Timing Is Everything: a Field Study of Subway Reliability
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MTA Capital Program 2008–2013
MTA Capital Program 2008–2013 February 2008 TABLE OF CONTENTS Page Overview: The MTA 2008-2013 Capital Program-- - i - “Building for the Future on a Firm Foundation” 2008-2013 Introduction: Investment Summary and Program Funding - 1 - I. Core CPRB Capital Program - 7 - MTA NYC Transit 2008-2013 Capital Program - 13 - Overview Program Plan MTA Long Island Rail Road 2008-2013 Capital Program - 45 - Overview Program Plan MTA Metro-North Railroad 2008-2013 Capital Program - 73 - Overview Program Plan MTA Bus Company 2008-2013 Capital Program - 101 - Overview Program Plan MTA Security 2008-2013 Capital Program - 111 - Overview Introduction MTA Interagency 2008-2013 Capital Program - 115 - Overview Program Plan II. Capacity Expansion - 123 - Completing the Current Expansion Projects: MTA Capital Construction Company: - 125 - Overview Program plan East Side Access Second Avenue Subway Fulton Street Transit Center South Ferry Terminal Regional Investments Miscellaneous 2005-2009 Capital Program New Capacity Expansion Investments - 141 - Overview Investments to Implement Congestion Pricing New Capacity Expansions to Support Regional Growth Communications Based Train Control Second Avenue Subway Next Phase Penn Station Access Jamaica Capacity Improvements #7 Fleet Expansion Capacity Planning Studies Sustainability Investments Program Project Listings (blue pages) - 149 - (not paginated; follows order above, beginning with blue pages for MTA NYC Transit and ending with blue pages for MTA Capital Construction Company) MTA Bridges and Tunnels 2008-2013 Capital Program - B-1 - Overview Program Plan Program Project Listings - B-25 - 2005-2009 Capital Program THE 2008-2013 CAPITAL PROGRAM: Building for the Future on a Firm Foundation In the early 1960’s, the New York Metropolitan Region’s mass transportation network faced financial collapse and a crisis of capacity. -

The Bulletin the MILEPOSTS of THE
ERA BULLETIN — JANUARY, 2017 The Bulletin Electric Railroaders’ Association, Incorporated Vol. 60, No. 1 January, 2017 The Bulletin THE MILEPOSTS OF THE Published by the Electric NEW YORK SUBWAY SYSTEM Railroaders’ Association, Incorporated, PO Box by ERIC R. OSZUSTOWICZ 3323, New York, New York 10163-3323. Many of us are familiar with the chaining three former divisions (plus the Flushing and system for the tracks of the New York sub- Canarsie Lines) had one zero point. Most of For general inquiries, or way system. Each track on the system has a these signs have been removed due to vari- Bulletin submissions, marker every 50 feet based on a “zero point” ous construction projects over the years and contact us at bulletin@ for that particular track. For example, the ze- were never replaced. Their original purpose erausa.org. ERA’s ro point for the BMT Broadway Subway is is unknown, but shortly after their installation, website is just north of 57th Street-Seventh Avenue. The they quickly fell into disuse. www.erausa.org. southbound local track is Track A1. 500 feet Over the years, I have been recording and Editorial Staff: south of the zero point, the marker is photographing the locations of the remaining Editor-in-Chief: A1/5+00. One hundred fifty feet further south, mileposts before they all disappear com- Bernard Linder the marker is A1/6+50. If you follow the line pletely. These locations were placed on a Tri-State News and all the way to 14th Street-Union Square, one spreadsheet. Using track schematics show- Commuter Rail Editor: Ronald Yee will find a marker reading A1/120+00 within ing exact distances, I was able to deduce the North American and World the station. -

