Graylog Documentation Release 3.1.0
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Practical Handbook for Determining the Ages of Gulf of Mexico And
A Practical Handbook for Determining the Ages of Gulf of Mexico and Atlantic Coast Fishes THIRD EDITION GSMFC No. 300 NOVEMBER 2020 i Gulf States Marine Fisheries Commission Commissioners and Proxies ALABAMA Senator R.L. “Bret” Allain, II Chris Blankenship, Commissioner State Senator District 21 Alabama Department of Conservation Franklin, Louisiana and Natural Resources John Roussel Montgomery, Alabama Zachary, Louisiana Representative Chris Pringle Mobile, Alabama MISSISSIPPI Chris Nelson Joe Spraggins, Executive Director Bon Secour Fisheries, Inc. Mississippi Department of Marine Bon Secour, Alabama Resources Biloxi, Mississippi FLORIDA Read Hendon Eric Sutton, Executive Director USM/Gulf Coast Research Laboratory Florida Fish and Wildlife Ocean Springs, Mississippi Conservation Commission Tallahassee, Florida TEXAS Representative Jay Trumbull Carter Smith, Executive Director Tallahassee, Florida Texas Parks and Wildlife Department Austin, Texas LOUISIANA Doug Boyd Jack Montoucet, Secretary Boerne, Texas Louisiana Department of Wildlife and Fisheries Baton Rouge, Louisiana GSMFC Staff ASMFC Staff Mr. David M. Donaldson Mr. Bob Beal Executive Director Executive Director Mr. Steven J. VanderKooy Mr. Jeffrey Kipp IJF Program Coordinator Stock Assessment Scientist Ms. Debora McIntyre Dr. Kristen Anstead IJF Staff Assistant Fisheries Scientist ii A Practical Handbook for Determining the Ages of Gulf of Mexico and Atlantic Coast Fishes Third Edition Edited by Steve VanderKooy Jessica Carroll Scott Elzey Jessica Gilmore Jeffrey Kipp Gulf States Marine Fisheries Commission 2404 Government St Ocean Springs, MS 39564 and Atlantic States Marine Fisheries Commission 1050 N. Highland Street Suite 200 A-N Arlington, VA 22201 Publication Number 300 November 2020 A publication of the Gulf States Marine Fisheries Commission pursuant to National Oceanic and Atmospheric Administration Award Number NA15NMF4070076 and NA15NMF4720399. -

Gender and the Quest in British Science Fiction Television CRITICAL EXPLORATIONS in SCIENCE FICTION and FANTASY (A Series Edited by Donald E
Gender and the Quest in British Science Fiction Television CRITICAL EXPLORATIONS IN SCIENCE FICTION AND FANTASY (a series edited by Donald E. Palumbo and C.W. Sullivan III) 1 Worlds Apart? Dualism and Transgression in Contemporary Female Dystopias (Dunja M. Mohr, 2005) 2 Tolkien and Shakespeare: Essays on Shared Themes and Language (ed. Janet Brennan Croft, 2007) 3 Culture, Identities and Technology in the Star Wars Films: Essays on the Two Trilogies (ed. Carl Silvio, Tony M. Vinci, 2007) 4 The Influence of Star Trek on Television, Film and Culture (ed. Lincoln Geraghty, 2008) 5 Hugo Gernsback and the Century of Science Fiction (Gary Westfahl, 2007) 6 One Earth, One People: The Mythopoeic Fantasy Series of Ursula K. Le Guin, Lloyd Alexander, Madeleine L’Engle and Orson Scott Card (Marek Oziewicz, 2008) 7 The Evolution of Tolkien’s Mythology: A Study of the History of Middle-earth (Elizabeth A. Whittingham, 2008) 8 H. Beam Piper: A Biography (John F. Carr, 2008) 9 Dreams and Nightmares: Science and Technology in Myth and Fiction (Mordecai Roshwald, 2008) 10 Lilith in a New Light: Essays on the George MacDonald Fantasy Novel (ed. Lucas H. Harriman, 2008) 11 Feminist Narrative and the Supernatural: The Function of Fantastic Devices in Seven Recent Novels (Katherine J. Weese, 2008) 12 The Science of Fiction and the Fiction of Science: Collected Essays on SF Storytelling and the Gnostic Imagination (Frank McConnell, ed. Gary Westfahl, 2009) 13 Kim Stanley Robinson Maps the Unimaginable: Critical Essays (ed. William J. Burling, 2009) 14 The Inter-Galactic Playground: A Critical Study of Children’s and Teens’ Science Fiction (Farah Mendlesohn, 2009) 15 Science Fiction from Québec: A Postcolonial Study (Amy J. -

