A Peripheral Blood Transcriptomic Signature Predicts Autoantibody Development in Infants at Risk of Type 1 Diabetes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Genetic Background of Clinical Mastitis in Holstein- Friesian Cattle
Animal (2019), 13:1 0p , p 2156–2163 © The Animal Consortium 2019 animal doi:10.1017/S1751731119000338 The genetic background of clinical mastitis in Holstein- Friesian cattle J. Szyda1,2†, M. Mielczarek1,2,M.Frąszczak1, G. Minozzi3, J. L. Williams4 and K. Wojdak-Maksymiec5 1Biostatistics Group, Department of Genetics, Wroclaw University of Environmental and Life Sciences, Kozuchowska 7, 51-631 Wroclaw, Poland; 2Institute of Animal Breeding, Krakowska 1, 32-083 Balice, Poland; 3Department of Veterinary Medicine, Università degli Studi di Milano, Via Giovanni Celoria 10, 20133 Milano, Italy; 4Davies Research Centre, School of Animal and Veterinary Sciences, University of Adelaide, Roseworthy, SA 5371, Australia; 5Department of Animal Genetics, West Pomeranian University of Technology, Doktora Judyma 26, 71-466 Szczecin, Poland (Received 15 September 2018; Accepted 28 January 2019; First published online 5 March 2019) Mastitis is an inflammatory disease of the mammary gland, which has a significant economic impact and is an animal welfare concern. This work examined the association between single nucleotide polymorphisms (SNPs) and copy number variations (CNVs) with the incidence of clinical mastitis (CM). Using information from 16 half-sib pairs of Holstein-Friesian cows (32 animals in total) we searched for genomic regions that differed between a healthy (no incidence of CM) and a mastitis-prone (multiple incidences of CM) half-sib. Three cows with average sequence depth of coverage below 10 were excluded, which left 13 half-sib pairs available for comparisons. In total, 191 CNV regions were identified, which were deleted in a mastitis-prone cow, but present in its healthy half-sib and overlapped in at least nine half-sib pairs. -

Nuclear and Mitochondrial Genome Defects in Autisms
UC Irvine UC Irvine Previously Published Works Title Nuclear and mitochondrial genome defects in autisms. Permalink https://escholarship.org/uc/item/8vq3278q Journal Annals of the New York Academy of Sciences, 1151(1) ISSN 0077-8923 Authors Smith, Moyra Spence, M Anne Flodman, Pamela Publication Date 2009 DOI 10.1111/j.1749-6632.2008.03571.x License https://creativecommons.org/licenses/by/4.0/ 4.0 Peer reviewed eScholarship.org Powered by the California Digital Library University of California THE YEAR IN HUMAN AND MEDICAL GENETICS 2009 Nuclear and Mitochondrial Genome Defects in Autisms Moyra Smith, M. Anne Spence, and Pamela Flodman Department of Pediatrics, University of California, Irvine, California In this review we will evaluate evidence that altered gene dosage and structure im- pacts neurodevelopment and neural connectivity through deleterious effects on synap- tic structure and function, and evidence that the latter are key contributors to the risk for autism. We will review information on alterations of structure of mitochondrial DNA and abnormal mitochondrial function in autism and indications that interactions of the nuclear and mitochondrial genomes may play a role in autism pathogenesis. In a final section we will present data derived using Affymetrixtm SNP 6.0 microar- ray analysis of DNA of a number of subjects and parents recruited to our autism spectrum disorders project. We include data on two sets of monozygotic twins. Col- lectively these data provide additional evidence of nuclear and mitochondrial genome imbalance in autism and evidence of specific candidate genes in autism. We present data on dosage changes in genes that map on the X chromosomes and the Y chro- mosome. -

