Localization and Internationalization Unicode TEX Pdftex Luatex Xetex
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Survey of Orthographic Information in Machine Translation 3
Machine Translation Journal manuscript No. (will be inserted by the editor) A Survey of Orthographic Information in Machine Translation Bharathi Raja Chakravarthi1 ⋅ Priya Rani 1 ⋅ Mihael Arcan2 ⋅ John P. McCrae 1 the date of receipt and acceptance should be inserted later Abstract Machine translation is one of the applications of natural language process- ing which has been explored in different languages. Recently researchers started pay- ing attention towards machine translation for resource-poor languages and closely related languages. A widespread and underlying problem for these machine transla- tion systems is the variation in orthographic conventions which causes many issues to traditional approaches. Two languages written in two different orthographies are not easily comparable, but orthographic information can also be used to improve the machine translation system. This article offers a survey of research regarding orthog- raphy’s influence on machine translation of under-resourced languages. It introduces under-resourced languages in terms of machine translation and how orthographic in- formation can be utilised to improve machine translation. We describe previous work in this area, discussing what underlying assumptions were made, and showing how orthographic knowledge improves the performance of machine translation of under- resourced languages. We discuss different types of machine translation and demon- strate a recent trend that seeks to link orthographic information with well-established machine translation methods. Considerable attention is given to current efforts of cog- nates information at different levels of machine translation and the lessons that can Bharathi Raja Chakravarthi [email protected] Priya Rani [email protected] Mihael Arcan [email protected] John P. -

From Arabic Style Toward Javanese Style: Comparison Between Accents of Javanese Recitation and Arabic Recitation
From Arabic Style toward Javanese Style: Comparison between Accents of Javanese Recitation and Arabic Recitation Nur Faizin1 Abstract Moslem scholars have acceptedmaqamat in reciting the Quran otherwise they have not accepted macapat as Javanese style in reciting the Quran such as recitationin the State Palace in commemoration of Isra` Miraj 2015. The paper uses a phonological approach to accents in Arabic and Javanese style in recitingthe first verse of Surah Al-Isra`. Themethod used here is analysis of suprasegmental sound (accent) by usingSpeech Analyzer programand the comparison of these accents is analyzed by descriptive method. By doing so, the author found that:first, there is not any ideological reason to reject Javanese style because both of Arabic and Javanese style have some aspects suitable and unsuitable with Ilm Tajweed; second, the suitability of Arabic style was muchthan Javanese style; third, it is not right to reject recitingthe Quran with Javanese style only based on assumption that it evokedmistakes and errors; fourth, the acceptance of Arabic style as the art in reciting the Quran should risedacceptanceof the Javanese stylealso. So, rejection of reciting the Quranwith Javanese style wasnot due to any reason and it couldnot be proofed by any logical argument. Keywords: Recitation, Arabic Style, Javanese Style, Quran. Introduction There was a controversial event in commemoration of Isra‘ Mi‘raj at the State Palacein Jakarta May 15, 2015 ago. The recitation of the Quran in the commemoration was recitedwithJavanese style (langgam).That was not common performance in relation to such as official event. Muhammad 58 Nur Faizin, From Arabic Style toward Javanese Style Yasser Arafat, a lecture of Sunan Kalijaga State Islamic University Yogyakarta has been reciting first verse of Al-Isra` by Javanese style in the front of state officials and delegationsof many countries. -

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -
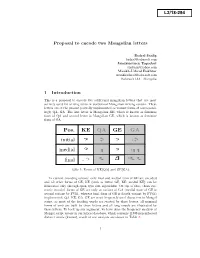
Pos. KE QA GE GA Initial ᠬ ᠭ Medial Final
Proposal to encode two Mongolian letters Badral Sanlig [email protected] Jamiyansuren Togoobat [email protected] Munkh-Uchral Enkhtur [email protected] Bolorsoft LLC, Mongolia 1 Introduction This is a proposal to encode two additional mongolian letters that are most actively used for writing texts in traditional Mongolian writing system. These letters are at the present partially implemented as variant forms of correspond- ingly QA, GA. The first letter is Mongolian KE, which is known as feminine form of QA and second letter is Mongolian GE, which is known as feminine form of GA. Pos. KE QA GE GA ᠬ ᠭ initial medial final - Table 1: Forms of KE(QA) and GE(GA). In current encoding scheme, only final and medial form of GE are encoded and all other forms of GE, KE (such as initial GE, KE, medial KE) can be illustrated only through open type font algorithms. On top of that, those cur- rently encoded forms of GE are only as variant of GA (medial form of GE is second variant by FVS1, whereas final form of GE is fourth variant by FVS3) implemented. QA, KE, GA, GE are most frequently used characters in Mongol script, as most of the heading words are started by these letters, all nominal forms of verb are built by these letters and all long vowels are illustrated by these letters. To back up our argument, we have done the frequency analysis of Mongol script letters in our lexical database, which contains 41808 non-inflected distinct words (lemma), result of our analysis are shown in Table 2. -

