Implementing Out-Of-Order Execution Processors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Computer Science 246 Computer Architecture Spring 2010 Harvard University
Computer Science 246 Computer Architecture Spring 2010 Harvard University Instructor: Prof. David Brooks [email protected] Dynamic Branch Prediction, Speculation, and Multiple Issue Computer Science 246 David Brooks Lecture Outline • Tomasulo’s Algorithm Review (3.1-3.3) • Pointer-Based Renaming (MIPS R10000) • Dynamic Branch Prediction (3.4) • Other Front-end Optimizations (3.5) – Branch Target Buffers/Return Address Stack Computer Science 246 David Brooks Tomasulo Review • Reservation Stations – Distribute RAW hazard detection – Renaming eliminates WAW hazards – Buffering values in Reservation Stations removes WARs – Tag match in CDB requires many associative compares • Common Data Bus – Achilles heal of Tomasulo – Multiple writebacks (multiple CDBs) expensive • Load/Store reordering – Load address compared with store address in store buffer Computer Science 246 David Brooks Tomasulo Organization From Mem FP Op FP Registers Queue Load Buffers Load1 Load2 Load3 Load4 Load5 Store Load6 Buffers Add1 Add2 Mult1 Add3 Mult2 Reservation To Mem Stations FP adders FP multipliers Common Data Bus (CDB) Tomasulo Review 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 LD F0, 0(R1) Iss M1 M2 M3 M4 M5 M6 M7 M8 Wb MUL F4, F0, F2 Iss Iss Iss Iss Iss Iss Iss Iss Iss Ex Ex Ex Ex Wb SD 0(R1), F0 Iss Iss Iss Iss Iss Iss Iss Iss Iss Iss Iss Iss Iss M1 M2 M3 Wb SUBI R1, R1, 8 Iss Ex Wb BNEZ R1, Loop Iss Ex Wb LD F0, 0(R1) Iss Iss Iss Iss M Wb MUL F4, F0, F2 Iss Iss Iss Iss Iss Ex Ex Ex Ex Wb SD 0(R1), F0 Iss Iss Iss Iss Iss Iss Iss Iss Iss M1 M2 -

Pipelining 2
Instruction-Level Parallelism Dynamic Scheduling CS448 1 Dynamic Scheduling • Static Scheduling – Compiler rearranging instructions to reduce stalls • Dynamic Scheduling – Hardware rearranges instruction stream to reduce stalls – Possible to account for dependencies that are only known at run time - e. g. memory reference – Simplifies the compiler – Code built for one pipeline in mind could also run efficiently on a different pipeline – minimizes the need for speculative slot filling - NP hard • Once a common tactic with supercomputers and mainframes but was too expensive for single-chip – Now fits on a desktop PC’s 2 1 Dynamic Scheduling • Dependencies that are close together stall the entire pipeline – DIVD F0, F2, F4 – ADDD F10, F0, F8 – SUBD F12, F8, F14 • The ADD needs the DIV to finish, so there is a stall… which also stalls the SUBD – Looong stall for DIV – But the SUBD is independent so there is no reason why we shouldn’t execute it – Or is there? • Precise Interrupts - Ignore for now • Compiler could rearrange instructions, but so could the hardware 3 Dynamic Scheduling • It would be desirable to decode instructions into the pipe in order but then let them stall individually while waiting for operands before issue to execution units. • Dynamic Scheduling – Out of Order Issue / Execution • Scoreboarding 4 2 Scoreboarding Split ID stage into two: Issue (Decode, check for Structural hazards) Read Operands (Wait until no data hazards, read operands) 5 Scoreboard Overview • Consider another example: – DIVD F0, F2, F4 – ADDD F10, F0, -
Local, Compressed
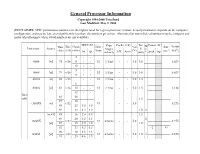
General Processor Information Copyright 1994-2000 Tom Burd Last Modified: May 2, 2000 (DISCLAIMER: SPEC performance numbers are the highest rated for a given processor version. Actual performance depends on the computer configuration, and may be less, even significantly less than, the numbers given here. Also note that non-italicized numbers may be company esti- mates of perforamnce when actual numbers are not available) SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ 5 - - 8086 [vi] 78 v/16 8 - - 1/1 1/1/na - - 5.0 3.0 0.029 10 - - 5 - - 8088 [vi] 79 v/16 1/1 1/1/na - - 5.0 3.0 0.029 8 - - 80186 [vi] 82 v/16 - - 1/1 1/1/na - - 5.0 1.5 6 - - 80286 [vi] 82 v/16 10 - - 1/1 1/1/na - - 5.0 1.5 0.134 12 - - Intel 85 16 x86 1.5 87 20 i386DX [vi] v/32 1/1 - - 5.0 0.275 88 25 6.5 1.9 89 33 8.4 3.0 1.0 2 [vi,41] 88 16 2.4 0.9 1.5 89 20 3.5 1.3 2 i386SX v/32 1/1 4/na/na - - 5.0 0.275 [vi] 89 25 4.6 1.9 1.0 92 33 6.2 3.3 ~2 43 90 20 3.5 1.3 i386SL [vi] v/32 1/1 4/na/na - - 5.0 1.0 2 0.855 91 25 4.6 1.9 SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ [vi] 89 25 14.2 6.7 1.0 2 i486DX [vi,45] 90 v/32 33 18.6 8.5 2/1 5/na/5? 8 u. -