RNF122: a Novel Ubiquitin Ligase Associated with Calcium-Modulating Cyclophilin Ligand BMC Cell Biology 2010, 11:41 References 1
Peng et al. BMC Cell Biology 2010, 11:41 http://www.biomedcentral.com/1471-2121/11/41 RESEARCH ARTICLE Open Access RNF122:Research article A novel ubiquitin ligase associated with calcium-modulating cyclophilin ligand Zhi Peng1,4, Taiping Shi*1,2,3 and Dalong Ma1,2,3 Abstract Background: RNF122 is a recently discovered RING finger protein that is associated with HEK293T cell viability and is overexpressed in anaplastic thyroid cancer cells. RNF122 owns a RING finger domain in C terminus and transmembrane domain in N terminus. However, the biological mechanism underlying RNF122 action remains unknown. Results: In this study, we characterized RNF122 both biochemically and intracellularly in order to gain an understanding of its biological role. RNF122 was identified as a new ubiquitin ligase that can ubiquitinate itself and undergoes degradation in a RING finger-dependent manner. From a yeast two-hybrid screen, we identified calcium- modulating cyclophilin ligand (CAML) as an RNF122-interacting protein. To examine the interaction between CAML and RNF122, we performed co-immunoprecipitation and colocalization experiments using intact cells. What is more, we found that CAML is not a substrate of ubiquitin ligase RNF122, but that, instead, it stabilizes RNF122. Conclusions: RNF122 can be characterized as a C3H2C3-type RING finger-containing E3 ubiquitin ligase localized to the ER. RNF122 promotes its own degradation in a RING finger-and proteasome-dependent manner. RNF122 interacts with CAML, and its E3 ubiquitin ligase activity was noted to be dependent on the RING finger domain. Background RING finger proteins contain a RING finger domain, The ubiquitin-proteasome system is involved in protein which was first identified as being encoded by the Really degradation and many biological processes such as tran- Interesting New Gene in the early 1990 s [5]. -

Analysis of Gene Expression Data for Gene Ontology
ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION A Thesis Presented to The Graduate Faculty of The University of Akron In Partial Fulfillment of the Requirements for the Degree Master of Science Robert Daniel Macholan May 2011 ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION Robert Daniel Macholan Thesis Approved: Accepted: _______________________________ _______________________________ Advisor Department Chair Dr. Zhong-Hui Duan Dr. Chien-Chung Chan _______________________________ _______________________________ Committee Member Dean of the College Dr. Chien-Chung Chan Dr. Chand K. Midha _______________________________ _______________________________ Committee Member Dean of the Graduate School Dr. Yingcai Xiao Dr. George R. Newkome _______________________________ Date ii ABSTRACT A tremendous increase in genomic data has encouraged biologists to turn to bioinformatics in order to assist in its interpretation and processing. One of the present challenges that need to be overcome in order to understand this data more completely is the development of a reliable method to accurately predict the function of a protein from its genomic information. This study focuses on developing an effective algorithm for protein function prediction. The algorithm is based on proteins that have similar expression patterns. The similarity of the expression data is determined using a novel measure, the slope matrix. The slope matrix introduces a normalized method for the comparison of expression levels throughout a proteome. The algorithm is tested using real microarray gene expression data. Their functions are characterized using gene ontology annotations. The results of the case study indicate the protein function prediction algorithm developed is comparable to the prediction algorithms that are based on the annotations of homologous proteins. -

Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model
Downloaded from http://www.jimmunol.org/ by guest on September 25, 2021 T + is online at: average * The Journal of Immunology , 34 of which you can access for free at: 2016; 197:1477-1488; Prepublished online 1 July from submission to initial decision 4 weeks from acceptance to publication 2016; doi: 10.4049/jimmunol.1600589 http://www.jimmunol.org/content/197/4/1477 Molecular Profile of Tumor-Specific CD8 Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. Waugh, Sonia M. Leach, Brandon L. Moore, Tullia C. Bruno, Jonathan D. Buhrman and Jill E. Slansky J Immunol cites 95 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html http://www.jimmunol.org/content/suppl/2016/07/01/jimmunol.160058 9.DCSupplemental This article http://www.jimmunol.org/content/197/4/1477.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 25, 2021. The Journal of Immunology Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. -
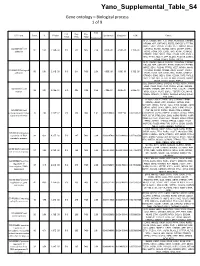
Supplemental Tables4.Pdf
Yano_Supplemental_Table_S4 Gene ontology – Biological process 1 of 9 Fold List Pop Pop GO Term Count % PValue Bonferroni Benjamini FDR Genes Total Hits Total Enrichment DLC1, CADM1, NELL2, CLSTN1, PCDHGA8, CTNNB1, NRCAM, APP, CNTNAP2, FERT2, RAPGEF1, PTPRM, MPDZ, SDK1, PCDH9, PTPRS, VEZT, NRXN1, MYH9, GO:0007155~cell CTNNA2, NCAM1, NCAM2, DDR1, LSAMP, CNTN1, 50 5.61 2.14E-08 510 311 7436 2.34 4.50E-05 4.50E-05 3.70E-05 adhesion ROR2, VCAN, DST, LIMS1, TNC, ASTN1, CTNND2, CTNND1, CDH2, NEO1, CDH4, CD24A, FAT3, PVRL3, TRO, TTYH1, MLLT4, LPP, NLGN1, PCDH19, LAMA1, ITGA9, CDH13, CDON, PSPC1 DLC1, CADM1, NELL2, CLSTN1, PCDHGA8, CTNNB1, NRCAM, APP, CNTNAP2, FERT2, RAPGEF1, PTPRM, MPDZ, SDK1, PCDH9, PTPRS, VEZT, NRXN1, MYH9, GO:0022610~biological CTNNA2, NCAM1, NCAM2, DDR1, LSAMP, CNTN1, 50 5.61 2.14E-08 510 311 7436 2.34 4.50E-05 4.50E-05 3.70E-05 adhesion ROR2, VCAN, DST, LIMS1, TNC, ASTN1, CTNND2, CTNND1, CDH2, NEO1, CDH4, CD24A, FAT3, PVRL3, TRO, TTYH1, MLLT4, LPP, NLGN1, PCDH19, LAMA1, ITGA9, CDH13, CDON, PSPC1 DCC, ENAH, PLXNA2, CAPZA2, ATP5B, ASTN1, PAX6, ZEB2, CDH2, CDH4, GLI3, CD24A, EPHB1, NRCAM, GO:0006928~cell CTTNBP2, EDNRB, APP, PTK2, ETV1, CLASP2, STRBP, 36 4.04 3.46E-07 510 205 7436 2.56 7.28E-04 3.64E-04 5.98E-04 motion NRG1, DCLK1, PLAT, SGPL1, TGFBR1, EVL, MYH9, YWHAE, NCKAP1, CTNNA2, SEMA6A, EPHA4, NDEL1, FYN, LRP6 PLXNA2, ADCY5, PAX6, GLI3, CTNNB1, LPHN2, EDNRB, LPHN3, APP, CSNK2A1, GPR45, NRG1, RAPGEF1, WWOX, SGPL1, TLE4, SPEN, NCAM1, DDR1, GRB10, GRM3, GNAQ, HIPK1, GNB1, HIPK2, PYGO1, GO:0007166~cell RNF138, ROR2, CNTN1, -

Functional Characterization of the New 8Q21 Asthma Risk Locus
Functional characterization of the new 8q21 Asthma risk locus Cristina M T Vicente B.Sc, M.Sc A thesis submitted for the degree of Doctor of Philosophy at The University of Queensland in 2017 Faculty of Medicine Abstract Genome wide association studies (GWAS) provide a powerful tool to identify genetic variants associated with asthma risk. However, the target genes for many allergy risk variants discovered to date are unknown. In a recent GWAS, Ferreira et al. identified a new association between asthma risk and common variants located on chromosome 8q21. The overarching aim of this thesis was to elucidate the biological mechanisms underlying this association. Specifically, the goals of this study were to identify the gene(s) underlying the observed association and to study their contribution to asthma pathophysiology. Using genetic data from the 1000 Genomes Project, we first identified 118 variants in linkage disequilibrium (LD; r2>0.6) with the sentinel allergy risk SNP (rs7009110) on chromosome 8q21. Of these, 35 were found to overlap one of four Putative Regulatory Elements (PREs) identified in this region in a lymphoblastoid cell line (LCL), based on epigenetic marks measured by the ENCODE project. Results from analysis of gene expression data generated for LCLs (n=373) by the Geuvadis consortium indicated that rs7009110 is associated with the expression of only one nearby gene: PAG1 - located 732 kb away. PAG1 encodes a transmembrane adaptor protein localized to lipid rafts, which is highly expressed in immune cells. Results from chromosome conformation capture (3C) experiments showed that PREs in the region of association physically interacted with the promoter of PAG1. -

