276 Art P Kaveri 54-65
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2018 Annual Report on Form 10-K
2018 ANNUAL REPORT ON FORM 10-K MARCH 2019 DEAR SHAREHOLDERS: From the industry’s first 1GHz CPU to the world’s first GPU delivering a teraflop of computing power, AMD has always stood for pushing the boundaries of what is possible. A few years ago, we made several big bets to accelerate our pace of innovation, strengthen our execution, and enable AMD to deliver a leadership portfolio of computing and graphics processors capable of increasing our share of the $75 billion high-performance computing market. In 2018, we saw those bets begin to pay off as we delivered our second straight year of greater than 20% annual revenue growth and significantly improved our gross margin and profitability from the previous year. REVENUE GROSS MARGIN % R&D INVESTMENT EXPENSE/REVENUE % $ Billions $ Billions $6.5B 38% $1.43B 34% $5.3B 34% 33% $4.3B $1.20B 23% $1.01B 31% 2016 2017 2018 2016 2017 2018 2016 2017 2018 2016 2017 2018 Added $2.2B in revenue Significantly improved gross Increased R&D by more than Significant improvement over the last 2 years margin over last 2 years based 40% over the last 2 years in OPEX leverage on new product portfolio Our newest Ryzen™, EPYC™ and datacenter GPU products contributed more than $1.2 billion of revenue in 2018 and helped us gain share across our priority markets. In 2018, we added 3.9% points of desktop processor unit share, 5.3% points of notebook processor unit share and met our goal of exiting the year with mid-single digit server processor market share. -

I Processori Amd Trinity
UNIVERSITA’ DEGLI STUDI DI PADOVA __________________________________________________ Facoltà di Ingegneria Corso di laurea in Ingegneria Informatica I PROCESSORI AMD TRINITY Laureando Relatore Luca Marzaro Prof. Sergio Congiu ___________________________________________________________ ANNO ACCADEMICO 2012/2013 ii iii A Giulia, mamma, papà e Diego iv Indice 1. Introduzione 1 1.1 Cenni storici AMD . 1 1.2 Evoluzione del processore: dall' Am386 alle APU Trinity . 2 2. Trinity: Architettura 5 2.1 Introduzione . 5 2.2 Da Llano a Trinity: architettura Piledriver . 6 2.3 Graphics Memory Controller: architettura VLIW4 . 8 2.4 Un nuovo socket: FM2 . 12 3. Specifiche tecniche 15 3.1 Modelli e dati tecnici . 15 3.2 Comparazione con Llano e Intel core i3 . 17 4. Prestazioni 19 4.1 Introduzione . 19 4.2 Applicazioni multimediali . 22 4.3 Calcolo e compressione . 25 4.4 Consumi . 30 5. Considerazioni finali 35 vi INDICE Bibliografia 37 Capitolo 1 Introduzione 1.1 Cenni storici AMD AMD (Advanced Micro Devices) è una multinazionale americana produttrice di semiconduttori la cui sede si trova a Sunnyvale in California. La peculiarità di tale azienda è la produzione di microprocessori, workstation e server, di chip grafici e di chipset. Si classifica seconda al mondo Figura 1.1: Jerry Sanders nella produzione di microprocessori con architettuta x86 dopo Intel. Il primo maggio 1969 Jerry Sanders (vedi Figura 1.1) e sette amici fondano la AMD. Sei anni più tardi, lanciano nel mercato la prima memoria RAM marchiata AMD, la Am9102 e presentano AMD 8080, una variante dell'INTEL 8080 che lancia l'azienda nel mondo dei microprocessori. Dal 1980 AMD si impone come uno dei principali concorrenti di Intel nel mercato dei processori x86- compatibili. -

