Decision Summary
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

HIST1H3D: a Promising Therapeutic Target for Lung Cancer
INTERNATIONAL JOURNAL OF ONCOLOGY 50: 815-822, 2017 HIST1H3D: A promising therapeutic target for lung cancer YAN RUI1*, WEN-JIA PENG2*, MING WANG1*, QIAN WANG1*, ZI-LI LIU1, YU-QING CHEN1 and LI-NIAN HUANG1 1Department of Respiration and Critical Care Medicine, The First Affiliated Hospital of Bengbu Medical College, Lung Cancer Diagnosis and Treatment Center of Anhui Province, Anhui Provincial Key Laboratory of Clinical Basic Research on Respiratory Disease, Bengbu, Anhui 233004; 2Department of Epidemiology and Health Statistics, Bengbu Medical College, Bengbu, Anhui 233000, P.R. China Received October 6, 2016; Accepted December 1, 2016 DOI: 10.3892/ijo.2017.3856 Abstract. HIST1H3D gene encodes histone H3.1 and is involved CDKN1 and CCNE2 genes. In conclusion, our results suggest in gene-silencing and heterochromatin formation. HIST1H3D that HIST1H3D is highly expressed in lung cancer cell lines expression is upregulated in primary gastric cancer tissue. In and tissues. Furthermore, HIST1H3D may be important in this study, we explored the effects of HIST1H3D expression cell proliferation, apoptosis and cell cycle progression, and is on lung cancer, and its mechanisms. HIST1H3D expression implicated as a potential therapeutic target for lung cancer. was measured by immunohistochemistry and RT-PCR in lung cancer tissues and human lung cancer cell lines. Cell prolif- Introduction eration was assessed by MTT assay. Flow cytometric analysis was used to determine cell cycle distribution and apoptosis. Lung cancer is one of the most common cancers and the Levels of related proteins were detected by western blotting. major cause of cancer deaths worldwide, with 1.6 million new Bioinformatics analysis was performed to investigate related lung cancer cases and 1.4 million lung cancer deaths each signaling pathways. -

Specific Functions of the Wnt Signaling System in Gene Regulatory Networks
Specific functions of the Wnt signaling system in PNAS PLUS gene regulatory networks throughout the early sea urchin embryo Miao Cui, Natnaree Siriwon1, Enhu Li2, Eric H. Davidson3, and Isabelle S. Peter3 Division of Biology and Biological Engineering, California Institute of Technology, Pasadena, CA 91125 Contributed by Eric H. Davidson, October 9, 2014 (sent for review September 12, 2014; reviewed by Robert D. Burke and Randall T. Moon) Wnt signaling affects cell-fate specification processes throughout Fig. 1A. Cells located at the vegetal pole will become skeleto- embryonic development. Here we take advantage of the well-studied genic mesodermal cells. These cells are surrounded by the veg2 gene regulatory networks (GRNs) that control pregastrular sea urchin cell lineage. This lineage consists of veg2 mesodermal cells, lo- embryogenesis to reveal the gene regulatory functions of the entire cated adjacent to skeletogenic cells and giving rise to all other Wnt-signaling system. Five wnt genes, three frizzled genes, two se- mesodermal cell fates such as esophageal muscle cells, blasto- creted frizzled-related protein 1 genes, and two Dickkopf genes are coelar cells, and pigment cells, and of veg2 endoderm cells, expressed in dynamic spatial patterns in the pregastrular embryo of which will form the foregut and parts of the midgut. At a further Strongylocentrotus purpuratus. We present a comprehensive analysis distance from the vegetal pole, but still within the vegetal half of of these genes in each embryonic domain. Total functions of the the embryo, is the veg1 lineage, consisting of veg1 endoderm, Wnt-signaling system in regulatory gene expression throughout the located adjacent to veg2 endoderm and giving rise to the other embryo were studied by use of the Porcupine inhibitor C59, which parts of the midgut and the hindgut, and of veg1 ectoderm, the interferes with zygotic Wnt ligand secretion. -