Sections 3.2 and 3.3 Dynamic Scheduling – Tomasulo's Algorithm
EEF011 Computer Architecture 計算機結構 Sections 3.2 and 3.3 Dynamic Scheduling – Tomasulo’s Algorithm 吳俊興 高雄大學資訊工程學系 October 2004 A Dynamic Algorithm: Tomasulo’s Algorithm • For IBM 360/91 (before caches!) – 3 years after CDC • Goal: High Performance without special compilers • Small number of floating point registers (4 in 360) prevented interesting compiler scheduling of operations – This led Tomasulo to try to figure out how to get more effective registers — renaming in hardware! • Why Study 1966 Computer? • The descendants of this have flourished! – Alpha 21264, HP 8000, MIPS 10000, Pentium III, PowerPC 604, … Example to eleminate WAR and WAW by register renaming • Original DIV.D F0, F2, F4 ADD.D F6, F0, F8 S.D F6, 0(R1) SUB.D F8, F10, F14 MUL.D F6, F10, F8 WAR between ADD.D and SUB.D, WAW between ADD.D and MUL.D (Due to that DIV.D needs to take much longer cycles to get F0) • Register renaming DIV.D F0, F2, F4 ADD.D S, F0, F8 S.D S, 0(R1) SUB.D T, F10, F14 MUL.D F6, F10, T Tomasulo Algorithm • Register renaming provided – by reservation stations, which buffer the operands of instructions waiting to issue – by the issue logic • Basic idea: – a reservation station fetches and buffers an operand as soon as it is available, eliminating the need to get the operand from a register (WAR) – pending instructions designate the reservation station that will provide their input (RAW) – when successive writes to a register overlap in execution, only the last one is actually used to update the register (WAW) As instructions are issued, the register specifiers for pending operands are renamed to the names of the reservation station, which provides register renaming • more reservation stations than real registers Properties of Tomasulo Algorithm 1. -