Kopik Type Family
Kopik Type Family Kopik is a modern hand-drawn script inspired by the 1960’s architectural handwriting style practised by draftsmen. Originated using a Copic 1.0 Multiliner pen, then traced digitally using a stylus and tablet to help reduce imperfections. The result is a simple, readable, monolinear typeface with a marker pen quality suitable for a wide range of applications. RELEASED OPENTYPE FEATURES SUPPORTED LANGUAGES 2021 PROPORTIONAL FIGURES AFRIKAANS, ALBANIAN, ASU, BASQUE, TABULAR FIGURES BEMBA, BENA, BOSNIAN, CATALAN, DESIGNER NUMERATORS & DENOMINATORS CHIGA, COLOGNIAN, CORNISH, CROATIAN, JONATHAN HILL SUPERSCRIPT & SUBSCRIPT CZECH, DANISH, DUTCH, EMBU, ENGLISH, STANDARD FRACTIONS ESPERANTO, ESTONIAN, FAROESE, FILIPINO, 6 STYLES NUT FRACTIONS FINNISH, FRENCH, FRIULIAN, GALICIAN, 3 WEIGHTS + ITALICS SLASHED ZERO GANDA, GERMAN, GERMAN (SWITZERLAND), CASE-SENSITIVE FIGURES GUSII, HUNGARIAN, ICELANDIC, INARI SAMI, CLASSIFICATION CASE-SENSITIVE FORMS INDONESIAN, IRISH, ITALIAN, JOLA-FONYI, HAND-DRAWN SCRIPT STYLISTIC ALTERNATES KABUVERDIANU, KALENJIN, KAMBA, KIKUYU, STYLISTIC SETS KINYARWANDA, LATVIAN, LITHUANIAN, FORMAT STANDARD LIGATURES LOW GERMAN, LOWER SORBIAN, LUO, OTF, TTF, WOFF, WOFF 2, SVG, EOT DISCRETIONARY LIGATURES LUXEMBOURGISH, LUYIA, MACHAME, EXTENDED LATIN MAKHUWA-MEETTO, MAKONDE, MALAGASY, GLYPHS MALAY, MALTESE, MANX, MAORI, MERU, 440 PER FONT MORISYEN, NORTH NDEBELE, NORTHERN SAMI, NORWEGIAN BOKMÅL, NORWEGIAN NYNORSK, NYANKOLE, OROMO, POLISH, PORTUGUESE, ROMANIAN, ROMANSH, ROMBO, RUNDI, RWA, SAMBURU, SANGO, SANGU, -

DCSA API Design Principles 1.0
DCSA API Design Principles 1.0 September 2020 Table of contents Change history ___________________________________________________ 4 Terms, acronyms, and abbreviations _____________________________________ 4 1 Introduction __________________________________________________ 5 1.1 Purpose and scope ________________________________________________ 5 1.2 API characteristics ________________________________________________ 5 1.3 Conventions ____________________________________________________ 6 2 Suitable _____________________________________________________ 6 3 Maintainable __________________________________________________ 6 3.1 JSON _________________________________________________________ 6 3.2 URLs __________________________________________________________ 6 3.3 Collections _____________________________________________________ 6 3.4 Sorting ________________________________________________________ 6 3.5 Pagination______________________________________________________ 7 3.6 Property names __________________________________________________ 8 3.7 Enum values ____________________________________________________ 9 3.8 Arrays _________________________________________________________ 9 3.9 Date and Time properties ___________________________________________ 9 3.10UTF-8 _________________________________________________________ 9 3.11 Query parameters _______________________________________________ 10 3.12 Custom headers ________________________________________________ 10 3.13 Binary data _____________________________________________________ 11 -