Communication Theory II
Microprocessor (COM 9323) Lecture 2: Review on Intel Family Ahmed Elnakib, PhD Assistant Professor, Mansoura University, Egypt Feb 17th, 2016 1 Text Book/References Textbook: 1. The Intel Microprocessors, Architecture, Programming and Interfacing, 8th edition, Barry B. Brey, Prentice Hall, 2009 2. Assembly Language for x86 processors, 6th edition, K. R. Irvine, Prentice Hall, 2011 References: 1. Computer Architecture: A Quantitative Approach, 5th edition, J. Hennessy, D. Patterson, Elsevier, 2012. 2. The 80x86 Family, Design, Programming and Interfacing, 3rd edition, Prentice Hall, 2002 3. The 80x86 IBM PC and Compatible Computers, Assembly Language, Design, and Interfacing, 4th edition, M.A. Mazidi and J.G. Mazidi, Prentice Hall, 2003 2 Lecture Objectives 1. Provide an overview of the various 80X86 and Pentium family members 2. Define the contents of the memory system in the personal computer 3. Convert between binary, decimal, and hexadecimal numbers 4. Differentiate and represent numeric and alphabetic information as integers, floating-point, BCD, and ASCII data 5. Understand basic computer terminology (bit, byte, data, real memory system, protected mode memory system, Windows, DOS, I/O) 3 Brief History of the Computers o1946 The first generation of Computer ENIAC (Electrical and Numerical Integrator and Calculator) was started to be used based on the vacuum tube technology, University of Pennsylvania o1970s entire CPU was put in a single chip. (1971 the first microprocessor of Intel 4004 (4-bit data bus and 2300 transistors and 45 instructions) 4 Brief History of the Computers (cont’d) oLate 1970s Intel 8080/85 appeared with 8-bit data bus and 16-bit address bus and used from traffic light controllers to homemade computers (8085: 246 instruction set, RISC*) o1981 First PC was introduced by IBM with Intel 8088 (CISC**: over 20,000 instructions) microprocessor oMotorola emerged with 6800. -

SMBIOS Specification
1 2 Document Identifier: DSP0134 3 Date: 2019-10-31 4 Version: 3.4.0a 5 System Management BIOS (SMBIOS) Reference 6 Specification Information for Work-in-Progress version: IMPORTANT: This document is not a standard. It does not necessarily reflect the views of the DMTF or its members. Because this document is a Work in Progress, this document may still change, perhaps profoundly and without notice. This document is available for public review and comment until superseded. Provide any comments through the DMTF Feedback Portal: http://www.dmtf.org/standards/feedback 7 Supersedes: 3.3.0 8 Document Class: Normative 9 Document Status: Work in Progress 10 Document Language: en-US 11 System Management BIOS (SMBIOS) Reference Specification DSP0134 12 Copyright Notice 13 Copyright © 2000, 2002, 2004–2019 DMTF. All rights reserved. 14 DMTF is a not-for-profit association of industry members dedicated to promoting enterprise and systems 15 management and interoperability. Members and non-members may reproduce DMTF specifications and 16 documents, provided that correct attribution is given. As DMTF specifications may be revised from time to 17 time, the particular version and release date should always be noted. 18 Implementation of certain elements of this standard or proposed standard may be subject to third party 19 patent rights, including provisional patent rights (herein "patent rights"). DMTF makes no representations 20 to users of the standard as to the existence of such rights, and is not responsible to recognize, disclose, 21 or identify any or all such third party patent right, owners or claimants, nor for any incomplete or 22 inaccurate identification or disclosure of such rights, owners or claimants. -