Cava of Toledo; Or, the Gothic Princess
Author: Augusta Amelia Stuart Title: Cava of Toledo; or, the Gothic Princess Place of publication: London Publisher: Printed at the Minerva-Press, for A. K. Newman and Co. Date of publication: 1812 Edition: 1st ed. Number of volumes: 5 CAVA OF TOLEDO. A ROMANCE. Lane, Darling, and Co. Leadenhall-Street. CAVA OF TOLEDO; OR, The Gothic Princess. A ROMANCE. IN FIVE VOLUMES BY AUGUSTA AMELIA STUART, AUTHOR OF LUDOVICO’S TALE; THE ENGLISH BROTHERS; EXILE OF PORTUGAL, &c. &c. Fierce wars, and faithful loves, And truths severe, in fairy fiction drest. VOL. I. LONDON: PRINTED AT THE Minerva Press, FOR A. K. NEWMAN AND CO. LEADENHALL-STREET. 1812. PREFACE. THE author of the following sheets, struck by the account historians have given of the fall of the Gothic empire in Spain, took the story of Cava for the foundation of a romance: whether she has succeeded or not in rendering it interesting, must be left to her readers to judge. She thinks it, however, necessary to say she has not falsified history; all relating to the war is exact: the real characters she has endeavoured to delineate such as they were; —Rodrigo—count Julian—don Palayo—Abdalesis, the Moor—queen Egilone—Musa—and Tariff, are drawn as the Spanish history represents them. Cava was never heard of from her quitting Spain with her father; of course, her adventures, from that period, are the coinage of the author’s brain. The enchanted palace, which Rodrigo broke into, is mentioned in history. Her fictitious characters she has moulded to her own will; and has found it a much more difficult task than she expected, to write an historical romance, and adhere to the truth, while she endeavoured to embellish it. -

Nine Meals from Anarchy Oil Dependence, Climate Change and the Transition to Resilience
Nine Meals from Anarchy Oil dependence, climate change and the transition to resilience new economics foundation nef is an independent think-and-do tank that inspires and demonstrates real economic well-being. We aim to improve quality of life by promoting innovative solutions that challenge mainstream thinking on economic, environmental and social issues. We work in partnership and put people and the planet first. nef centres for: global thriving well-being future interdependence communities economy nef (the new economics foundation) is a registered charity founded in 1986 by the leaders of The Other Economic Summit (TOES), which forced issues such as international debt onto the agenda of the G8 summit meetings. It has taken a lead in helping establish new coalitions and organisations such as the Jubilee 2000 debt campaign; the Ethical Trading Initiative; the UK Social Investment Forum; and new ways to measure social and economic well-being. new economics foundation Nine Meals from Anarchy Oil dependence, climate change and the transition to resilience Schumacher Lecture, 2008 Schumacher North, Leeds, UK by Andrew Simms new economics foundation ‘Such essays cannot awat the permanence of the book. They do not belong n the learned journal. They resst packagng n perodcals.’ Ivan Illich Contents ‘Apparently sold financal nsttutons have tumbled. So, what else that we currently take for granted mght be prone to sudden collapse?’ Schumacher Lecture, 4 October 2008 Delivered by Andrew Simms Schumacher North, Leeds, UK To begin with – the world as it is 1 Nine meals from anarchy 3 Enough of problems 17 Conclusion 30 Endnotes 32 ‘Perhaps we cannot rase the wnds. -

Here Do I Start? a Newbie’S Dilemma
Copyright True Adventures, Ltd., 2019 last updated September 16, 2020 1 All rights reserved Table of Contents Introduction: What is True Dungeon? .... 4 Aura of Devotion ......................... 18 4th vs. 5th ....................................... 27 What Does That Word Mean? ....... 4 Shield Focus ................................. 19 Assassinate................................... 27 Community .................................... 4 Elf Wizard ......................................... 19 Poison Resistance ........................ 27 Character Class Overview ....................... 4 Skill Check: Planar Chart ............. 19 Wizard .............................................. 28 Combat Characters ............................. 4 Polymorph .................................... 19 Skill Check: Planar Chart ............ 28 Rogues ........................................... 4 Focused Polymorph...................... 19 Polymorph ................................... 28 Spellcasters......................................... 4 4th vs. 5th ....................................... 19 4th vs. 5th ..................................... 28 Bards ............................................. 4 Elf Wizard Spell List.................... 19 Wand Mastery .............................. 28 No Duplicate Classes in a Party ......... 4 Fighter ............................................... 20 Wizard Spell List ......................... 28 Class Card Introduction .......................... 5 Weapon Focus .............................. 20 Sorcerer Spell List ...................... -

