Name Synopsis Description Options
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Freebsd File Formats Manual Libarchive-Formats (5)
libarchive-formats (5) FreeBSD File Formats Manual libarchive-formats (5) NAME libarchive-formats —archive formats supported by the libarchive library DESCRIPTION The libarchive(3) library reads and writes a variety of streaming archive formats. Generally speaking, all of these archive formats consist of a series of “entries”. Each entry stores a single file system object, such as a file, directory,orsymbolic link. The following provides a brief description of each format supported by libarchive,with some information about recognized extensions or limitations of the current library support. Note that just because a format is supported by libarchive does not imply that a program that uses libarchive will support that format. Applica- tions that use libarchive specify which formats theywish to support, though manyprograms do use libarchive convenience functions to enable all supported formats. TarFormats The libarchive(3) library can read most tar archives. However, itonly writes POSIX-standard “ustar” and “pax interchange” formats. All tar formats store each entry in one or more 512-byte records. The first record is used for file metadata, including filename, timestamp, and mode information, and the file data is stored in subsequent records. Later variants have extended this by either appropriating undefined areas of the header record, extending the header to multiple records, or by storing special entries that modify the interpretation of subsequent entries. gnutar The libarchive(3) library can read GNU-format tar archives. It currently supports the most popular GNU extensions, including modern long filename and linkname support, as well as atime and ctime data. The libarchive library does not support multi-volume archives, nor the old GNU long filename format. -

CDE: Run Any Linux Application On-Demand Without Installation
CDE: Run Any Linux Application On-Demand Without Installation Philip J. Guo Stanford University [email protected] Abstract with compiling, installing, and configuring software and their myriad of dependencies. For example, the official There is a huge ecosystem of free software for Linux, but Google Chrome help forum for “install/uninstall issues” since each Linux distribution (distro) contains a differ- has over 5800 threads. ent set of pre-installed shared libraries, filesystem layout In addition, a study of US labor statistics predicts that conventions, and other environmental state, it is difficult by 2012, 13 million American workers will do program- to create and distribute software that works without has- ming in their jobs, but amongst those, only 3 million will sle across all distros. Online forums and mailing lists be professional software developers [24]. Thus, there are are filled with discussions of users’ troubles with com- potentially millions of people who still need to get their piling, installing, and configuring Linux software and software to run on other machines but who are unlikely their myriad of dependencies. To address this ubiqui- to invest the effort to create one-click installers or wres- tous problem, we have created an open-source tool called tle with package managers, since their primary job is not CDE that automatically packages up the Code, Data, and to release production-quality software. For example: Environment required to run a set of x86-Linux pro- grams on other x86-Linux machines. Creating a CDE • System administrators often hack together ad- package is as simple as running the target application un- hoc utilities comprised of shell scripts and custom- der CDE’s monitoring, and executing a CDE package re- compiled versions of open-source software, in or- quires no installation, configuration, or root permissions. -

IDOL Keyview PDF Export SDK 12.6 C Programming Guide
KeyView Software Version 12.6 PDF Export SDK C Programming Guide Document Release Date: June 2020 Software Release Date: June 2020 PDF Export SDK C Programming Guide Legal notices Copyright notice © Copyright 1997-2020 Micro Focus or one of its affiliates. The only warranties for products and services of Micro Focus and its affiliates and licensors (“Micro Focus”) are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. Micro Focus shall not be liable for technical or editorial errors or omissions contained herein. The information contained herein is subject to change without notice. Documentation updates The title page of this document contains the following identifying information: l Software Version number, which indicates the software version. l Document Release Date, which changes each time the document is updated. l Software Release Date, which indicates the release date of this version of the software. To check for updated documentation, visit https://www.microfocus.com/support-and-services/documentation/. Support Visit the MySupport portal to access contact information and details about the products, services, and support that Micro Focus offers. This portal also provides customer self-solve capabilities. It gives you a fast and efficient way to access interactive technical support tools needed to manage your business. As a valued support customer, you can benefit by using the MySupport portal to: l Search for knowledge documents of interest l Access product documentation l View software vulnerability alerts l Enter into discussions with other software customers l Download software patches l Manage software licenses, downloads, and support contracts l Submit and track service requests l Contact customer support l View information about all services that Support offers Many areas of the portal require you to sign in. -

