UNIVERSITY of CALIFORNIA, SAN DIEGO Modeling the Visual Word Form Area Using a Deep Convolutional Neural Network a Thesis Submit
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cloud Fonts in Microsoft Office
APRIL 2019 Guide to Cloud Fonts in Microsoft® Office 365® Cloud fonts are available to Office 365 subscribers on all platforms and devices. Documents that use cloud fonts will render correctly in Office 2019. Embed cloud fonts for use with older versions of Office. Reference article from Microsoft: Cloud fonts in Office DESIGN TO PRESENT Terberg Design, LLC Index MICROSOFT OFFICE CLOUD FONTS A B C D E Legend: Good choice for theme body fonts F G H I J Okay choice for theme body fonts Includes serif typefaces, K L M N O non-lining figures, and those missing italic and/or bold styles P R S T U Present with most older versions of Office, embedding not required V W Symbol fonts Language-specific fonts MICROSOFT OFFICE CLOUD FONTS Abadi NEW ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Abadi Extra Light ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Note: No italic or bold styles provided. Agency FB MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Agency FB Bold ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Note: No italic style provided Algerian MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ 01234567890 Note: Uppercase only. No other styles provided. Arial MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Italic ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Bold ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Bold Italic ABCDEFGHIJKLMNOPQRSTUVWXYZ -

As Seen in the Translation Industry
Chinese Language & Culture As seen in the translation industry Introduction Prior to one of the most important celebrations in Asia - the Lunar New Year, we decided to share our next piece of extraordinary information with you. We have chosen a country quite famous for itself with rich traditions, interesting history and at the same time very different from the modern western world. In our small e-book, we’ve combined something famous, something small, and a bit of professional advice. We are glad to introduce to you our Chinese Language & Culture week. Welcome to our world! Gergana Toleva (Global Marketing Manager) Paper cutting The art of paper cutting is one of the most intricate arts with paper we’ve ever seen. It is oftentimes called chuāng huā ( ), window flowers or window paper- cuts as it was窗花 used to decorate windows and doors, so the light can shine through the cutout and create wondrous effects. They are usually made of red paper and symbolize luck and happiness. About Chinese Fonts When it comes to Chinese language, we don’t need to quote Traditional Chinese was used prior to 1954. Traditional numbers and statistics to convince someone that it’s one Chinese is still used widely in Chinatowns outside of China, of the most widely used languages in the world. Everyone as well as in Hong-Kong, Taiwan and Macau, where it’s the knows that. It’s a beautiful and fascinating language, and it official written language. In Mainland China, it’s used only in looks so different than most western languages that we’re extremely formal cases. -

Ultimate++ Forum It Higher Priority Now
Subject: It's suspected to be an issue with Font. Posted by Lance on Fri, 18 Mar 2011 22:50:28 GMT View Forum Message <> Reply to Message The programs I used to compare are UWord from the UPP, and MS Word. The platform is Windows 7. The text I used to test is: The problem with U++ drawed text is that some characters are notably larger than others and some have incorrect horizontal displacement. Please see attached picture for a visual effect. I also encountered issue where chinese characters are displayed correctly displayed on Windows but are blank on Ubuntu. And when I copies the same text that was displayed as blank to, say gedit, the text displayed correctly as in Windows. That part I will attach picture in future. File Attachments 1) font problem.png, downloaded 650 times Subject: Re: It's suspected to be an issue with Font. Posted by mirek on Sun, 10 Apr 2011 12:42:52 GMT View Forum Message <> Reply to Message Lance wrote on Fri, 18 March 2011 18:50The programs I used to compare are UWord from the UPP, and MS Word. The platform is Windows 7. The text I used to test is: The problem with U++ drawed text is that some characters are notably larger than others and some have incorrect horizontal displacement. It works fine on my Windows 7. However, I believe that the problem is caused by font substitution mechanism and perhaps on your system, you have some font that takes precendence for some glyphs, but does not contain other characters. -