Identification of TPD52 and DNAJB1 As Two Novel Bile Biomarkers for Cholangiocarcinoma by Itraq‑Based Quantitative Proteomics Analysis
2622 ONCOLOGY REPORTS 42: 2622-2634, 2019 Identification of TPD52 and DNAJB1 as two novel bile biomarkers for cholangiocarcinoma by iTRAQ‑based quantitative proteomics analysis HONGYUE REN1*, MINGXU LUO2,3*, JINZHONG CHEN4, YANMING ZHOU5, XIUMEI LI4, YANYAN ZHAN6, DONGYAN SHEN7 and BO CHEN3 1Department of Pathology, The Affiliated Southeast Hospital of Xiamen University, Zhangzhou, Fujian 363000; 2Department of Gastrointestinal Surgery, Xiamen Humanity Hospital; Departments of 3Gastrointestinal Surgery, 4Endoscopy Center and 5Hepatopancreatobiliary Surgery, Xiamen Cancer Hospital, The First Affiliated Hospital of Xiamen University, Xiamen Fujian 361003; 6Cancer Research Center, Xiamen University Medical College, Xiamen, Fujian 361002; 7Biobank, Xiamen Cancer Hospital, The First Affiliated Hospital of Xiamen University, Xiamen, Fujian 361003, P.R. China Received December 17, 2018; Accepted September 26, 2019 DOI: 10.3892/or.2019.7387 Abstract. Cholangiocarcinoma (CCA) represents a type of proteins may contribute to tumor pathogenesis. In addition, the epithelial cancer with a late diagnosis and poor outcome. expression levels of TPD52 and DNAJB1 were found to be However, the molecular mechanisms responsible for the devel- closely associated with the clinical parameters and prognosis opment of CCA have not yet been fully identified. Thus, in this of patients with CCA. On the whole, the findings of this study study, we aimed to elucidate some of these mechanisms. For indicate that TPD52 and DNAJB1 may serve as novel bile this purpose, isobaric tags for relative and absolute quantifica- biomarkers for CCA. tion (iTRAQ) was performed to analyze the secretory proteins from the 2 CCA cell lines, TFK1 and HuCCT1, as well as from Introduction a normal biliary epithelial cell line, human intrahepatic biliary epithelial cells (HiBECs). -
![Computational Genome-Wide Identification of Heat Shock Protein Genes in the Bovine Genome [Version 1; Peer Review: 2 Approved, 1 Approved with Reservations]](https://docslib.b-cdn.net/cover/8283/computational-genome-wide-identification-of-heat-shock-protein-genes-in-the-bovine-genome-version-1-peer-review-2-approved-1-approved-with-reservations-88283.webp)
Computational Genome-Wide Identification of Heat Shock Protein Genes in the Bovine Genome [Version 1; Peer Review: 2 Approved, 1 Approved with Reservations]
