Automated Breakpoint Generation for Debugging
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

KDE 2.0 Development, Which Is Directly Supported
23 8911 CH18 10/16/00 1:44 PM Page 401 The KDevelop IDE: The CHAPTER Integrated Development Environment for KDE by Ralf Nolden 18 IN THIS CHAPTER • General Issues 402 • Creating KDE 2.0 Applications 409 • Getting Started with the KDE 2.0 API 413 • The Classbrowser and Your Project 416 • The File Viewers—The Windows to Your Project Files 419 • The KDevelop Debugger 421 • KDevelop 2.0—A Preview 425 23 8911 CH18 10/16/00 1:44 PM Page 402 Developer Tools and Support 402 PART IV Although developing applications under UNIX systems can be a lot of fun, until now the pro- grammer was lacking a comfortable environment that takes away the usual standard activities that have to be done over and over in the process of programming. The KDevelop IDE closes this gap and makes it a joy to work within a complete, integrated development environment, combining the use of the GNU standard development tools such as the g++ compiler and the gdb debugger with the advantages of a GUI-based environment that automates all standard actions and allows the developer to concentrate on the work of writing software instead of managing command-line tools. It also offers direct and quick access to source files and docu- mentation. KDevelop primarily aims to provide the best means to rapidly set up and write KDE software; it also supports extended features such as GUI designing and translation in con- junction with other tools available especially for KDE development. The KDevelop IDE itself is published under the GNU Public License (GPL), like KDE, and is therefore publicly avail- able at no cost—including its source code—and it may be used both for free and for commer- cial development. -
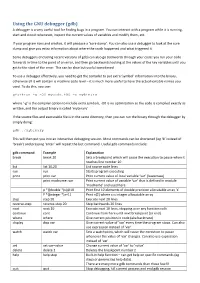
Using the GNU Debugger (Gdb) a Debugger Is a Very Useful Tool for Finding Bugs in a Program
Using the GNU debugger (gdb) A debugger is a very useful tool for finding bugs in a program. You can interact with a program while it is running, start and stop it whenever, inspect the current values of variables and modify them, etc. If your program runs and crashes, it will produce a ‘core dump’. You can also use a debugger to look at the core dump and give you extra information about where the crash happened and what triggered it. Some debuggers (including recent versions of gdb) can also go backwards through your code: you run your code forwards in time to the point of an error, and then go backwards looking at the values of the key variables until you get to the start of the error. This can be slow but useful sometimes! To use a debugger effectively, you need to get the compiler to put extra ‘symbol’ information into the binary, otherwise all it will contain is machine code level – it is much more useful to have the actual variable names you used. To do this, you use: gfortran –g –O0 mycode.f90 –o mybinary where ‘-g’ is the compiler option to include extra symbols, -O0 is no optimization so the code is compiled exactly as written, and the output binary is called ’mybinary’. If the source files and executable file is in the same directory, then you can run the binary through the debugger by simply doing: gdb ./mybinary This will then put you into an interactive debugging session. Most commands can be shortened (eg ‘b’ instead of ‘break’) and pressing ‘enter’ will repeat the last command. -

Intel® 64 and IA-32 Architectures Software Developer's Manual
Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3B: System Programming Guide, Part 2 NOTE: The Intel® 64 and IA-32 Architectures Software Developer's Manual consists of five volumes: Basic Architecture, Order Number 253665; Instruction Set Reference A-M, Order Number 253666; Instruction Set Reference N-Z, Order Number 253667; System Programming Guide, Part 1, Order Number 253668; System Programming Guide, Part 2, Order Number 253669. Refer to all five volumes when evaluating your design needs. Order Number: 253669-029US November 2008 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANT- ED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR IN- TENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUA- TION WHERE PERSONAL INJURY OR DEATH MAY OCCUR. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "unde- fined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. -