Forcepoint DLP Supported File Formats and Size Limits
Forcepoint DLP Supported File Formats and Size Limits Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 This article provides a list of the file formats that can be analyzed by Forcepoint DLP, file formats from which content and meta data can be extracted, and the file size limits for network, endpoint, and discovery functions. See: ● Supported File Formats ● File Size Limits © 2021 Forcepoint LLC Supported File Formats Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 The following tables lists the file formats supported by Forcepoint DLP. File formats are in alphabetical order by format group. ● Archive For mats, page 3 ● Backup Formats, page 7 ● Business Intelligence (BI) and Analysis Formats, page 8 ● Computer-Aided Design Formats, page 9 ● Cryptography Formats, page 12 ● Database Formats, page 14 ● Desktop publishing formats, page 16 ● eBook/Audio book formats, page 17 ● Executable formats, page 18 ● Font formats, page 20 ● Graphics formats - general, page 21 ● Graphics formats - vector graphics, page 26 ● Library formats, page 29 ● Log formats, page 30 ● Mail formats, page 31 ● Multimedia formats, page 32 ● Object formats, page 37 ● Presentation formats, page 38 ● Project management formats, page 40 ● Spreadsheet formats, page 41 ● Text and markup formats, page 43 ● Word processing formats, page 45 ● Miscellaneous formats, page 53 Supported file formats are added and updated frequently. Key to support tables Symbol Description Y The format is supported N The format is not supported P Partial metadata -

Unix Command
Veloce descrizione di comandi Unix Buona parte dei comandi dell’elenco seguente fanno parte della distribuzione standard di molte architetture Unix. Per i dettagli vedere le relative pagine di manuale, invocabili con il comando "man topic". a2p convertitore awk - perl amstex AmSTeX language create, modify, and extract from archives (per creare ar librerie) arch print machine architecture at, batch, atq, atrm - queue, examine or delete jobs for later at execution awk gawk - pattern scanning and processing language basename strip directory and suffix from filenames bash GNU Bourne-Again SHell bc An arbitrary precision calculator language bibtex make a bibliography for (La)TeX c++ GNU project C++ Compiler cal displays a calendar cat concatenate files and print on the standard output cc gcc, g++ - GNU project C and C++ Compiler checkalias usage: /usr/bin/checkalias alias .. chfn change your finger information chgrp change the group ownership of files chmod change the access permissions of files chown change the user and group ownership of files chsh change your login shell cksum checksum and count the bytes in a file clear clear terminal screen cmp compare two files col filter reverse line feeds from input column columnate lists comm compare two sorted files line by line compress compress, uncompress, zcat - compress and expand data cp copy files cpio copy files to and from archives tcsh - C shell with file name completion and command line csh editing csplit split a file into sections determined by context lines cut remove sections from each -

GNU Sharutils, Version 4.1.9 a Set of Shell Archiver Utilities Edition 4.1.9, 28 October
GNU sharutils, version 4.1.9 A set of shell archiver utilities Edition 4.1.9, 28 October Jan Dj¨arv Francois Pinard Copyright c 1994 Free Software Foundation, Inc. Permission is granted to make and distribute verbatim copies of this manual provided the copy- right notice and this permission notice are preserved on all copies. Permission is granted to copy and distribute modified versions of this manual under the condi- tions for verbatim copying, provided that the entire resulting derived work is distributed under the terms of a permission notice identical to this one. Permission is granted to copy and distribute translations of this manual into another language, under the above conditions for modified versions, except that this permission notice may be stated in a translation approved by the Foundation. i Short Contents 1 Introduction to both programs ................................... 1 2 Invoking the shar program ..................................... 2 3 Invoking the unshar program ................................... 7 4 Miscellaneous considerations .................................... 8 ii Table of Contents 1 Introduction to both programs .......................... 1 2 Invoking the shar program .............................. 2 2.1 Selecting files................................................................ 2 2.2 Splitting output ............................................................. 2 2.3 Controlling the shar headers .................................................. 3 2.4 Selecting how files are stocked ............................................... -

Building and Installing Software Packages for Linux Building and Installing Software Packages for Linux
Building and Installing Software Packages for Linux Building and Installing Software Packages for Linux Table of Contents Building and Installing Software Packages for Linux.....................................................................................1 Mendel Cooper −−− http://personal.riverusers.com/~thegrendel/...........................................................1 1.Introduction...........................................................................................................................................1 2.Unpacking the Files..............................................................................................................................1 3.Using Make...........................................................................................................................................1 4.Prepackaged Binaries............................................................................................................................1 5.Termcap and Terminfo Issues...............................................................................................................1 6.Backward Compatibility With a.out Binaries.......................................................................................1 7.Troubleshooting....................................................................................................................................2 8.Final Steps.............................................................................................................................................2 -