Supplementary Table 1: Adhesion Genes Data Set
Supplementary Table 1: Adhesion genes data set PROBE Entrez Gene ID Celera Gene ID Gene_Symbol Gene_Name 160832 1 hCG201364.3 A1BG alpha-1-B glycoprotein 223658 1 hCG201364.3 A1BG alpha-1-B glycoprotein 212988 102 hCG40040.3 ADAM10 ADAM metallopeptidase domain 10 133411 4185 hCG28232.2 ADAM11 ADAM metallopeptidase domain 11 110695 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 195222 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 165344 8751 hCG20021.3 ADAM15 ADAM metallopeptidase domain 15 (metargidin) 189065 6868 null ADAM17 ADAM metallopeptidase domain 17 (tumor necrosis factor, alpha, converting enzyme) 108119 8728 hCG15398.4 ADAM19 ADAM metallopeptidase domain 19 (meltrin beta) 117763 8748 hCG20675.3 ADAM20 ADAM metallopeptidase domain 20 126448 8747 hCG1785634.2 ADAM21 ADAM metallopeptidase domain 21 208981 8747 hCG1785634.2|hCG2042897 ADAM21 ADAM metallopeptidase domain 21 180903 53616 hCG17212.4 ADAM22 ADAM metallopeptidase domain 22 177272 8745 hCG1811623.1 ADAM23 ADAM metallopeptidase domain 23 102384 10863 hCG1818505.1 ADAM28 ADAM metallopeptidase domain 28 119968 11086 hCG1786734.2 ADAM29 ADAM metallopeptidase domain 29 205542 11085 hCG1997196.1 ADAM30 ADAM metallopeptidase domain 30 148417 80332 hCG39255.4 ADAM33 ADAM metallopeptidase domain 33 140492 8756 hCG1789002.2 ADAM7 ADAM metallopeptidase domain 7 122603 101 hCG1816947.1 ADAM8 ADAM metallopeptidase domain 8 183965 8754 hCG1996391 ADAM9 ADAM metallopeptidase domain 9 (meltrin gamma) 129974 27299 hCG15447.3 ADAMDEC1 ADAM-like, -

140503 IPF Signatures Supplement Withfigs Thorax
Supplementary material for Heterogeneous gene expression signatures correspond to distinct lung pathologies and biomarkers of disease severity in idiopathic pulmonary fibrosis Daryle J. DePianto1*, Sanjay Chandriani1⌘*, Alexander R. Abbas1, Guiquan Jia1, Elsa N. N’Diaye1, Patrick Caplazi1, Steven E. Kauder1, Sabyasachi Biswas1, Satyajit K. Karnik1#, Connie Ha1, Zora Modrusan1, Michael A. Matthay2, Jasleen Kukreja3, Harold R. Collard2, Jackson G. Egen1, Paul J. Wolters2§, and Joseph R. Arron1§ 1Genentech Research and Early Development, South San Francisco, CA 2Department of Medicine, University of California, San Francisco, CA 3Department of Surgery, University of California, San Francisco, CA ⌘Current address: Novartis Institutes for Biomedical Research, Emeryville, CA. #Current address: Gilead Sciences, Foster City, CA. *DJD and SC contributed equally to this manuscript §PJW and JRA co-directed this project Address correspondence to Paul J. Wolters, MD University of California, San Francisco Department of Medicine Box 0111 San Francisco, CA 94143-0111 [email protected] or Joseph R. Arron, MD, PhD Genentech, Inc. MS 231C 1 DNA Way South San Francisco, CA 94080 [email protected] 1 METHODS Human lung tissue samples Tissues were obtained at UCSF from clinical samples from IPF patients at the time of biopsy or lung transplantation. All patients were seen at UCSF and the diagnosis of IPF was established through multidisciplinary review of clinical, radiological, and pathological data according to criteria established by the consensus classification of the American Thoracic Society (ATS) and European Respiratory Society (ERS), Japanese Respiratory Society (JRS), and the Latin American Thoracic Association (ALAT) (ref. 5 in main text). Non-diseased normal lung tissues were procured from lungs not used by the Northern California Transplant Donor Network. -

