The RISC-V Instruction Set Manual Volume I: User-Level ISA Document Version 2.2
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Data-Level Parallelism
Fall 2015 :: CSE 610 – Parallel Computer Architectures Data-Level Parallelism Nima Honarmand Fall 2015 :: CSE 610 – Parallel Computer Architectures Overview • Data Parallelism vs. Control Parallelism – Data Parallelism: parallelism arises from executing essentially the same code on a large number of objects – Control Parallelism: parallelism arises from executing different threads of control concurrently • Hypothesis: applications that use massively parallel machines will mostly exploit data parallelism – Common in the Scientific Computing domain • DLP originally linked with SIMD machines; now SIMT is more common – SIMD: Single Instruction Multiple Data – SIMT: Single Instruction Multiple Threads Fall 2015 :: CSE 610 – Parallel Computer Architectures Overview • Many incarnations of DLP architectures over decades – Old vector processors • Cray processors: Cray-1, Cray-2, …, Cray X1 – SIMD extensions • Intel SSE and AVX units • Alpha Tarantula (didn’t see light of day ) – Old massively parallel computers • Connection Machines • MasPar machines – Modern GPUs • NVIDIA, AMD, Qualcomm, … • Focus of throughput rather than latency Vector Processors 4 SCALAR VECTOR (1 operation) (N operations) r1 r2 v1 v2 + + r3 v3 vector length add r3, r1, r2 vadd.vv v3, v1, v2 Scalar processors operate on single numbers (scalars) Vector processors operate on linear sequences of numbers (vectors) 6.888 Spring 2013 - Sanchez and Emer - L14 What’s in a Vector Processor? 5 A scalar processor (e.g. a MIPS processor) Scalar register file (32 registers) Scalar functional units (arithmetic, load/store, etc) A vector register file (a 2D register array) Each register is an array of elements E.g. 32 registers with 32 64-bit elements per register MVL = maximum vector length = max # of elements per register A set of vector functional units Integer, FP, load/store, etc Some times vector and scalar units are combined (share ALUs) 6.888 Spring 2013 - Sanchez and Emer - L14 Example of Simple Vector Processor 6 6.888 Spring 2013 - Sanchez and Emer - L14 Basic Vector ISA 7 Instr. -

KDE 2.0 Development, Which Is Directly Supported
23 8911 CH18 10/16/00 1:44 PM Page 401 The KDevelop IDE: The CHAPTER Integrated Development Environment for KDE by Ralf Nolden 18 IN THIS CHAPTER • General Issues 402 • Creating KDE 2.0 Applications 409 • Getting Started with the KDE 2.0 API 413 • The Classbrowser and Your Project 416 • The File Viewers—The Windows to Your Project Files 419 • The KDevelop Debugger 421 • KDevelop 2.0—A Preview 425 23 8911 CH18 10/16/00 1:44 PM Page 402 Developer Tools and Support 402 PART IV Although developing applications under UNIX systems can be a lot of fun, until now the pro- grammer was lacking a comfortable environment that takes away the usual standard activities that have to be done over and over in the process of programming. The KDevelop IDE closes this gap and makes it a joy to work within a complete, integrated development environment, combining the use of the GNU standard development tools such as the g++ compiler and the gdb debugger with the advantages of a GUI-based environment that automates all standard actions and allows the developer to concentrate on the work of writing software instead of managing command-line tools. It also offers direct and quick access to source files and docu- mentation. KDevelop primarily aims to provide the best means to rapidly set up and write KDE software; it also supports extended features such as GUI designing and translation in con- junction with other tools available especially for KDE development. The KDevelop IDE itself is published under the GNU Public License (GPL), like KDE, and is therefore publicly avail- able at no cost—including its source code—and it may be used both for free and for commer- cial development. -

