UC Berkeley Proposals from the Script Encoding Initiative
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Research Brief March 2017 Publication #2017-16
Research Brief March 2017 Publication #2017-16 Flourishing From the Start: What Is It and How Can It Be Measured? Kristin Anderson Moore, PhD, Child Trends Christina D. Bethell, PhD, The Child and Adolescent Health Measurement Introduction Initiative, Johns Hopkins Bloomberg School of Every parent wants their child to flourish, and every community wants its Public Health children to thrive. It is not sufficient for children to avoid negative outcomes. Rather, from their earliest years, we should foster positive outcomes for David Murphey, PhD, children. Substantial evidence indicates that early investments to foster positive child development can reap large and lasting gains.1 But in order to Child Trends implement and sustain policies and programs that help children flourish, we need to accurately define, measure, and then monitor, “flourishing.”a Miranda Carver Martin, BA, Child Trends By comparing the available child development research literature with the data currently being collected by health researchers and other practitioners, Martha Beltz, BA, we have identified important gaps in our definition of flourishing.2 In formerly of Child Trends particular, the field lacks a set of brief, robust, and culturally sensitive measures of “thriving” constructs critical for young children.3 This is also true for measures of the promotive and protective factors that contribute to thriving. Even when measures do exist, there are serious concerns regarding their validity and utility. We instead recommend these high-priority measures of flourishing -

Dubrovnik Manuscripts and Fragments Written In
Rozana Vojvoda DALMATIAN ILLUMINATED MANUSCRIPTS WRITTEN IN BENEVENTAN SCRIPT AND BENEDICTINE SCRIPTORIA IN ZADAR, DUBROVNIK AND TROGIR PhD Dissertation in Medieval Studies (Supervisor: Béla Zsolt Szakács) Department of Medieval Studies Central European University BUDAPEST April 2011 CEU eTD Collection TABLE OF CONTENTS 1. INTRODUCTION ........................................................................................................................... 7 1.1. Studies of Beneventan script and accompanying illuminations: examples from North America, Canada, Italy, former Yugoslavia and Croatia .................................................................................. 7 1.2. Basic information on the Beneventan script - duration and geographical boundaries of the usage of the script, the origin and the development of the script, the Monte Cassino and Bari type of Beneventan script, dating the Beneventan manuscripts ................................................................... 15 1.3. The Beneventan script in Dalmatia - questions regarding the way the script was transmitted from Italy to Dalmatia ............................................................................................................................ 21 1.4. Dalmatian Benedictine scriptoria and the illumination of Dalmatian manuscripts written in Beneventan script – a proposed methodology for new research into the subject .............................. 24 2. ZADAR MANUSCRIPTS AND FRAGMENTS WRITTEN IN BENEVENTAN SCRIPT ............ 28 2.1. Introduction -
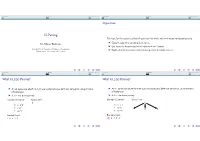
LL Parsing Objectives What Is LL(N) Parsing? What Is LL(N
Introduction LL Parsing Breaking LL Parsers Introduction LL Parsing Breaking LL Parsers Objectives LL Parsing The topic for this lecture is a kind of grammar that works well with recursive-descent parsing. Classify a grammar as being LL or not LL. Dr. Mattox Beckman I I Use recursive-descent parsing to implement an LL parser. University of Illinois at Urbana-Champaign Explain how left-recursion and common prefixes defeat LL parsers. Department of Computer Science I Introduction LL Parsing Breaking LL Parsers Introduction LL Parsing Breaking LL Parsers What Is LL(n) Parsing? What Is LL(n) Parsing? I An LL parse uses a Left-to-right scan and produces a Leftmost derivation, using n tokens I An LL parse uses a Left-to-right scan and produces a Leftmost derivation, using n tokens of lookahead. of lookahead. I A.k.a. top-down parsing I A.k.a. top-down parsing Example Grammar: Syntax Tree: Example Grammar: Syntax Tree: S S S + EE S + EE → → E int E int → + E E E→ EE E EE →∗ →∗ Example Input: Example Input: + 2 * 3 4 + 2 * 3 4 Introduction LL Parsing Breaking LL Parsers Introduction LL Parsing Breaking LL Parsers What Is LL(n) Parsing? What Is LL(n) Parsing? I An LL parse uses a Left-to-right scan and produces a Leftmost derivation, using n tokens I An LL parse uses a Left-to-right scan and produces a Leftmost derivation, using n tokens of lookahead. of lookahead. I A.k.a. top-down parsing I A.k.a. top-down parsing Example Grammar: Syntax Tree: Example Grammar: Syntax Tree: S S S + EE S + EE → → E int + E E E int + E E E→ EE E→ EE →∗ →∗ Example Input: 2 Example Input: 2 * E E + 2 * 3 4 + 2 * 3 4 Introduction LL Parsing Breaking LL Parsers Introduction LL Parsing Breaking LL Parsers What Is LL(n) Parsing? What Is LL(n) Parsing? I An LL parse uses a Left-to-right scan and produces a Leftmost derivation, using n tokens I An LL parse uses a Left-to-right scan and produces a Leftmost derivation, using n tokens of lookahead. -