August 2007 Bulletin.Pub
TheNEW YORK DIVISION BULLETIN - AUGUST, 2007 Bulletin New York Division, Electric Railroaders’ Association Vol. 50, No. 8 August, 2007 The Bulletin SECOND AVENUE SUBWAY Published by the New WILL BE ENERGY-EFFICIENT York Division, Electric WILL BE ENERGY-EFFICIENT Railroaders’ Association, Incorporated, PO Box The Second Avenue Subway is the biggest Federal Emergency Management Agency’s 3001, New York, New expansion in decades of New York City’s flood maps, which establish flood elevations York 10008-3001. public transportation system. Scheduled for for a 50-year flood, 100-year flood, and 500- completion in 2013, Phase One includes the year flood for each area. In new construction, extension of Q service, with stations at 72nd all entrances, exits, and openings from the For general inquiries, th th contact us at nydiv@ Street, 86 Street, and 96 Street. station and tunnel will be built at least one electricrailroaders.org NYC Transit’s April, 2007 At Your Service foot above the 100-year flood elevation. All or by phone at (212) newsletter describes the energy-efficient fea- underground construction will be water- 986-4482 (voice mail tures of the new subway. In 2004, NYC Tran- proofed and will have pump rooms. The older available). ERA’s subway lines have street gratings which pro- website is sit won the Green Building Design Award for www.electricrailroaders. station skylights, energy-efficient lighting, vide ventilation with the piston action of the org. energy-efficient aluminum third rails, and es- trains. The Second Avenue Subway will not calators that run at a reduced speed when have any street gratings, but will have open- Editorial Staff: they are not used. -

Brooklyn-Queens Greenway Guide
TABLE OF CONTENTS The Brooklyn-Queens Greenway Guide INTRODUCTION . .2 1 CONEY ISLAND . .3 2 OCEAN PARKWAY . .11 3 PROSPECT PARK . .16 4 EASTERN PARKWAY . .22 5 HIGHLAND PARK/RIDGEWOOD RESERVOIR . .29 6 FOREST PARK . .36 7 FLUSHING MEADOWS CORONA PARK . .42 8 KISSENA-CUNNINGHAM CORRIDOR . .54 9 ALLEY POND PARK TO FORT TOTTEN . .61 CONCLUSION . .70 GREENWAY SIGNAGE . .71 BIKE SHOPS . .73 2 The Brooklyn-Queens Greenway System ntroduction New York City Department of Parks & Recreation (Parks) works closely with The Brooklyn-Queens the Departments of Transportation Greenway (BQG) is a 40- and City Planning on the planning mile, continuous pedestrian and implementation of the City’s and cyclist route from Greenway Network. Parks has juris- Coney Island in Brooklyn to diction and maintains over 100 miles Fort Totten, on the Long of greenways for commuting and Island Sound, in Queens. recreational use, and continues to I plan, design, and construct additional The Brooklyn-Queens Greenway pro- greenway segments in each borough, vides an active and engaging way of utilizing City capital funds and a exploring these two lively and diverse number of federal transportation boroughs. The BQG presents the grants. cyclist or pedestrian with a wide range of amenities, cultural offerings, In 1987, the Neighborhood Open and urban experiences—linking 13 Space Coalition spearheaded the parks, two botanical gardens, the New concept of the Brooklyn-Queens York Aquarium, the Brooklyn Greenway, building on the work of Museum, the New York Hall of Frederick Law Olmsted, Calvert Vaux, Science, two environmental education and Robert Moses in their creations of centers, four lakes, and numerous the great parkways and parks of ethnic and historic neighborhoods. -
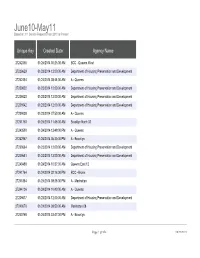
June10-May11 Based on 311 Service Requests from 2010 to Present
June10-May11 Based on 311 Service Requests from 2010 to Present Unique Key Created Date Agency Name 27242358 01/24/2014 08:25:00 AM BCC - Queens West 27239629 01/23/2014 12:00:00 AM Department of Housing Preservation and Development 27242454 01/24/2014 08:44:00 AM A - Queens 27239622 01/23/2014 12:00:00 AM Department of Housing Preservation and Development 27239420 01/23/2014 12:00:00 AM Department of Housing Preservation and Development 27239342 01/23/2014 12:00:00 AM Department of Housing Preservation and Development 27239038 01/23/2014 07:50:00 AM A - Queens 27241760 01/24/2014 11:45:00 AM Brooklyn North 03 27243590 01/24/2014 12:49:00 PM A - Queens 27242967 01/24/2014 06:30:00 PM A - Brooklyn 27239664 01/23/2014 12:00:00 AM Department of Housing Preservation and Development 27239681 01/23/2014 12:00:00 AM Department of Housing Preservation and Development 27243488 01/24/2014 10:37:00 AM Queens East 12 27241764 01/24/2014 02:16:00 PM BCC - Bronx 27241884 01/24/2014 09:38:00 PM A - Manhattan 27244136 01/24/2014 10:40:00 AM A - Queens 27239617 01/23/2014 12:00:00 AM Department of Housing Preservation and Development 27240670 01/24/2014 08:50:00 AM Manhattan 08 27240768 01/24/2014 03:47:00 PM A - Brooklyn Page 1 of 956 09/29/2021 June10-May11 Based on 311 Service Requests from 2010 to Present Incident Complaint Type Descriptor Zip Missed Collection (All Materials) 1R Missed Recycling-All Materials 11379 HEATING HEAT 10453 Snow E9 Snow / Icy Sidewalk 11372 HEATING HEAT 11435 HEATING HEAT 11221 HEATING HEAT 10463 Snow E9 Snow / Icy Sidewalk 11367 Snow 15S Re-Plow/Spread/Ice-Snow Cond. -

