Mysql Reference Manual
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mysql Presentation
MySQL Presentation Group members: Marco Tony Kassis Nourhan Sakr Roba Bairakdar Outline S What is MySQL? S History S Uses S Platforms and Interfaces S GUIs S Syntax S Why MySQL? What is MySQL? S It is the world’s most commonly used RDBMS S It is named after developer Michael Widenius; daughter, MY S Its source code is available under the terms of the GNU General Public License. S MySQL was owned and sponsored by a single for-profit firm, the Swedish company MySQL AB, now owned by Oracle Corporation S MySQL is used in high-profile, large-scale World Wide Web products, including Wikipedia, Google, Facebook and Twitter. History S Originally developed by Michael Widenius and David Axmark in 1994 S First release on 23rd of May 1995 S Windows version was released in 1998 S … S MySQL server 5.5 was released in December 2010 Uses S It is the most popular choice of database for use in web applications S It is a central component of the widely used LAMP open source web application software stack (LAMP: Linux, Apache, MySQL, Perl/PHP/Python) Platforms and interfaces S MySQL is written in C and C++ S It works on many different system platforms, including Linux, Mac OS X, Solaris, etc. S Some programming languages include libraries for accessing MySQL databases. These include MySQL Connector/Net for integration with Microsoft’s Visual Studio and JDBC driver for Java Graphical User Interface S MySQL has no GUI tools to administer the databases or manage the data contained S Official MySQL Workbench enables users to graphically administer MySQL databases -

Mr. Marten Mickos, CEO, Mysql AB
Monetary and Social Economics of Information Sharing Fujitsu Labs of America Technology Symposium 2007 Mårten Mickos, CEO, MySQL AB Copyright 2007 MySQL AB The World’s Most Popular Open Source Database 1 "The future is here, it's just not widely distributed yet." William Gibson Copyright 2007 MySQL AB The World’s Most Popular Open Source Database 2 The World is Going Online 1 billion internet users - nearly 3 billion mobile phone users Copyright 2007 MySQL AB The World’s Most Popular Open Source Database 3 Disruptive Innovations SOFTWARE BUSINESS DEVELOPMENT MODEL MODEL ONLINE ROLE OF ORGANISATIONAL SOFTWARE MODEL Copyright 2007 MySQL AB The World’s Most Popular Open Source Database 4 The Internet Keeps Growing Netcraft: Total Sites Across All Domains August 1995 - October 2007 Copyright 2007 MySQL AB The World’s Most Popular Open Source Database 5 From Web to Enterprise 66% Are Deploying MySQL or Are Planning To Copyright 2007 MySQL AB The World’s Most Popular Open Source Database 6 Online, People ... Communicate ... Connect ... Share ... Play ... Trade ... craigslist Search & Look Up Copyright 2007 MySQL AB The World’s Most Popular Open Source Database 7 An Architecture of Participation Time Magazine 2006 Person of the Year: You Copyright 2007 MySQL AB The World’s Most Popular Open Source Database 8 Why Software Freedom is so Powerful Number of developers who built our current information Number of developers on the society internet today. 100X Copyright 2007 MySQL AB The World’s Most Popular Open Source Database 9 Production by Amateurs "The highest and best form of efficiency is the spontaneous cooperation of a free people." Bernard Baruch, Financier and Roosevelt advisor, 1870-1965 Alla of the above run on MySQL. -

Guide to Secure Software Development in Ruby
Fedora Security Team Secure Ruby Development Guide Guide to secure software development in Ruby Ján Rusnačko Secure Ruby Development Guide Fedora Security Team Secure Ruby Development Guide Guide to secure software development in Ruby Edition 1 Author Ján Rusnačko [email protected] Copyright © 2014 Ján Rusnačko. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. The original authors of this document, and Red Hat, designate the Fedora Project as the "Attribution Party" for purposes of CC-BY-SA. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, MetaMatrix, Fedora, the Infinity Logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. For guidelines on the permitted uses of the Fedora trademarks, refer to https://fedoraproject.org/wiki/ Legal:Trademark_guidelines. Linux® is the registered trademark of Linus Torvalds in the United States and other countries. Java® is a registered trademark of Oracle and/or its affiliates. XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. -