Roman Numerals
History of Numbers 1c. I can distinguish between an additive and positional system, and convert between Roman and Hindu-Arabic numbers. Roman Numerals The numeric system represented by Roman numerals originated in ancient Rome (753 BC–476 AD) and remained the usual way of writing numbers throughout Europe well into the Late Middle Ages. By the 11th century, the more efJicient Hindu–Arabic numerals had been introduced into Europe by way of Arab traders. Roman numerals, however, remained in commo use well into the 14th and 15th centuries, even in accounting and other business records (where the actual calculations would have been made using an abacus). Roman numerals are still used today, in certain contexts. See: Modern Uses of Roman Numerals Numbers in this system are represented by combinations of letters from the Latin alphabet. Roman numerals, as used today, are based on seven symbols: The numbers 1 to 10 are expressed in Roman numerals as: I, II, III, IV, V, VI, VII, VIII, IX, X. This an additive system. Numbers are formed by combining symbols and adding together their values. For example, III is three (three ones) and XIII is thirteen (a ten plus three ones). Because each symbol (I, V, X ...) has a Jixed value rather than representing multiples of ten, one hundred and so on (according to the numeral's position) there is no need for “place holding” zeros, as in numbers like 207 or 1066. Using Roman numerals, those numbers are written as CCVII (two hundreds, plus a ive and two ones) and MLXVI (a thousand plus a ifty plus a ten, a ive and a one). -

8 December 2004 (Revised 10 January 2005) Topic: Unicode Technical Meeting #101, 15 -18 November 2004, Cupertino, California
To: LSA and UC Berkeley Communities From: Deborah Anderson, UCB representative and LSA liaison Date: 8 December 2004 (revised 10 January 2005) Topic: Unicode Technical Meeting #101, 15 -18 November 2004, Cupertino, California As the UC Berkeley representative and LSA liaison, I am most interested in the proposals for new characters and scripts that were discussed at the UTC, so these topics are the focus of this report. For the full minutes, readers should consult the "Unicode Technical Committee Minutes" web page (http://www.unicode.org/consortum/utc-minutes.html), where the minutes from this meeting will be posted several weeks hence. I. Proposals for New Scripts and Additional Characters A summary of the proposals and the UTC's decisions are listed below. As the proposals discussed below are made public, I will post the URLs on the SEI web page (www.linguistics.berkeley.edu/sei). A. Linguistics Characters Lorna Priest of SIL International submitted three proposals for additional linguistics characters. Most of the characters proposed are used in the orthographies of languages from Africa, Asia, Mexico, Central and South America. (For details on the proposed characters, with a description of their use and an image, see the appendix to this document.) Two characters from these proposals were not approved by the UTC because there are already characters encoded that are very similar. The evidence did not adequately demonstrate that the proposed characters are used distinctively. The two problematical proposed characters were: the modifier straight letter apostrophe (used for a glottal stop, similar to ' APOSTROPHE U+0027) and the Latin small "at" sign (used for Arabic loanwords in an orthography for the Koalib language from the Sudan, similar to @ COMMERCIAL AT U+0040). -

The Unicode Standard, Version 6.1 This File Contains an Excerpt from the Character Code Tables and List of Character Names for the Unicode Standard, Version 6.1
Latin Extended-D Range: A720–A7FF The Unicode Standard, Version 6.1 This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 6.1. Characters in this chart that are new for The Unicode Standard, Version 6.1 are shown in conjunction with any existing characters. For ease of reference, the new characters have been highlighted in the chart grid and in the names list. This file will not be updated with errata, or when additional characters are assigned to the Unicode Standard. See http://www.unicode.org/errata/ for an up-to-date list of errata. See http://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See http://www.unicode.org/charts/PDF/Unicode-6.1/ for charts showing only the characters added in Unicode 6.1. See http://www.unicode.org/Public/6.1.0/charts/ for a complete archived file of character code charts for Unicode 6.1. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 6.1 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 6.1, online at http://www.unicode.org/versions/Unicode6.1.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, and #44, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. -

