Cuneiform Range: 12000–123FF
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -
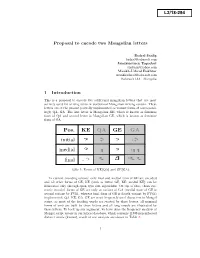
Pos. KE QA GE GA Initial ᠬ ᠭ Medial Final
Proposal to encode two Mongolian letters Badral Sanlig [email protected] Jamiyansuren Togoobat [email protected] Munkh-Uchral Enkhtur [email protected] Bolorsoft LLC, Mongolia 1 Introduction This is a proposal to encode two additional mongolian letters that are most actively used for writing texts in traditional Mongolian writing system. These letters are at the present partially implemented as variant forms of correspond- ingly QA, GA. The first letter is Mongolian KE, which is known as feminine form of QA and second letter is Mongolian GE, which is known as feminine form of GA. Pos. KE QA GE GA ᠬ ᠭ initial medial final - Table 1: Forms of KE(QA) and GE(GA). In current encoding scheme, only final and medial form of GE are encoded and all other forms of GE, KE (such as initial GE, KE, medial KE) can be illustrated only through open type font algorithms. On top of that, those cur- rently encoded forms of GE are only as variant of GA (medial form of GE is second variant by FVS1, whereas final form of GE is fourth variant by FVS3) implemented. QA, KE, GA, GE are most frequently used characters in Mongol script, as most of the heading words are started by these letters, all nominal forms of verb are built by these letters and all long vowels are illustrated by these letters. To back up our argument, we have done the frequency analysis of Mongol script letters in our lexical database, which contains 41808 non-inflected distinct words (lemma), result of our analysis are shown in Table 2. -

Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-04-22 Document version: 2.7 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract This document lays down the Label Generation Ruleset for Gurmukhi script. Three main components of the Gurmukhi Script LGR i.e. Code point repertoire, Variants and Whole Label Evaluation Rules have been described in detail here. All these components have been incorporated in a machine-readable format in the accompanying XML file named "proposal-gurmukhi-lgr-22apr19-en.xml". In addition, a document named “gurmukhi-test-labels-22apr19-en.txt” has been provided. It provides a list of labels which can produce variants as laid down in Section 6 of this document and it also provides valid and invalid labels as per the Whole Label Evaluation laid down in Section 7. 2. Script for which the LGR is proposed ISO 15924 Code: Guru ISO 15924 Key N°: 310 ISO 15924 English Name: Gurmukhi Latin transliteration of native script name: gurmukhī Native name of the script: ਗੁਰਮੁਖੀ Maximal Starting Repertoire [MSR] version: 4 1 3. Background on Script and Principal Languages Using It 3.1. The Evolution of the Script Like most of the North Indian writing systems, the Gurmukhi script is a descendant of the Brahmi script. The Proto-Gurmukhi letters evolved through the Gupta script from 4th to 8th century, followed by the Sharda script from 8th century onwards and finally adapted their archaic form in the Devasesha stage of the later Sharda script, dated between the 10th and 14th centuries. -

2 the Assyrian Empire, the Conquest of Israel, and the Colonization of Judah 37 I
ISRAEL AND EMPIRE ii ISRAEL AND EMPIRE A Postcolonial History of Israel and Early Judaism Leo G. Perdue and Warren Carter Edited by Coleman A. Baker LONDON • NEW DELHI • NEW YORK • SYDNEY 1 Bloomsbury T&T Clark An imprint of Bloomsbury Publishing Plc Imprint previously known as T&T Clark 50 Bedford Square 1385 Broadway London New York WC1B 3DP NY 10018 UK USA www.bloomsbury.com Bloomsbury, T&T Clark and the Diana logo are trademarks of Bloomsbury Publishing Plc First published 2015 © Leo G. Perdue, Warren Carter and Coleman A. Baker, 2015 All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or any information storage or retrieval system, without prior permission in writing from the publishers. Leo G. Perdue, Warren Carter and Coleman A. Baker have asserted their rights under the Copyright, Designs and Patents Act, 1988, to be identified as Authors of this work. No responsibility for loss caused to any individual or organization acting on or refraining from action as a result of the material in this publication can be accepted by Bloomsbury or the authors. British Library Cataloguing-in-Publication Data A catalogue record for this book is available from the British Library. ISBN: HB: 978-0-56705-409-8 PB: 978-0-56724-328-7 ePDF: 978-0-56728-051-0 Library of Congress Cataloging-in-Publication Data A catalogue record for this book is available from the British Library. Typeset by Forthcoming Publications (www.forthpub.com) 1 Contents Abbreviations vii Preface ix Introduction: Empires, Colonies, and Postcolonial Interpretation 1 I. -