Modeling Popularity and Reliability of Sources in Multilingual Wikipedia
information Article Modeling Popularity and Reliability of Sources in Multilingual Wikipedia Włodzimierz Lewoniewski * , Krzysztof W˛ecel and Witold Abramowicz Department of Information Systems, Pozna´nUniversity of Economics and Business, 61-875 Pozna´n,Poland; [email protected] (K.W.); [email protected] (W.A.) * Correspondence: [email protected] Received: 31 March 2020; Accepted: 7 May 2020; Published: 13 May 2020 Abstract: One of the most important factors impacting quality of content in Wikipedia is presence of reliable sources. By following references, readers can verify facts or find more details about described topic. A Wikipedia article can be edited independently in any of over 300 languages, even by anonymous users, therefore information about the same topic may be inconsistent. This also applies to use of references in different language versions of a particular article, so the same statement can have different sources. In this paper we analyzed over 40 million articles from the 55 most developed language versions of Wikipedia to extract information about over 200 million references and find the most popular and reliable sources. We presented 10 models for the assessment of the popularity and reliability of the sources based on analysis of meta information about the references in Wikipedia articles, page views and authors of the articles. Using DBpedia and Wikidata we automatically identified the alignment of the sources to a specific domain. Additionally, we analyzed the changes of popularity and reliability in time and identified growth leaders in each of the considered months. The results can be used for quality improvements of the content in different languages versions of Wikipedia. -

M. Ricklefs an Inventory of the Javanese Manuscript Collection in the British Museum
M. Ricklefs An inventory of the Javanese manuscript collection in the British Museum In: Bijdragen tot de Taal-, Land- en Volkenkunde 125 (1969), no: 2, Leiden, 241-262 This PDF-file was downloaded from http://www.kitlv-journals.nl Downloaded from Brill.com09/29/2021 11:29:04AM via free access AN INVENTORY OF THE JAVANESE MANUSCRIPT COLLECTION IN THE BRITISH MUSEUM* he collection of Javanese manuscripts in the British Museum, London, although small by comparison with collections in THolland and Indonesia, is nevertheless of considerable importance. The Crawfurd collection, forming the bulk of the manuscripts, provides a picture of the types of literature being written in Central Java in the late eighteenth and early nineteenth centuries, a period which Dr. Pigeaud has described as a Literary Renaissance.1 Because they were acquired by John Crawfurd during his residence as an official of the British administration on Java, 1811-1815, these manuscripts have a convenient terminus ad quem with regard to composition. A large number of the items are dated, a further convenience to the research worker, and the dates are seen to cluster in the four decades between AD 1775 and AD 1815. A number of the texts were originally obtained from Pakualam I, who was installed as an independent Prince by the British admini- stration. Some of the manuscripts are specifically said to have come from him (e.g. Add. 12281 and 12337), and a statement in a Leiden University Bah ad from the Pakualaman suggests many other volumes in Crawfurd's collection also derive from this source: Tuwan Mister [Crawfurd] asked to be instructed in adat law, with examples of the Javanese usage. -

The IHO S-100 Standard and E-Navigation Information
e-NAV10/INF/7 e-NAV10 Information paper Agenda item 12 Task Number Author(s) Raphael Malyankar, Jeppesen Jarle Hauge, Norwegian Coastal Administration The IHO S-100 Standard and e-Navigation Information Concept Exploration with Ship Reporting Data and Product Specification 1 SUMMARY The papers describe an exploration in modeling substantially non-geographic maritime information using the S-100 framework, specifically notice of arrival and pilot requests in Norway. The Norwegian Coastal Administration is the National Competent Authority for the European SafeSeaNet (SSN) in Norway and thereby maintains a vessel and voyage reporting system intended for use by commercial marine traffic arriving and departing Norwegian ports. Data used in this system describes vessels, HAZMAT cargo, voyages, and information used in arranging pilotage. Jeppesen and the NCA has developed a product specification (the “NOAPR product specification”) based on the S-100 standard, for a subset of information used in the abovementioned system. The product specification describes the data model for ship reporting and pilot requests. The current version is a “proof-of-concept” intended to explore the development of S-100 compatible data models for non-geographic maritime information. The papers also discuss the use of the Geospatial Information Registry and the NOAPR Model. 1.1 Purpose of the document The product specification [NOAPR] demonstrates the feasibility of modelling ship notice of arrival and pilot requests using the data model compatible with S-100. 2 BACKGROUND The papers are a result of a mutual work between Jeppesen and the Norwegian Coastal Administration within the Interreg project; BLAST (http://www.blast-project.eu/index.php). -