Lista Sockets.Xlsx
Data de Processadores Socket Número de pinos lançamento compatíveis Socket 0 168 1989 486 DX 486 DX 486 DX2 Socket 1 169 ND 486 SX 486 SX2 486 DX 486 DX2 486 SX Socket 2 238 ND 486 SX2 Pentium Overdrive 486 DX 486 DX2 486 DX4 486 SX Socket 3 237 ND 486 SX2 Pentium Overdrive 5x86 Socket 4 273 março de 1993 Pentium-60 e Pentium-66 Pentium-75 até o Pentium- Socket 5 320 março de 1994 120 486 DX 486 DX2 486 DX4 Socket 6 235 nunca lançado 486 SX 486 SX2 Pentium Overdrive 5x86 Socket 463 463 1994 Nx586 Pentium-75 até o Pentium- 200 Pentium MMX K5 Socket 7 321 junho de 1995 K6 6x86 6x86MX MII Slot 1 Pentium II SC242 Pentium III (Cartucho) 242 maio de 1997 Celeron SEPP (Cartucho) K6-2 Socket Super 7 321 maio de 1998 K6-III Celeron (Socket 370) Pentium III FC-PGA Socket 370 370 agosto de 1998 Cyrix III C3 Slot A 242 junho de 1999 Athlon (Cartucho) Socket 462 Athlon (Socket 462) Socket A Athlon XP 453 junho de 2000 Athlon MP Duron Sempron (Socket 462) Socket 423 423 novembro de 2000 Pentium 4 (Socket 423) PGA423 Socket 478 Pentium 4 (Socket 478) mPGA478B Celeron (Socket 478) 478 agosto de 2001 Celeron D (Socket 478) Pentium 4 Extreme Edition (Socket 478) Athlon 64 (Socket 754) Socket 754 754 setembro de 2003 Sempron (Socket 754) Socket 940 940 setembro de 2003 Athlon 64 FX (Socket 940) Athlon 64 (Socket 939) Athlon 64 FX (Socket 939) Socket 939 939 junho de 2004 Athlon 64 X2 (Socket 939) Sempron (Socket 939) LGA775 Pentium 4 (LGA775) Pentium 4 Extreme Edition Socket T (LGA775) Pentium D Pentium Extreme Edition Celeron D (LGA 775) 775 agosto de -
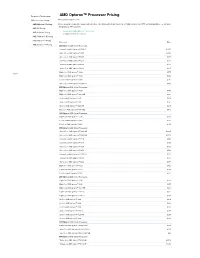
AMD Opteron\231 Processor Pricing
Products & Technologies AMD Opteron™ Processor Pricing AMD Processor Pricing Effective December 4, 2012 AMD Opteron™ Pricing Prices below are subject to change without notice. This listing reflects pricing for direct AMD customers in 1000-unit tray quantities, except when designated as PIB quantities. AMD FX Pricing Shop for all AMD Opteron™ Processors AMD A-Series Pricing Compare Server Processors AMD Phenom™ II Pricing AMD Athlon™ II Pricing Processor Price AMD Sempron™ Pricing AMD Opteron 6300 Series Processors Sixteen-Core AMD Opteron™ 6386 SE $1,392 Sixteen-Core AMD Opteron™ 6380 $1,088 Sixteen-Core AMD Opteron™ 6378 $867 Sixteen-Core AMD Opteron™ 6376 $703 Twelve-Core AMD Opteron™ 6348 $575 Twelve-Core AMD Opteron™ 6344 $415 Eight-Core AMD Opteron™ 6328 $575 Share Eight-Core AMD Opteron™ 6320 $293 Four-Core AMD Opteron™ 6308 $501 Sixteen-Core AMD Opteron™ 6366 HE $575 AMD Opteron 4300 Series Processors Eight-Core AMD Opteron™ 4386 $348 Eight-Core AMD Opteron™ 4376 HE $501 Six-Core AMD Opteron™ 4340 $348 Six-Core AMD Opteron™ 4334 $191 Six-Core AMD Opteron™ 4332 HE $415 Four-Core AMD Opteron™ 4310 EE $415 AMD Opteron 3300 Series Processors Eight-Core AMD Opteron™ 3380 $229 Four-Core AMD Opteron™ 3350 $125 Four-Core AMD Opteron™ 3320 $174 AMD Opteron 6200 Series Processors Sixteen-Core AMD Opteron™ 6284 SE $1265 Sixteen-Core AMD Opteron™ 6282 SE $1,019 Sixteen-Core AMD Opteron™ 6278 $989 Sixteen-Core AMD Opteron™ 6276 $788 Sixteen-Core AMD Opteron™ 6274 $639 Sixteen-Core AMD Opteron™ 6272 $523 Sixteen-Core AMD Opteron™ 6262 HE $523 -