Design of the RISC-V Instruction Set Architecture
Design of the RISC-V Instruction Set Architecture Andrew Waterman Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2016-1 http://www.eecs.berkeley.edu/Pubs/TechRpts/2016/EECS-2016-1.html January 3, 2016 Copyright © 2016, by the author(s). All rights reserved. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission. Design of the RISC-V Instruction Set Architecture by Andrew Shell Waterman A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Computer Science in the Graduate Division of the University of California, Berkeley Committee in charge: Professor David Patterson, Chair Professor Krste Asanovi´c Associate Professor Per-Olof Persson Spring 2016 Design of the RISC-V Instruction Set Architecture Copyright 2016 by Andrew Shell Waterman 1 Abstract Design of the RISC-V Instruction Set Architecture by Andrew Shell Waterman Doctor of Philosophy in Computer Science University of California, Berkeley Professor David Patterson, Chair The hardware-software interface, embodied in the instruction set architecture (ISA), is arguably the most important interface in a computer system. Yet, in contrast to nearly all other interfaces in a modern computer system, all commercially popular ISAs are proprietary. -

ARM Debugger
ARM Debugger TRACE32 Online Help TRACE32 Directory TRACE32 Index TRACE32 Documents ...................................................................................................................... ICD In-Circuit Debugger ................................................................................................................ Processor Architecture Manuals .............................................................................................. ARM/CORTEX/XSCALE ........................................................................................................... ARM Debugger ..................................................................................................................... 1 History ................................................................................................................................ 7 Warning .............................................................................................................................. 8 Introduction ....................................................................................................................... 9 Brief Overview of Documents for New Users 9 Demo and Start-up Scripts 10 Quick Start of the JTAG Debugger .................................................................................. 12 FAQ ..................................................................................................................................... 13 Troubleshooting ............................................................................................................... -

Windows Powershell Best Practices Windows Powershell Best Practices
Windows PowerShell Best Practices Windows PowerShell Best Practices Expert recommendations, pragmatically applied Automate system administration using Windows PowerShell best practices—and optimize your operational efficiency. With this About the Author practical guide, Windows PowerShell expert and instructor Ed Ed Wilson, MCSE, CISSP, is a well-known Wilson delivers field-tested tips, real-world examples, and candid scripting expert and author of “Hey Windows Scripting Guy!”—one of the most popular advice culled from administrators across a range of business and blogs on Microsoft TechNet. He’s written technical scenarios. If you’re an IT professional with Windows several books on Windows scripting PowerShell experience, this book is ideal. for Microsoft Press, including Windows PowerShell 2.0 Best Practices and Windows PowerShell Scripting Guide. Discover how to: PowerShell • Use Windows PowerShell to automate Active Directory tasks • Explore available WMI classes and methods with CIM cmdlets • Identify and track scripting opportunities to avoid duplication • Use functions to encapsulate business logic and reuse code • Design your script’s best input method and output destination • Test scripts by checking their syntax and performance • Choose the most suitable method for running remote commands • Manage software services with Desired State Configuration Wilson BEST PRACTICES microsoft.com/mspress ISBN 978-0-7356-6649-8 U.S.A. $59.99 55999 Canada $68.99 [Recommended] 9 780735 666498 Operating Systems/Windows Server Celebrating 30 years! Ed Wilson 666498_Win_PowerShell_Best_Practices.indd 1 4/11/14 10:30 AM Windows PowerShell Best Practices Ed Wilson 666498_book.indb 1 12/20/13 10:50 AM Published with the authorization of Microsoft Corporation by: O’Reilly Media, Inc. -

Debugger User's Guide
DEBUGGER USER'S GUIDE Version 2018 TABLE OF CONTENTS Preface............................................................................................................ xii Intended Audience............................................................................................ xii Documentation.................................................................................................xii Compatibility and Conformance to Standards............................................................xii Organization................................................................................................... xiii Conventions.................................................................................................... xiv Terminology.....................................................................................................xv Related Publications.......................................................................................... xv Chapter 1. Getting Started.....................................................................................1 1.1. Definition of Terms.......................................................................................1 1.2. Building Applications for Debug........................................................................2 1.2.1. Debugging Optimized Code........................................................................ 2 1.2.2. Building for Debug on Windows...................................................................2 1.3. User Interfaces........................................................................................... -