The Limits of Middle Babylonian Archives1
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by OpenstarTs The Limits of Middle Babylonian Archives1 susanne paulus Middle Babylonian Archives Archives and archival records are one of the most important sources for the un- derstanding of the Babylonian culture.2 The definition of “archive” used for this article is the one proposed by Pedersén: «The term “archive” here, as in some other studies, refers to a collection of texts, each text documenting a message or a statement, for example, letters, legal, economic, and administrative documents. In an archive there is usually just one copy of each text, although occasionally a few copies may exist.»3 The aim of this article is to provide an overview of the archives of the Middle Babylonian Period (ca. 1500-1000 BC),4 which are often 1 All kudurrus are quoted according to Paulus 2012a. For a quick reference on the texts see the list of kudurrus in table 1. 2 For an introduction into Babylonian archives see Veenhof 1986b; for an overview of differ- ent archives of different periods see Veenhof 1986a and Brosius 2003a. 3 Pedersén 1998; problems connected to this definition are shown by Brosius 2003b, 4-13. 4 This includes the time of the Kassite dynasty (ca. 1499-1150) and the following Isin-II-pe- riod (ca. 1157-1026). All following dates are BC, the chronology follows – willingly ignoring all linked problems – Gasche et. al. 1998. the limits of middle babylonian archives 87 left out in general studies,5 highlighting changes in respect to the preceding Old Babylonian period and problems linked with the material. -

Design of Javanese Text to Speech Application
Design of Javanese Text to Speech Application Yulia, Liliana, Rudy Adipranata, Gregorius Satia Budhi Informatics Department, Industrial Technology Faculty, Petra Christian University Surabaya, Indonesia [email protected] Abstract—Javanese is one of the many regional languages used in Indonesia. Javanese language is used by most of the population in Java. But now along with the development of the era, the use of regional languages including Javanese language is to be re- duced especially among the younger generation. One way to help conserve the use of Javanese language is to utilize information technologies, one of them is by developing a text to speech appli- cation that can be used to find out how the pronunciation of Ja- vanese language. In this paper, we discussed the design for Java- nese text to speech applications uses finite state automata. The design result will be used as rules to separate syllables when im- plementing text to speech application. Index Terms—Javanese language; Finite state automata; Text to speech. Figure 1: Basic Javanese characters I. INTRODUCTION In addition to the basic characters, the Javanese character Javanese language is a language widely spoken by the peo- has supplementary characters, consist of symbols for express- ple of Java. It is one of the regional languages of many region- ing vowels as well as a combination of two specific conso- al languages spoken in Indonesia. As one of the assets of na- nants. This supplementary characters is called sandhangan tional culture, Javanese language needs to be preserved. The and can be seen in Figure 2 [5]. younger generation is now more interested in learning a for- Symbol Example Read eign language, rather than the native Indonesian local lan- guage. -