EECS 570 Lecture 5 GPU Winter 2021 Prof
EECS 570 Lecture 5 GPU Winter 2021 Prof. Satish Narayanasamy http://www.eecs.umich.edu/courses/eecs570/ Slides developed in part by Profs. Adve, Falsafi, Martin, Roth, Nowatzyk, and Wenisch of EPFL, CMU, UPenn, U-M, UIUC. 1 EECS 570 • Slides developed in part by Profs. Adve, Falsafi, Martin, Roth, Nowatzyk, and Wenisch of EPFL, CMU, UPenn, U-M, UIUC. Discussion this week • Term project • Form teams and start to work on identifying a problem you want to work on Readings For next Monday (Lecture 6): • Michael Scott. Shared-Memory Synchronization. Morgan & Claypool Synthesis Lectures on Computer Architecture (Ch. 1, 4.0-4.3.3, 5.0-5.2.5). • Alain Kagi, Doug Burger, and Jim Goodman. Efficient Synchronization: Let Them Eat QOLB, Proc. 24th International Symposium on Computer Architecture (ISCA 24), June, 1997. For next Wednesday (Lecture 7): • Michael Scott. Shared-Memory Synchronization. Morgan & Claypool Synthesis Lectures on Computer Architecture (Ch. 8-8.3). • M. Herlihy, Wait-Free Synchronization, ACM Trans. Program. Lang. Syst. 13(1): 124-149 (1991). Today’s GPU’s “SIMT” Model CIS 501 (Martin): Vectors 5 Graphics Processing Units (GPU) • Killer app for parallelism: graphics (3D games) Tesla S870 What is Behind such an Evolution? • The GPU is specialized for compute-intensive, highly data parallel computation (exactly what graphics rendering is about) ❒ So, more transistors can be devoted to data processing rather than data caching and flow control ALU ALU Control ALU ALU CPU GPU Cache DRAM DRAM • The fast-growing video game industry -

Multiple Instruction Issue and Completion Per Clock Cycle Using Tomasulo’S Algorithm – a Simple Example
Multiple Instruction Issue and Completion per Clock Cycle Using Tomasulo’s Algorithm – A Simple Example Assumptions: . The processor has in-order issue but execution may be out-of-order as it is done as soon after issue as operands are available. Instructions commit as they finish execu- tion. There is no speculative execution on Branch instructions because out-of-order com- pletion prevents backing out incorrect results. The reason for the out-of-order com- pletion is that there is no buffer between results from the execution and their com- mitment in the register file. This restriction is just to keep the example simple. It is possible for at least two instructions to issue in a cycle. The processor has two integer ALU’s with one Reservation Station each. ALU op- erations complete in one cycle. We are looking at the operation during a sequence of arithmetic instructions so the only Functional Units shown are the ALU’s. NOTES: Customarily the term “issue” is the transition from ID to the window for dy- namically scheduled machines and dispatch is the transition from the window to the FU’s. Since this machine has an in-order window and dispatch with no speculation, I am using the term “issue” for the transition to the reservation stations. It is possible to have multiple reservation stations in front of a single functional unit. If two instructions are ready for execution on that unit at the same clock cycle, the lowest station number executes. There is a problem with exception processing when there is no buffering of results being committed to the register file because some register entries may be from instructions past the point at which the exception occurred. -

Microprocessor Training
Microprocessors and Microcontrollers © 1999 Altera Corporation 1 Altera Confidential Agenda New Products - MicroController products (1 hour) n Microprocessor Systems n The Embedded Microprocessor Market n Altera Solutions n System Design Considerations n Uncovering Sales Opportunities © 2000 Altera Corporation 2 Altera Confidential Embedding microprocessors inside programmable logic opens the door to a multi-billion dollar market. Altera has solutions for this market today. © 2000 Altera Corporation 3 Altera Confidential Microprocessor Systems © 1999 Altera Corporation 4 Altera Confidential Processor Terminology n Microprocessor: The implementation of a computer’s central processor unit functions on a single LSI device. n Microcontroller: A self-contained system with a microprocessor, memory and peripherals on a single chip. “Just add software.” © 2000 Altera Corporation 5 Altera Confidential Examples Microprocessor: Motorola PowerPC 600 Microcontroller: Motorola 68HC16 © 2000 Altera Corporation 6 Altera Confidential Two Types of Processors Computational Embedded n Programmable by the end-user to n Performs a fixed set of functions that accomplish a wide range of define the product. User may applications configure but not reprogram. n Runs an operating system n May or may not use an operating system n Program exists on mass storage n Program usually exists in ROM or or network Flash n Tend to be: n Tend to be: – Microprocessors – Microcontrollers – More expensive (ASP $193) – Less expensive (ASP $12) n Examples n Examples – Work Station -

