On the role of thematic roles in a historical event ontology This is the author's manuscript Original Citation: Availability: This version is available http://hdl.handle.net/2318/1660625 since 2018-11-23T15:38:21Z Published version: DOI:10.3233/AO-170192 Terms of use: Open Access Anyone can freely access the full text of works made available as "Open Access". Works made available under a Creative Commons license can be used according to the terms and conditions of said license. Use of all other works requires consent of the right holder (author or publisher) if not exempted from copyright protection by the applicable law. (Article begins on next page) 02 October 2021 On the role of thematic roles in a historical event ontology * Anna Goy**, Diego Magro and Marco Rovera Università di Torino, Dipartimento di Informatica, Corso Svizzera 185, 10149, Torino, ITALY E-mail: {annamaria.goy, diego.magro, marco.rovera}@unito.it Abstract. In this paper we discuss the issues related to the formal representation of thematic roles in an ontology modeling historical events. We start by analyzing the ontological distinctions between thematic roles and social roles, which suggest different formal representations. Coupling the study of existing approaches with an analysis of historical texts available within the Harlock'900 project we propose a formal representation of thematic roles in HERO (Historical Event Representation Ontology), based on binary properties, directly connecting the event to its participants. Moreover, we show that a fine-grained formal ontological model of participation in (historical) events should include general thematic roles (e.g., agent, patient) able to capture the common aspects of the ways entities are involved in events and event-specific roles (e.g., sniper), introduced in the ontology according to a specific criterion, that guarantees the needed expressivity without proliferating roles.