F1000Research 2018, 7:1504 Last updated: 08 AUG 2021 RESEARCH ARTICLE Computational genome-wide identification of heat shock protein genes in the bovine genome [version 1; peer review: 2 approved, 1 approved with reservations] Oyeyemi O. Ajayi1,2, Sunday O. Peters3, Marcos De Donato2,4, Sunday O. Sowande5, Fidalis D.N. Mujibi6, Olanrewaju B. Morenikeji2,7, Bolaji N. Thomas 8, Matthew A. Adeleke 9, Ikhide G. Imumorin2,10,11 1Department of Animal Breeding and Genetics, Federal University of Agriculture, Abeokuta, Nigeria 2International Programs, College of Agriculture and Life Sciences, Cornell University, Ithaca, NY, 14853, USA 3Department of Animal Science, Berry College, Mount Berry, GA, 30149, USA 4Departamento Regional de Bioingenierias, Tecnologico de Monterrey, Escuela de Ingenieria y Ciencias, Queretaro, Mexico 5Department of Animal Production and Health, Federal University of Agriculture, Abeokuta, Nigeria 6Usomi Limited, Nairobi, Kenya 7Department of Animal Production and Health, Federal University of Technology, Akure, Nigeria 8Department of Biomedical Sciences, Rochester Institute of Technology, Rochester, NY, 14623, USA 9School of Life Sciences, University of KwaZulu-Natal, Durban, 4000, South Africa 10School of Biological Sciences, Georgia Institute of Technology, Atlanta, GA, 30032, USA 11African Institute of Bioscience Research and Training, Ibadan, Nigeria v1 First published: 20 Sep 2018, 7:1504 Open Peer Review https://doi.org/10.12688/f1000research.16058.1 Latest published: 20 Sep 2018, 7:1504 https://doi.org/10.12688/f1000research.16058.1 Reviewer Status Invited Reviewers Abstract Background: Heat shock proteins (HSPs) are molecular chaperones 1 2 3 known to bind and sequester client proteins under stress. Methods: To identify and better understand some of these proteins, version 1 we carried out a computational genome-wide survey of the bovine 20 Sep 2018 report report report genome. -

Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model
Downloaded from http://www.jimmunol.org/ by guest on September 25, 2021 T + is online at: average * The Journal of Immunology , 34 of which you can access for free at: 2016; 197:1477-1488; Prepublished online 1 July from submission to initial decision 4 weeks from acceptance to publication 2016; doi: 10.4049/jimmunol.1600589 http://www.jimmunol.org/content/197/4/1477 Molecular Profile of Tumor-Specific CD8 Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. Waugh, Sonia M. Leach, Brandon L. Moore, Tullia C. Bruno, Jonathan D. Buhrman and Jill E. Slansky J Immunol cites 95 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html http://www.jimmunol.org/content/suppl/2016/07/01/jimmunol.160058 9.DCSupplemental This article http://www.jimmunol.org/content/197/4/1477.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 25, 2021. The Journal of Immunology Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. -
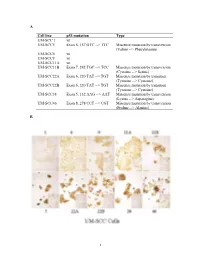
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

DNA Methylation Changes in Down Syndrome Derived Neural Ipscs Uncover Co-Dysregulation of ZNF and HOX3 Families of Transcription
Laan et al. Clinical Epigenetics (2020) 12:9 https://doi.org/10.1186/s13148-019-0803-1 RESEARCH Open Access DNA methylation changes in Down syndrome derived neural iPSCs uncover co- dysregulation of ZNF and HOX3 families of transcription factors Loora Laan1†, Joakim Klar1†, Maria Sobol1, Jan Hoeber1, Mansoureh Shahsavani2, Malin Kele2, Ambrin Fatima1, Muhammad Zakaria1, Göran Annerén1, Anna Falk2, Jens Schuster1 and Niklas Dahl1* Abstract Background: Down syndrome (DS) is characterized by neurodevelopmental abnormalities caused by partial or complete trisomy of human chromosome 21 (T21). Analysis of Down syndrome brain specimens has shown global epigenetic and transcriptional changes but their interplay during early neurogenesis remains largely unknown. We differentiated induced pluripotent stem cells (iPSCs) established from two DS patients with complete