SMBIOS) Reference 6 Specification
1 2 Document Identifier: DSP0134 3 Date: 2018-04-26 4 Version: 3.2.0 5 System Management BIOS (SMBIOS) Reference 6 Specification 7 Supersedes: 3.1.1 8 Document Class: Normative 9 Document Status: Published 10 Document Language: en-US 11 System Management BIOS (SMBIOS) Reference Specification DSP0134 12 Copyright Notice 13 Copyright © 2000, 2002, 2004–2016 Distributed Management Task Force, Inc. (DMTF). All rights 14 reserved. 15 DMTF is a not-for-profit association of industry members dedicated to promoting enterprise and systems 16 management and interoperability. Members and non-members may reproduce DMTF specifications and 17 documents, provided that correct attribution is given. As DMTF specifications may be revised from time to 18 time, the particular version and release date should always be noted. 19 Implementation of certain elements of this standard or proposed standard may be subject to third party 20 patent rights, including provisional patent rights (herein "patent rights"). DMTF makes no representations 21 to users of the standard as to the existence of such rights, and is not responsible to recognize, disclose, 22 or identify any or all such third party patent right, owners or claimants, nor for any incomplete or 23 inaccurate identification or disclosure of such rights, owners or claimants. DMTF shall have no liability to 24 any party, in any manner or circumstance, under any legal theory whatsoever, for failure to recognize, 25 disclose, or identify any such third party patent rights, or for such party’s reliance on the standard or 26 incorporation thereof in its product, protocols or testing procedures. -

Tabla De Evolución De Los Procesadores INTEL Y
Evolución Histórica de los Microprocesadores Desarrollados por Intel y AMD Profesor: Walter Carnero MICROPROCESADORES, EVOLUCIÓN HISTÓRICA Y CARACTERÍSTICAS TÉCNICAS BÁSICAS Se muestra a continuación la evolución histórica de los microprocesadores fabricados por INTEL (fundada en 1968 por Robert Noyce, Gordon Moore y Andrew Grove) y AMD (fundada en 1969 por Jerry Sanders y Seven Friends), además de los zócalos que corresponden con cada uno de los modelos y sus principales características técnicas y de fabricación. AÑO DE EMPRESAS FABRICANTES CARACTERÍSTICAS ZÓCALO FABRICACIÓN PRINCIPALES INTEL AMD Microprocesador de 4 bits. Contiene 2.300 transistores. Encapsulado CERDIP de 16 pines. Máxima velocidad de reloj 740KHz. Usa Arquitectura Harvard, es decir, 1971 - - - - - - - - - - DIP – 16 pines almacenamiento separado de programas y datos. Instrucciones de 8 bits de ancho, que no deben ser colocadas en la misma memoria de datos de 4 bits. Este microprocesador 4004 consta de 46 instrucciones. El i8008 emplea direcciones de 14 bits, pudiendo direccionar hasta 16 KB de memoria. El circuito integrado del i8008, limitado por los 18 contactos de su encapsulado DIP, tiene un bus compartido de datos y direcciones de 8 1972 - - - - - - - - - - DIP – 18 Pines bits, por lo que necesita una gran cantidad de circuitería externa para poder ser utilizado. El i8008 puede acceder a 8 puertos de entrada y 24 de 8008 salida. Este microprocesador tenía un reloj interno de 500Khz. Curso: Reparador de PC 1 Evolución Histórica de los Microprocesadores Desarrollados por Intel y AMD Profesor: Walter Carnero Los Intel 8086 e Intel 8088 (i8086, 1978 - - - - - - - - - - DIP – 40 Pines llamado oficialmente iAPX 86, e i8088) son dos microprocesadores de 16 bits diseñados por Intel en 1978, iniciadores de la arquitectura x86. -