Finance Committee Meeting
Finance Committee Meeting March 2017 Committee Members L. Schwartz, Chair F. Ferrer, Vice Chair I. Greenberg* D. Jones C. Moerdler J. Molloy M. Pally J. Samuelsen P. Trottenberg V. Vanterpool J. Vitiello P. Ward C. Wortendyke N. Zuckerman Finance Committee Meeting 2 Broadway, 20th Floor Board Room New York, NY 10004 Monday, 3/20/2017 12:30 - 1:45 PM ET 1. PUBLIC COMMENTS PERIOD 2. APPROVAL OF MINUTES – FEBRUARY 21, 2017 Finance Committee Minutes - Page 4 3. 2017 COMMITTEE WORK PLAN 2017 Work Plan - Page 12 4. BUDGETS/CAPITAL CYCLE BudgetWatch (Handout) Finance Watch Finance Watch - Page 20 5. MTA HEADQUARTERS & ALL-AGENCY ITEMS Action Items 2016 Annual Procurement Report (Full Report Available in the Document Center and MTA.Info) - Page 32 Report and Information Items MTA Prompt Payment Annual Report 2016 - Page 33 4th Quarter Finance Change Order Report - Page 39 Procurements MTAHQ Procurement Report - Page 42 MTAHQ Competitive Procurements - Page 44 6. METRO-NORTH RAILROAD (No Items) 7. LONG ISLAND RAIL ROAD (No Items) 8. NEW YORK CITY TRANSIT, and MTA BUS OPERATIONS NYCT & MTA Bus Procurements - Page 54 9. BRIDGES AND TUNNELS B & T Procurements - Page 62 10. FIRST MUTUAL TRANSPORTATION ASSURANCE COMPANY (No Items) 11. MTA CONSOLIDATED REPORTS Statement of Operations - Page 72 Overtime Report - Page 79 Subsidy, Interagency Loans and Stabilization Fund Transactions - Page 83 Debt Service - Page 91 Positions - Page 93 Farebox Ratios - Page 96 MTA Ridership - Page 97 Fuel Hedge Program - Page 121 12. REAL ESTATE AGENDA Action Items Real Estate Action Items - Page 124 Property Disposition Guidelines (Available in the Exhibit Book and MTA.Info) Report and Information Items Real Estate Info Items - Page 164 Date of next meeting: April 24, 2017 @ 12:00 PM Minutes of the MTA Finance Committee Meeting February 2 Broadway, 20th Floor Board Room New York, NY 10004 12:00 PM The following Finance Committee members attended: Hon. -

Metropolitan Transportation Authority (MTA) Contract Solicitations
Eye On The Future - Metropolitan Transportation Authority (MTA) Contract Solicitations Reference Number Agency Agency Description S47009/S32398/S32399 NYCT New York City Transit SF02-8129 NYCT New York City Transit C34846 NYCT New York City Transit A36949 NYCT New York City Transit P36339 NYCT New York City Transit R34253 NYCT New York City Transit BW-63/TN-63 B&T Bridges and Tunnels P36483 NYCT New York City Transit A37119 / A38100 NYCT New York City Transit E34026 NYCT New York City Transit A46029 NYCT New York City Transit A37208 NYCT New York City Transit Page 1 of 285 09/26/2021 Eye On The Future - Metropolitan Transportation Authority (MTA) Contract Solicitations Type of Contract Duration of Contract Construction 59 Purchase Construction 10 Construction 10 Construction 25 Purchase 30 Constr 18 Construction 24 Construction 18 Construction 30 Construction 20 Construction 11 Page 2 of 285 09/26/2021 Eye On The Future - Metropolitan Transportation Authority (MTA) Contract Solicitations Contract Description Communication Based Train Control (CBTC): Two Interlockings and Signal Overlay / Culver Line** Purchase 45 Standard Electric Buses** DCE Shop Components - Phase 3 / Jerome Aqueduct-North Conduit Av / RKY Repl Control & Battery Cable: 4 Substn Cntrl Zones (2/3/5/8) Purchase of 12 3-Ton Crane Cars Construction: Open Road Tolling Initiative - Paving and Landscaping Reconstruction of CBH # 392 - Flushing River Bridge Intermodal and ADA: Canarsie-Rockaway Pkwy / Canarsie Replace 11 Hydraulic Elevators / Various** Station Renewal: 69 Street / Flushing Subway Stairs: 34 St-Herald Sq / Bdwy (S8) [SBMP] Page 3 of 285 09/26/2021 Eye On The Future - Metropolitan Transportation Authority (MTA) Contract Solicitations Project Description Solicitation Month To implement Communication Based Train Control (CBTC) Signal System Rehabilitation from JUN Church Ave. -