T21 and matched euploid donors into two distinct neural stages corresponding to early- and mid-gestational ages. Results: Using the Illumina Infinium 450K array, we assessed the DNA methylation pattern of known CpG regions and promoters across the genome in trisomic neural iPSC derivatives, and we identified a total of 500 stably and differentially methylated CpGs that were annotated to CpG islands of 151 genes. The genes were enriched within the DNA binding category, uncovering 37 factors of importance for transcriptional regulation and chromatin structure. In particular, we observed regional epigenetic changes of the transcription factor genes ZNF69, ZNF700 and ZNF763 as well as the HOXA3, HOXB3 and HOXD3 genes. A similar clustering of differential methylation was found in the CpG islands of the HIST1 genes suggesting effects on chromatin remodeling. Conclusions: The study shows that early established differential methylation in neural iPSC derivatives with T21 are associated with a set of genes relevant for DS brain development, providing a novel framework for further studies on epigenetic changes and transcriptional dysregulation during T21 neurogenesis. -

Download Download
Supplementary Figure S1. Results of flow cytometry analysis, performed to estimate CD34 positivity, after immunomagnetic separation in two different experiments. As monoclonal antibody for labeling the sample, the fluorescein isothiocyanate (FITC)- conjugated mouse anti-human CD34 MoAb (Mylteni) was used. Briefly, cell samples were incubated in the presence of the indicated MoAbs, at the proper dilution, in PBS containing 5% FCS and 1% Fc receptor (FcR) blocking reagent (Miltenyi) for 30 min at 4 C. Cells were then washed twice, resuspended with PBS and analyzed by a Coulter Epics XL (Coulter Electronics Inc., Hialeah, FL, USA) flow cytometer. only use Non-commercial 1 Supplementary Table S1. Complete list of the datasets used in this study and their sources. GEO Total samples Geo selected GEO accession of used Platform Reference series in series samples samples GSM142565 GSM142566 GSM142567 GSM142568 GSE6146 HG-U133A 14 8 - GSM142569 GSM142571 GSM142572 GSM142574 GSM51391 GSM51392 GSE2666 HG-U133A 36 4 1 GSM51393 GSM51394 only GSM321583 GSE12803 HG-U133A 20 3 GSM321584 2 GSM321585 use Promyelocytes_1 Promyelocytes_2 Promyelocytes_3 Promyelocytes_4 HG-U133A 8 8 3 GSE64282 Promyelocytes_5 Promyelocytes_6 Promyelocytes_7 Promyelocytes_8 Non-commercial 2 Supplementary Table S2. Chromosomal regions up-regulated in CD34+ samples as identified by the LAP procedure with the two-class statistics coded in the PREDA R package and an FDR threshold of 0.5. Functional enrichment analysis has been performed using DAVID (http://david.abcc.ncifcrf.gov/) -

Tsrna Signatures in Cancer
tsRNA signatures in cancer Veronica Balattia, Giovanni Nigitaa,1, Dario Venezianoa,1, Alessandra Druscoa, Gary S. Steinb,c, Terri L. Messierb,c, Nicholas H. Farinab,c, Jane B. Lianb,c, Luisa Tomaselloa, Chang-gong Liud, Alexey Palamarchuka, Jonathan R. Harte, Catherine Belle, Mariantonia Carosif, Edoardo Pescarmonaf, Letizia Perracchiof, Maria Diodorof, Andrea Russof, Anna Antenuccif, Paolo Viscaf, Antonio Ciardig, Curtis C. Harrish, Peter K. Vogte, Yuri Pekarskya,2, and Carlo M. Crocea,2 aDepartment of Cancer Biology and Medical Genetics, The Ohio State University Comprehensive Cancer Center, Columbus, OH 43210; bDepartment of Biochemistry, University of Vermont College of Medicine, Burlington, VT 