Embedded Systems
Sri Chandrasekharendra Saraswathi Viswa Maha Vidyalaya Department of Electronics and Communication Engineering STUDY MATERIAL for III rd Year VI th Semester Subject Name: EMBEDDED SYSTEMS Prepared by Dr.P.Venkatesan, Associate Professor, ECE, SCSVMV University Sri Chandrasekharendra Saraswathi Viswa Maha Vidyalaya Department of Electronics and Communication Engineering PRE-REQUISITE: Basic knowledge of Microprocessors, Microcontrollers & Digital System Design OBJECTIVES: The student should be made to – Learn the architecture and programming of ARM processor. Be familiar with the embedded computing platform design and analysis. Be exposed to the basic concepts and overview of real time Operating system. Learn the system design techniques and networks for embedded systems to industrial applications. Sri Chandrasekharendra Saraswathi Viswa Maha Vidyalaya Department of Electronics and Communication Engineering SYLLABUS UNIT – I INTRODUCTION TO EMBEDDED COMPUTING AND ARM PROCESSORS Complex systems and micro processors– Embedded system design process –Design example: Model train controller- Instruction sets preliminaries - ARM Processor – CPU: programming input and output- supervisor mode, exceptions and traps – Co- processors- Memory system mechanisms – CPU performance- CPU power consumption. UNIT – II EMBEDDED COMPUTING PLATFORM DESIGN The CPU Bus-Memory devices and systems–Designing with computing platforms – consumer electronics architecture – platform-level performance analysis - Components for embedded programs- Models of programs- -