Multilingual Ranking of Wikipedia Articles with Quality and Popularity Assessment in Different Topics
computers Article Multilingual Ranking of Wikipedia Articles with Quality and Popularity Assessment in Different Topics Włodzimierz Lewoniewski * , Krzysztof W˛ecel and Witold Abramowicz Department of Information Systems, Pozna´nUniversity of Economics and Business, 61-875 Pozna´n,Poland * Correspondence: [email protected]; Tel.: +48-(61)-639-27-93 Received: 10 May 2019; Accepted: 13 August 2019; Published: 14 August 2019 Abstract: On Wikipedia, articles about various topics can be created and edited independently in each language version. Therefore, the quality of information about the same topic depends on the language. Any interested user can improve an article and that improvement may depend on the popularity of the article. The goal of this study is to show what topics are best represented in different language versions of Wikipedia using results of quality assessment for over 39 million articles in 55 languages. In this paper, we also analyze how popular selected topics are among readers and authors in various languages. We used two approaches to assign articles to various topics. First, we selected 27 main multilingual categories and analyzed all their connections with sub-categories based on information extracted from over 10 million categories in 55 language versions. To classify the articles to one of the 27 main categories, we took into account over 400 million links from articles to over 10 million categories and over 26 million links between categories. In the second approach, we used data from DBpedia and Wikidata. We also showed how the results of the study can be used to build local and global rankings of the Wikipedia content. -

Germanic Standardizations: Past to Present (Impact: Studies in Language and Society)
<DOCINFO AUTHOR ""TITLE "Germanic Standardizations: Past to Present"SUBJECT "Impact 18"KEYWORDS ""SIZE HEIGHT "220"WIDTH "150"VOFFSET "4"> Germanic Standardizations Impact: Studies in language and society impact publishes monographs, collective volumes, and text books on topics in sociolinguistics. The scope of the series is broad, with special emphasis on areas such as language planning and language policies; language conflict and language death; language standards and language change; dialectology; diglossia; discourse studies; language and social identity (gender, ethnicity, class, ideology); and history and methods of sociolinguistics. General Editor Associate Editor Annick De Houwer Elizabeth Lanza University of Antwerp University of Oslo Advisory Board Ulrich Ammon William Labov Gerhard Mercator University University of Pennsylvania Jan Blommaert Joseph Lo Bianco Ghent University The Australian National University Paul Drew Peter Nelde University of York Catholic University Brussels Anna Escobar Dennis Preston University of Illinois at Urbana Michigan State University Guus Extra Jeanine Treffers-Daller Tilburg University University of the West of England Margarita Hidalgo Vic Webb San Diego State University University of Pretoria Richard A. Hudson University College London Volume 18 Germanic Standardizations: Past to Present Edited by Ana Deumert and Wim Vandenbussche Germanic Standardizations Past to Present Edited by Ana Deumert Monash University Wim Vandenbussche Vrije Universiteit Brussel/FWO-Vlaanderen John Benjamins Publishing Company Amsterdam/Philadelphia TM The paper used in this publication meets the minimum requirements 8 of American National Standard for Information Sciences – Permanence of Paper for Printed Library Materials, ansi z39.48-1984. Library of Congress Cataloging-in-Publication Data Germanic standardizations : past to present / edited by Ana Deumert, Wim Vandenbussche. -

The Thinking of Speaking Issue #27 May /June 2017 Ccooggnnaatteess,, Tteelllliinngg Rreeaall Ffrroomm Ffaakkee More About Cognates Than You Ever Wanted to Know
Parrot Time The Thinking of Speaking Issue #27 May /June 2017 CCooggnnaatteess,, TTeelllliinngg RReeaall ffrroomm FFaakkee More about cognates than you ever wanted to know AA PPeeeekk iinnttoo PPiinnyyiinn The Romaniizatiion of Mandariin Chiinese IInnssppiirraattiioonnaall LLaanngguuaaggee AArrtt Maxiimiilliien Urfer''s piiece speaks to one of our wriiters TThhee LLeeaarrnniinngg MMiinnddsseett Language acquiisiitiion requiires more than study An Art Exhibition That Spoke To Me LLooookk bbeeyyoonndd wwhhaatt yyoouu kknnooww Parrot Time is your connection to languages, linguistics and culture from the Parleremo community. Expand your understanding. Never miss an issue. 2 Parrot Time | Issue#27 | May/June2017 Contents Parrot Time Parrot Time is a magazine covering language, linguistics Features and culture of the world around us. 8 More About Cognates Than You Ever Wanted to Know It is published by Scriveremo Languages interact with each other, sharing aspects of Publishing, a division of grammar, writing, and vocabulary. However, coincidences also Parleremo, the language learning create words which only looked related. John C. Rigdon takes a community. look at these true and false cognates, and more. Join Parleremo today. Learn a language, make friends, have fun. 1 6 A Peek into Pinyin Languages with non-Latin alphabets are often a major concern for language learners. The process of converting a non-Latin alphabet into something familiar is called "Romanization", and Tarja Jolma looks at how this was done for Mandarin Chinese. 24 An Art Exhibition That Spoke To Me Editor: Erik Zidowecki Inspiration is all around us, often crossing mediums. Olivier Email: [email protected] Elzingre reveals how a performance piece affected his thinking of languages.