Sketch Block Bold Accord Heavy SF Bold Accord SF Bold Aclonica Adamsky SF AFL Font Pespaye Nonmetric Aharoni Vet Airmole Shaded
Sketch Block Bold Accord Heavy SF Bold Accord SF Bold Aclonica Adamsky SF AFL Font pespaye nonmetric Aharoni Vet Airmole Shaded Airmole Stripe Airstream Alegreya Alegreya Black Alegreya Black Italic Alegreya Bold Alegreya Bold Italic Alegreya Italic Alegreya Sans Alegreya Sans Black Alegreya Sans Black Italic Alegreya Sans Bold Alegreya Sans Bold Italic Alegreya Sans ExtraBold Alegreya Sans ExtraBold Italic Alegreya Sans Italic Alegreya Sans Light Alegreya Sans Light Italic Alegreya Sans Medium Alegreya Sans Medium Italic Alegreya Sans SC Alegreya Sans SC Black Alegreya Sans SC Black Italic Alegreya Sans SC Bold Alegreya Sans SC Bold Italic Alegreya Sans SC ExtraBold Alegreya Sans SC ExtraBold Italic Alegreya Sans SC Italic Alegreya Sans SC Light Alegreya Sans SC Light Italic Alegreya Sans SC Medium Alegreya Sans SC Medium Italic Alegreya Sans SC Thin Alegreya Sans SC Thin Italic Alegreya Sans Thin Alegreya Sans Thin Italic AltamonteNF AMC_SketchyOutlines AMC_SketchySolid Ancestory SF Andika New Basic Andika New Basic Bold Andika New Basic Bold Italic Andika New Basic Italic Angsana New Angsana New Angsana New Cursief Angsana New Vet Angsana New Vet Cursief Annie BTN Another Typewriter Aparajita Aparajita Bold Aparajita Bold Italic Aparajita Italic Appendix Normal Apple Boy BTN Arabic Typesetting Arabolical Archive Arial Arial Black Bold Arial Black Standaard Arial Cursief Arial Narrow Arial Narrow Vet Arial Unicode MS Arial Vet Arial Vet Cursief Aristocrat SF Averia-Bold Averia-BoldItalic Averia-Gruesa Averia-Italic Averia-Light Averia-LightItalic -