The Role of Non-Coding Rnas in Uveal Melanoma
cancers Review The Role of Non-Coding RNAs in Uveal Melanoma Manuel Bande 1,2,*, Daniel Fernandez-Diaz 1,2, Beatriz Fernandez-Marta 1, Cristina Rodriguez-Vidal 3, Nerea Lago-Baameiro 4, Paula Silva-Rodríguez 2,5, Laura Paniagua 6, María José Blanco-Teijeiro 1,2, María Pardo 2,4 and Antonio Piñeiro 1,2 1 Department of Ophthalmology, University Hospital of Santiago de Compostela, Ramon Baltar S/N, 15706 Santiago de Compostela, Spain; [email protected] (D.F.-D.); [email protected] (B.F.-M.); [email protected] (M.J.B.-T.); [email protected] (A.P.) 2 Tumores Intraoculares en el Adulto, Instituto de Investigación Sanitaria de Santiago (IDIS), 15706 Santiago de Compostela, Spain; [email protected] (P.S.-R.); [email protected] (M.P.) 3 Department of Ophthalmology, University Hospital of Cruces, Cruces Plaza, S/N, 48903 Barakaldo, Vizcaya, Spain; [email protected] 4 Grupo Obesidómica, Instituto de Investigación Sanitaria de Santiago (IDIS), 15706 Santiago de Compostela, Spain; [email protected] 5 Fundación Pública Galega de Medicina Xenómica, Clinical University Hospital, SERGAS, 15706 Santiago de Compostela, Spain 6 Department of Ophthalmology, University Hospital of Coruña, Praza Parrote, S/N, 15006 La Coruña, Spain; [email protected] * Correspondence: [email protected]; Tel.: +34-981951756; Fax: +34-981956189 Received: 13 September 2020; Accepted: 9 October 2020; Published: 12 October 2020 Simple Summary: The development of uveal melanoma is a multifactorial and multi-step process, in which abnormal gene expression plays a key role. -

Ubiquitin-Dependent Regulation of the WNT Cargo Protein EVI/WLS Handelt Es Sich Um Meine Eigenständig Erbrachte Leistung
DISSERTATION submitted to the Combined Faculty of Natural Sciences and Mathematics of the Ruperto-Carola University of Heidelberg, Germany for the degree of Doctor of Natural Sciences presented by Lucie Magdalena Wolf, M.Sc. born in Nuremberg, Germany Date of oral examination: 2nd February 2021 Ubiquitin-dependent regulation of the WNT cargo protein EVI/WLS Referees: Prof. Dr. Michael Boutros apl. Prof. Dr. Viktor Umansky If you don’t think you might, you won’t. Terry Pratchett This work was accomplished from August 2015 to November 2020 under the supervision of Prof. Dr. Michael Boutros in the Division of Signalling and Functional Genomics at the German Cancer Research Center (DKFZ), Heidelberg, Germany. Contents Contents ......................................................................................................................... ix 1 Abstract ....................................................................................................................xiii 1 Zusammenfassung .................................................................................................... xv 2 Introduction ................................................................................................................ 1 2.1 The WNT signalling pathways and cancer ........................................................................ 1 2.1.1 Intercellular communication ........................................................................................ 1 2.1.2 WNT ligands are conserved morphogens ................................................................. -

The Role of the Transmembrane RING Finger Proteins in Cellular and Organelle Function
Membranes 2011, 1, 354-393; doi:10.3390/membranes1040354 OPEN ACCESS membranes ISSN 2077-0375 www.mdpi.com/journal/membranes Review The Role of the Transmembrane RING Finger Proteins in Cellular and Organelle Function Nobuhiro Nakamura Department of Biological Sciences, Tokyo Institute of Technology, 4259-B13 Nagatsuta-cho, Midori-ku, Yokohama 226-8501, Japan; E-Mail: [email protected]; Tel.: +81-45-924-5726; Fax: +81-45-924-5824 Received: 26 October 2011; in revised form: 24 November 2011 / Accepted: 5 December 2011 / Published: 9 December 2011 Abstract: A large number of RING finger (RNF) proteins are present in eukaryotic cells and the majority of them are believed to act as E3 ubiquitin ligases. In humans, 49 RNF proteins are predicted to contain transmembrane domains, several of which are specifically localized to membrane compartments in the secretory and endocytic pathways, as well as to mitochondria and peroxisomes. They are thought to be molecular regulators of the organization and integrity of the functions and dynamic architecture of cellular membrane and membranous organelles. Emerging evidence has suggested that transmembrane RNF proteins control the stability, trafficking and activity of proteins that are involved in many aspects of cellular and physiological processes. This review summarizes the current knowledge of mammalian transmembrane RNF proteins, focusing on their roles and significance. Keywords: endocytosis; ERAD; immune regulation; membrane trafficking; mitochondrial dynamics; proteasome; quality control; RNF; ubiquitin; ubiquitin ligase 1. Introduction Ubiquitination is a posttranslational modification that mediates the covalent attachment of ubiquitin (Ub), a small, highly conserved, cytoplasmic protein of 76 amino acid residues, to target proteins.