Franklin Ave Rezoning EAS Part 2 – November 9, 2016
Franklin Avenue Rezoning EAS Attachment E: Community Facilities developments in the future without the Proposed Action. This would increase projected enrollment to 1,783, resulting in a collective utilization rate of 85.2 percent, with 310 available day care slots (refer to Table E- 8) in the future without the Proposed Action. Table E-8: No-Action Public Day Care Enrollment and Capacity Changes Capacity Projected Enrollment Available Slots Utilization (%) 2,093 1,783 310 85.2 Notes: 1 No child care center capacity changes are anticipated in the No-Action Scenario. 2 Projected Enrollment is calculated by adding the projected new public child care-eligible children (Table E-7) to the existing publicly- funded group day care enrollment in the study area (Table E-6). The Future With the Proposed Action (With-Action Condition) As described in Attachment A, “Project Description,” in the RWCDS With-Action condition, the Proposed Action would facilitate a net increment of 284 DUs (151 of which would be affordable units). As shown in Table E-9, based on CEQR student generation rates, the Proposed Action is expected to result in an additional 27 children eligible for publicly-funded day care by 2023. Table E-9: With-Action Number of Public Day Care Pupils Generated by the Proposed Action Number of Child Care- Affordable DU Generation Ratio per Unit1 Eligible Children 151 0.178 27 Notes: 1Pupil Generation Ratios are for the borough of Brooklyn, as per Table 6-1b of the 2014 CEQR Technical Manual. As described above, under No-Action conditions, the day care utilization rate for the study area is expected to be 93.1 percent. -

AGENCY FULL BLUE PAGES WITHOUT FOOTER.Xlsx
MTA Capital Program 2010-2014 Amendment as submitted to the MTA CAPITAL PROGRAM REVIEW BOARD January 2012 Introduction On September 29, 2009, the MTA Board approved a proposed $28.080 billion 2010-2014 Capital Program and submitted that plan to the Capital Program Review Board (CPRB) in October 2009, requesting their approval of the $25.572 billion CPRB portion of that plan (excludes Bridges and Tunnels, which self-funds its program). On December 31, 2009, the CPRB vetoed that plan without prejudice to permit additional time to resolve issues related to fully funding the program. Subsequently, the MTA prepared a revised program totaling $23.812 billion, reflecting a nearly $2 billion reduction effort to sharpen the focus of the program to ensure the delivery of specific customer benefits for the lowest cost. The MTA Board approved the revised plan on April 28, 2010 and the CPRB approved the five-year program of projects on June 1, 2010. The approved program fully funded only the first two years (2010 and 2011) of the plan, with a commitment to come back to CPRB with a funding proposal for the last three years. Proposed Amendment This plan amendment, approved by the MTA Board in December 2011, funds all of the projects in the last three years of the program through a combination of self-help (efficiency improvements and real estate initiatives), participation by our funding partners and innovative and pragmatic financing arrangements. The revised CPRB $22.195 billion plan also spreads projects out evenly over the final three years of the program as listed on the attached blue pages. -