Kdevelop Handbook
KDevelop Handbook This documentation was converted from the KDE UserBase KDevelop4/Manual page. KDevelop Handbook 2 Contents 1 What is KDevelop?6 2 Sessions and projects: The basics of KDevelop8 2.1 Terminology . .8 2.2 Setting up a session and importing an existing project . .9 2.2.1 Option 1: Importing a project from a version control system server . .9 2.2.2 Option 2: Importing a project that is already on your hard drive . 10 2.3 Setting up an application as a second project . 10 2.4 Creating projects from scratch . 10 3 Working with source code 12 3.1 Tools and views . 12 3.2 Exploring source code . 14 3.2.1 Local information . 14 3.2.2 File scope information . 16 3.2.3 Project and session scope information . 17 3.2.4 Rainbow color highlighting explained . 19 3.3 Navigating in source code . 19 3.3.1 Local navigation . 19 3.3.2 File scope navigation and outline mode . 20 3.3.3 Project and session scope navigation: Semantic navigation . 21 3.4 Writing source code . 25 3.4.1 Auto-completion . 25 3.4.2 Adding new classes and implementing member functions . 27 3.4.3 Documenting declarations . 31 3.4.4 Renaming variables, functions and classes . 34 3.4.5 Code snippets . 35 3.5 Modes and working sets . 37 3.6 Some useful keyboard shortcuts . 39 KDevelop Handbook 4 Code generation with templates 41 4.1 Creating a new class . 41 4.2 Creating a new unit test . 43 4.3 Other files . -

The RISC-V Instruction Set Manual Volume I: User-Level ISA Document Version 2.2
The RISC-V Instruction Set Manual Volume I: User-Level ISA Document Version 2.2 Editors: Andrew Waterman1, Krste Asanovi´c1;2 1SiFive Inc., 2CS Division, EECS Department, University of California, Berkeley [email protected], [email protected] May 7, 2017 Contributors to all versions of the spec in alphabetical order (please contact editors to suggest corrections): Krste Asanovi´c,Rimas Aviˇzienis,Jacob Bachmeyer, Christopher F. Batten, Allen J. Baum, Alex Bradbury, Scott Beamer, Preston Briggs, Christopher Celio, David Chisnall, Paul Clayton, Palmer Dabbelt, Stefan Freudenberger, Jan Gray, Michael Hamburg, John Hauser, David Horner, Olof Johansson, Ben Keller, Yunsup Lee, Joseph Myers, Rishiyur Nikhil, Stefan O'Rear, Albert Ou, John Ousterhout, David Patterson, Colin Schmidt, Michael Taylor, Wesley Terpstra, Matt Thomas, Tommy Thorn, Ray VanDeWalker, Megan Wachs, Andrew Waterman, Robert Wat- son, and Reinoud Zandijk. This document is released under a Creative Commons Attribution 4.0 International License. This document is a derivative of \The RISC-V Instruction Set Manual, Volume I: User-Level ISA Version 2.1" released under the following license: c 2010{2017 Andrew Waterman, Yunsup Lee, David Patterson, Krste Asanovi´c. Creative Commons Attribution 4.0 International License. Please cite as: \The RISC-V Instruction Set Manual, Volume I: User-Level ISA, Document Version 2.2", Editors Andrew Waterman and Krste Asanovi´c,RISC-V Foundation, May 2017. Preface This is version 2.2 of the document describing the RISC-V user-level architecture. The document contains the following versions of the RISC-V ISA modules: Base Version Frozen? RV32I 2.0 Y RV32E 1.9 N RV64I 2.0 Y RV128I 1.7 N Extension Version Frozen? M 2.0 Y A 2.0 Y F 2.0 Y D 2.0 Y Q 2.0 Y L 0.0 N C 2.0 Y B 0.0 N J 0.0 N T 0.0 N P 0.1 N V 0.2 N N 1.1 N To date, no parts of the standard have been officially ratified by the RISC-V Foundation, but the components labeled \frozen" above are not expected to change during the ratification process beyond resolving ambiguities and holes in the specification. -