MBS Compression Plugin.Pdf
MBS Compression Plugin Documentation Christian Schmitz September 6, 2021 2 0.1 Introduction This is the PDF version of the documentation for the Xojo Plug-in from Monkeybread Software Germany. Plugin part: MBS Compression Plugin 0.2 Content • 1 List of all topics 3 • 2 List of all classes 29 • 3 List of all modules 31 • 4 List of all global methods 33 • 5 All items in this plugin 35 • 8 List of Questions in the FAQ 225 • 9 The FAQ 235 Chapter 1 List of Topics • 5 Archive 35 – 5.1.1 class ArchiveEntryMBS 35 ∗ 5.1.7 Clear 36 ∗ 5.1.8 ClearACL 36 ∗ 5.1.9 ClearXAttr 36 ∗ 5.1.10 Clone as ArchiveEntryMBS 36 ∗ 5.1.11 Constructor 37 ∗ 5.1.12 Constructor(Archive as ArchiverMBS) 37 ∗ 5.1.13 Destructor 37 ∗ 5.1.14 GetFFlags(byref FlagsSet as UInt64, byref FlagsClear as UInt64) 37 ∗ 5.1.15 SetFFlags(FlagsSet as UInt64, FlagsClear as UInt64) 37 ∗ 5.1.16 SetLink(link as string) 37 ∗ 5.1.17 UnsetATime 38 ∗ 5.1.18 UnsetBTime 38 ∗ 5.1.19 UnsetCTime 38 ∗ 5.1.20 UnsetGName 38 ∗ 5.1.21 UnsetHardLink 38 ∗ 5.1.22 UnsetMTime 38 ∗ 5.1.23 UnsetPathName 39 ∗ 5.1.24 UnsetSize 39 ∗ 5.1.25 UnsetSymLink 39 ∗ 5.1.26 UnsetUName 39 ∗ 5.1.28 ADateTime as DateTime 39 ∗ 5.1.29 ATime as Date 40 ∗ 5.1.30 ATimeSet as Boolean 40 ∗ 5.1.31 BDateTime as DateTime 40 ∗ 5.1.32 BTime as Date 40 3 4 CHAPTER 1. LIST OF TOPICS ∗ 5.1.33 BTimeSet as Boolean 40 ∗ 5.1.34 CDateTime as DateTime 41 ∗ 5.1.35 CTime as Date 41 ∗ 5.1.36 CTimeSet as Boolean 41 ∗ 5.1.37 Dev as Integer 41 ∗ 5.1.38 DevMajor as Integer 41 ∗ 5.1.39 DevMinor as Integer 42 ∗ 5.1.40 DevSet as Boolean 42 ∗ 5.1.41 FFlags as -

Freebsd General Commands Manual BSDCPIO (1)
BSDCPIO (1) FreeBSD General Commands Manual BSDCPIO (1) NAME cpio —copyfiles to and from archives SYNOPSIS cpio { −i}[options][pattern . ..][<archive] cpio { −o}[options] <name-list [>archive] cpio { −p}[options] dest-dir < name-list DESCRIPTION cpio copies files between archivesand directories. This implementation can extract from tar,pax, cpio, zip, jar,ar, and ISO 9660 cdrom images and can create tar,pax, cpio, ar,and shar archives. The first option to cpio is a mode indicator from the following list: −i Input. Read an archive from standard input (unless overriden) and extract the contents to disk or (if the −t option is specified) list the contents to standard output. If one or more file patterns are specified, only files matching one of the patterns will be extracted. −o Output. Read alist of filenames from standard input and produce a newarchive onstandard output (unless overriden) containing the specified items. −p Pass-through. Read alist of filenames from standard input and copythe files to the specified direc- tory. OPTIONS Unless specifically stated otherwise, options are applicable in all operating modes. −0 Read filenames separated by NUL characters instead of newlines. This is necessary if anyofthe filenames being read might contain newlines. −A (o mode only) Append to the specified archive.(Not yet implemented.) −a (o and p modes) Reset access times on files after theyare read. −B (o mode only) Block output to records of 5120 bytes. −C size (o mode only) Block output to records of size bytes. −c (o mode only) Use the old POSIX portable character format. Equivalent to −-format odc. -