A58md 6.1/6.3/6.5
A58MD 6.1/6.3/6.5 Supported Socket FM2+/FM2 processors AMD A-series/ E2-series processor Supported AMD Mutil Core(x4,x2) AMD 100W processor support AMD A55 Chipset 2 DIMM supported DDR3-2600(OC)/ 2400(OC)/ 2133/ 1866/ 1600/ 1333/ 1066/ 800 AMD Dual Graphics Technology Chipset AMD A55 AMD A10 Processor AMD A8 Processor AMD A6 Processor CPU SUPPORT AMD A4 Processor AMD E2 Processor AMD Athlon™ II X4 Processor Maximum CPU TDP (Thermal Design Power) : 100Watt Support Dual Channel DDR3 2600(OC)/2400(OC)/2133/1866/1600/1333/1066/800 MHz MEMORY 2 x DDR3 DIMM Memory Slot Max. Supports up to 32GB Memory EXPANSION SLOT 1 x PCI-E x16 3.0 Slot (supported by FM2+ CPU) Page 1 of 8. The specification and pictures are subject to change without notice and the package contents may differ by area or your motherboard version! 1 x PCI-E x1 2.0 Slot 4 x SATA2 Connector STORAGE Support SATA RAID: 0,1,10 4 x USB 2.0 Port USB 2 x USB 2.0 Header LAN Realtek RTL8111G - 10/100/1000 Controller By CPU model INTEGRATED AMD Dual Graphics Technology VIDEO Supports DX11.1 CODEC Realtek ALC662 6-Channel HD Audio 1 x PS/2 Mouse 1 x PS/2 Keyboard 4 x USB 2.0 Port REAR I/O 1 x DVI (Dual Link) Connector 1 x VGA Port 1 x RJ-45 Port 3 x Audio Connector 2 x USB 2.0 Header 4 x SATA2 3Gb/s Connector INTERNAL I/O 1 x Front Audio Header 1 x Front Panel Header 1 x CPU FAN Header Page 2 of 8. -

Fm2a55m-Dgs R2.0
FM2A55M-DGS R2.0 User Manual Version 1.0 Published December 2012 Copyright©2012 ASRock INC. All rights reserved. 1 Copyright Notice: No part of this manual may be reproduced, transcribed, transmitted, or translated in any language, in any form or by any means, except duplication of documentation by the purchaser for backup purpose, without written consent of ASRock Inc. Products and corporate names appearing in this manual may or may not be regis- tered trademarks or copyrights of their respective companies, and are used only for identification or explanation and to the owners’ benefit, without intent to infringe. Disclaimer: Specifications and information contained in this manual are furnished for informa- tional use only and subject to change without notice, and should not be constructed as a commitment by ASRock. ASRock assumes no responsibility for any errors or omissions that may appear in this manual. With respect to the contents of this manual, ASRock does not provide warranty of any kind, either expressed or implied, including but not limited to the implied warran- ties or conditions of merchantability or fitness for a particular purpose. In no event shall ASRock, its directors, officers, employees, or agents be liable for any indirect, special, incidental, or consequential damages (including damages for loss of profits, loss of business, loss of data, interruption of business and the like), even if ASRock has been advised of the possibility of such damages arising from any defect or error in the manual or product. This device complies with Part 15 of the FCC Rules. Operation is subject to the fol- lowing two conditions: (1) this device may not cause harmful interference, and (2) this device must accept any interference received, including interference that may cause undesired operation. -