Field Programmable Gate Arrays with Hardwired Networks on Chip
Field Programmable Gate Arrays with Hardwired Networks on Chip PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Technische Universiteit Delft, op gezag van de Rector Magnificus prof. ir. K.C.A.M. Luyben, voorzitter van het College voor Promoties, in het openbaar te verdedigen op dinsdag 6 november 2012 om 15:00 uur door MUHAMMAD AQEEL WAHLAH Master of Science in Information Technology Pakistan Institute of Engineering and Applied Sciences (PIEAS) geboren te Lahore, Pakistan. Dit proefschrift is goedgekeurd door de promotor: Prof. dr. K.G.W. Goossens Copromotor: Dr. ir. J.S.S.M. Wong Samenstelling promotiecommissie: Rector Magnificus voorzitter Prof. dr. K.G.W. Goossens Technische Universiteit Eindhoven, promotor Dr. ir. J.S.S.M. Wong Technische Universiteit Delft, copromotor Prof. dr. S. Pillement Technical University of Nantes, France Prof. dr.-Ing. M. Hubner Ruhr-Universitat-Bochum, Germany Prof. dr. D. Stroobandt University of Gent, Belgium Prof. dr. K.L.M. Bertels Technische Universiteit Delft Prof. dr.ir. A.J. van der Veen Technische Universiteit Delft, reservelid ISBN: 978-94-6186-066-8 Keywords: Field Programmable Gate Arrays, Hardwired, Networks on Chip Copyright ⃝c 2012 Muhammad Aqeel Wahlah All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without permission of the author. Printed in The Netherlands Acknowledgments oday when I look back, I find it a very interesting journey filled with different emotions, i.e., joy and frustration, hope and despair, and T laughter and sadness. -

On the Hardware Reduction of Z-Datapath of Vectoring CORDIC
On the Hardware Reduction of z-Datapath of Vectoring CORDIC R. Stapenhurst*, K. Maharatna**, J. Mathew*, J.L.Nunez-Yanez* and D. K. Pradhan* *University of Bristol, Bristol, UK **University of Southampton, Southampton, UK [email protected] Abstract— In this article we present a novel design of a hardware wordlength larger than 18-bits the hardware requirement of it optimal vectoring CORDIC processor. We present a mathematical becomes more than the classical CORDIC. theory to show that using bipolar binary notation it is possible to eliminate all the arithmetic computations required along the z- In this particular work we propose a formulation to eliminate datapath. Using this technique it is possible to achieve three and 1.5 all the arithmetic operations along the z-datapath for conventional times reduction in the number of registers and adder respectively two-sided vector rotation and thereby reducing the hardware compared to classical CORDIC. Following this, a 16-bit vectoring while increasing the accuracy. Also the resulting architecture CORDIC is designed for the application in Synchronizer for IEEE shows significant hardware saving as the wordlength increases. 802.11a standard. The total area and dynamic power consumption Although we stick to the 2’s complement number system, without of the processor is 0.14 mm2 and 700μW respectively when loss of generality, this formulation can be adopted easily for synthesized in 0.18μm CMOS library which shows its effectiveness redundant arithmetic and higher radix formulation. A 16-bit as a low-area low-power processor. processor developed following this formulation requires 0.14 mm2 area and consumes 700 μW dynamic power when synthesized in 0.18μm CMOS library. -

The RISC-V Instruction Set Manual, Volume I: User- Level ISA, Version 2.0
The RISC-V Instruction Set Manual, Volume I: User- Level ISA, Version 2.0 Andrew Waterman Yunsup Lee David A. Patterson Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2014-54 http://www.eecs.berkeley.edu/Pubs/TechRpts/2014/EECS-2014-54.html May 6, 2014 Copyright © 2014, by the author(s). All rights reserved. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission. The RISC-V Instruction Set Manual Volume I: User-Level ISA Version 2.0 Andrew Waterman, Yunsup Lee, David Patterson, Krste Asanovi´c CS Division, EECS Department, University of California, Berkeley fwaterman|yunsup|pattrsn|[email protected] May 6, 2014 Preface This is the second release of the user ISA specification, and we intend the specification of the base user ISA plus general extensions (i.e., IMAFD) to remain fixed for future development. The following changes have been made since Version 1.0 [25] of this ISA specification. • The ISA has been divided into an integer base with several standard extensions. • The instruction formats have been rearranged to make immediate encoding more efficient. • The base ISA has been defined to have a little-endian memory system, with big-endian or bi-endian as non-standard variants. -
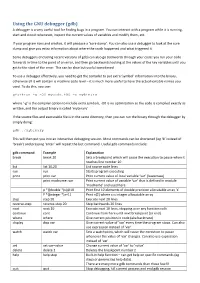
Using the GNU Debugger (Gdb) a Debugger Is a Very Useful Tool for Finding Bugs in a Program
Using the GNU debugger (gdb) A debugger is a very useful tool for finding bugs in a program. You can interact with a program while it is running, start and stop it whenever, inspect the current values of variables and modify them, etc. If your program runs and crashes, it will produce a ‘core dump’. You can also use a debugger to look at the core dump and give you extra information about where the crash happened and what triggered it. Some debuggers (including recent versions of gdb) can also go backwards through your code: you run your code forwards in time to the point of an error, and then go backwards looking at the values of the key variables until you get to the start of the error. This can be slow but useful sometimes! To use a debugger effectively, you need to get the compiler to put extra ‘symbol’ information into the binary, otherwise all it will contain is machine code level – it is much more useful to have the actual variable names you used. To do this, you use: gfortran –g –O0 mycode.f90 –o mybinary where ‘-g’ is the compiler option to include extra symbols, -O0 is no optimization so the code is compiled exactly as written, and the output binary is called ’mybinary’. If the source files and executable file is in the same directory, then you can run the binary through the debugger by simply doing: gdb ./mybinary This will then put you into an interactive debugging session. Most commands can be shortened (eg ‘b’ instead of ‘break’) and pressing ‘enter’ will repeat the last command. -