Red Hat Linux 6.0
Red Hat Linux 6.0 The Official Red Hat Linux Installation Guide Red Hat Software, Inc. Durham, North Carolina Copyright c 1995, 1996, 1997, 1998, 1999 Red Hat Software, Inc. Red Hat is a registered trademark and the Red Hat Shadow Man logo, RPM, the RPM logo, and Glint are trademarks of Red Hat Software, Inc. Linux is a registered trademark of Linus Torvalds. Motif and UNIX are registered trademarks of The Open Group. Alpha is a trademark of Digital Equipment Corporation. SPARC is a registered trademark of SPARC International, Inc. Products bearing the SPARC trade- marks are based on an architecture developed by Sun Microsystems, Inc. Netscape is a registered trademark of Netscape Communications Corporation in the United States and other countries. TrueType is a registered trademark of Apple Computer, Inc. Windows is a registered trademark of Microsoft Corporation. All other trademarks and copyrights referred to are the property of their respective owners. ISBN: 1-888172-28-2 Revision: Inst-6.0-Print-RHS (04/99) Red Hat Software, Inc. 2600 Meridian Parkway Durham, NC 27713 P. O. Box 13588 Research Triangle Park, NC 27709 (919) 547-0012 http://www.redhat.com While every precaution has been taken in the preparation of this book, the publisher assumes no responsibility for errors or omissions, or for damages resulting from the use of the information con- tained herein. The Official Red Hat Linux Installation Guide may be reproduced and distributed in whole or in part, in any medium, physical or electronic, so long as this copyright notice remains intact and unchanged on all copies. -
List-Of-Mime-Types-By-Content-Type.Pdf
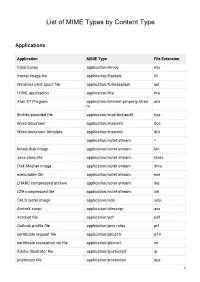
List of MIME Types by Content Type Applications Application MIME Type File Extension Corel Envoy application/envoy evy fractal image file application/fractals fif Windows print spool file application/futuresplash spl HTML application application/hta hta Atari ST Program application/internet-property-strea acx m BinHex encoded file application/mac-binhex40 hqx Word document application/msword doc Word document template application/msword dot application/octet-stream * binary disk image application/octet-stream bin Java class file application/octet-stream class Disk Masher image application/octet-stream dms executable file application/octet-stream exe LHARC compressed archive application/octet-stream lha LZH compressed file application/octet-stream lzh CALS raster image application/oda oda ActiveX script application/olescript axs Acrobat file application/pdf pdf Outlook profile file application/pics-rules prf certificate request file application/pkcs10 p10 certificate revocation list file application/pkix-crl crl Adobe Illustrator file application/postscript ai postscript file application/postscript eps 1 postscript file application/postscript ps rich text format file application/rtf rtf set payment initiation application/set-payment-initiation setpay set registration initiation application/set-registration-initiatio setreg n Excel Add-in file application/vnd.ms-excel xla Excel chart application/vnd.ms-excel xlc Excel macro application/vnd.ms-excel xlm Excel spreadsheet application/vnd.ms-excel xls Excel template application/vnd.ms-excel -

RTEMS Release Notes Edition 4.9.0, for RTEMS 4.9.0
RTEMS Release Notes Edition 4.9.0, for RTEMS 4.9.0 24 September 2008 On-Line Applications Research Corporation On-Line Applications Research Corporation TEXinfo 2007-12-02.17 COPYRIGHT c 1988 - 2008. On-Line Applications Research Corporation (OAR). The authors have used their best efforts in preparing this material. These efforts include the development, research, and testing of the theories and programs to determine their effectiveness. No warranty of any kind, expressed or implied, with regard to the software or the material contained in this document is provided. No liability arising out of the application or use of any product described in this document is assumed. The authors reserve the right to revise this material and to make changes from time to time in the content hereof without obligation to notify anyone of such revision or changes. The RTEMS Project is hosted at http://www.rtems.com. Any inquiries concerning RTEMS, its related support components, its documentation, or any custom services for RTEMS should be directed to the contacts listed on that site. A current list of RTEMS Support Providers is at http://www.rtems.com/support.html. i Table of Contents 1 Introduction::::::::::::::::::::::::::::::::::::: 1 1.1 Supporting Tools ::::::::::::::::::::::::::::::::::::::::::::::: 1 1.1.1 GNU Development Tools :::::::::::::::::::::::::::::::::: 1 1.1.2 ANSI C Libraries:::::::::::::::::::::::::::::::::::::::::: 2 1.1.3 GNU C Library ::::::::::::::::::::::::::::::::::::::::::: 2 1.1.4 Cygnus NEWLIB C Library :::::::::::::::::::::::::::::::