The Ordination of Women in the Early Middle Ages
Theological Studies 61 (2000) THE ORDINATION OF WOMEN IN THE EARLY MIDDLE AGES GARY MACY [The author analyzes a number of references to the ordination of women in the early Middle Ages in light of the meaning given to ordination at that time and in the context of the ministries of early medieval women. The changing definition of ordination in the twelfth century is then assessed in view of contemporary shifts in the understanding of the sacraments. Finally, a brief commentary is presented on the historical and theological significance of this ma- terial.] N HER PROVOCATIVE WORK, The Lady was a Bishop, Joan Morris argued I that the great mitered abbesses of the Middle Ages were treated as equivalent to bishops. In partial support of her contention, she quoted a capitulum from the Mozarabic Liber ordinum that reads “Ordo ad ordin- andam abbatissam.”1 Despite this intriguing find, there seems to have been no further research into the ordination of women in the early Middle Ages. A survey of early medieval documents demonstrates, however, how wide- spread was the use of the terms ordinatio, ordinare, and ordo in regard to the commissioning of women’s ministries during that era. The terms are used not only to describe the installation of abbesses, as Morris noted, but also in regard to deaconesses and to holy women, that is, virgins, widows, GARY MACY is professor in the department of theology and religious studies at the University of San Diego, California. He received his Ph.D. in 1978 from the University of Cambridge. Besides a history of the Eucharist entitled The Banquet’s Wisdom: A Short History of the Theologies of the Lord’s Supper (Paulist, 1992), he recently published Treasures from the Storehouse: Essays on the Medieval Eucharist (Liturgical, 1999). -

Sumerian Lexicon, Version 3.0 1 A
Sumerian Lexicon Version 3.0 by John A. Halloran The following lexicon contains 1,255 Sumerian logogram words and 2,511 Sumerian compound words. A logogram is a reading of a cuneiform sign which represents a word in the spoken language. Sumerian scribes invented the practice of writing in cuneiform on clay tablets sometime around 3400 B.C. in the Uruk/Warka region of southern Iraq. The language that they spoke, Sumerian, is known to us through a large body of texts and through bilingual cuneiform dictionaries of Sumerian and Akkadian, the language of their Semitic successors, to which Sumerian is not related. These bilingual dictionaries date from the Old Babylonian period (1800-1600 B.C.), by which time Sumerian had ceased to be spoken, except by the scribes. The earliest and most important words in Sumerian had their own cuneiform signs, whose origins were pictographic, making an initial repertoire of about a thousand signs or logograms. Beyond these words, two-thirds of this lexicon now consists of words that are transparent compounds of separate logogram words. I have greatly expanded the section containing compounds in this version, but I know that many more compound words could be added. Many cuneiform signs can be pronounced in more than one way and often two or more signs share the same pronunciation, in which case it is necessary to indicate in the transliteration which cuneiform sign is meant; Assyriologists have developed a system whereby the second homophone is marked by an acute accent (´), the third homophone by a grave accent (`), and the remainder by subscript numerals. -

Ahom Range: 11700–1174F
Ahom Range: 11700–1174F This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

Three Conquests of Canaan
ÅA Wars in the Middle East are almost an every day part of Eero Junkkaala:of Three Canaan Conquests our lives, and undeniably the history of war in this area is very long indeed. This study examines three such wars, all of which were directed against the Land of Canaan. Two campaigns were conducted by Egyptian Pharaohs and one by the Israelites. The question considered being Eero Junkkaala whether or not these wars really took place. This study gives one methodological viewpoint to answer this ques- tion. The author studies the archaeology of all the geo- Three Conquests of Canaan graphical sites mentioned in the lists of Thutmosis III and A Comparative Study of Two Egyptian Military Campaigns and Shishak and compares them with the cities mentioned in Joshua 10-12 in the Light of Recent Archaeological Evidence the Conquest stories in the Book of Joshua. Altogether 116 sites were studied, and the com- parison between the texts and the archaeological results offered a possibility of establishing whether the cities mentioned, in the sources in question, were inhabited, and, furthermore, might have been destroyed during the time of the Pharaohs and the biblical settlement pe- riod. Despite the nature of the two written sources being so very different it was possible to make a comparative study. This study gives a fresh view on the fierce discus- sion concerning the emergence of the Israelites. It also challenges both Egyptological and biblical studies to use the written texts and the archaeological material togeth- er so that they are not so separated from each other, as is often the case. -