AMD Opteron\231 Processor Pricing
AMD > Products We Design > Processor Pricing > AMD Opteron™ Effecve January 22, 20 4 Prices below are sub%ect to change without noce. This lisng re)ects pricing for direct AMD customers in 000,unit tray -uanes, e.cept when designated as PI0 -uanes. 1hop for all AMD Opteron™ Processors 2ompare 1erver Processors AMD Opteron™ 32 50 AP5 677 AMD Opteron™ 3 50 2P5 684 1ixteen,2ore AMD Opteron™ 8388 1E 6 ,372 1ixteen,2ore AMD Opteron™ 8380 6 ,088 1ixteen,2ore AMD Opteron™ 8378 6887 1ixteen,2ore AMD Opteron™ 8378 6703 1ixteen,2ore AMD Opteron™ 8370P 6578 Twelve,2ore AMD Opteron™ 8348 6575 Twelve,2ore AMD Opteron™ 8344 64 5 Twelve,2ore AMD Opteron™ 8338P 6377 Eight,2ore AMD Opteron™ 8328 6575 Eight,2ore AMD Opteron™ 8320 6273 Four,2ore AMD Opteron™ 8308 650 1ixteen,2ore AMD Opteron™ 8388 HE 6575 Eight,2ore AMD Opteron™ 4388 6348 Eight,2ore AMD Opteron™ 4378 HE 650 1ix,2ore AMD Opteron™ 4340 6348 1ix,2ore AMD Opteron™ 4334 6 7 1ix,2ore AMD Opteron™ 4332 HE 64 5 Four,2ore AMD Opteron™ 43 0 EE 64 5 Eight,2ore AMD Opteron™ 3380 6227 Four,2ore AMD Opteron™ 3350 6 25 Four,2ore AMD Opteron™ 3320 6 74 1ixteen,2ore AMD Opteron™ 8284 1E 6 ,285 1ixteen,2ore AMD Opteron™ 8282 1E 6 ,0 7 1ixteen,2ore AMD Opteron™ 8278 6787 1ixteen,2ore AMD Opteron™ 8278 6788 1ixteen,2ore AMD Opteron™ 8274 6837 1ixteen,2ore AMD Opteron™ 8272 6523 1ixteen,2ore AMD Opteron™ 8282 HE 6523 Twelve,2ore AMD Opteron™ 8238 6455 Twelve,2ore AMD Opteron™ 8234 6377 Eight,2ore AMD Opteron™ 8220 6523 Eight,2ore AMD Opteron™ 82 2 6288 Four,2ore AMD Opteron™ 8204 6455 Eight,2ore AMD Opteron™ -
A88M Motherboard
A88M Motherboard • Supported Socket FM2+/FM2 processors AMD A- series/ E2-series processor • Supported AMD Mutil Core(x4,x2) • AMD 100W processor support • AMD A88X Chipset • 2 DIMM supported DDR3-2600(OC)/ 2400(OC)/ 2133/ 1866/ 1600/ 1333/ 1066/ 800 • AMD Dual Graphics Technology • 100% X.D.C solid capacitor A88M Specifcation CPU SUPPORT AMD A10 Processor AMD A8 Processor AMD A6 Processor AMD A4 Processor AMD E2 Processor AMD Athlon™ II X4 Processor Maximum CPU TDP (Thermal Design Power) : 100Watt MEMORY Support Dual Channel DDR3 2600(OC)/2400(OC)/2133/1866/1600/1333/1066/800 MHz 2 x DDR3 DIMM Memory Slot Max. Supports up to 32GB Memory INTEGRATED VIDEO By CPU model BIOSTARAMD Dual Graphics Technology Supports DX11.1 Supports HDCP STORAGE 6 x SATA III Connector Support SATA RAID: 0,1,5,10 LAN Realtek RTL8111G - 10/100/1000 Controller AUDIO CODEC Realtek ALC892 8-Channel Blu-ray Audio USB 2 x USB 3.0 Port 1 x USB 3.0 Header 2 x USB 2.0 Port 2 x USB 2.0 Header EXPANSION SLOT 1 x PCI-E 3.0 x16 Slot(supported by FM2+ CPU) 1 x PCI-E 2.0 x1 Slot 1 x PCI Slot REAR I/O 1 x PS/2 Mouse 1 x PS/2 Keyboard 2 x USB 3.0 Port 2 x USB 2.0 Port 1 x DVI (Dual Link) Connector 1 x VGA Port 1 x LAN Port 3 x Audio Jacks INTERNAL I/O 1 x USB 3.0 Header 2 x USB 2.0 Header 6 x SATA III Connector (6Gb/s) 1 x Front Audio Header 1 x Front Panel Header 1 x S/PDIF-Out Header 1 x CPU Fan Connector 1 x System Fan Connector 1 x COM Port Header 1 x Printer Port Header H/W MONITORING CPU / System Temperature Monitoring CPU / System Fan Monitoring Smart / Manual CPU Fan