August 2010 Bulletin REVISED.Pub
TheNEW YORK DIVISION BULLETIN - AUGUST, 2010 Bulletin New York Division, Electric Railroaders’ Association Vol. 53, No. 8 August, 2010 The Bulletin TWO RIVER TUNNELS OPENED 90 YEARS AGO Published by the New With the opening of the Montague Street clearance trains operated on the Franklin York Division, Electric Tunnel and the 60th Street Tunnel on August Avenue Shuttle on May 7 and 9, 1924. The Railroaders’ Association, Incorporated, PO Box 1, 1920, BRT service was increased. Under next day Franklin-Chambers expresses 3001, New York, New the old schedule, Brighton riders were al- started running from May to September on York 10008-3001. lowed a one-seat five-cent ride only as far as warm, sunny Saturday afternoons and Sun- Park Row. Starting 2 AM August 1, 1920 days. Trains in this service made express through service was operated on the Brigh- stops on the Brighton Line to Coney Island, For general inquiries, contact us at nydiv@ ton Line from Coney Island through lower after which they operated on the Sea Beach th th erausa.org or by phone and midtown Manhattan to Queensborough middle. Trains stopped at 59 Street, 36 at (212) 986-4482 (voice Plaza. Street, and Pacific Street, bypassed DeKalb mail available). The The following service was operated before Avenue and Myrtle Avenue, crossed the Division’s website is www.erausa.org/ and after August 1, 1920: Manhattan Bridge, and terminated at Cham- nydiv.html. bers Street. LINE UNTIL AUGUST STARTING AU- MANHATTAN BRIDGE SERVICE 1, 1920 GUST 1, 1920 Editorial Staff: The tracks are located on both sides of the Editor-in-Chief: Fourth Avenue 86th Street to 86th Street to bridge, which tilts slightly with each passing Bernard Linder Local Chambers Street Queensborough train. -

Land Use, Zoning, and Public Policy A. INTRODUCTION
Chapter 3: Land Use, Zoning, and Public Policy A. INTRODUCTION The proposed project would significantly change land use on a large, prominently located—but underutilized—site, at the crossroads of Brooklyn’s two most important avenues, adjacent to a major public transportation hub, and at the intersection of six distinct neighborhoods. This development would fill the void resulting from the below-grade Vanderbilt Yard (the “rail yard”), eliminate blight, and integrate neighborhoods historically divided by this rail yard. The project would introduce, for the first time in 50 years, an arena for a major sports team in the heart of Brooklyn. It would surround that arena with a broad mix of retail, hotel, office, residential, community facility, and open space uses (see Chapter 1, “Project Description,” for details). Because this is a major land use plan situated in a key location in Brooklyn, the potential for impact on land use on the project site and in the surrounding area and neighborhoods is an important consideration in this EIS. Several issues of public policy also arise in connection with the proposed project. Implementation of the development would be subject to the land use and design controls of the General Project Plan (GPP) for the Atlantic Yards Land Use Improvement and Civic Project, administered by the Empire State Development Corporation (ESDC). This GPP would apply in lieu of local City zoning—the City has been consulted and involved during the site plan review process—so that rezoning would not be required. Nonetheless, the issue of compatibility with local zoning must be considered as part of this environmental analysis. -

The Related Entities
APPENDIX A THE RELATED ENTITIES This Appendix A is dated April 30, 2014 and contains information only through that date (or the specific earlier dates noted herein, such as year-end December 31, 2013 financial and statistical information). MTA intends to update and supplement specific information contained herein (1) through revised Continuing Disclosure Filings, (2) as part of its quarterly financial statement reports, and (3) in connection with its periodic issuance of bonds, notes and other obligations. MTA expects to file such updated and supplemental information with the Municipal Securities Rulemaking Board and its Electronic Municipal Market Access system (“EMMA”) and may incorporate such information herein by specific cross-reference. Such information is also posted on the MTA website under “About the MTA – Financial Information” at www.mta.info for convenience. All of the information is accurate as of its respective date. MTA retains the right to update and supplement specific information contained herein as events warrant. Certain statements included in this Appendix A constitute “forward-looking statements.” Such statements generally are identifiable by the terminology used, such as “plan,” “expect,” “estimate,” “budget,” “project,” “forecast” or other similar words. Such forward-looking statements include, but are not limited to, certain statements contained in the information under the captions “FINANCIAL INFORMATION – FINANCIAL PLANS AND CAPITAL PROGRAMS” and “PUBLIC DEBT SECURITIES AND OTHER FINANCIAL INSTRUMENTS.” The achievement of certain results or other expectations contained in such forward-looking statements involve known and unknown risks, uncertainties and other factors that may cause actual results, performance or achievements described to be materially different from any future results, performance or achievements expressed or implied by such forward-looking statements.