Amarna Period Down to the Opening of Sety I's Reign
oi.uchicago.edu STUDIES IN ANCIENT ORIENTAL CIVILIZATION * NO.42 THE ORIENTAL INSTITUTE OF THE UNIVERSITY OF CHICAGO Thomas A. Holland * Editor with the assistance of Thomas G. Urban oi.uchicago.edu oi.uchicago.edu Internet publication of this work was made possible with the generous support of Misty and Lewis Gruber THE ROAD TO KADESH A HISTORICAL INTERPRETATION OF THE BATTLE RELIEFS OF KING SETY I AT KARNAK SECOND EDITION REVISED WILLIAM J. MURNANE THE ORIENTAL INSTITUTE OF THE UNIVERSITY OF CHICAGO STUDIES IN ANCIENT ORIENTAL CIVILIZATION . NO.42 CHICAGO * ILLINOIS oi.uchicago.edu Library of Congress Catalog Card Number: 90-63725 ISBN: 0-918986-67-2 ISSN: 0081-7554 The Oriental Institute, Chicago © 1985, 1990 by The University of Chicago. All rights reserved. Published 1990. Printed in the United States of America. oi.uchicago.edu TABLE OF CONTENTS List of M aps ................................ ................................. ................................. vi Preface to the Second Edition ................................................................................................. vii Preface to the First Edition ................................................................................................. ix List of Bibliographic Abbreviations ..................................... ....................... xi Chapter 1. Egypt's Relations with Hatti From the Amarna Period Down to the Opening of Sety I's Reign ...................................................................... ......................... 1 The Clash of Empires -

Baseandmodifiedcuneiformsigns.Pdf
12000 CUNEIFORM SIGN A 12001 CUNEIFORM SIGN A TIMES A 12002 CUNEIFORM SIGN A TIMES BAD 12003 CUNEIFORM SIGN A TIMES GAN2 TENU 12004 CUNEIFORM SIGN A TIMES HA 12005 CUNEIFORM SIGN A TIMES IGI 12006 CUNEIFORM SIGN A TIMES LAGAR GUNU 12007 CUNEIFORM SIGN A TIMES MUSH 12008 CUNEIFORM SIGN A TIMES SAG 12009 CUNEIFORM SIGN A2 1200A CUNEIFORM SIGN AB 1200B CUNEIFORM SIGN AB GUNU 1200C CUNEIFORM SIGN AB TIMES ASH2 1200D CUNEIFORM SIGN AB TIMES GIN2 1200E CUNEIFORM SIGN AB TIMES GAL 1200F CUNEIFORM SIGN AB TIMES GAN2 TENU 12010 CUNEIFORM SIGN AB TIMES HA 12011 CUNEIFORM SIGN AB TIMES IMIN 12012 CUNEIFORM SIGN AB TIMES LAGAB 12013 CUNEIFORM SIGN AB TIMES SHESH 12014 CUNEIFORM SIGN AB TIMES SIG7 12015 CUNEIFORM SIGN AB TIMES U PLUS U PLUS U 12016 CUNEIFORM SIGN AB2 12017 CUNEIFORM SIGN AB2 TIMES ASHGAB 12018 CUNEIFORM SIGN AB2 TIMES BALAG 12019 CUNEIFORM SIGN AB2 TIMES BI 1201A CUNEIFORM SIGN AB2 TIMES DUG 1201B CUNEIFORM SIGN AB2 TIMES GAN2 TENU 1201C CUNEIFORM SIGN AB2 TIMES GUD 1201D CUNEIFORM SIGN AB2 TIMES KAD3 1201E CUNEIFORM SIGN AB2 TIMES LA 1201F CUNEIFORM SIGN AB2 TIMES ME PLUS EN 12020 CUNEIFORM SIGN AB2 TIMES NE 12021 CUNEIFORM SIGN AB2 TIMES SHA3 12022 CUNEIFORM SIGN AB2 TIMES SIG7 12023 CUNEIFORM SIGN AB2 TIMES SILA3 12024 CUNEIFORM SIGN AB2 TIMES TAK4 12025 CUNEIFORM SIGN AB2 TIMES U2 12026 CUNEIFORM SIGN AD 12027 CUNEIFORM SIGN AK 12028 CUNEIFORM SIGN AK TIMES ERIN2 12029 CUNEIFORM SIGN AK TIMES SAL PLUS GISH 1202A CUNEIFORM SIGN AK TIMES SHITA PLUS GISH 1202B CUNEIFORM SIGN AL 1202C CUNEIFORM SIGN