1999 Nendo Supercompiler Te
NEDO-PR- 9 90 3 x-A°-=i wu ? '7-z / □ ixomgffi'g. NEDOBIS T93018 #f%4vl/4=- — 'I'Jff&'a fi ISEDQ mb'Sa 3a 0-7 rx-/<-n>/<^7-T^yovOIElS9f%l TR&1 2^3^ A 249H illK t>*^#itafc?iJI+WE$>i=t^<bLfc3>/U7S#r$u:|-^n S & - *%#$............. (3) (5) m #.......... (7) Abstract............ (9) m #?'Hb3>/W3## i 1.1 # i 1.2 g ##Wb3 7 ©&ffitib[p].................................................... 3 1.2.1 ............................................................................... 3 1.2.2 ^ y ........................................................................ 18 1.2.3 OpenMP 43,fctf OpenMP ©x-^fcKlfOttfcifeSi................. 26 1.2.4 #%3 >;W ly —^ 3 .............................................. 39 1.2.5 VLIW ^;i/3£#Hb.................................................................... 48 1.2.6 ........................ 62 1.2.7 3>;W7 <b)## p/i-f-zL —- > py—............... 72 1.2.8 3 >;w 3©##E#m©##mm.............................................. 82 1.2.9 3°3-tr y +1 © lb fp] : Stanford Hydra Chip Multiprocessor 95 1.2.10 s^^Eibrniiis : hpca -6 .............................. 134 1.3 # b#^Hb3>/W7^#m%................. 144 1.3.1 m # 144 1.3.2 145 1.3.3 m 152 1.3.4 152 2$ j£M^>E3 >hajL-T-^ 155 2.1 M E......................................................................................................................... 155 2.2 j£M5>i(3 > b° j-—x 4“ >^"©&Hlib[p] ........................................................... 157 2.2.. 1 j[£WtS(3>h0a.-:r^ >^'©51^............................................................ 157 2.2.2 : Grid Forum99, U.C.B., JavaGrande Portals Group Meeting iZjotf & ti^jSbfp] — 165 2.2.3 : Supercomputing99 iZlotf & ££l/tribip].................... 182 2.2.4 Grid##43Z^^m^m^^7"A Globus ^©^tn1 G: Hit* £ tiWSbfp] ---- 200 (1) 2.3 ><y(D mmtmrn...... -
Securecrt 7.3.6 Crack for Mac >>>
Securecrt 7.3.6 Crack For Mac >>> http://shurll.com/77o35 1 / 5 2 / 5 hash,,47850D6A1C717CEC4534B14525ED9BF2292DD905,,... VanDyke,,SecureCRT,,and,,SecureFX,,7 .3.6,,[Mac,,Os,,X],,[MAC599],,DOWNLOAD,,TORRENTSecureCRT,,for,,Mac,,OS,,X,,7.1... VanDyke,,Secu reCRT,,and,,SecureFX,,7.3.6,,[Mac,,Os,,X].torrent,,내부,,파일,,..Turn,,,your,,,computer,,,into,,,a,,,terminal,, ,server,,,using,,,Serial,,,to,,,Ethernet,,,Converter,,,with,,,its,,,amazing,,,capability,,,to,,,share,,,serial,,, devices,,,in,,,... Free,,,Download,,,SecureCRT,,,for,,,Mac,,,8.1.3,,,Build,,,1382,,,-,,,A,,,fully-featured,,,te rminal,,,emulator,,,as,,,well,,,as,,,a,,,SSH,,,and,,,Telnet,,,client,,,with,,,advanced,,,session,,,mana... Do wnload,,,VanDyke,,,SecureCRT,,,and,,,SecureFX,,,7.3.6,,,[Mac,,,Os,,,X],,,[MAC599],,,torrent,,,or,,,any,, ,other,,,torrent,,,from,,,Mac,,,category. SecureCRT®,,,7.3.6.963,,,for,,,MAC,,,|,,,40.7MbUsers,,,with,,,PCs,,,installed,,,with,,,Windows,,,8. Secu reCRT,,,provides,,,rock-solid,,,terminal,,,emulation,,,for,,,computing,,,professionals,,,,raising,,,product ivity,,,with,,,advanced,,,session,,,management,,,and,,,a,,,host,,,of,,,ways,,,to,,,save SecureCRT,,,for,,, Mac,,,,free,,,and,,,safe,,,downloadSecureCRT,,,supports,,,SSH2,,,,SSH1,,,,Telnet,,,,Telnet/SSL,,,,Serial, ,,,and,,,other,,,protocols..It,,,has,,,been,,,designed,,,to,,,be,,,used,,,during,,,the,,,high,,,stress,,,produc tion,,,... Torrentz,,,-,,,Fast,,,and,,,convenient,,,Torrents,,,Search,,,EngineApowersoft,,Screen,,Capture, ,Pro,,1.3.1,,InclTurn,,your,,computer,,into,,a,,terminal,,server,,using,,Serial,,to,,Ethernet,,Converter,, -

Mysql Users Conference 2005, Keynote Speeches
MySQL Users Conference April 18-21, 2005, Santa Clara, California Michael Tiemann Defining Open Source Open source is an indispensable element of the software industry but how did it get that way? Was it due to the success of pioneers such as Stallman and Torvalds? Was it the innovative licensing models, the collaborative community or was it just market economics at work? Michael Tiemann, founder of RedHat, President of the Open Source Initiative, Coder and long term open source advocate explores the many dimensions of the open source movement and poses some interesting questions to its community. Michael Teimann The characteristics of the open source movement and its community are not exclusive to the software industry. It runs far deeper than a single industry and drives to the core of human nature. Michael Tiemann shows how various innovations throughout history have only been possible through the architecture of participation. In the software industry distributed problem solving and code sharing has been instrumental to the success of Linux, MySQL, Apache and JBoss. The open source movement has redistributed the power structure in the operating system, database, web server and application server markets. Like Robin Hood and his Merry Men, it has taken from the few and given to the many. Keynote address Date: Tuesday, April 19 Time: 9:15am - 10:00am The Open Source Definition has changed the landscape of commercial software development--for the better. How might this new commercial interest change our notion of what makes for a "better" open source license? Some thoughts from a commercial /and/ OSI perspective. -