05405; cUniversity of Vermont Cancer Center, College of Medicine, Burlington, VT 05405; dMD Anderson Cancer Center, Houston, TX 77030; eDepartment of Molecular Medicine, The Scripps Research Institute, La Jolla, CA 92037; fIstituto di Ricovero e Cura a Carattere Scientifico, Regina Elena National Cancer Institute, 00144 Rome, Italy; gUniversita’ Di Roma La Sapienza, 00185 Rome, Italy; and hLaboratory of Human Carcinogenesis, Center for Cancer Research, National Cancer Institute, National Institutes of Health, Bethesda, MD 20892 Contributed by Carlo M. Croce, June 13, 2017 (sent for review April 26, 2017; reviewed by Riccardo Dalla-Favera and Philip N. Tsichlis) Small, noncoding RNAs are short untranslated RNA molecules, some these molecules, which we defined as single-stranded small of which have been associated with cancer development. Recently RNAs, 16–48 nt long, ending with a stretch of four Ts (4). When we showed that a class of small RNAs generated during the matu- tsRNAs accumulate in the nucleus, they can be exported, sug- ration process of tRNAs (tRNA-derived small RNAs, hereafter gesting that tsRNAs could regulate gene expression at different “tsRNAs”) is dysregulated in cancer. -

Serum Albumin OS=Homo Sapiens
Protein Name Cluster of Glial fibrillary acidic protein OS=Homo sapiens GN=GFAP PE=1 SV=1 (P14136) Serum albumin OS=Homo sapiens GN=ALB PE=1 SV=2 Cluster of Isoform 3 of Plectin OS=Homo sapiens GN=PLEC (Q15149-3) Cluster of Hemoglobin subunit beta OS=Homo sapiens GN=HBB PE=1 SV=2 (P68871) Vimentin OS=Homo sapiens GN=VIM PE=1 SV=4 Cluster of Tubulin beta-3 chain OS=Homo sapiens GN=TUBB3 PE=1 SV=2 (Q13509) Cluster of Actin, cytoplasmic 1 OS=Homo sapiens GN=ACTB PE=1 SV=1 (P60709) Cluster of Tubulin alpha-1B chain OS=Homo sapiens GN=TUBA1B PE=1 SV=1 (P68363) Cluster of Isoform 2 of Spectrin alpha chain, non-erythrocytic 1 OS=Homo sapiens GN=SPTAN1 (Q13813-2) Hemoglobin subunit alpha OS=Homo sapiens GN=HBA1 PE=1 SV=2 Cluster of Spectrin beta chain, non-erythrocytic 1 OS=Homo sapiens GN=SPTBN1 PE=1 SV=2 (Q01082) Cluster of Pyruvate kinase isozymes M1/M2 OS=Homo sapiens GN=PKM PE=1 SV=4 (P14618) Glyceraldehyde-3-phosphate dehydrogenase OS=Homo sapiens GN=GAPDH PE=1 SV=3 Clathrin heavy chain 1 OS=Homo sapiens GN=CLTC PE=1 SV=5 Filamin-A OS=Homo sapiens GN=FLNA PE=1 SV=4 Cytoplasmic dynein 1 heavy chain 1 OS=Homo sapiens GN=DYNC1H1 PE=1 SV=5 Cluster of ATPase, Na+/K+ transporting, alpha 2 (+) polypeptide OS=Homo sapiens GN=ATP1A2 PE=3 SV=1 (B1AKY9) Fibrinogen beta chain OS=Homo sapiens GN=FGB PE=1 SV=2 Fibrinogen alpha chain OS=Homo sapiens GN=FGA PE=1 SV=2 Dihydropyrimidinase-related protein 2 OS=Homo sapiens GN=DPYSL2 PE=1 SV=1 Cluster of Alpha-actinin-1 OS=Homo sapiens GN=ACTN1 PE=1 SV=2 (P12814) 60 kDa heat shock protein, mitochondrial OS=Homo -

Neddylation: a Novel Modulator of the Tumor Microenvironment Lisha Zhou1,2*†, Yanyu Jiang3†, Qin Luo1, Lihui Li1 and Lijun Jia1*
Zhou et al. Molecular Cancer (2019) 18:77 https://doi.org/10.1186/s12943-019-0979-1 REVIEW Open Access Neddylation: a novel modulator of the tumor microenvironment Lisha Zhou1,2*†, Yanyu Jiang3†, Qin Luo1, Lihui Li1 and Lijun Jia1* Abstract Neddylation, a post-translational modification that adds an ubiquitin-like protein NEDD8 to substrate proteins, modulates many important biological processes, including tumorigenesis. The process of protein neddylation is overactivated in multiple human cancers, providing a sound rationale for its targeting as an attractive