H-1297-1, Creating Section 508 Compliant Documents
Form 1221-2 (June 1969) UNITED STATES DEPARTMENT OF THE INTERIOR Release BUREAU OF LAND MANAGEMENT 1-1766 Date MANUAL TRANSMITTAL SHEET 03/09/2015 Subject H-1297-1 Creating Section 508 Compliant Documents 1. Explanation of Material Transmitted: This handbook provides step-by-step instructions to assist BLM employees in creating accessible documents compliant with Section 508 of the Rehabilitation Act of 1973, as amended (29 U.S.C. 794d). Section 508 requires the federal government to ensure that the electronic and information technology that it develops, procures, maintains, or uses is accessible to persons with disabilities. 2. Reports Required: None. 3. Material Superseded: None. 4. Filing Instructions: File as directed below. REMOVE INSERT Total: 108 sheets Janine Valesco Assistant Director, Business, Fiscal, and Information Resources Management Handbook for Creating Section 508 Compliant Documents This document contains basic recommended guidelines for development of documents and PDF files. BLM Handbook Rel. No. 1-1766 03/09/2015 H-1297-1 Handbook for Creating Section 508 Compliant Documents (P) i Table of Contents Table of Contents ............................................................................................................................ i Chapter 1 - Introduction to 508 Compliance ............................................................................. 1-1 Chapter 2 - Microsoft Word Document Creation ...................................................................... 2-1 A. Font Group versus Style Group -
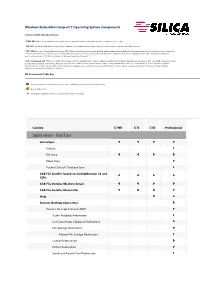
Windows Embedded Compact 7 Operating System Components
Windows Embedded Compact 7 Operating System Components Column and SKU listing Descriptions "C7NR" SKU : Offers key foundational operating system components targeted towards portable navigation devices only. "C7E" SKU : Provides OEMs with a comprehensive package of operating components to develop a wide variety of general embedded devices. "C7G" SKU : Provides Consumer Internet Device (CID) OEMs a competitive package that includes web browsing, media playback and messaging as well as foundati onal and connectivity technologies necessary for internet devices. These SKUs are ideal for set top boxes, portable media players, mobile internet devices, digital picture frames, digital media adapters, and eLearning devices. C7G SKU is available on Windo ws Embedded Compact 7. “C7P” Professional SKU : Offers the richest set of components and applications to enable complex consumer and enterprise class devices. Professional SKU can satisfy complex scenarios such as remote desktop connectivity, data sync via Active Sync, web browsing, media playback, email, contact management, and voice communication. It also includes a software development kit to allow devices to be customized and extended by end customers. Professional SKU is ideal for many device ca tegorie s including thin clients, mobile handheld terminals, and industrial automation controllers. OS Components Table Key Indicates that the corresponding catalog item is included in that particular run -time license. Denotes New Item Designates additional clarification appears at the end of the page -
Windows Embedded Compact 7 Components SKU Comparison
Windows Embedded Compact 7 Components SKU Comparison Column and SKU listing Descriptions "C7NR" SKU: Offers key foundational operating system components targeted towards portable navigation devices. "C7E" SKU: Provides OEMs with a comprehensive package of operating components to develop a wide variety of general embedded devices. "C7G" SKU: Provides Consumer Internet Device (CID) OEMs a competitive package that includes web browsing, media playback and messaging as well as foundational and connectivity technologies necessary for internet devices. These SKUs are ideal for set top boxes, portable media players, mobile internet devices, digital picture frames, digital media adapters, and eLearning devices. C7G SKU is available on Windows Embedded Compact 7. "C7P" SKU: Offers the richest set of components and applications to enable complex consumer and enterprise class devices. C7P SKU can satisfy complex scenarios such as remote desktop connectivity, data sync via Active Sync, web browsing, media playback, email, contact management, and voice communication. It also includes a software development kit to allow devices to be customized and extended by end customers. C7P SKU is ideal for many device categories including thin clients, mobile handheld terminals, and industrial automation controllers. "C7T" SKU: C7T provides RemoteFX out of the box as well as security technology like Kerberos, CredSSP and NTML technology so that your thin clients are enterprise ready. OS Components Table Key Indicates that the corresponding catalog item is included -
Top 10 Tips for Chinese Website Design
STAR TS Translation Services Confidence in a Translated World Automotive Health and Safety Public Sector Documentation Websites Technical Top 10 Tips for Chinese Website Design A short guide by Damian Scattergood STAR Technology Solutions, Docklands Innovation Park, 128-130 East Wall Road Dublin 3, Ireland Phone: +353 1 8365614 http://www.star-ts.com Contact: [email protected] STAR TS Translation Services ISO 9001:2008 Confidence in a Translated World BS: EN15038 Certified Docklands Innovation Park, 128-130 East Wall Road, Dublin 3, Ireland Phone: +353 (0) 1 8365614 Fax: +353 (0)1 8364644 Web: www.star-ts.com Email: [email protected] VAT No. IE 6378439J Company Reg. No. 358439 STAR TS Translation Services Confidence in a Translated World Chinese Website Design by STAR Translation Services With 44 global offices STAR provides technical translation services to clients around the world. As an ISO 9001 and EN 15038 certified company we can help you deliver the quality language documents, brochures, websites and services you require for your international business. Top 10 Tips for Chinese Website Design #1: Support UTF-8 UTF-8 enable your website. When choosing a website design system or content management system make sure it can display UTF-8 enabled fonts. You can set this up in most systems in the HTML metatags as you can see in the following snippet from our own website. <title>Translation Services, STAR Dublin, ISO9001, EN15038 Certified Translators</title> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"/> “UTF-8” is a character encoding system that will support virtually every character set in the world including European, Asian and Middle Eastern languages. -

NWCG Guidelines for Creating Accessible Electronic Documents
A publication of the National Wildfire Coordinating Group NWCG Guidelines for Creating Accessible Electronic Documents July 2020 Table of Contents Introduction to Accessibility .................................................................................................................... 1 NWCG Staff Support .............................................................................................................................. 1 Microsoft Word Document Creation ...................................................................................................... 1 New Document Setup .............................................................................................................................. 1 Formatting Documents ............................................................................................................................ 4 Tables .................................................................................................................................................... 20 Forms ..................................................................................................................................................... 24 Saving as a Template and Create Editable Regions .............................................................................. 24 Is Your Document Accessible? ............................................................................................................. 25 Additional Information ......................................................................................................................... -