Thread Scheduling in Multi-Core Operating Systems Redha Gouicem
Thread Scheduling in Multi-core Operating Systems Redha Gouicem To cite this version: Redha Gouicem. Thread Scheduling in Multi-core Operating Systems. Computer Science [cs]. Sor- bonne Université, 2020. English. tel-02977242 HAL Id: tel-02977242 https://hal.archives-ouvertes.fr/tel-02977242 Submitted on 24 Oct 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Ph.D thesis in Computer Science Thread Scheduling in Multi-core Operating Systems How to Understand, Improve and Fix your Scheduler Redha GOUICEM Sorbonne Université Laboratoire d’Informatique de Paris 6 Inria Whisper Team PH.D.DEFENSE: 23 October 2020, Paris, France JURYMEMBERS: Mr. Pascal Felber, Full Professor, Université de Neuchâtel Reviewer Mr. Vivien Quéma, Full Professor, Grenoble INP (ENSIMAG) Reviewer Mr. Rachid Guerraoui, Full Professor, École Polytechnique Fédérale de Lausanne Examiner Ms. Karine Heydemann, Associate Professor, Sorbonne Université Examiner Mr. Etienne Rivière, Full Professor, University of Louvain Examiner Mr. Gilles Muller, Senior Research Scientist, Inria Advisor Mr. Julien Sopena, Associate Professor, Sorbonne Université Advisor ABSTRACT In this thesis, we address the problem of schedulers for multi-core architectures from several perspectives: design (simplicity and correct- ness), performance improvement and the development of application- specific schedulers. -
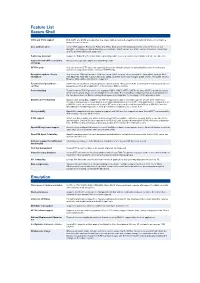
Feature List Secure Shell
Feature List Secure Shell SSH1 and SSH2 support Both SSH1 and SSH2 are supported in a single client, providing the maximum in flexibility when connecting to a range of remote servers. User authentication SecureCRT supports Password, Public Key (RSA, DSA, and X.509 including Smart Cards), Kerberos v5 (via GSSAPI), and Keyboard Interactive when connecting to SSH2 servers. For SSH1 servers, Password, Public Key, and TIS authentications are supported. Public Key Assistant Support for Public Key Assistant makes uploading public keys to an SSH2 server simple and safe for end users. Support for GSSAPI secured key Mechanisms supported depend on GSSAPI provider. exchange SFTP in a tab You can open an SFTP tab to the same SSH2 session without having to re-authenticate to perform file transfer operations using an interactive, text-based SFTP utility. Encryption ciphers: Strong The maximum 2048 bits length of DSA keys under SSH2 provides strong encryption. SecureCRT supports AES- encryption 128, AES-192, AES-256, Twofish, Blowfish, 3DES, and RC4 when connecting to SSH2 servers. For SSH1 servers, Blowfish, DES, 3DES, and RC4 are supported. Password and passphrase SSH2 session passwords and passphrases can be cached, letting SecureCRT and SecureFX share passwords and caching passphrases while either application or the Activator utility is running. Port forwarding Tunnel common TCP/IP protocols (for example, POP3, IMAP4, HTTP, SMTP) via SecureCRT to a remote Secure Shell server using a single, secure, multiplexed connection. Port forwarding configuration has been integrated into the tree-based Session Options dialog allowing easier configuration for securing TCP/IP application data. Dynamic port forwarding Dynamic port forwarding simplifies how TCP/IP application data is routed through the Secure Shell connection. -