14 Superscalar Processors
UNIT- 5 Chapter 14 Instruction Level Parallelism and Superscalar Processors What is Superscalar? • Use multiple independent instruction pipeline. • Instruction level parallelism • Identify dependencies in program • Eliminate Unnecessary dependencies • Use additional registers & renaming of register references in original code. • Branch prediction improves efficiency What is Superscalar? • RISC-like instructions, one per word • Multiple parallel execution units • Reorders and optimizes instruction stream at run time • Branch prediction with speculative execution of one path • Loads data from memory only when needed, and tries to find the data in the caches first Why Superscalar? • In 1987, scalar instruction • Most operations are on scalar quantities • Improving these operations to get an overall improvement • High performance microprocessors. General Superscalar Organization Superscalar V/S Superpipelined • Ordinary:- • One instruction/clock cycle & can perform one pipeline stage per clock cycle. • Superpipelined:- • 2 pipeline stage per cycle • Execution time:-half a clock cycle • Double internal clock speed gets two tasks per external clock cycle • Superscalar :- • allows parallel fetch execute • Start of the program & at branch target it performs better than above said. Superscalar v Superpipeline Limitations • Instruction level parallelism • Compiler based optimisation • Hardware techniques • Limited by —True data dependency —Procedural dependency —Resource conflicts —Output dependency —Antidependency True Data Dependency • ADD r1, -

Concepts Introduced in Chapter 3 Instruction Level Parallelism (ILP)
Intro Compiler Techs Branch Pred Dynamic Sched Speculation Multi Issue ILP Limits MT Intro Compiler Techs Branch Pred Dynamic Sched Speculation Multi Issue ILP Limits MT Concepts Introduced in Chapter 3 Instruction Level Parallelism (ILP) introduction Pipelining is the overlapping of dierent portions of instruction compiler techniques for ILP execution. advanced branch prediction Instruction level parallelism is the parallel execution of a dynamic scheduling sequence of instructions associated with a single thread of speculation execution. multiple issue scheduling approaches to exploit ILP static (compiler) limits of ILP dynamic (hardware) multithreading Intro Compiler Techs Branch Pred Dynamic Sched Speculation Multi Issue ILP Limits MT Intro Compiler Techs Branch Pred Dynamic Sched Speculation Multi Issue ILP Limits MT Data Dependences Control Dependences An instruction is control dependent on a branch instruction if the instruction will only be executed when the branch has a specic result. An instruction that is control dependent on a branch cannot be moved before the branch so that its execution is not controlled by the branch. Instructions must be independent to be executed in parallel. instruction types of data dependences branch branch True dependences can lead to RAW hazards. name dependences instruction Antidependences can lead to WAR hazards. before transformation after transformation Output dependences can lead to WAW hazards. An instruction that is not control dependent on a branch cannot be moved after the branch so that its execution is controlled by the branch. instruction branch branch instruction before transformation after transformation Intro Compiler Techs Branch Pred Dynamic Sched Speculation Multi Issue ILP Limits MT Intro Compiler Techs Branch Pred Dynamic Sched Speculation Multi Issue ILP Limits MT Static Scheduling Latencies of FP Operations Used in This Chapter The latency here indicates the number of intervening independent instructions that are needed to avoid a stall. -

Tomasulo's Algorithm
Out-of-Order Execution Several implementations • out-of-order completion • CDC 6600 with scoreboarding • IBM 360/91 with Tomasulo’s algorithm & reservation stations • out-of-order completion leads to: • imprecise interrupts • WAR hazards • WAW hazards • in-order completion • MIPS R10000/R12000 & Alpha 21264/21364 with large physical register file & register renaming • Intel Pentium Pro/Pentium III with the reorder buffer Autumn 2006 CSE P548 - Tomasulo 1 Out-of-order Hardware In order to compute correct results, need to keep track of: • which instruction is in which stage of the pipeline • which registers are being used for reading/writing & by which instructions • which operands are available • which instructions have completed Each scheme has different hardware structures & different algorithms to do this Autumn 2006 CSE P548 - Tomasulo 2 1 Tomasulo’s Algorithm Tomasulo’s Algorithm (IBM 360/91) • out-of-order execution capability plus register renaming Motivation • long FP delays • only 4 FP registers • wanted common compiler for all implementations Autumn 2006 CSE P548 - Tomasulo 3 Tomasulo’s Algorithm Key features & hardware structures • reservation stations • distributed hazard detection & execution control • forwarding to eliminate RAW hazards • register renaming to eliminate WAR & WAW hazards • deciding which instruction to execute next • common data bus • dynamic memory disambiguation Autumn 2006 CSE P548 - Tomasulo 4 2 Hardware for Tomasulo’s Algorithm Autumn 2006 CSE P548 - Tomasulo 5 Tomasulo’s Algorithm: Key Features Reservation -