A Japanese Text That Won't Render: こここここここここここここ Same Text with Fallbacks Available: この日本語
A Japanese text that won't render: こここここここここここここ Same text with fallbacks available: この日本語は表示されます Arial: The quick brown fox jumps over the lazy dog. Arial Black: The quick brown fox jumps over the lazy dog. Calibri: The quick brown fox jumps over the lazy dog. Calibri Light: The quick brown fox jumps over the lazy dog. Cambria: The quick brown fox jumps over the lazy dog. Cambria Math: The quick brown fox jumps over the lazy dog. Candara: The quick brown fox jumps over the lazy dog. Comic Sans MS: The quick brown fox jumps over the lazy dog. Consolas: The quick brown fox jumps over the lazy dog. Constantia: The quick brown fox jumps over the lazy dog. Corbel: The quick brown fox jumps over the lazy dog. Courier New: The quick brown fox jumps over the lazy dog. Ebrima: The quick brown fox jumps over the lazy dog. Franklin Gothic Medium: The quick brown fox jumps over the lazy dog. Gabriola: The quick brown fox jumps over the lazy dog. Gadugi: The quick brown fox jumps over the lazy dog. Georgia: The quick brown fox jumps over the lazy dog. Impact: The quick brown fox jumps over the lazy dog. Javanese Text: The quick brown fox jumps over the lazy dog. Leelawadee UI: The quick brown fox jumps over the lazy dog. Lucida Console: The quick brown fox jumps over the lazy dog. Lucida Sans Unicode: The quick brown fox jumps over the lazy dog. Malgun Gothic: The quick brown fox jumps over the lazy dog. arlettr he quick brown fox jumps over the M T la y dogf z Microsoft Himalaya: The quick brown fox jumps over the lazy dog. -

Font Samples
Beyond Sky 28 Days Later 4th and Inches @Premier League with Lion Numbe A Charming Font A Charming Font Expanded A Charming Font Italic A Charming Font Leftleaning A Charming Font Outline A Charming Font Superexpanded Aachen-Bold Action Jackson AdLib BT AdLib WGL4 BT Adobe Arabic Adobe Fan Heiti Std B Adobe Gothic Std B Adobe Hebrew Adobe Heiti Std R Adobe Ming Std L Adobe Myungjo Std M Adobe Song Std L Adobe Thai Adumu Adumu Inline Aerospace BT Aerovias Brasil NF Agency FB Agfa Rotis Sans Serif Airstream Akron Aldine401 BT Aldine721 BdCn BT Aldine721 BT Aldine721 Lt BT Alex Brush Algerian Algerian Basic D Alien Encounters Alien Encounters Solid Allegro BT AlphabetSoup Tilt BT AlternateGothic2 BT Altrincham AltrinchamConReg Amazone BT Amelia BT American Captain Americana BT Americana XBd BT Americana XBdCn BT AmericanText BT AmeriGarmnd BT Amerigo BT Amerigo Md BT Amienne AndrewScript_1.6 ANGEL TEARS Animals 1 Animals 2 Another Round Antlers Demo AquilineTwo Arial Arial Black Arial Narrow Arial Rounded MT Bold Arial Unicode MS Armed and Traitorous Aromatica Aromatica Bold Aromatica ExtraLight Aromatica Light Aromatica Patterns Aromatica Script Aromatica SemiBold Arrows1 Arrows2 Arrus Blk BT Arrus Blk OSF BT Arrus BT Arrus Ext BT Arrus OSF BT Arrus SmCap BT Ashyhouse Assembled From Scratch AURORA Aurora BdCn BT Aurora Cn BT Avenir LT Std 35 Light Avenir LT Std 65 Medium Awards Bad Coma Bad Signal Badger Bold Badger Heavy Badger Light Bahnhof Ultra Bahnschrift Bahnschrift Condensed Bahnschrift Light Bahnschrift Light Condensed Bahnschrift -

Guide to in Microsoft Office
NOVEMBER 2019 Guide to Cloud Fonts in Microsoft® Office 365® Cloud fonts are available to Office 365 subscribers on all platforms and devices. Documents that use cloud fonts will render correctly in Office 2019. Embed cloud fonts for use with older versions of Office. Reference article from Microsoft: Cloud fonts in Office DESIGN TO PRESENT Terberg Design, LLC Index MICROSOFT OFFICE CLOUD FONTS A B C D E Legend: F G H I J Good choice for theme body fonts Okay choice for theme body fonts K L M N O Includes serif typefaces, non-lining figures, and those missing italic and/or bold styles P Q R S T Present with most older versions of Office, embedding not required U V W Symbol fonts Language-specific fonts MICROSOFT OFFICE CLOUD FONTS Abadi NEW ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Abadi Extra Light ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Note: No italic or bold styles provided. Agency FB MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Agency FB Bold ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Note: No italic style provided Algerian MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ 01234567890 Note: Uppercase only. No other styles provided. Arial MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Italic ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Bold ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Bold Italic ABCDEFGHIJKLMNOPQRSTUVWXYZ