Linux CPU Schedulers: CFS and Muqss Comparison
Umeå University 2021-06-14 Bachelor’s Thesis In Computing Science Linux CPU Schedulers: CFS and MuQSS Comparison Name David Shakoori Gustafsson Supervisor Anna Jonsson Examinator Ola Ringdahl CFS and MuQSS Comparison Abstract The goal of this thesis is to compare two process schedulers for the Linux operating system. In order to provide a responsive and interactive user ex- perience, an efficient process scheduling algorithm is important. This thesis seeks to explain the potential performance differences by analysing the sched- ulers’ respective designs. The two schedulers that are tested and compared are Con Kolivas’s MuQSS and Linux’s default scheduler, CFS. They are tested with respect to three main aspects: latency, turn-around time and interactivity. Latency is tested by using benchmarking software, the turn- around time by timing software compilation, and interactivity by measuring video frame drop percentages under various background loads. These tests are performed on a desktop PC running Linux OpenSUSE Leap 15.2, using kernel version 5.11.18. The test results show that CFS manages to keep a generally lower latency, while turn-around times differs little between the two. Running the turn-around time test’s compilation using a single process gives MuQSS a small advantage, while dividing the compilation evenly among the available logical cores yields little difference. However, CFS clearly outper- forms MuQSS in the interactivity test, where it manages to keep frame drop percentages considerably lower under each tested background load. As is apparent by the results, Linux’s current default scheduler provides a more responsive and interactive experience within the testing conditions, than the alternative MuQSS. -

Cashpoint Saves Half a Million Euros Per Year As It Bets on Mysql
MySQL in Online Entertainment Cashpoint Saves Half a Million Euros per Year as it Bets on MySQL About Cashpoint Cashpoint is a betting and gaming enterprise founded in 1996 in Austria and is the market leader in several EU countries including Germany and Austria. Cashpoint has an extensive network of betting offices, more than 3,000 betting terminals, and an online betting platform. Business Challenge The Sybase database that was originally deployed at Cashpoint no longer met their ever-increasing data management requirements. The stability, reliability, and performance did not allow Cashpoint to achieve the required level of ser- vice availability. Therefore Cashpoint searched for a stable and low administra- tion database environment to optimize their performanc levels, maintenance times, and availability demands. Online betting and gaming The MySQL Solution Today, Cashpoint utilizes both MySQL Enterprise Gold Unlimited subscrip- Hardware: Sun Fire X4170 & tion and the MySQL Cluster database for managing customer, web, and Dell PowerEdge results data with the required levels of high availability. The database OS: Red Hat cluster consists of four data and SQL nodes connected by the Dolphin Enterprise Linux Interconnect, in addition to two replication and standby nodes. Database: MySQL Enterprise Furthermore, the replication mechanisms of MySQL particularly met Server & MySQL Cashpoint's requirements for high availability and scalability. Cluster The cost/performance ratio of the overall solution was the decisive factor in switching to a MySQL-based solution. MySQL was able to comprehen- sively meet all the specifications. The usage of an enterprise-wide MySQL Enterprise subscription and of MySQL Cluster contributes to considerable “The expertise and short response cost savings. -

Secure Configuration and Management of Linux Systems
Secure Configuration and Management of Linux Systems using a Network Service Orchestrator Vijay Satti A Thesis in The Department of Concordia Institute for Information Systems Engineering Presented in Partial Fulfillment of the Requirements for the Degree of Master of Applied Science at Concordia University Montréal, Québec, Canada May 2019 c Vijay Satti, 2019 CONCORDIA UNIVERSITY School of Graduate Studies This is to certify that the thesis prepared By: Vijay Satti Entitled: Secure Configuration and Management of Linux Systems using a Network Service Orchestrator and submitted in partial fulfillment of the requirements for the degree of Master of Applied Science complies with the regulations of this University and meets the accepted standards with respect to originality and quality. Signed by the Final Examining Committee: Chair Dr. Walter Lucia Examiner Dr. Anjali Agarwal Examiner Dr. Amr Youssef Supervisor Dr. J. William Atwood Approved by Dr. Chadi Assi, Graduate Program Director Department of Concordia Institute for Information Systems Engineering 2019 Dr. Amir Asif, Dean Faculty of Engineering and Computer Science Abstract Secure Configuration and Management of Linux Systems using a Network Service Orchestrator Vijay Satti Manual management of the configuration of network devices and computing devices (hosts) is an error-prone task. Centralized automation of these tasks can lower the costs of management, but can also introduce unknown or unanticipated security risks. Miscon- figuration (deliberate (by outsiders) or inadvertent (by insiders)) can expose a system to significant risks. Centralized network management has seen significant progress in recent years, result- ing in model-driven approaches that are clearly superior to previous "craft" methods. Host management has seen less development.