ISO Basic Latin Alphabet
ISO basic Latin alphabet The ISO basic Latin alphabet is a Latin-script alphabet and consists of two sets of 26 letters, codified in[1] various national and international standards and used widely in international communication. The two sets contain the following 26 letters each:[1][2] ISO basic Latin alphabet Uppercase Latin A B C D E F G H I J K L M N O P Q R S T U V W X Y Z alphabet Lowercase Latin a b c d e f g h i j k l m n o p q r s t u v w x y z alphabet Contents History Terminology Name for Unicode block that contains all letters Names for the two subsets Names for the letters Timeline for encoding standards Timeline for widely used computer codes supporting the alphabet Representation Usage Alphabets containing the same set of letters Column numbering See also References History By the 1960s it became apparent to thecomputer and telecommunications industries in the First World that a non-proprietary method of encoding characters was needed. The International Organization for Standardization (ISO) encapsulated the Latin script in their (ISO/IEC 646) 7-bit character-encoding standard. To achieve widespread acceptance, this encapsulation was based on popular usage. The standard was based on the already published American Standard Code for Information Interchange, better known as ASCII, which included in the character set the 26 × 2 letters of the English alphabet. Later standards issued by the ISO, for example ISO/IEC 8859 (8-bit character encoding) and ISO/IEC 10646 (Unicode Latin), have continued to define the 26 × 2 letters of the English alphabet as the basic Latin script with extensions to handle other letters in other languages.[1] Terminology Name for Unicode block that contains all letters The Unicode block that contains the alphabet is called "C0 Controls and Basic Latin". -

Germanic Standardizations: Past to Present (Impact: Studies in Language and Society)
<DOCINFO AUTHOR ""TITLE "Germanic Standardizations: Past to Present"SUBJECT "Impact 18"KEYWORDS ""SIZE HEIGHT "220"WIDTH "150"VOFFSET "4"> Germanic Standardizations Impact: Studies in language and society impact publishes monographs, collective volumes, and text books on topics in sociolinguistics. The scope of the series is broad, with special emphasis on areas such as language planning and language policies; language conflict and language death; language standards and language change; dialectology; diglossia; discourse studies; language and social identity (gender, ethnicity, class, ideology); and history and methods of sociolinguistics. General Editor Associate Editor Annick De Houwer Elizabeth Lanza University of Antwerp University of Oslo Advisory Board Ulrich Ammon William Labov Gerhard Mercator University University of Pennsylvania Jan Blommaert Joseph Lo Bianco Ghent University The Australian National University Paul Drew Peter Nelde University of York Catholic University Brussels Anna Escobar Dennis Preston University of Illinois at Urbana Michigan State University Guus Extra Jeanine Treffers-Daller Tilburg University University of the West of England Margarita Hidalgo Vic Webb San Diego State University University of Pretoria Richard A. Hudson University College London Volume 18 Germanic Standardizations: Past to Present Edited by Ana Deumert and Wim Vandenbussche Germanic Standardizations Past to Present Edited by Ana Deumert Monash University Wim Vandenbussche Vrije Universiteit Brussel/FWO-Vlaanderen John Benjamins Publishing Company Amsterdam/Philadelphia TM The paper used in this publication meets the minimum requirements 8 of American National Standard for Information Sciences – Permanence of Paper for Printed Library Materials, ansi z39.48-1984. Library of Congress Cataloging-in-Publication Data Germanic standardizations : past to present / edited by Ana Deumert, Wim Vandenbussche. -