anticancer therapeutic strategy, as evidence by the development of NEDD8-activating enzyme (NAE) inhibitor MLN4924 (also known as pevonedistat). Neddylation inhibition by MLN4924 exerts significantly anticancer effects mainly by triggering cell apoptosis, senescence and autophagy. Recently, intensive evidences reveal that inhibition of neddylation pathway, in addition to acting on tumor cells, also influences the functions of multiple important components of the tumor microenvironment (TME), including immune cells, cancer-associated fibroblasts (CAFs), cancer-associated endothelial cells (CAEs) and some factors, all of which are crucial for tumorigenesis. Here, we briefly summarize the latest progresses in this field to clarify the roles of neddylation in the TME, thus highlighting the overall anticancer efficacy of neddylaton inhibition. Keywords: Neddylation, Tumor microenvironment, Tumor-derived factors, Cancer-associated fibroblasts, Cancer- associated endothelial cells, Immune cells Introduction Overall, binding of NEDD8 molecules to target proteins Neddylation is a reversible covalent conjugation of an can affect their stability, subcellular localization, conform- ubiquitin-like molecule NEDD8 (neuronal precursor ation and function [4]. The best-characterized substrates cell-expressed developmentally down-regulated protein of neddylation are the cullin subunits of Cullin-RING li- 8) to a lysine residue of the substrate protein [1, 2]. -

Snf2h-Mediated Chromatin Organization and Histone H1 Dynamics Govern Cerebellar Morphogenesis and Neural Maturation
ARTICLE Received 12 Feb 2014 | Accepted 15 May 2014 | Published 20 Jun 2014 DOI: 10.1038/ncomms5181 OPEN Snf2h-mediated chromatin organization and histone H1 dynamics govern cerebellar morphogenesis and neural maturation Matı´as Alvarez-Saavedra1,2, Yves De Repentigny1, Pamela S. Lagali1, Edupuganti V.S. Raghu Ram3, Keqin Yan1, Emile Hashem1,2, Danton Ivanochko1,4, Michael S. Huh1, Doo Yang4,5, Alan J. Mears6, Matthew A.M. Todd1,4, Chelsea P. Corcoran1, Erin A. Bassett4, Nicholas J.A. Tokarew4, Juraj Kokavec7, Romit Majumder8, Ilya Ioshikhes4,5, Valerie A. Wallace4,6, Rashmi Kothary1,2, Eran Meshorer3, Tomas Stopka7, Arthur I. Skoultchi8 & David J. Picketts1,2,4 Chromatin compaction mediates progenitor to post-mitotic cell transitions and modulates gene expression programs, yet the mechanisms are poorly defined. Snf2h and Snf2l are ATP-dependent chromatin remodelling proteins that assemble, reposition and space nucleosomes, and are robustly expressed in the brain. Here we show that mice conditionally inactivated for Snf2h in neural progenitors have reduced levels of histone H1 and H2A variants that compromise chromatin fluidity and transcriptional programs within the developing cerebellum. Disorganized chromatin limits Purkinje and granule neuron progenitor expansion, resulting in abnormal post-natal foliation, while deregulated transcriptional programs contribute to altered neural maturation, motor dysfunction and death. However, mice survive to young adulthood, in part from Snf2l compensation that restores Engrailed-1 expression. Similarly, Purkinje-specific Snf2h ablation affects chromatin ultrastructure and dendritic arborization, but alters cognitive skills rather than motor control. Our studies reveal that Snf2h controls chromatin organization and histone H1 dynamics for the establishment of gene expression programs underlying cerebellar morphogenesis and neural maturation.