IDE, a Software Environment You Can Use to Develop Your C/C++ Programs
The University of CMSC 15200 ± Introduction to Computer Science 2 Chicago Summer Quarter 2005 Department of Lab #2 (08/01/2005) Computer Science Name: Student ID: Lab Instructor: Borja Sotomayor Do not write in this area 1 2 3 TOTAL Maximum possible points: 30 One of the goals of this lab is to introduce the Eclipse IDE, a software environment you can use to develop your C/C++ programs. We provide some basic instructions on how to write a program with Eclipse, and how to use Eclipse's debugging features. More complete documentation can be found in Eclipse's official website: http://www.eclipse.org/ http://www.eclipse.org/documentation/ http://help.eclipse.org/ IDE: Integrated Development Environment An IDE, or Integrated Development Environment, provides an environment that integrates all the tools necessary to develop a piece of software. IDEs typically include a text editor, a compiler, a debugger, and other tools to improve the productivity of the programmer. For example, many IDEs include tools that allow us to easily create graphical interfaces for our own applications (“UI designers”) The user can interact with all these tools (editor, compiler, etc.) using an interface which generally (but not always) will be an easy-to-use graphical interface. In fact, the main advantage of using an IDE is that the programmer can do all his work from a single interface, instead of having to constantly switch between different tools. The following are some popular IDEs: ➢ Free / Open source (UNIX/Linux) ● Eclipse (Multi-platform, Java, C/C++, other -

The Design of a Debugger Unit for a RISC Processor Core
Rochester Institute of Technology RIT Scholar Works Theses 3-2018 The Design of a Debugger Unit for a RISC Processor Core Nikhil Velguenkar [email protected] Follow this and additional works at: https://scholarworks.rit.edu/theses Recommended Citation Velguenkar, Nikhil, "The Design of a Debugger Unit for a RISC Processor Core" (2018). Thesis. Rochester Institute of Technology. Accessed from This Master's Project is brought to you for free and open access by RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact [email protected]. The Design of a Debugger Unit for a RISC Processor Core by Nikhil Velguenkar Graduate Paper Submitted in partial fulfillment of the requirements for the degree of Master of Science in Electrical Engineering Approved by: Mr. Mark A. Indovina, Lecturer Graduate Research Advisor, Department of Electrical and Microelectronic Engineering Dr. Sohail A. Dianat, Professor Department Head, Department of Electrical and Microelectronic Engineering Department of Electrical and Microelectronic Engineering Kate Gleason College of Engineering Rochester Institute of Technology Rochester, New York March 2018 To my family and friends, for all of their endless love, support, and encouragement throughout my career at Rochester Institute of Technology Abstract Recently, there has been a significant increase in design complexity for Embedded Sys- tems often referred to as Hardware Software Co-Design. Complexity in design is due to both hardware and firmware closely coupled together in-order to achieve features forlow power, high performance and low area. Due to these demands, embedded systems consist of multiple interconnected hardware IPs with complex firmware algorithms running on the device. -

Virtual Breakpoints for X86/64
Virtual Breakpoints for x86/64 Gregory Price1∗y August 22, 2019 Abstract Debuggers [1] and other instrumentation tools [3][4][7][11] are becoming increasingly complex as Efficient, reliable trapping of execution in a pro- malware deploys equally complex anti-analysis gram at the desired location is a linchpin tech- techniques. Many techniques require special mem- nique for dynamic malware analysis. The pro- ory allocators, compilers, or complex systems to gression of debuggers and malware is akin to a control the \view" of memory [10, 2]. In some game of cat and mouse - each are constantly in cases, the efficiency or robustness of these tech- a state of trying to thwart one another. At the niques rely on architecture-level quirks that are core of most efficient debuggers today is a com- more of a happy accident, rather than intentional bination of virtual machines and traditional bi- design. For example, SPIDER breakpoints [2] nary modification breakpoints (int3). In this pa- rely on a caching quirk of Intel CPU's to remain per, we present a design for Virtual Breakpoints efficient, and many dynamic binary instrumenta- | a modification to the x86 MMU which brings tion systems [10] are a mess of trampolines and breakpoint management into hardware alongside runtime hooking. page tables. In this paper we demonstrate the Despite the growing complexity, all of these fundamental abstraction failures of current trap- systems must trade between efficiency, reliabil- ping methods, and design a new mechanism from ity, and transparency [4]. If a trapping mech- the hardware up. This design incorporates lessons anism introduces significant overhead, analysis learned from 50 years of virtualization and de- becomes tedious.