18-447 Computer Architecture Lecture 6: Multi-Cycle and Microprogrammed Microarchitectures
18-447 Computer Architecture Lecture 6: Multi-Cycle and Microprogrammed Microarchitectures Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 1/28/2015 Agenda for Today & Next Few Lectures n Single-cycle Microarchitectures n Multi-cycle and Microprogrammed Microarchitectures n Pipelining n Issues in Pipelining: Control & Data Dependence Handling, State Maintenance and Recovery, … n Out-of-Order Execution n Issues in OoO Execution: Load-Store Handling, … 2 Reminder on Assignments n Lab 2 due next Friday (Feb 6) q Start early! n HW 1 due today n HW 2 out n Remember that all is for your benefit q Homeworks, especially so q All assignments can take time, but the goal is for you to learn very well 3 Lab 1 Grades 25 20 15 10 5 Number of Students 0 30 40 50 60 70 80 90 100 n Mean: 88.0 n Median: 96.0 n Standard Deviation: 16.9 4 Extra Credit for Lab Assignment 2 n Complete your normal (single-cycle) implementation first, and get it checked off in lab. n Then, implement the MIPS core using a microcoded approach similar to what we will discuss in class. n We are not specifying any particular details of the microcode format or the microarchitecture; you can be creative. n For the extra credit, the microcoded implementation should execute the same programs that your ordinary implementation does, and you should demo it by the normal lab deadline. n You will get maximum 4% of course grade n Document what you have done and demonstrate well 5 Readings for Today n P&P, Revised Appendix C q Microarchitecture of the LC-3b q Appendix A (LC-3b ISA) will be useful in following this n P&H, Appendix D q Mapping Control to Hardware n Optional q Maurice Wilkes, “The Best Way to Design an Automatic Calculating Machine,” Manchester Univ. -

The 32-Bit PA-RISC Run-Time Architecture Document, V. 1.0 for HP
The 32-bit PA-RISC Run-time Architecture Document HP-UX 11.0 Version 1.0 (c) Copyright 1997 HEWLETT-PACKARD COMPANY. The information contained in this document is subject to change without notice. HEWLETT-PACKARD MAKES NO WARRANTY OF ANY KIND WITH REGARD TO THIS MATERIAL, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. Hewlett-Packard shall not be liable for errors contained herein or for incidental or consequential damages in connection with furnishing, performance, or use of this material. Hewlett-Packard assumes no responsibility for the use or reliability of its software on equipment that is not furnished by Hewlett-Packard. This document contains proprietary information which is protected by copyright. All rights are reserved. No part of this document may be photocopied, reproduced, or translated to another language without the prior written consent of Hewlett-Packard Company. CSO/STG/STD/CLO Hewlett-Packard Company 11000 Wolfe Road Cupertino, California 95014 By The Run-time Architecture Team 32-bit PA-RISC RUN-TIME ARCHITECTURE DOCUMENT 11.0 version 1.0 -1 -2 CHAPTER 1 Introduction 7 1.1 Target Audiences 7 1.2 Overview of the PA-RISC Runtime Architecture Document 8 CHAPTER 2 Common Coding Conventions 9 2.1 Memory Model 9 2.1.1 Text Segment 9 2.1.2 Initialized and Uninitialized Data Segments 9 2.1.3 Shared Memory 10 2.1.4 Subspaces 10 2.2 Register Usage 10 2.2.1 Data Pointer (GR 27) 10 2.2.2 Linkage Table Register (GR 19) 10 2.2.3 Stack Pointer (GR 30) 11 2.2.4 Space -