The Book Art in Croatia Exhibition Catalogue
Book Art in Croatia BOOK ART IN CROATIA National and University Library in Zagreb, Zagreb, 2018 Contents Foreword / 4 Centuries of Book Art in Croatia / 5 Catalogue / 21 Foreword The National and University Library in Croatia, with the aim to present and promote the Croatian cultural heritage has prepared the exhibition Book Art in Croatia. The exhibition gives a historical view of book preparation and design in Croatia from the Middle Ages to the present day. It includes manuscript and printed books on different topics and themes, from mediaeval evangelistaries and missals to contemporary illustrated editions, print portfolios and artists’ books. Featured are the items that represent the best samples of artistic book design in Croatia with regard to their graphic design and harmonious relationship between the visual and graphic layout and content. The author of the exhibition is art historian Milan Pelc, who selected 60 items for presentation on panels. In addition to the introductory essay, the publication contains the catalogue of items with short descriptions. 4 Milan Pelc CENTURIES OF BOOK ART IN CROATIA Introduction Book art, a constituent part of written culture and Croatian cultural heritage as a whole, is ex- ceptionally rich and diverse. This essay does not pretend to describe it in its entirety. Its goal is to shed light on some (key) moments in its complex historical development and point to its most important specificities. The essay does not pertain to entire Croatian literary heritage, but only to the part created on the historical Croatian territory and created by the Croats. Namely, with regard to its origins, the Croatian literary heritage can be divided into three big groups. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -
![Spelling Progress Bulletin Summer 1977 P2 in the Printed Version]](https://docslib.b-cdn.net/cover/2223/spelling-progress-bulletin-summer-1977-p2-in-the-printed-version-762223.webp)
Spelling Progress Bulletin Summer 1977 P2 in the Printed Version]
Spelling Progress Bulletin Summer, 1977 Dedicated to finding the causes of difficulties in learning reading and spelling. Summer, 1977. Publisht quarterly Editor and General Manager, Assistant Editor, Spring, Summer, Fall, Winter. Newell W. Tune, Helen Bonnema Bisgard, Subscription $ 3. 00 a year. 5848 Alcove Ave, 13618 E. Bethany Pl, #307 Volume XVII, no. 2 No. Hollywood, Calif. 91607 Denver, Colo, 80232 Editorial Board: Emmett A. Betts, Helen Bonnema, Godfrey Dewey, Wilbur J. Kupfrian, William J. Reed, Ben D. Wood, Harvie Barnard. Table of Contents 1. Spelling and Phonics II, by Emmett Albert Betts, Ph.D., LL.D. 2. Sounds and Phonograms I (Grapho-Phoneme Variables), by Emmett A. Betts, Ph.D. 3. Sounds and Phonograms II (Variant Spellings), by Emmett Albert Betts, Ph.D, LL.D. 4. Sounds and Phonograms III (Variant Spellings), by Emmett Albert Betts, Ph.D, LL.D. 5. The Development of Danish Orthography, by Mogens Jansen & Tom Harpøth. 6. The Holiday, by Frank T. du Feu. 7. A Decade of Achievement with i. t. a., by John Henry Martin. 8. Ten Years with i. t. a. in California, by Eva Boyd. 9. Logic and Good Judgement needed in Selecting the Symbols to Represent the Sounds of Spoken English, by Newell W. Tune. 10. Criteria for Selecting a System of Reformed Spelling for a Permanent Reform, by Newell W. Tune. 11. Those Dropping Test Scores, by Harvie Barnard. 12. Why Johnny Still Can't Learn to Read, by Newell W. Tune. 13. A Condensed Summary of Reasons For and Against Orthographic Simplification, by Harvie Barnard. 14. An Explanation of Vowels Followed by /r/ in World English Spelling (I. -

I(Il Ll:N Cit~ BEFORE the BOARD of HEALING ARTS AUG 2 6 2010 of the STATE of KANSAS
i(iL ll:n Cit~ BEFORE THE BOARD OF HEALING ARTS AUG 2 6 2010 OF THE STATE OF KANSAS In the Matter of ) ) DocketNo. 11-HA 000A5 Michael Todd Hanson, R.T. ) Kansas License No. Pending ) CONSENT ORDER COMES NOW, the Kansas State Board of Healing Arts, ("Board"), by and through Stacy R. Bond, Associate Litigation Counsel ("Petitioner"), and Michael Todd Hanson, R.T. ("Applicant") and move the Board for approval of a Consent Order affecting Applicant's license to practice respiratory therapy in the State of Kansas. The Parties stipulate and agree to the following: 1. Applicant's last known mailing address to the Board is: P.O. Box 66, Stewartsville, Missouri 64490. 2. On or about May 4, 2010, Applicant submitted to the Board an application for licensure in respiratory therapy. Such application was deemed complete on July 15, 2010. 3. The Board is the sole and exclusive administrative agency in the State of Kansas authorized to regulate the practice of the healing arts, specifically the practice of respiratory therapy. K.S.A. 65-5501 et seq. and K.S.A. 65-5502. 4. This Consent Order and the filing of such document are in accordance with applicable law and the Board has jurisdiction to enter into the Consent Order as provided by K.S.A. 77-505 and 65-2838. Upon approval, these stipulations shall Consent Order Michael Todd Hanson, R.T. Page 1 of 13 constitute the findings of the Board, and this Consent Order shall constitute the Board's Final Order. 5. The Kansas Respiratory Therapy Practice Act is constitutional on its face and as applied in the case.