Intro Evolution of Superscalar Processor
Superscalar Processors Superscalar Processors vs. VLIW • 7.1 Introduction • 7.2 Parallel decoding • 7.3 Superscalar instruction issue • 7.4 Shelving • 7.5 Register renaming • 7.6 Parallel execution • 7.7 Preserving the sequential consistency of instruction execution • 7.8 Preserving the sequential consistency of exception processing • 7.9 Implementation of superscalar CISC processors using a superscalar RISC core • 7.10 Case studies of superscalar processors TECH Computer Science CH01 Superscalar Processor: Intro Emergence and spread of superscalar processors • Parallel Issue • Parallel Execution • {Hardware} Dynamic Instruction Scheduling • Currently the predominant class of processors 4Pentium 4PowerPC 4UltraSparc 4AMD K5- 4HP PA7100- 4DEC α Evolution of superscalar processor Specific tasks of superscalar processing Parallel decoding {and Dependencies check} Decoding and Pre-decoding • What need to be done • Superscalar processors tend to use 2 and sometimes even 3 or more pipeline cycles for decoding and issuing instructions • >> Pre-decoding: 4shifts a part of the decode task up into loading phase 4resulting of pre-decoding f the instruction class f the type of resources required for the execution f in some processor (e.g. UltraSparc), branch target addresses calculation as well 4the results are stored by attaching 4-7 bits • + shortens the overall cycle time or reduces the number of cycles needed The principle of perdecoding Number of perdecode bits used Specific tasks of superscalar processing: Issue 7.3 Superscalar instruction issue • How and when to send the instruction(s) to EU(s) Instruction issue policies of superscalar processors: Issue policies ---Performance, tread-----Æ Issue rate {How many instructions/cycle} Issue policies: Handing Issue Blockages • CISC about 2 • RISC: Issue stopped by True dependency Issue order of instructions • True dependency Æ (Blocked: need to wait) Aligned vs. -

Technical Report
Technical Report Department of Computer Science University of Minnesota 4-192 EECS Building 200 Union Street SE Minneapolis, MN 55455-0159 USA TR 97-030 Hardware and Compiler-Directed Cache Coherence in Large-Scale Multiprocessors by: Lynn Choi and Pen-Chung Yew Hardware and Compiler-Directed Cache Coherence 1n Large-Scale Multiprocessors: Design Considerations and Performance Study1 Lynn Choi Center for Supercomputing Research and Development University of Illinois at Urbana-Champaign 1308 West Main Street Urbana, IL 61801 Email: lchoi@csrd. uiuc. edu Pen-Chung Yew 4-192 EE/CS Building Department of Computer Science University of Minnesota 200 Union Street, SE Minneapolis, MN 55455-0159 Email: [email protected] Abstract In this paper, we study a hardware-supported, compiler-directed (HSCD) cache coherence scheme, which can be implemented on a large-scale multiprocessor using off-the-shelf micro processors, such as the Cray T3D. The scheme can be adapted to various cache organizations, including multi-word cache lines and byte-addressable architectures. Several system related issues, including critical sections, inter-thread communication, and task migration have also been addressed. The cost of the required hardware support is minimal and proportional to the cache size. The necessary compiler algorithms, including intra- and interprocedural array data flow analysis, have been implemented on the Polaris parallelizing compiler [33]. From our simulation study using the Perfect Club benchmarks [5], we found that in spite of the conservative analysis made by the compiler, the performance of the proposed HSCD scheme can be comparable to that of a full-map hardware directory scheme. Given its compa rable performance and reduced hardware cost, the proposed scheme can be a viable alternative for large-scale multiprocessors such as the Cray T3D, which rely on users to maintain data coherence.