The Coming Anarchy - Robert D
The Coming Anarchy - Robert D. Kaplan - The Atlantic http://www.theatlantic.com/magazine/print/1994/02/the-coming... • SUBSCRIBE • RENEW • GIVE A GIFT • DIGITAL EDITION Print | Close The Coming Anarchy HOW SCARCITY, CRIME, OVERPOPULATION, TRIBALISM, AND DISEASE ARE RAPIDLY DESTROYING THE SOCIAL FABRIC OF OUR PLANET By Robert D. Kaplan The Minister's eyes were like egg yolks, an aftereffect of some of the many illnesses, malaria especially, endemic in his country. There was also an irrefutable sadness in his eyes. He spoke in a slow and creaking voice, the voice of hope about to expire. Flame trees, coconut palms, and a ballpoint-blue Atlantic composed the background. None of it seemed beautiful, though. "In forty-five years I have never seen things so bad. We did not manage ourselves well after the British departed. But what we have now is something worse—the revenge of the poor, of the social failures, of the people least able to bring up children in a modern society." Then he referred to the recent coup in the West African country Sierra Leone. "The boys who took power in Sierra Leone come from houses like this." The Minister jabbed his finger at a corrugated metal shack teeming with children. "In three months these boys confiscated all the official Mercedes, Volvos, and BMWs and willfully wrecked them on the road." The Minister mentioned one of the coup's leaders, Solomon Anthony Joseph Musa, who shot the people who had paid for his schooling, "in order to erase the humiliation and mitigate the power his middle-class sponsors held over him." Tyranny is nothing new in Sierra Leone or in the rest of West Africa. -

(12) United States Patent (10) Patent No.: US 9.458,509 B2 Benenson Et Al
US0094.58509B2 (12) United States Patent (10) Patent No.: US 9.458,509 B2 Benenson et al. 45) Date of Patent: Oct. 4,9 2016 (54) MULTIPLE INPUT BIOLOGIC CLASSIFIER (52) U.S. Cl. CIRCUITS FOR CELLS CPC ............. CI2O 1/6886 (2013.01): CI2N 15/63 (2013.01); C12O 1/6897 (2013.01); G06F (75) Inventors: Yates'Biseiss. Newton :"A Liliana Ron 19/20 (2013.01); G06F 19/24 (2013.01) Wroblewska,s Arlington,s MAs (US); (58)58) Field ofO ClassificationSSCO SSea h Zhen Xie, Malden, MA (US) See application file for complete search history. (73) Assignees: PRESIDENT AND FELLOWS OF HARVARD COLLEGE, Cambridge, (56) References Cited MA (US); MASSACHUSETTS INSTITUTE OF TECHNOLOGY, FOREIGN PATENT DOCUMENTS Cambridge, MA (US) WO WO 2008134593 A1 * 11/2008 (*) Notice: Subject to any disclaimer, the term of this OTHER PUBLICATIONS patent is extended or adjusted under 35 U.S.C. 154(b) by 385 days. “Encode” definition; Oxford dictionary; http://www.oxford dictionaries.com/us/definition/american english encode; accessed (21) Appl. No.: 13/811,126 Apr. 27, 2015; pp. 5-6.* (22) PCT Filed: Jul. 22, 2011 * cited by examiner (86). PCT No.: PCT/US2O11AO45038 Primary Examiner — Antonio Galisteo Gonzalez S 371 (c)(1), (74) Attorney, Agent, or Firm — Nath, Goldberg & Meyer; (2), (4) Date: Apr. 5, 2013 Tanya E. Harkins (87) PCT Pub. No.: WO2012/012739 (57) ABSTRACT PCT Pub. Date: Jan. 26, 2012 Provided herein are high-input detector modules and multi input biological classifier circuits and systems that integrate (65) Prior Publication Data Sophisticated sensing, information processing, and actuation in living cells and permit new directions in basic biology, US 2013/02O2532 A1 Aug. -