Lecture 14: Gpus
LECTURE 14 GPUS DANIEL SANCHEZ AND JOEL EMER [INCORPORATES MATERIAL FROM KOZYRAKIS (EE382A), NVIDIA KEPLER WHITEPAPER, HENNESY&PATTERSON] 6.888 PARALLEL AND HETEROGENEOUS COMPUTER ARCHITECTURE SPRING 2013 Today’s Menu 2 Review of vector processors Basic GPU architecture Paper discussions 6.888 Spring 2013 - Sanchez and Emer - L14 Vector Processors 3 SCALAR VECTOR (1 operation) (N operations) r1 r2 v1 v2 + + r3 v3 vector length add r3, r1, r2 vadd.vv v3, v1, v2 Scalar processors operate on single numbers (scalars) Vector processors operate on linear sequences of numbers (vectors) 6.888 Spring 2013 - Sanchez and Emer - L14 What’s in a Vector Processor? 4 A scalar processor (e.g. a MIPS processor) Scalar register file (32 registers) Scalar functional units (arithmetic, load/store, etc) A vector register file (a 2D register array) Each register is an array of elements E.g. 32 registers with 32 64-bit elements per register MVL = maximum vector length = max # of elements per register A set of vector functional units Integer, FP, load/store, etc Some times vector and scalar units are combined (share ALUs) 6.888 Spring 2013 - Sanchez and Emer - L14 Example of Simple Vector Processor 5 6.888 Spring 2013 - Sanchez and Emer - L14 Basic Vector ISA 6 Instr. Operands Operation Comment VADD.VV V1,V2,V3 V1=V2+V3 vector + vector VADD.SV V1,R0,V2 V1=R0+V2 scalar + vector VMUL.VV V1,V2,V3 V1=V2*V3 vector x vector VMUL.SV V1,R0,V2 V1=R0*V2 scalar x vector VLD V1,R1 V1=M[R1...R1+63] load, stride=1 VLDS V1,R1,R2 V1=M[R1…R1+63*R2] load, stride=R2 -

A Superscalar Out-Of-Order X86 Soft Processor for FPGA
A Superscalar Out-of-Order x86 Soft Processor for FPGA Henry Wong University of Toronto, Intel [email protected] June 5, 2019 Stanford University EE380 1 Hi! ● CPU architect, Intel Hillsboro ● Ph.D., University of Toronto ● Today: x86 OoO processor for FPGA (Ph.D. work) – Motivation – High-level design and results – Microarchitecture details and some circuits 2 FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT6-LUT 6-LUT6-LUT 3 6-LUT 6-LUT FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT 6-LUT 6-LUT 6-LUT 4 6-LUT 6-LUT FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 5 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 6 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

RTEMS CPU Supplement Documentation Release 4.11.3 ©Copyright 2016, RTEMS Project (Built 15Th February 2018)
RTEMS CPU Supplement Documentation Release 4.11.3 ©Copyright 2016, RTEMS Project (built 15th February 2018) CONTENTS I RTEMS CPU Architecture Supplement1 1 Preface 5 2 Port Specific Information7 2.1 CPU Model Dependent Features...........................8 2.1.1 CPU Model Name...............................8 2.1.2 Floating Point Unit..............................8 2.2 Multilibs........................................9 2.3 Calling Conventions.................................. 10 2.3.1 Calling Mechanism.............................. 10 2.3.2 Register Usage................................. 10 2.3.3 Parameter Passing............................... 10 2.3.4 User-Provided Routines............................ 10 2.4 Memory Model..................................... 11 2.4.1 Flat Memory Model.............................. 11 2.5 Interrupt Processing.................................. 12 2.5.1 Vectoring of an Interrupt Handler...................... 12 2.5.2 Interrupt Levels................................ 12 2.5.3 Disabling of Interrupts by RTEMS...................... 12 2.6 Default Fatal Error Processing............................. 14 2.7 Symmetric Multiprocessing.............................. 15 2.8 Thread-Local Storage................................. 16 2.9 CPU counter...................................... 17 2.10 Interrupt Profiling................................... 18 2.11 Board Support Packages................................ 19 2.11.1 System Reset................................. 19 3 ARM Specific Information 21 3.1 CPU Model Dependent Features..........................