Clips Regulate Neuronal Polarization Through Microtubule and Growth Cone Dynamics” Selbständig Und Ohne Unerlaubte Hilfe Angefertigt Habe
CLIPs regulate neuronal polarization through microtubule and growth cone dynamics Dissertation zur Erlangung des Doktorgrades der Naturwissenschaften an der Fakultät für Biologie der Ludwig–Maximilians–Universität München Angefertigt am Max-Planck-Institut für Neurobiologie in der Arbeitsgruppe ‟Axonales Wachstum und Regeneration‟ Vorgelegt von Dorothee Neukirchen München, 30. März 2010 Erstgutachter: PD Dr. Frank Bradke Zweitgutachter: Prof. Dr. Rainer Uhl Tag der mündlichen Prüfung: 19.Juli 2010 Ehrenwörtliche Versicherung: Ich versichere hiermit ehrenwörtlich, dass ich die Dissertation mit dem Titel ” CLIPs regulate neuronal polarization through microtubule and growth cone dynamics” selbständig und ohne unerlaubte Hilfe angefertigt habe. Ich habe mich dabei keiner anderen als der von mir ausdrücklich bezeichneten Hilfen und Quellen bedient. Erklärung: Hiermit erkläre ich, dass ich mich nicht anderweitig einer Doktorprüfung ohne Erfolg unterzogen habe. Die Dissertation wurde in ihrer jetzigen oder ähnlichen Form bei keiner anderen Hochschule eingereicht und hat noch keinen sonstigen Prüfungszwecken gedient. München, 30.03.2010 Dorothee Neukirchen Die vorliegende Arbeit wurde in der Arbeitsgruppe für „Axonales Wachstum und Regeneration“ von PD Dr. Frank Bradke am Max-Planck-Institut für Neurobiologie in Martinsried angefertigt. Contents List of figures ........................................................................................... III List of tables ............................................................................................ -

Narrative Quest and Healing Transformation in the Work of Reynolds Price
A VIEW TO A CURE: NARRATIVE QUEST AND HEALING TRANSFORMATION IN THE WORK OF REYNOLDS PRICE Suzanne Shrell Bolt A dissertation submitted to the faculty of the University of North Carolina at Chapel Hill in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of English. Chapel Hill 2007 Approved by: Joseph M. Flora Fred Hobson Edward Donald Kennedy George S. Lensing Kimball King © 2007 Suzanne Shrell Bolt ALL RIGHTS RESERVED ii ABSTRACT SUZANNE SHRELL BOLT: A View to a Cure: Narrative Quest and Healing Transformation in the Work of Reynolds Price (Under the direction of Joseph M. Flora) Reynolds Price is a writer of serious religious fiction whose unique evangelium reaches beyond orthodox Christianity for some of its deepest expressions. At the heart of his work is a line of radiant, threatened protagonists whom Price calls “sacrificial people. .lambs in whose blood we bathe, whose blood we drink . in the sense of the god whom men kill and eat.” And the nature of such physical and spiritual grace—its swift destruction and occasional, surprising redemption—is one of the most crucial, recurrent mysteries Price explores. As sinner, battler, victim, object of Grace, and vehicle of revelation, Price’s central type surfaces memorably in characters such as Milo Mustian ( A Generous Man ), Todd Eborn ( Love and Work ), Rob Mayfield ( A Great Circle ), Neal Avery ( New Music ), Raphael Noren ( The Tongues of Angels )—even Price’s father, Will ( Clear Pictures and the sketch “Life for Life”). Echoing the dynamics of Jesse Weston’s core grail scene (with its ritualized gesture of identification, reconciliation, spiritual revelation, and healing), each narrative staging resembles a kind of passion play. -
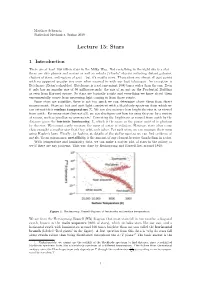
Lecture 15: Stars
Matthew Schwartz Statistical Mechanics, Spring 2019 Lecture 15: Stars 1 Introduction There are at least 100 billion stars in the Milky Way. Not everything in the night sky is a star there are also planets and moons as well as nebula (cloudy objects including distant galaxies, clusters of stars, and regions of gas) but it's mostly stars. These stars are almost all just points with no apparent angular size even when zoomed in with our best telescopes. An exception is Betelgeuse (Orion's shoulder). Betelgeuse is a red supergiant 1000 times wider than the sun. Even it only has an angular size of 50 milliarcseconds: the size of an ant on the Prudential Building as seen from Harvard square. So stars are basically points and everything we know about them experimentally comes from measuring light coming in from those points. Since stars are pointlike, there is not too much we can determine about them from direct measurement. Stars are hot and emit light consistent with a blackbody spectrum from which we can extract their surface temperature Ts. We can also measure how bright the star is, as viewed from earth . For many stars (but not all), we can also gure out how far away they are by a variety of means, such as parallax measurements.1 Correcting the brightness as viewed from earth by the distance gives the intrinsic luminosity, L, which is the same as the power emitted in photons by the star. We cannot easily measure the mass of a star in isolation. However, stars often come close enough to another star that they orbit each other. -

SPECIES IDENTIFICATION GUIDE National Plant Monitoring Scheme SPECIES IDENTIFICATION GUIDE
National Plant Monitoring Scheme SPECIES IDENTIFICATION GUIDE National Plant Monitoring Scheme SPECIES IDENTIFICATION GUIDE Contents White / Cream ................................ 2 Grasses ...................................... 130 Yellow ..........................................33 Rushes ....................................... 138 Red .............................................63 Sedges ....................................... 140 Pink ............................................66 Shrubs / Trees .............................. 148 Blue / Purple .................................83 Wood-rushes ................................ 154 Green / Brown ............................. 106 Indexes Aquatics ..................................... 118 Common name ............................. 155 Clubmosses ................................. 124 Scientific name ............................. 160 Ferns / Horsetails .......................... 125 Appendix .................................... 165 Key Traffic light system WF symbol R A G Species with the symbol G are For those recording at the generally easier to identify; Wildflower Level only. species with the symbol A may be harder to identify and additional information is provided, particularly on illustrations, to support you. Those with the symbol R may be confused with other species. In this instance distinguishing features are provided. Introduction This guide has been produced to help you identify the plants we would like you to record for the National Plant Monitoring Scheme. There is an index at -

UCA 2018 Final.Pdf
Internal work DISTRIBUTION Episode Season Production reference at the Used subtitle or episode title Used main title Original subtitle or episode title Original main title Unknown Share YEAR number number country sending society Država Obracun ZRB Master Naslov Master Orig Original Br. Epizode Sezona Uloga UCA Udio UCA produkcije Winston Churchill: div Winston Churchill: A Giant in the 2018 1340360 stoljeća Century RE 100,00% ES 2018 1337032 Šetnja Galicijom Un paseo por Galicia RE 100,00% HR 2018 1282048 Ottavio AS 30.00% NL 2018 1370582 Trag krvi Bloedlink AS;CM 55.00% YU 2018 561332 Tajna starog tavana RE 45.00% ES Coco i Drilla: Božićna 2018 1393940 avantura Coco and Drilla: Christmas Special AS;CT 60.00% GB Harry i Meghan: Njihovim Meghan and Harry: In Their Own 2018 1312706 riječima Words AS;CM 55.00% DE 2018 599124 Kuća izazova No Good Deed RE 45.00% JP Curly: Najmanji psić na 2018 1069750 svijetu Curly: The Littlest Puppy AS;CT 60.00% GB Od Diane do Meghan: Tajne Diana to Meghan: Royal Wedding 2018 1312712 kraljevskih vjenčanja Secrets AS;CM 55.00% DE 2018 1052596 Pčelica Maja Die Biene Maja CT 30.00% AU 2018 853426 Ples malog pingvina Happy Feet CT 30.00% AU 2018 1011238 Ples malog pingvina 2 Happy Feet Two CT 30.00% GB 2018 871886 Priča o mišu zvanom Despero The Tale of Despereaux CT 30.00% ES 2018 1325968 Top Cat: Mačak za 5 Don Gato: El Inicio de la Pandilla CT 30.00% CA 2018 1321098 Priča o obitelji Robinson Swiss Family Robinson CT 30.00% GB The Crimson Wing: Mystery of the 2018 1313070 Misterij ružičastih plamenaca Flamingos